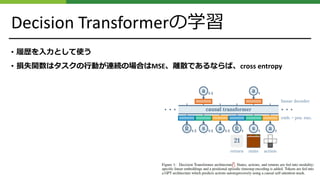
学習の擬似コード
# training loop
for(R, s, a, t) in dataloader : # dims : ( batch_size , K, dim )
a_preds = DecisionTransformer (R, s, a, t)
loss = mean (( a_preds - a )**2) # L2 loss for continuous actions
optimizer . zero_grad (); loss . backward (); optimizer . step ()
15.
評価実験
• 他のオフライン強化学習⼿法と⽐べてどんな性質があるか調べてみた
実験環境
Atari: 離散制御
OpenAI gym: 連続制御
Key-to-door: 右下図のような環境
評価指標
リターンを元に正規化された指標
評価条件
TD法: 特にCQLを利⽤
模倣学習: 特にBCを利⽤
テスト時の初期リターン値
望む値
[4] Thomas Mesnard, Th ophane Weber, Fabio Viola, Shantanu Thakoor, Alaa Saade,
Anna Harutyunyan, Will Dabney, Tom Stepleton, Nicolas Heess, Arthur Guez, et al.
Counterfactual credit assignment in model-free reinforcement learning. arXiv preprint
arXiv:2011.09464, 2020
[4] より引⽤
16.
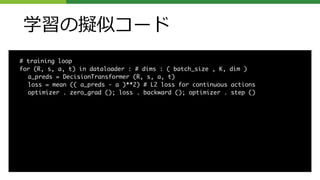
評価実験の擬似コード
# evaluation loop
target_return= 1 # for instance , expert - level return
R, s, a, t, done = [ target_return ], [env. reset ()] , [], [1] , False
while not done : # autoregressive generation / sampling
# sample next action
action = DecisionTransformer (R, s, a, t)[ -1] # for cts actions
new_s , r, done , _ = env. step ( action )
# append new tokens to sequence
R = R + [R[ -1] - r] # decrement returns -to -go with reward
s, a, t = s + [ new_s ], a + [ action ], t + [len(R)]
R, s, a, t = R[-K:], ... # only keep context length of
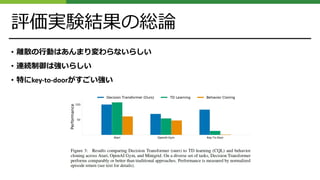
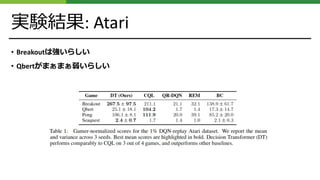
実験結果: OpenAI Gym
•D4RLというデータセットのうち、HalfCheetah、Hopper、Walkerの運動を学習させたらしい
Medium: エキスパートに対して1/3のスコアを出す中レベル⽅策が100万回のタイムスタンプを試⾏し
たデータセット。
Medium-Replay: 最⼤40万回のタイプスタンプを中レベル⽅策で集め、リプレイさせたデータセット。
Medium-Expert: 中レベル⽅策が100万回のタイプスタンプを試⾏したデータとエキスパートが100万
回のタイプスタンプを試⾏したデータセット。
[5] Justin Fu, Aviral Kumar, Ofir Nachum, George Tucker, and Sergey
Levine. D4rl: Datasets for deep data-driven reinforcement learning. arXiv
preprint arXiv:2004.07219, 2020.
[5] より引⽤
20.
考察
• めちゃくちゃ疑問がおおい
Does DecisionTransformer perform behavior cloning on a subset of the data?
How well does Decision Transformer model the distribution of returns?
What is the benefit of using a longer context length?
Does Decision Transformer perform effective long-term credit assignment?
Does Decision Transformer perform well in sparse reward settings?
Why does Decision Transformer avoid the need for value pessimism or behavior regularization?
How can Decision Transformer benefit online RL regimes?
• なので、気になった疑問だけを紹介







![準備: Transformer
• TransformerとはAttentionと呼ばれる以下の数式を特徴とするニューラルネットワーク
• Transformerでスペイン語を英語に翻訳するイメージは以下の通り。
[1] https://qiita.com/omiita/items/07e69aef6c156d23c538
[1] より引⽤](https://image.slidesharecdn.com/decisiontransformerr2distri-210712111601/85/Decision-Transformer-Reinforcement-Learning-via-Sequence-Modeling-7-320.jpg)
![提案⼿法: Decision Transformer
• こんなアニメーション(リンク先[2]参照)のような感じらしい
[2] https://sites.google.com/berkeley.edu/decision-transformer
[2] より引⽤](https://image.slidesharecdn.com/decisiontransformerr2distri-210712111601/85/Decision-Transformer-Reinforcement-Learning-via-Sequence-Modeling-8-320.jpg)

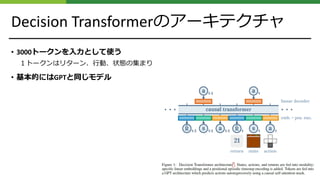
![補⾜: GPTのアーキテクチャ
• GPTのアーキテクチャは下図のとおりである
[3] Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. Improving language understanding by generative pre-training. 2018.
[3] より引⽤](https://image.slidesharecdn.com/decisiontransformerr2distri-210712111601/85/Decision-Transformer-Reinforcement-Learning-via-Sequence-Modeling-11-320.jpg)

![評価実験
• 他のオフライン強化学習⼿法と⽐べてどんな性質があるか調べてみた
実験環境
Atari: 離散制御
Open AI gym: 連続制御
Key-to-door: 右下図のような環境
評価指標
リターンを元に正規化された指標
評価条件
TD法: 特にCQLを利⽤
模倣学習: 特にBCを利⽤
テスト時の初期リターン値
望む値
[4] Thomas Mesnard, Th ophane Weber, Fabio Viola, Shantanu Thakoor, Alaa Saade,
Anna Harutyunyan, Will Dabney, Tom Stepleton, Nicolas Heess, Arthur Guez, et al.
Counterfactual credit assignment in model-free reinforcement learning. arXiv preprint
arXiv:2011.09464, 2020
[4] より引⽤](https://image.slidesharecdn.com/decisiontransformerr2distri-210712111601/85/Decision-Transformer-Reinforcement-Learning-via-Sequence-Modeling-15-320.jpg)
![評価実験の擬似コード
# evaluation loop
target_return = 1 # for instance , expert - level return
R, s, a, t, done = [ target_return ], [env. reset ()] , [], [1] , False
while not done : # autoregressive generation / sampling
# sample next action
action = DecisionTransformer (R, s, a, t)[ -1] # for cts actions
new_s , r, done , _ = env. step ( action )
# append new tokens to sequence
R = R + [R[ -1] - r] # decrement returns -to -go with reward
s, a, t = s + [ new_s ], a + [ action ], t + [len(R)]
R, s, a, t = R[-K:], ... # only keep context length of](https://image.slidesharecdn.com/decisiontransformerr2distri-210712111601/85/Decision-Transformer-Reinforcement-Learning-via-Sequence-Modeling-16-320.jpg)
![実験結果: OpenAI Gym
• D4RLというデータセットのうち、HalfCheetah、Hopper、Walkerの運動を学習させたらしい
Medium: エキスパートに対して1/3のスコアを出す中レベル⽅策が100万回のタイムスタンプを試⾏し
たデータセット。
Medium-Replay: 最⼤40万回のタイプスタンプを中レベル⽅策で集め、リプレイさせたデータセット。
Medium-Expert: 中レベル⽅策が100万回のタイプスタンプを試⾏したデータとエキスパートが100万
回のタイプスタンプを試⾏したデータセット。
[5] Justin Fu, Aviral Kumar, Ofir Nachum, George Tucker, and Sergey
Levine. D4rl: Datasets for deep data-driven reinforcement learning. arXiv
preprint arXiv:2004.07219, 2020.
[5] より引⽤](https://image.slidesharecdn.com/decisiontransformerr2distri-210712111601/85/Decision-Transformer-Reinforcement-Learning-via-Sequence-Modeling-19-320.jpg)


![提案⼿法をオンラインにすると︖
• うまく⾏けば、Go-Exploreの「記憶エンジン」として使えるんじゃないかな
補⾜: Go-ExploreとはAtariの中でも最も難しいゲームをぶっちぎりのスコアを出した⼿法
[5] Adrien Ecoffet, Joost Huizinga, Joel Lehman, Kenneth O Stanley, and Jeff Clune. Go-explore: a new approach for hard-exploration
problems. arXiv preprint arXiv:1901.10995, 2019.
[5] より引⽤
[5] より引⽤](https://image.slidesharecdn.com/decisiontransformerr2distri-210712111601/85/Decision-Transformer-Reinforcement-Learning-via-Sequence-Modeling-22-320.jpg)
![まとめ
• Decision TransformerというTransformerベースの強化学習を提案した
• 強化学習界隈でTransformerをもっと使ってほしい
• 現状では実世界応⽤には難があるかもしれない
特に怪しいデータを突っ込むと意図しない⾏動を起こすかもしれない
[2] より引⽤](https://image.slidesharecdn.com/decisiontransformerr2distri-210712111601/85/Decision-Transformer-Reinforcement-Learning-via-Sequence-Modeling-23-320.jpg)



![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...](https://cdn.slidesharecdn.com/ss_thumbnails/20190426akuzawa-190426020057-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]逆強化学習とGANs](https://cdn.slidesharecdn.com/ss_thumbnails/irlgans-171128063119-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Dream to Control: Learning Behaviors by Latent Imagination](https://cdn.slidesharecdn.com/ss_thumbnails/20200313furutav2-200313025657-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向](https://cdn.slidesharecdn.com/ss_thumbnails/os2-03latest-210610045610-thumbnail.jpg?width=640&height=640&fit=bounds)












![[DL輪読会]`強化学習のための状態表現学習 -より良い「世界モデル」の獲得に向けて-](https://cdn.slidesharecdn.com/ss_thumbnails/20181026staterepresenration-181127055206-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DL輪読会]Temporal DifferenceVariationalAuto-Encoder](https://cdn.slidesharecdn.com/ss_thumbnails/20181130new-190205051636-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Learning to Adapt: Meta-Learning for Model-Based Control](https://cdn.slidesharecdn.com/ss_thumbnails/20180511dl-180511004107-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]ODT: Online Decision Transformer](https://cdn.slidesharecdn.com/ss_thumbnails/20220318-220322065805-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Imagination-Augmented Agents for Deep Reinforcement Learning / Learnin...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacksshioya201707281-170728054152-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Learning Task Informed Abstractions](https://cdn.slidesharecdn.com/ss_thumbnails/20210709akuzawa-210709021836-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Learning to Act by Predicting the Future](https://cdn.slidesharecdn.com/ss_thumbnails/20171113dl-171114045641-thumbnail.jpg?width=640&height=640&fit=bounds)


















