Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Deep Learning JP
PPTX, PDF
6,546 views
[DL輪読会]World Models
2018/04/27 Deep Learning JP: http://deeplearning.jp/seminar-2/
Technology
◦
Related topics:
Deep Learning
•
Read more
11
Save
Share
Embed
Embed presentation
Download
Downloaded 117 times
1
/ 30
2
/ 30
Most read
3
/ 30
4
/ 30
5
/ 30
6
/ 30
Most read
7
/ 30
8
/ 30
9
/ 30
10
/ 30
11
/ 30
12
/ 30
13
/ 30
14
/ 30
15
/ 30
16
/ 30
17
/ 30
18
/ 30
19
/ 30
20
/ 30
21
/ 30
22
/ 30
23
/ 30
24
/ 30
25
/ 30
26
/ 30
27
/ 30
28
/ 30
29
/ 30
30
/ 30
Most read
More Related Content
PDF
「世界モデル」と関連研究について
by
Masahiro Suzuki
PPTX
【DL輪読会】DayDreamer: World Models for Physical Robot Learning
by
Deep Learning JP
PPTX
[DL輪読会]GQNと関連研究,世界モデルとの関係について
by
Deep Learning JP
PPTX
[DL輪読会]Dream to Control: Learning Behaviors by Latent Imagination
by
Deep Learning JP
PDF
【DL輪読会】A Path Towards Autonomous Machine Intelligence
by
Deep Learning JP
PPTX
[DL輪読会]Learning Latent Dynamics for Planning from Pixels
by
Deep Learning JP
PPTX
[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...
by
Deep Learning JP
PDF
GAN(と強化学習との関係)
by
Masahiro Suzuki
「世界モデル」と関連研究について
by
Masahiro Suzuki
【DL輪読会】DayDreamer: World Models for Physical Robot Learning
by
Deep Learning JP
[DL輪読会]GQNと関連研究,世界モデルとの関係について
by
Deep Learning JP
[DL輪読会]Dream to Control: Learning Behaviors by Latent Imagination
by
Deep Learning JP
【DL輪読会】A Path Towards Autonomous Machine Intelligence
by
Deep Learning JP
[DL輪読会]Learning Latent Dynamics for Planning from Pixels
by
Deep Learning JP
[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...
by
Deep Learning JP
GAN(と強化学習との関係)
by
Masahiro Suzuki
What's hot
PDF
深層生成モデルと世界モデル
by
Masahiro Suzuki
PDF
深層生成モデルと世界モデル(2020/11/20版)
by
Masahiro Suzuki
PDF
画像生成・生成モデル メタサーベイ
by
cvpaper. challenge
PPTX
【DL輪読会】Transformers are Sample Efficient World Models
by
Deep Learning JP
PDF
PRML学習者から入る深層生成モデル入門
by
tmtm otm
PDF
多様な強化学習の概念と課題認識
by
佑 甲野
PDF
[DL輪読会]Temporal Abstraction in NeurIPS2019
by
Deep Learning JP
PDF
【DL輪読会】Mastering Diverse Domains through World Models
by
Deep Learning JP
PPTX
【DL輪読会】論文解説:Offline Reinforcement Learning as One Big Sequence Modeling Problem
by
Deep Learning JP
PPTX
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
PPTX
[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...
by
Deep Learning JP
PPTX
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
PPTX
報酬設計と逆強化学習
by
Yusuke Nakata
PDF
三次元点群を取り扱うニューラルネットワークのサーベイ
by
Naoya Chiba
PDF
POMDP下での強化学習の基礎と応用
by
Yasunori Ozaki
PPTX
モデルアーキテクチャ観点からの高速化2019
by
Yusuke Uchida
PPTX
【DL輪読会】Flamingo: a Visual Language Model for Few-Shot Learning 画像×言語の大規模基盤モ...
by
Deep Learning JP
PPTX
[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing
by
Deep Learning JP
PPTX
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
PDF
(DL hacks輪読) Deep Kernel Learning
by
Masahiro Suzuki
深層生成モデルと世界モデル
by
Masahiro Suzuki
深層生成モデルと世界モデル(2020/11/20版)
by
Masahiro Suzuki
画像生成・生成モデル メタサーベイ
by
cvpaper. challenge
【DL輪読会】Transformers are Sample Efficient World Models
by
Deep Learning JP
PRML学習者から入る深層生成モデル入門
by
tmtm otm
多様な強化学習の概念と課題認識
by
佑 甲野
[DL輪読会]Temporal Abstraction in NeurIPS2019
by
Deep Learning JP
【DL輪読会】Mastering Diverse Domains through World Models
by
Deep Learning JP
【DL輪読会】論文解説:Offline Reinforcement Learning as One Big Sequence Modeling Problem
by
Deep Learning JP
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...
by
Deep Learning JP
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
報酬設計と逆強化学習
by
Yusuke Nakata
三次元点群を取り扱うニューラルネットワークのサーベイ
by
Naoya Chiba
POMDP下での強化学習の基礎と応用
by
Yasunori Ozaki
モデルアーキテクチャ観点からの高速化2019
by
Yusuke Uchida
【DL輪読会】Flamingo: a Visual Language Model for Few-Shot Learning 画像×言語の大規模基盤モ...
by
Deep Learning JP
[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing
by
Deep Learning JP
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
(DL hacks輪読) Deep Kernel Learning
by
Masahiro Suzuki
Similar to [DL輪読会]World Models
PPTX
強化学習エージェントの内発的動機付けによる探索とその応用(第4回 統計・機械学習若手シンポジウム 招待公演)
by
Shota Imai
PPTX
[DL輪読会]Temporal DifferenceVariationalAuto-Encoder
by
Deep Learning JP
PPTX
最新の多様な深層強化学習モデルとその応用(第40回強化学習アーキテクチャ講演資料)
by
Shota Imai
PDF
[DL輪読会]Relational inductive biases, deep learning, and graph networks
by
Deep Learning JP
PDF
第7回WBAシンポジウム:予測符号化モデルとしての 深層予測学習とロボット知能化
by
The Whole Brain Architecture Initiative
PDF
World model
by
harmonylab
PDF
[DL輪読会]Imagination-Augmented Agents for Deep Reinforcement Learning / Learnin...
by
Deep Learning JP
PDF
20150930
by
nlab_utokyo
PPTX
「実ロボットの運動生成」
by
Yurika Doi
PDF
[DL輪読会]Shaping Belief States with Generative Environment Models for RL
by
Deep Learning JP
PDF
2021.1.28 understanding brain
by
Ryuichi Maruyama
PPTX
【DL輪読会】Masked World Models for Visual Control
by
Deep Learning JP
PPTX
「機械学習とは?」から始める Deep learning実践入門
by
Hideto Masuoka
PDF
Seeing Unseens with Machine Learning -- 見えていないものを見出す機械学習
by
Tatsuya Shirakawa
PDF
全脳アーキテクチャ勉強会 第4回(山川)
by
ドワンゴ 人工知能研究所
PDF
Generative deeplearning #02
by
逸人 米田
PDF
Ibis2016okanohara
by
Preferred Networks
PDF
第7回WBAシンポジウム:基調講演
by
The Whole Brain Architecture Initiative
PDF
医療ビッグデータの今後を見通すために知っておきたい機械学習の基礎〜最前線 agains COVID-19
by
Tatsuya Shirakawa
PDF
論文輪読: Deep neural networks are easily fooled: High confidence predictions for...
by
mmisono
強化学習エージェントの内発的動機付けによる探索とその応用(第4回 統計・機械学習若手シンポジウム 招待公演)
by
Shota Imai
[DL輪読会]Temporal DifferenceVariationalAuto-Encoder
by
Deep Learning JP
最新の多様な深層強化学習モデルとその応用(第40回強化学習アーキテクチャ講演資料)
by
Shota Imai
[DL輪読会]Relational inductive biases, deep learning, and graph networks
by
Deep Learning JP
第7回WBAシンポジウム:予測符号化モデルとしての 深層予測学習とロボット知能化
by
The Whole Brain Architecture Initiative
World model
by
harmonylab
[DL輪読会]Imagination-Augmented Agents for Deep Reinforcement Learning / Learnin...
by
Deep Learning JP
20150930
by
nlab_utokyo
「実ロボットの運動生成」
by
Yurika Doi
[DL輪読会]Shaping Belief States with Generative Environment Models for RL
by
Deep Learning JP
2021.1.28 understanding brain
by
Ryuichi Maruyama
【DL輪読会】Masked World Models for Visual Control
by
Deep Learning JP
「機械学習とは?」から始める Deep learning実践入門
by
Hideto Masuoka
Seeing Unseens with Machine Learning -- 見えていないものを見出す機械学習
by
Tatsuya Shirakawa
全脳アーキテクチャ勉強会 第4回(山川)
by
ドワンゴ 人工知能研究所
Generative deeplearning #02
by
逸人 米田
Ibis2016okanohara
by
Preferred Networks
第7回WBAシンポジウム:基調講演
by
The Whole Brain Architecture Initiative
医療ビッグデータの今後を見通すために知っておきたい機械学習の基礎〜最前線 agains COVID-19
by
Tatsuya Shirakawa
論文輪読: Deep neural networks are easily fooled: High confidence predictions for...
by
mmisono
More from Deep Learning JP
PDF
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
PDF
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
PDF
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
PDF
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
PPTX
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
PPTX
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
PDF
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
PPTX
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
PDF
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
PPTX
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
PPTX
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
PPTX
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
PPTX
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
PPTX
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
PPTX
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
PPTX
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
PPTX
【DL輪読会】VIP: Towards Universal Visual Reward and Representation via Value-Impl...
by
Deep Learning JP
PPTX
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
PDF
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
PPTX
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
【DL輪読会】VIP: Towards Universal Visual Reward and Representation via Value-Impl...
by
Deep Learning JP
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
[DL輪読会]World Models
1.
1 DEEP LEARNING JP [DL
Papers] http://deeplearning.jp/ World Models David Ha, Jürgen Schmidhuber Presenter: Masahiro Suzuki, Matsuo Lab
2.
本輪読発表について • World Models –
David Ha, Jürgen Schmidhuber • arXiv: 1803.10122 • Haさんはアカウント名「hardmaru」でおなじみ – 直訳すると「世界モデル」 • 世界モデルのコンセプトと本論文の提案モデルについて説明します – モデル自体はシンプルですが,コンセプトが非常に重要です • より詳しい背景や関連研究については「強化学習アーキテクチャ勉強 会(5/15)」で説明する予定です. 2
3.
余談 • このスライドを作り終わったタイミングでこんなツイートが 3
4.
目次 • 世界モデルの背景 • 提案モデル •
まとめ 4
5.
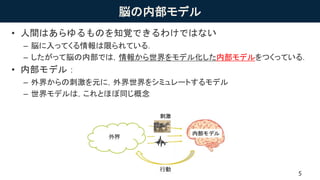
脳の内部モデル • 人間はあらゆるものを知覚できるわけではない – 脳に入ってくる情報は限られている. –
したがって脳の内部では,情報から世界をモデル化した内部モデルをつくっている. • 内部モデル: – 外界からの刺激を元に,外界世界をシミュレートするモデル – 世界モデルは,これとほぼ同じ概念 5
6.
内部モデルによる予測 • 「今までの記憶から未来を予測する力。それが知能である。 」 –
by ジェフ・ホーキンス(「考える脳 考えるコンピュータ」より) • より正確に言うと,現在の運動や行動を使って将来の刺激を予測して いる. – これは,学習した脳の内部モデルによって未来をシミュレーションしているということ. – 人間はこれを常に行っていると考えられる. 6
7.
内部モデルによる予測の例 • 例:野球(バットを振ってボールに当てる) – バットを振るのを決めるのに数ミリ秒かかる –
しかし,視覚信号->脳にかかる時間はそれよりも短い. ⇒Q. なぜバットを速球ボールに当てることが可能なのか? A. 内部モデルから無意識に予測を行い,それに従って筋肉を動かしているから 7
8.
内部モデルをどう設計するか? • ダイナミクスモデルをどのようにモデル化するかは古くか研究されて いた – 1980年代:フィードフォワードNNによるモデル –
1990年代:RNNによるモデル • 「Making the World Differentiable」(Schmidhuber, 1990) – より詳しくは「強化学習アーキテクチャ勉強会」にて • 最近の大規模RNNは,大量のデータから時間的表現を学習することが できる. • またAE系は,空間的表現を学習できる. ⇒内部モデルとして使えそう 8
9.
強化学習での利用 • 強化学習: – 状態と行動,そして環境からの報酬によって,エージェントの最適な方策を求める. –
このときエージェントは,過去や現在の状態の良い表現や未来の予測モデルがあれ ば,効率的に学習できると考えられる(モデルベース強化学習). • つまりエージェントは, – 世界(環境)をモデル化する大規模な内部モデル – タスクを実行するための小規模なモデル(コントローラー) を分けて学習すればいい ⇒本研究のアイディア 9
10.
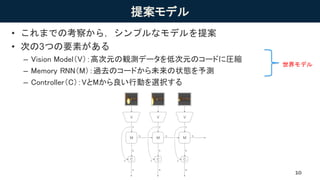
提案モデル • これまでの考察から,シンプルなモデルを提案 • 次の3つの要素がある –
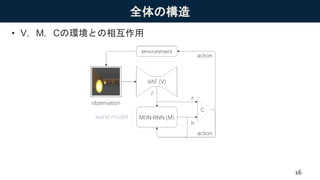
Vision Model(V):高次元の観測データを低次元のコードに圧縮 – Memory RNN(M):過去のコードから未来の状態を予測 – Controller(C):VとMから良い行動を選択する 10 世界モデル
11.
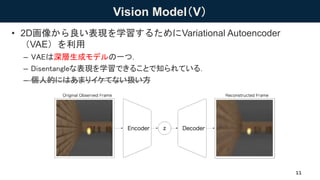
Vision Model(V) • 2D画像から良い表現を学習するためにVariational
Autoencoder (VAE)を利用 – VAEは深層生成モデルの一つ. – Disentangleな表現を学習できることで知られている. – 個人的にはあまりイケてない扱い方 11
12.
MDN-RNN(M) • Mモデルでは,圧縮した表現z_tから次の時間ステップの表現z_t+1を 予測する. – 具体的には,p(z_t+1|a_t,
z_t, h_t) をモデル化する. • aは行動,hはRNNの隠れ状態 – 決定論的ではなく,確率的にz_t+1をサンプルする. • Mモデルには,Haらが提案したMDN-RNNが使われている. – RNNと混合密度ネットワークを組み合わせている. • 温度パラメータで不確かさを調節できる. – Haらとしては,今までの研究を利用したかった感じ. 12
13.
補足:混合密度ネットワーク • 混合密度ネットワーク[Bishop+ 1994]: –
尤度をガウス分布から混合ガウス分布に変更したもの – 背景:単峰だと右図のようなデータへの適合が困難 • あるxに複数の対応するyが存在する. • 実装的には,混合数だけ平均・分散・混合係数を出力させる感じ. 13
14.
MDN-RNNを用いた例 • SketchRNN: – MDN-RNNによって,現在の筆跡から未来の絵を予測. 14
15.
Controller (C) Model •
コントローラーは,累積報酬を最大化するような行動を決める. – 世界モデルに複雑さを託したので,意図的に次のようなシンプルな線形モデルを考 える. – 現在の状態zとRNNの隠れ状態(内部モデルの現在の状態の予測)hが入力となる. – モデルがシンプルなため,従来の方法にとらわれない最適化戦略の選択が可能 • 今回は,進化戦略の一つである共分散行列適応進化戦略(CMA-ES)を選択 • パラメータ数が少ない(実験1では867パラメータ)ため,利用可能 15
16.
全体の構造 • V,M,Cの環境との相互作用 16
17.
実験1:カーレース • 提案モデルでカーレースのタスクを解く. – 行動は,左/右への操作,加速,ブレーキの3つの連続的な行動 –
環境に対してランダムなロールアウトによって10000データを集める • ランダムな行動とその状態を記録しておく. 17
18.
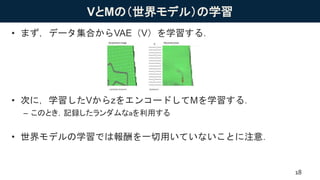
VとMの(世界モデル)の学習 • まず,データ集合からVAE(V)を学習する. • 次に,学習したVからzをエンコードしてMを学習する. –
このとき,記録したランダムなaを利用する • 世界モデルの学習では報酬を一切用いていないことに注意. 18
19.
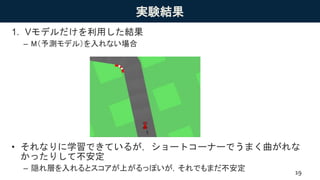
実験結果 1. Vモデルだけを利用した結果 – M(予測モデル)を入れない場合 •
それなりに学習できているが,ショートコーナーでうまく曲がれな かったりして不安定 – 隠れ層を入れるとスコアが上がるっぽいが,それでもまだ不安定 19
20.
実験結果 1. VとMの両方を利用した結果 – 予測モデルにもアクセスできる場合 •
運転がかなり安定するようになっている 20
21.
実験結果 • 平均スコアの比較 – OpenAI
Gymのleaderboard – 既存手法は色々特徴抽出とかやってたが,本研究では生のRGBデータを利用. – 本研究の手法が初めてこのタスクをまともに解いた,という主張 21
22.
世界モデルの「夢」 • SketchRNNと同じ要領で,世界モデルから未来の状態をサンプリング できる. – VAEなので,生成画像はぼやけてます. ということは,夢だけで学習して,実際の環境でうまく動作できる? (イメトレっぽい感じ) 22
23.
実験2:VizDoom • VizDoom: Doomをつかった強化学習用のベンチマーク –
ここでは火の玉を避けるように学習 – タイムステップ数を累積報酬とする(平均750タイムステップ生きられるようにする) 23
24.
実験設定 • 世界モデルだけでエージェントを学習したいので,Mモデルに次のス テップで死ぬかどうかを予測する部分を入れる. – done
_tという2値状態 – P(z_t+1, d_t+1| a_t, z_t, h_t) • データから世界モデルを学習し,その世界モデルによる仮想環境のみ からCを学習する. 24
25.
実験結果:夢の中での訓練 • エージェントは仮想環境で学習して,900タイステップというスコア を達成. • 仮想環境は,不確実性を入れることができるので,より挑戦的なゲー ムをシミュレートできる. –
不確実性はτパラメータで調節可能. – 不確実性を増やすと,実際の環境よりも難しくなる(急に死んだりとか) 25
26.
実験結果:実際の環境でのテスト • 仮想環境で学習したエージェントを実際のゲーム環境でテストする. – スコアは1000タイムステップとなり,仮想環境よりも高いスコアとなった •
不確実な(理不尽な)環境でも学習できるエージェントは,現実世界 なら余裕 26
27.
世界モデルのチート • 小さい頃にビデオゲームをやっていると,ゲームのバグを発見するこ とがある. – ポケモンの13番目セレクトBBとか –
しかしバグ技をつかいまくると,ゲーム本来のクリアに必要なスキルが失われる. • 今回の場合でも,仮想環境内に敵対的な方策があることがわかった. – 火玉がみえたときに,ある移動をすると消せちゃう. – 世界モデルは近似的な確率モデルに過ぎないので,いくらでも現実世界にはない チートをみつけてしまえる. 27
28.
確率モデルによる解決可能性 • 今回は実際の環境の取りうる結果の確率分布をモデル化するために MDN-RNNを用いた. – 確率的にすることで,CがMの欠点を悪用することを防げる. –
不確実性(温度τ)が,世界モデルのリアルさと悪用可能性のトレードオフになってい る. – また混合密度モデルなので,環境の背後にある複雑な論理をモデル化できる可能性 が高い. 28
29.
反復的な訓練 • 今回のタスクは簡単だったので,それっぽい世界モデルを訓練できた. – より複雑なタスクでは,反復的な訓練が必要 –
世界モデルが良くなるように新しい観測を収集する. • 関連テーマ: – 好奇心・内発的動機づけ • Mの尤度をみて,大きいところ(不確かなところ)に行くように行動を選択することで,内部モデルが 改善されそう. – 行動や報酬の予測 • 模倣学習とか – 神経科学とのつながり • 海馬のリプレイによる記憶の固定化( 「Replay Comes of Age」) – カリキュラム学習とか 29
30.
まとめ • 世界モデル中で訓練できる可能性を実証した. – 世界モデルを深層学習フレームワークで学習できるというところに色々利点がある. –
これは,世界を微分可能にしているということに対応(Schmidhuber先生や松尾先生 の考え) • 感想: – 手法よりも,関連研究周りのまとめが面白かった. – 内部モデルの「信念の更新」をどう入れ込むかに興味がある. • 好奇心だけだと内部モデルが学習しきれないのでうまくいかない可能性がある. • 個人的には信念の更新をベイズ的に考えたい. • 外部的に常に尤度をチェックする機構があるといい(「意識」のモデル化) – 内部モデルはまとめて深層生成モデルで扱いたい. 30
Download
![1
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
World Models
David Ha, Jürgen Schmidhuber
Presenter: Masahiro Suzuki, Matsuo Lab](https://image.slidesharecdn.com/20180427-180427003856/85/DL-World-Models-1-320.jpg)







![補足:混合密度ネットワーク
• 混合密度ネットワーク[Bishop+ 1994]:
– 尤度をガウス分布から混合ガウス分布に変更したもの
– 背景:単峰だと右図のようなデータへの適合が困難
• あるxに複数の対応するyが存在する.
• 実装的には,混合数だけ平均・分散・混合係数を出力させる感じ.
13](https://image.slidesharecdn.com/20180427-180427003856/85/DL-World-Models-13-320.jpg)

















![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Dream to Control: Learning Behaviors by Latent Imagination](https://cdn.slidesharecdn.com/ss_thumbnails/20200313furutav2-200313025657-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Learning Latent Dynamics for Planning from Pixels](https://cdn.slidesharecdn.com/ss_thumbnails/taniguchi20181221-190104064850-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...](https://cdn.slidesharecdn.com/ss_thumbnails/20190426akuzawa-190426020057-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]Temporal Abstraction in NeurIPS2019](https://cdn.slidesharecdn.com/ss_thumbnails/20191115-191112082849-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing](https://cdn.slidesharecdn.com/ss_thumbnails/glide2-220107030326-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Temporal DifferenceVariationalAuto-Encoder](https://cdn.slidesharecdn.com/ss_thumbnails/20181130new-190205051636-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Relational inductive biases, deep learning, and graph networks](https://cdn.slidesharecdn.com/ss_thumbnails/180629dlseminarrelationalinductivebias-180706003755-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Imagination-Augmented Agents for Deep Reinforcement Learning / Learnin...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacksshioya201707281-170728054152-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Shaping Belief States with Generative Environment Models for RL](https://cdn.slidesharecdn.com/ss_thumbnails/20190705suzuki-191204061058-thumbnail.jpg?width=640&height=640&fit=bounds)





























