6.1 Offline andsupervised reinforcement learning
I. Distribution shift in offline RL.
A. Constrain the policy action space.
B. Incorporate value pessimism
C. Incorporate pessimism into learned dynamics models.
II. Learning wide behavior distibution
A. Learning a task-agnostic set of skill, eigher with likelihood-based approaches.
B. maximizing mutual information
III. Return conditioning/’supervised RL’
A. similar to DT. DT benefit from the use of long contexts for behavior modeling as long-term
credit assignment.
❏ Offline RLの分布シフト問題に取り組む研究がたくさんある!
❏ 強化学習をSupervised Learningとして扱う研究
21.
6.2 Credit assignment(貢献度の分配)
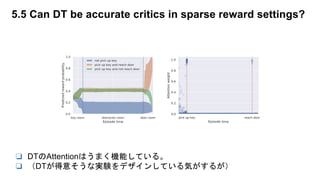
❏報酬を最も重要なStepで与える必要があり、その分配を求める研究
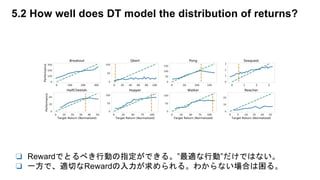
❏ 実験通じて、Transformerが良さそうことが分かった
1. Self-Attentional Credit Assignment for Transfer in Reinforcement
Learning
2. Hindsight Credit Assignment
3. Counterfactual credit assignment in model-free reinforcement
learning
22.
6.3 Conditional languagegeneration
6.4 Attention and transformer models
❏ 条件付き言語生成、TransformerとAttentionなどの関連研究がたくさんある
Offline RL, Sequencemodeling, goal condition by reward.
❏ アイデアが面白くて、関連研究がいっぱいでる予想
❏ 適切な報酬が知らないと困るので、解決できそうなアイデアを考えたい
Future work
- Stochastic Decision Transformer
- conditioning on return distributions to model stochastic settings instead of deterministic returns
- Model-based Decision Transformer.
- Transformer models can also be used to model the state evolution of trajectory
- For Real-world application
- Augmenting RL.
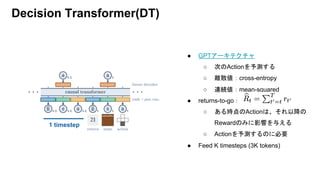
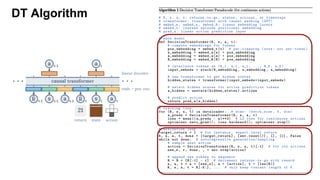
Decision Transformer
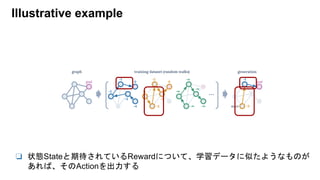
- Offline RL設定でGPT アーキテクチャを用いた。
- 適切なRewardを設定して、それを得られるActionを出力する。
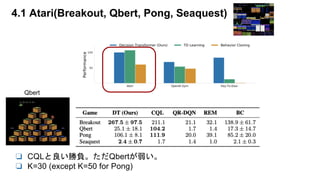
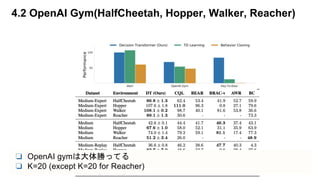
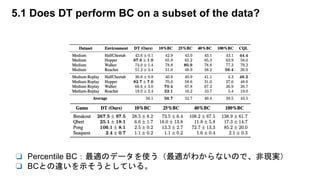
- Model freeの手法(CQL)と比較し、うまくいってる。
![DEEP LEARNING JP
[DL Papers] Decision Transformer :
Reinforcement Learning via sequence modeling
XIN ZHANG, Matsuo Lab
http://deeplearning.jp/](https://image.slidesharecdn.com/decisiontransformer20210709zhangxin-210709021501/85/DL-Decision-Transformer-Reinforcement-Learning-via-Sequence-Modeling-1-320.jpg)
![DEEP LEARNING JP
[DL Papers] Decision Transformer :
Reinforcement Learning via sequence modeling
XIN ZHANG, Matsuo Lab
http://deeplearning.jp/](https://image.slidesharecdn.com/decisiontransformer20210709zhangxin-210709021501/75/DL-Decision-Transformer-Reinforcement-Learning-via-Sequence-Modeling-1-2048.jpg)
















![[DL輪読会] マルチエージェント強化学習と心の理論](https://cdn.slidesharecdn.com/ss_thumbnails/0917imai-211210044729-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]AlphaStarとその関連技術](https://cdn.slidesharecdn.com/ss_thumbnails/dlalphastar-190605035416-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]World Models](https://cdn.slidesharecdn.com/ss_thumbnails/20180427-180427003856-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Dream to Control: Learning Behaviors by Latent Imagination](https://cdn.slidesharecdn.com/ss_thumbnails/20200313furutav2-200313025657-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]逆強化学習とGANs](https://cdn.slidesharecdn.com/ss_thumbnails/irlgans-171128063119-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Learning Latent Dynamics for Planning from Pixels](https://cdn.slidesharecdn.com/ss_thumbnails/taniguchi20181221-190104064850-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...](https://cdn.slidesharecdn.com/ss_thumbnails/20190426akuzawa-190426020057-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]`強化学習のための状態表現学習 -より良い「世界モデル」の獲得に向けて-](https://cdn.slidesharecdn.com/ss_thumbnails/20181026staterepresenration-181127055206-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Model-Based Reinforcement Learning via Meta-Policy Optimization](https://cdn.slidesharecdn.com/ss_thumbnails/model-basedreinforcementlearningviameta-policyoptimization-190705000247-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]近年のオフライン強化学習のまとめ —Offline Reinforcement Learning: Tutorial, Review, an...](https://cdn.slidesharecdn.com/ss_thumbnails/20200626journalclubpub-200630064755-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Temporal DifferenceVariationalAuto-Encoder](https://cdn.slidesharecdn.com/ss_thumbnails/20181130new-190205051636-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Shaping Belief States with Generative Environment Models for RL](https://cdn.slidesharecdn.com/ss_thumbnails/20190705suzuki-191204061058-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Learning to Adapt: Meta-Learning for Model-Based Control](https://cdn.slidesharecdn.com/ss_thumbnails/20180511dl-180511004107-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]ODT: Online Decision Transformer](https://cdn.slidesharecdn.com/ss_thumbnails/20220318-220322065805-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Learning to Act by Predicting the Future](https://cdn.slidesharecdn.com/ss_thumbnails/20171113dl-171114045641-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Imagination-Augmented Agents for Deep Reinforcement Learning / Learnin...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacksshioya201707281-170728054152-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL Hacks 実装]Playing FPS Games with Deep Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks-180202050350-thumbnail.jpg?width=640&height=640&fit=bounds)



















