BigGAN
• Large ScaleGAN Training for High Fidelity Natural Image Synthesis [Brock+ ICLR’19]
• SAGAN [Zhang+ ICLR’18]をベースにしたスケーラブルなアーキテクチャ x 大規模計算資源(TPU v3 x 128+ core)
– バッチサイズやチャネルを大きくする→入力の多様性が増えてmode collapseしにくい&学習の(現実的な)速度も速い
– PGGANのように逐次的に解像度を上げる必要もなく、直接512x512を生成可能
• 様々な性能向上の工夫
– Shared Embedding
– Hierarchical Latent Spaces
– Truncated Trick
– Orthogonal Regularization
• Gはconditional Batch Norm [De Vries+ NIPS’17]でラベルの条件付け
• DはProjection Discriminator [Miyato+ ICLR’18]でラベルの条件付け
7
2. Related Work
High-Fidelity GANs on ImageNet
2018/10/05 西村さんの発表
[DL輪読会]Large Scale GANTraining for High Fidelity Natural Image Synthesis
8.
Conditional Batch Norm
•Modulating early visual processing by language [De Vries+ NIPS’17]
• 元はVisual Question Answeringの文脈で提案
• 任意のモデルの出力をベースにBatch Normを行う
8
2. Related Work
High-Fidelity GANs on ImageNet
![DEEP LEARNING JP
[DL Seminar]
High-Fidelity Image Generation with Fewer Labels
Hiromi Nakagawa, Matsuo Lab
https://deeplearning.jp](https://image.slidesharecdn.com/190315dlseminargan-190315004124/75/DL-High-Fidelity-Image-Generation-with-Fewer-Labels-1-2048.jpg)

![GANを用いたHigh-Fidelity(高精細)な画像生成は、近年の様々な工夫により発展してきた
• 大規模モデルの利用
– BigGAN [Brock+ ICLR‘19]
– SPN(自己回帰モデル) [Menick+ ICLR’19]
• アーキテクチャの改良
– SAGAN [Zhang+ CVPR’18]
– Self Modulation [Chen+ ICLR'19]
– StyleGAN [Karras+ 18.12]
• 正則化
– SNGAN [Miyato+ ICLR'18]
4
1. Introduction
GANを用いたHigh-Fidelityな画像生成の発展](https://image.slidesharecdn.com/190315dlseminargan-190315004124/75/DL-High-Fidelity-Image-Generation-with-Fewer-Labels-4-2048.jpg)

![BigGAN
• Large Scale GAN Training for High Fidelity Natural Image Synthesis [Brock+ ICLR’19]
• SAGAN [Zhang+ ICLR’18]をベースにしたスケーラブルなアーキテクチャ x 大規模計算資源(TPU v3 x 128+ core)
– バッチサイズやチャネルを大きくする→入力の多様性が増えてmode collapseしにくい&学習の(現実的な)速度も速い
– PGGANのように逐次的に解像度を上げる必要もなく、直接512x512を生成可能
• 様々な性能向上の工夫
– Shared Embedding
– Hierarchical Latent Spaces
– Truncated Trick
– Orthogonal Regularization
• Gはconditional Batch Norm [De Vries+ NIPS’17]でラベルの条件付け
• DはProjection Discriminator [Miyato+ ICLR’18]でラベルの条件付け
7
2. Related Work
High-Fidelity GANs on ImageNet
2018/10/05 西村さんの発表
[DL輪読会]Large Scale GANTraining for High Fidelity Natural Image Synthesis](https://image.slidesharecdn.com/190315dlseminargan-190315004124/75/DL-High-Fidelity-Image-Generation-with-Fewer-Labels-7-2048.jpg)
![Conditional Batch Norm
• Modulating early visual processing by language [De Vries+ NIPS’17]
• 元はVisual Question Answeringの文脈で提案
• 任意のモデルの出力をベースにBatch Normを行う
8
2. Related Work
High-Fidelity GANs on ImageNet](https://image.slidesharecdn.com/190315dlseminargan-190315004124/75/DL-High-Fidelity-Image-Generation-with-Fewer-Labels-8-2048.jpg)
![Projection Discriminator
• cGANs with Projection Discriminator [Miyato+ ICLR’18]
• cGANとして従来用いられてきたのはACGAN [Odena+ ICML’17]
– DはReal/Fakeの識別と画像のクラス分類の2つのロスを最適化→多クラスでの学習が困難
• クラス条件ベクトルyを線形写像→Dの出力(φ)と内積を取り、Dの出力を変換(ψ)したものと足し合わせ
• 以下2つを1つのAdversarial Lossで定義可能
– Dの入力画像のReal/Fake
– Dの入力画像のクラス情報に基づくReal/Fake
• ACGANから大きく精度改善
• SAGANやBigGANのDのベース
9
2. Related Work
High-Fidelity GANs on ImageNet](https://image.slidesharecdn.com/190315dlseminargan-190315004124/75/DL-High-Fidelity-Image-Generation-with-Fewer-Labels-9-2048.jpg)

![• 識別系:教師なしデータxに対応する、自動で得られるカテゴリtを定義して教師ありの識別を学習
11
2. Related Work
Self-supervised Learning
Source: Self-supervised Learning による特徴表現学習 | cvpaper.challenge
Context Prediction [Doersch+ ICCV'15]
画像を3x3に分割して2つのパッチの相対位置を8クラス分類
Rotation [Gidaris+ ICLR'18]
画像の回転推定(SoTA & 実装が簡単)
Jigsaw [Noroozi+ ECCV’16]
パッチをランダムな順に入力し、正しい順列をクラス識別
Jigsaw++ [Noroozi + CVPR’18]
一部のパッチを他の画像のパッチに置き換える](https://image.slidesharecdn.com/190315dlseminargan-190315004124/75/DL-High-Fidelity-Image-Generation-with-Fewer-Labels-11-2048.jpg)
![• 再構成系:x={x1,x2}の一部を観測できている状態でxまたはx2を推定
12
2. Related Work
Self-supervised Learning
Source: Self-supervised Learning による特徴表現学習 | cvpaper.challenge
Context Encoder [Pathak+CVPR'16]
欠損画像の補完を回帰で学習
Split-Brain [Zhang+CVPR’17]
ネットワークをチャネル方向に2分割し、L⇔abのアンサンブル
Colorization [Zhang+ ECCV’16]
グレースケール画像(L)の色付け(ab)(量子化したab空間の識別)
SpotArtifact [Wu + CVPR’18]
特徴マップ上で欠損させた画像の補完](https://image.slidesharecdn.com/190315dlseminargan-190315004124/75/DL-High-Fidelity-Image-Generation-with-Fewer-Labels-12-2048.jpg)
![• その他
13
2. Related Work
Self-supervised Learning
Source: Self-supervised Learning による特徴表現学習 | cvpaper.challenge
Counting [Noroozi+ ICCV’17]
分割画像と元画像を同じCNNに入力し、
元画像の出力特徴=全分割画像の出力特徴の和
となるような制約をかける
Instance Discrimination [Wu+ CVPR'18]
各画像インスタンスを1つのクラスとして識別、
各画像の特徴ベクトルが超球上に
まばらに散るような埋め込みになる
Noise asTarget [Bojanowski+ ICML’17]
一様にサンプリングしたtarget vectorsに
各画像からの出力を1v1に対応させ、近づける
(特徴ベクトルを特徴空間上に一様に分散)](https://image.slidesharecdn.com/190315dlseminargan-190315004124/75/DL-High-Fidelity-Image-Generation-with-Fewer-Labels-13-2048.jpg)
![• 最新動向:データ構造に依存しない手法の成功
14
2. Related Work
Self-supervised Learning
Source: Self-supervised Learning による特徴表現学習 | cvpaper.challenge
Deep Cluster [Caron+ ECCV’18]
CNNの中間特徴を元にk-meansクラスタリング
→クラスタを擬似ラベルとして識別問題を学習
CPC [Oord+ 18.07]
系列情報においてある時点での特徴ベクトルc_t
と先の入力x_t+1の相互情報量を最大化
DがN個のペアから1つのpositiveペアを識別する
Nクラス分類問題を解くことでIの下限を最大化
Deep INFORMAX [Devon Hjelm++ ICLR’19]
入力xと特徴ベクトルzの相互情報量を
最大化するように学習
(x, z)のペアのpos-neg識別をするDをつけて
end-to-endに学習するだけでI(x;z)の下限を最大化](https://image.slidesharecdn.com/190315dlseminargan-190315004124/75/DL-High-Fidelity-Image-Generation-with-Fewer-Labels-14-2048.jpg)
![• Self-Supervised Generative Adversarial Networks [Chen+ CVPR'19]
– NN→破滅的忘却、GANでも、Gの生成分布が動的に変化していくため、Dが学習初期の識別境界を忘れて学習が不安定になる
– ラベルがある場合はラベルの条件付けである程度回避できるが、ラベルがないときでもSelf-supervisedに解決したい
– Dは画像の回転の判定を真データのみから学習することで安定化
– Self-supervised LearningをDの学習に反映させた点で、本研究のベース(同じグループ)
• Revisiting Self-Supervised Visual Representation Learning [Kolesnikov+ CVPR'19]
– タスクだけでなく、CNNのアーキテクチャも考慮しながら、 Self-supervised Learningの多様な手法を検証
– 教師ありの相対的な精度に完全に比例するわけではない
– 特に、Self-Supervised LearningではSkip-Connectionがあることが重要
– アーキテクチャによってタスクの相性の善し悪しがある
– CNNのフィルタを増やすことに依る表現の質の向上の幅が、教師ありよりも大きい
15
2. Related Work
Self-supervised Learning](https://image.slidesharecdn.com/190315dlseminargan-190315004124/75/DL-High-Fidelity-Image-Generation-with-Fewer-Labels-15-2048.jpg)

![• cGANにおけるラベルの意味合い
– Supervised Learning:人のラベル付けをDの学習に使う
– Self-Supervised Learning:自分で推論したラベルをDの学習に使う
• DにはProjection Discriminatorでラベル情報を渡す
– Dを表現学習を行う 𝐷 と線形分類器の 𝑐 𝑟/𝑓に分解し、𝐷(𝑥, 𝑦) = 𝑐 𝑟/𝑓( 𝐷 𝑥 + 𝑃( 𝐷 𝑥 , 𝑦) と表す( 𝑃 は線形写像)
• Gにはclass-conditional Batch Norm [Dumoulin+ ICLR’17, De Vries+ NIPS’17] でラベル情報を渡す
17
3. Proposed Method
Incorporating the labels
Projection Discriminatorを用いた基本的なcGANの構造
本研究では、3つのアプローチを検証
• Pre-trained approaches
• Co-training approaches
• Self-supervision during GAN training](https://image.slidesharecdn.com/190315dlseminargan-190315004124/75/DL-High-Fidelity-Image-Generation-with-Fewer-Labels-17-2048.jpg)
![• Unsupervised clustering-based method(CLUSTERING)
– 特徴抽出器 𝐹 を教師なし表現学習でSoTAの画像の回転を予測するタスクでSelf-Supervisedに学習
• [Gidaris+ ICLR'18] Unsupervised Representation Learning by Predicting Image Rotations
• [Kolesnikov+ CVPR'19] Revisiting Self-Supervised Visual Representation Learning
– 学習した表現をk-Meansでクラスタリング(𝑐 𝐶𝐿)し、得られたラベルを疑似ラベルとしてGANを訓練
– つまり、 𝑦 𝐶𝐿 = 𝑐 𝐶𝐿(𝐹(𝑥)) をラベルとしてGANを訓練
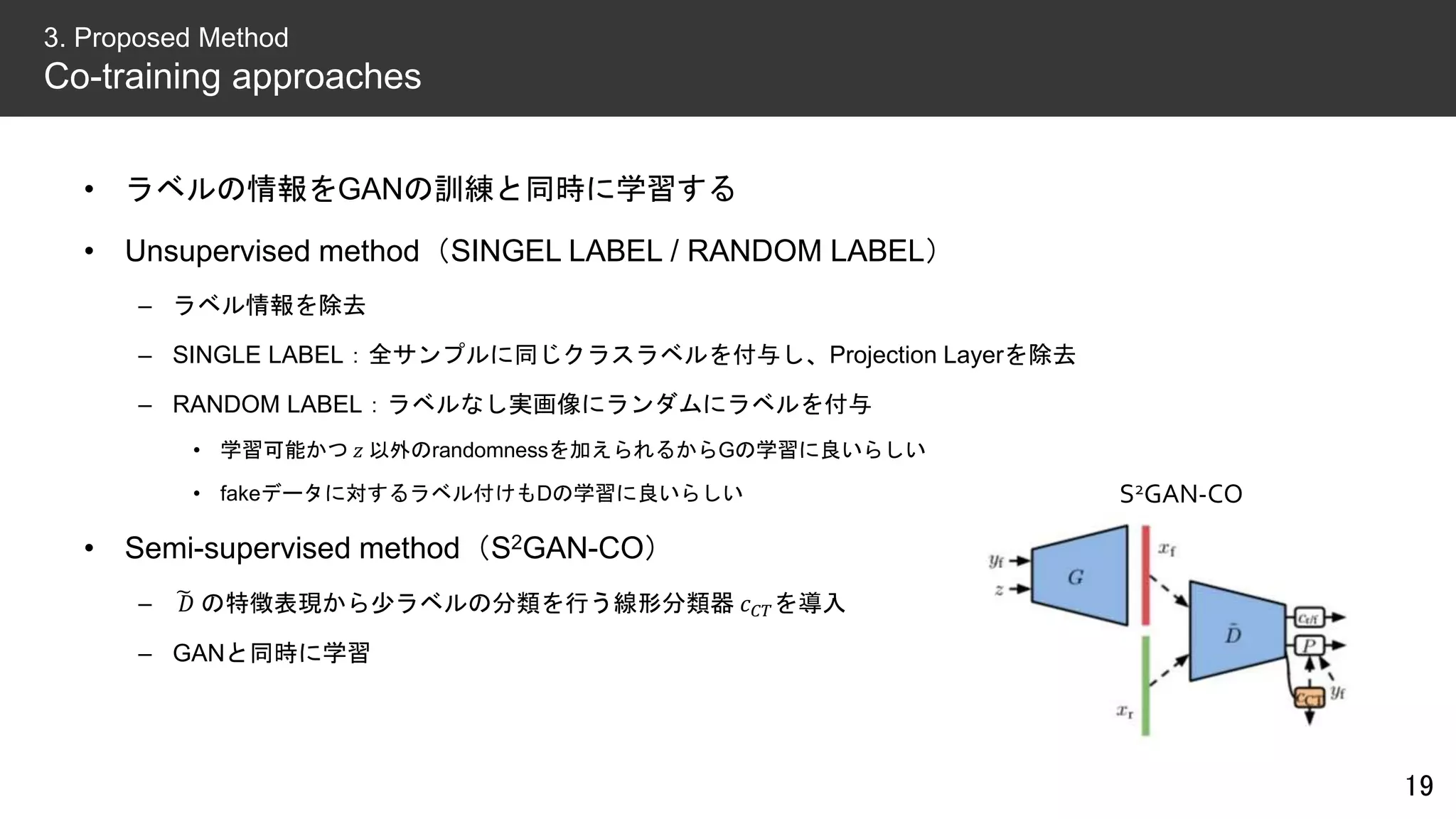
• Semi-supervised method(S2GAN)
– 表現学習時に少量のラベル識別器(𝑐𝑆2
𝐿)を入れてそのロスも最適化
– GANの学習時は特徴抽出器 𝐹 と 𝑐 𝐶𝐿 だけがCLUSTERINGと異なる
18
3. Proposed Method
Pre-trained approaches
CLUSTERING](https://image.slidesharecdn.com/190315dlseminargan-190315004124/75/DL-High-Fidelity-Image-Generation-with-Fewer-Labels-18-2048.jpg)
![• Pre-training / Co-training approachesでは、 𝐹 の良い表現を得るためにSelf-/Semi-Supervised
Learningを用いた
• Discriminator自体も分類器→補助タスクが役に立つはず
• 同様に回転を予測するタスクでGANの学習時もDをSelf-Supervision
– [Chen+ CVPR‘19] Self-Supervised GANs で学習が安定化することが実証されている
– 学習が進むに連れてGの生成分布が動的に変わる場合に、Dが学習初期の識別境界を忘却しないように働く
20
3. Proposed Method
Self-Supervision during GAN training](https://image.slidesharecdn.com/190315dlseminargan-190315004124/75/DL-High-Fidelity-Image-Generation-with-Fewer-Labels-20-2048.jpg)

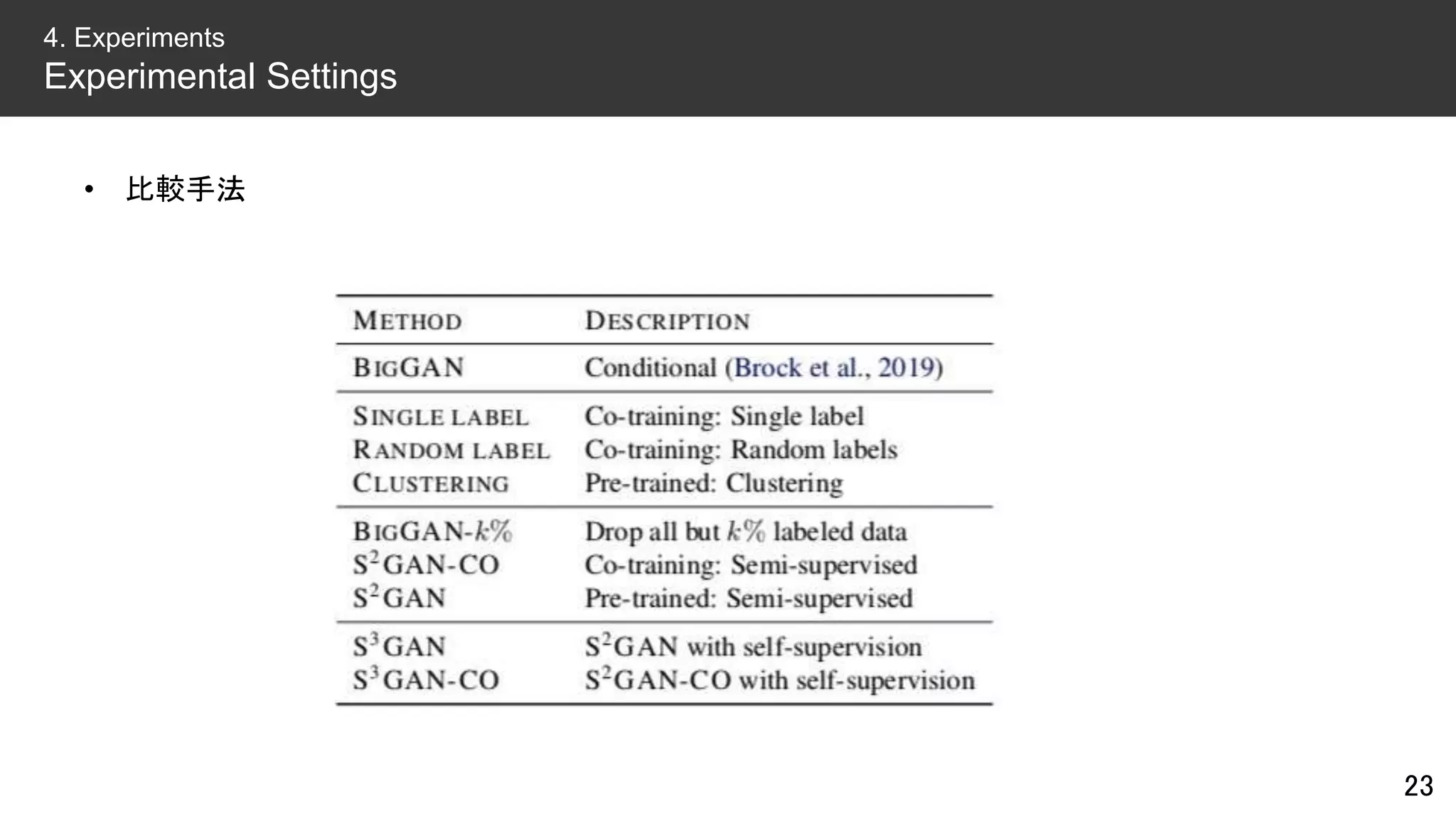
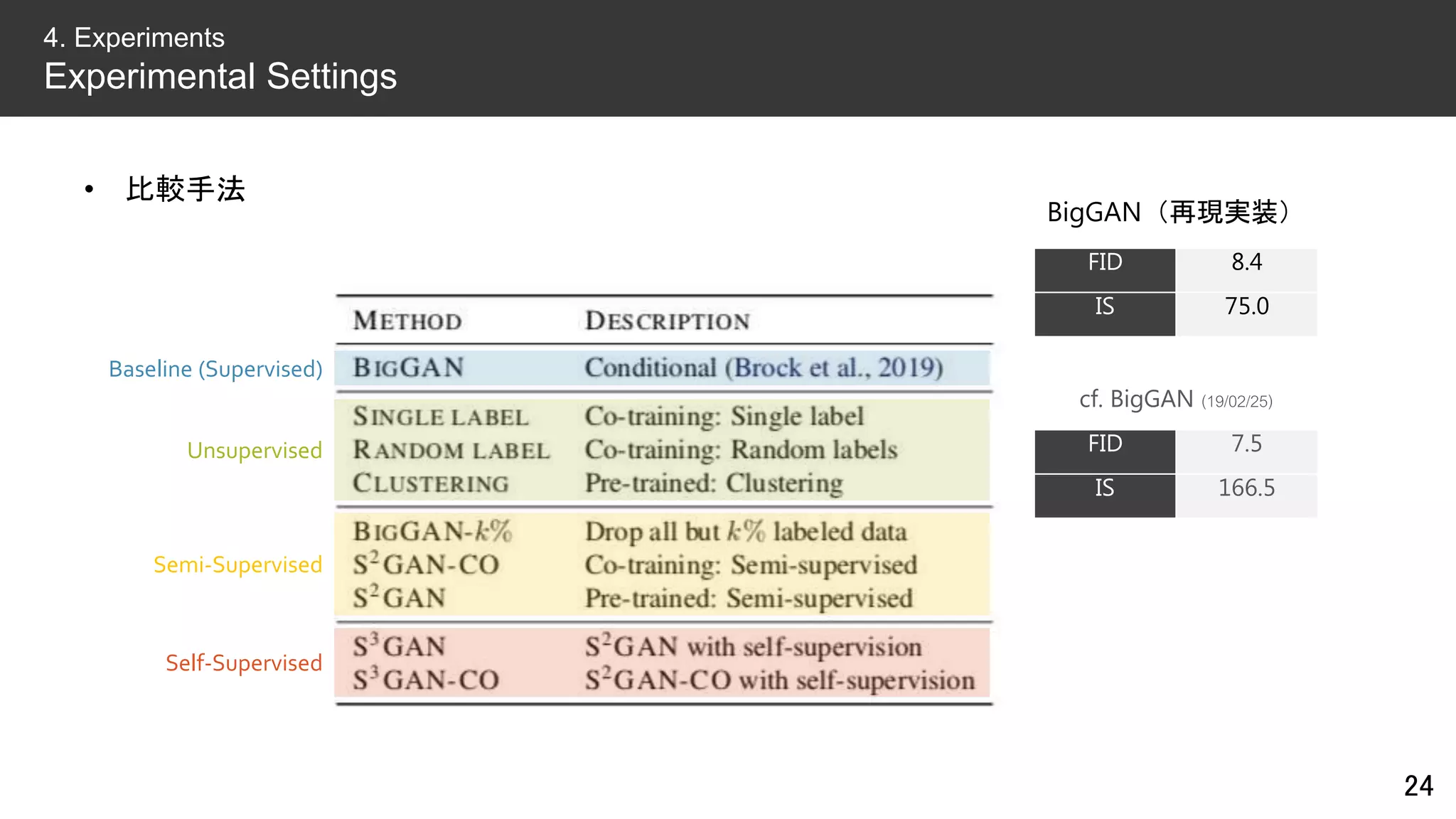
![• アーキテクチャ&ハイパラ
– 基本的にはBigGAN [Brock+ ICLR’19] と同じ
– Orthogonal InitializationとTruncation Trickは使わない
– 128x128x3にリサイズした画像をバッチサイズ2048で学習(TPU v3 x 128 core)
• データセット
– ImageNet(#class=1K, #training=1.3M, #test=50K)
• 評価指標
– FID(Fréchet Inception Distance):低いほどよい
– IS(Inception Score):高いほどよい
22
4. Experiments
Experimental Settings](https://image.slidesharecdn.com/190315dlseminargan-190315004124/75/DL-High-Fidelity-Image-Generation-with-Fewer-Labels-22-2048.jpg)
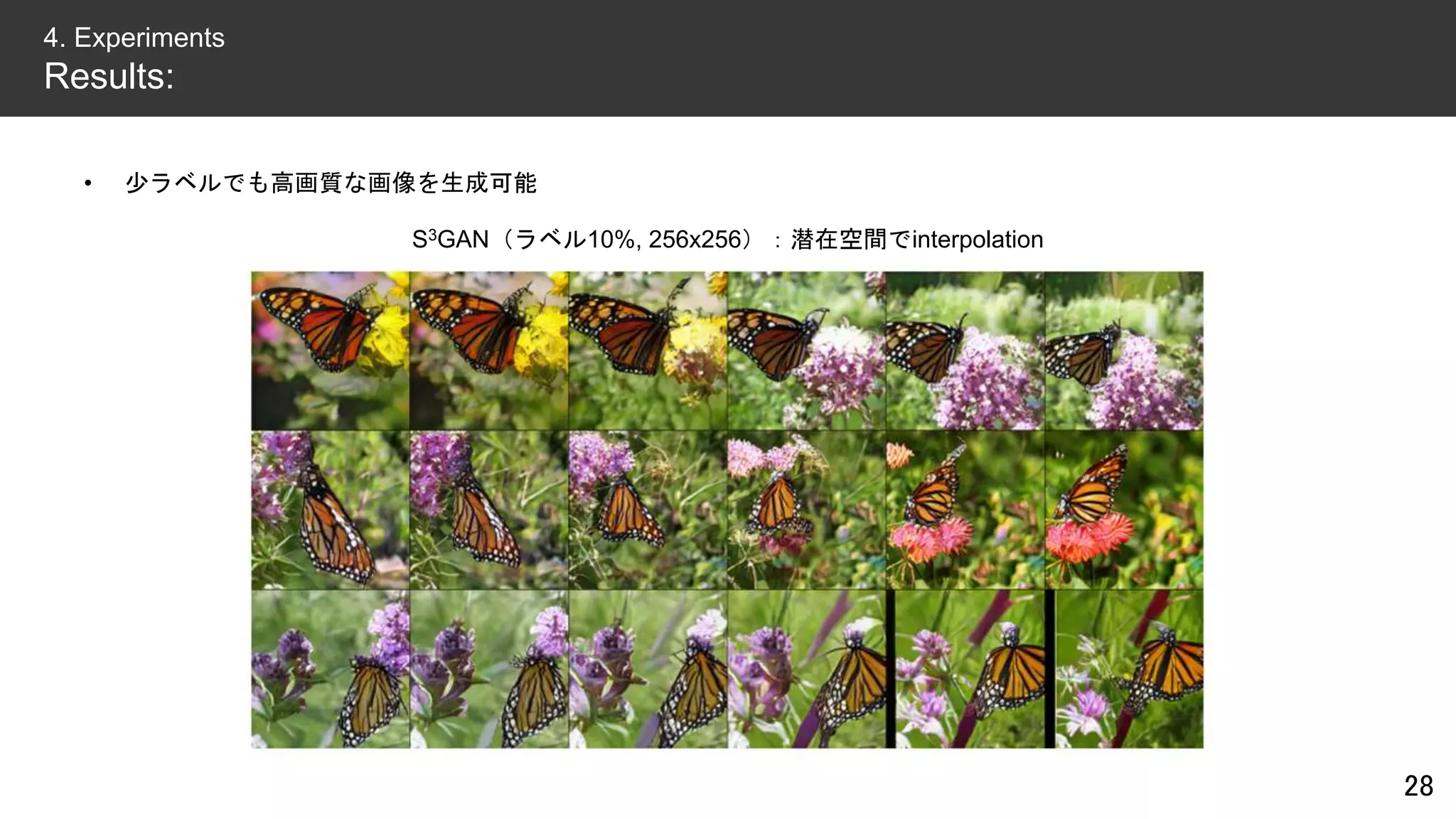
![• BigGANと比べると、完全な教師なしは分が悪い
• が、既存の教師なしのSoTA(FID=33)よりは良い
– [Chen+ CVPR’19] Self-Supervised GANs
25
4. Experiments
Results: Unsupervised Approaches
SS:Self-supervisionをGANの訓練中に行ったもの
BigGAN
FID 8.4
IS 75.0](https://image.slidesharecdn.com/190315dlseminargan-190315004124/75/DL-High-Fidelity-Image-Generation-with-Fewer-Labels-25-2048.jpg)





![• Hierarchical Autoregressive Image Models with Auxiliary Decoders [De Fauw+ 19.03]
– 同日2019/03/06にarXivに投稿された、自己回帰モデルベースの画像生成の論文
– Jeffrey De Fauw, Sander Dieleman, Karen Simonyan(DeepMind)
• GANベースと比べた自己回帰モデルベースの手法の特徴
– Pros:
• localなtextureやdetailを捉えるのに優れている
• GANのようにMode Collapseに陥らない
– Cons:structureやlarge-scale coherenceが苦手
• アーキテクチャレベルの帰納バイアスの問題
• 尤度最大化により生じる問題
• 既存の解決策:局所的な情報を取り除く
– Glow [Kingma+ NIPS’18], SPN + Multidimensional Upscaling [Menick+ ICLR’19]
• 提案手法:Auxiliary Decoderで入力表現を学習し、それをAR priorに適用する2stage型
32
おまけ](https://image.slidesharecdn.com/190315dlseminargan-190315004124/75/DL-High-Fidelity-Image-Generation-with-Fewer-Labels-32-2048.jpg)
![• 論文
[Bojanowski+ ICML'17] Unsupervised Learning by Predicting Noise
[Brock+ ICLR’19] Large Scale GAN Training for High Fidelity Natural Image Synthesis
[Caron+ ECCV’18] Deep Clustering for Unsupervised Learning of Visual Features
[Chen+ ICLR'19] On Self Modulation for Generative Adversarial Networks
[Chen+ CVPR'19] Self-Supervised Generative Adversarial Networks
[Devon Hjelm+ ICLR’19] Learning deep representations by mutual information estimation and maximization
[De Vries+ NIPS'17] Modulating early visual processing by language
[Doersch+ ICCV’15] Unsupervised Visual Representation Learning by Context Prediction
[Gidaris+ ICLR'18] Unsupervised Representation Learning by Predicting Image Rotations
[Kolesnikov+ CVPR'19] Revisiting Self-Supervised Visual Representation Learning
[Noroozi+ ECCV'16] Unsupervised Learning of Visual Representations by Solving Jigsaw Puzzles
[Noroozi+ ICCV'17] Representation Learning by Learning to Count
[Noroozi+ CVPR’18] Boosting Self-Supervised Learning viaKnowledge Transfer
[Miyato+ ICLR'18] cGANs with Projection Discriminator
[Mundhenk+ CVPR'18] Improvements to context based self-supervised learning
[Oord+ 18.07] Representation Learning with Contrastive Predictive Coding
[Pathak+ CVPR’16] Context encoders: Feature learning by inpainting
[Wu+ CVPR’18] Self-Supervised Feature Learning by Learning to Spot Artifacts
[Wu+ CVPR'18] Unsupervised Feature Learning via Non-Parametric Instance Discrimination
[Zhang+ ECCV’16] Colorful Image Colorization
[Zhang+ CVPR'17] Split-brain Autoencoders: Unsupervised Learning by Cross-channel Prediction
[Zhang+ CVPR’18] Self-Attention Generative Adversarial Networks
• 記事
[DL輪読会]Large Scale GAN Training for High Fidelity Natural Image Synthesis
Self-supervised Learning による特徴表現学習 | cvpaper.challenge
33
参考文献](https://image.slidesharecdn.com/190315dlseminargan-190315004124/75/DL-High-Fidelity-Image-Generation-with-Fewer-Labels-33-2048.jpg)










![[DL Hacks]Self-Attention Generative Adversarial Networks](https://cdn.slidesharecdn.com/ss_thumbnails/self-attentiongenerativeadversarialnetworks-180730075733-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会] MoCoGAN: Decomposing Motion and Content for Video Generation](https://cdn.slidesharecdn.com/ss_thumbnails/0911mocogan-170911121936-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]10分で10本の論⽂をざっくりと理解する (ICML2020)](https://cdn.slidesharecdn.com/ss_thumbnails/20200828-ant-200828025358-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会] “Asymmetric Tri-training for Unsupervised Domain Adaptation (ICML2017...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20170728-170728025901-thumbnail.jpg?width=640&height=640&fit=bounds)



























