Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Deep Learning JP
PPTX, PDF
446 views
【DL輪読会】Factory: Fast Contact for Robotic Assembly
2022/06/10 Deep Learning JP: http://deeplearning.jp/seminar-2/
Technology
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 25
2
/ 25
3
/ 25
4
/ 25
5
/ 25
6
/ 25
7
/ 25
8
/ 25
9
/ 25
10
/ 25
11
/ 25
12
/ 25
13
/ 25
14
/ 25
15
/ 25
16
/ 25
17
/ 25
18
/ 25
19
/ 25
20
/ 25
21
/ 25
22
/ 25
23
/ 25
24
/ 25
25
/ 25
More Related Content
PDF
深層生成モデルと世界モデル(2020/11/20版)
by
Masahiro Suzuki
PDF
動作認識の最前線:手法,タスク,データセット
by
Toru Tamaki
PDF
[DL輪読会]Progressive Growing of GANs for Improved Quality, Stability, and Varia...
by
Deep Learning JP
PDF
異常検知とGAN: AnoGan
by
Koichiro tamura
PDF
[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision
by
Deep Learning JP
PPTX
【DL輪読会】An Image is Worth One Word: Personalizing Text-to-Image Generation usi...
by
Deep Learning JP
PPTX
これからの Vision & Language ~ Acadexit した4つの理由
by
Yoshitaka Ushiku
PPTX
[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
by
Deep Learning JP
深層生成モデルと世界モデル(2020/11/20版)
by
Masahiro Suzuki
動作認識の最前線:手法,タスク,データセット
by
Toru Tamaki
[DL輪読会]Progressive Growing of GANs for Improved Quality, Stability, and Varia...
by
Deep Learning JP
異常検知とGAN: AnoGan
by
Koichiro tamura
[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision
by
Deep Learning JP
【DL輪読会】An Image is Worth One Word: Personalizing Text-to-Image Generation usi...
by
Deep Learning JP
これからの Vision & Language ~ Acadexit した4つの理由
by
Yoshitaka Ushiku
[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
by
Deep Learning JP
What's hot
PDF
3次元レジストレーション(PCLデモとコード付き)
by
Toru Tamaki
PDF
SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜
by
SSII
PDF
【メタサーベイ】Vision and Language のトップ研究室/研究者
by
cvpaper. challenge
PDF
動画認識サーベイv1(メタサーベイ )
by
cvpaper. challenge
PPTX
【DL輪読会】Flamingo: a Visual Language Model for Few-Shot Learning 画像×言語の大規模基盤モ...
by
Deep Learning JP
PPTX
【DL輪読会】Dropout Reduces Underfitting
by
Deep Learning JP
PDF
ディープラーニングのフレームワークと特許戦争
by
Yosuke Shinya
PDF
【DL輪読会】How Much Can CLIP Benefit Vision-and-Language Tasks?
by
Deep Learning JP
PPTX
[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...
by
Deep Learning JP
PPTX
[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...
by
Deep Learning JP
PDF
【DL輪読会】Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
by
Deep Learning JP
PDF
深層生成モデルを用いたマルチモーダル学習
by
Masahiro Suzuki
PPTX
【DL輪読会】DiffRF: Rendering-guided 3D Radiance Field Diffusion [N. Muller+ CVPR2...
by
Deep Learning JP
PDF
[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
by
Deep Learning JP
PDF
オープンワールド認識 (第34回全脳アーキテクチャ若手の会 勉強会)
by
Takuma Yagi
PDF
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
PDF
Transformer メタサーベイ
by
cvpaper. challenge
PPTX
【DL輪読会】Contrastive Learning as Goal-Conditioned Reinforcement Learning
by
Deep Learning JP
PPTX
【DL輪読会】Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Mo...
by
Deep Learning JP
PDF
文献紹介:Token Shift Transformer for Video Classification
by
Toru Tamaki
3次元レジストレーション(PCLデモとコード付き)
by
Toru Tamaki
SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜
by
SSII
【メタサーベイ】Vision and Language のトップ研究室/研究者
by
cvpaper. challenge
動画認識サーベイv1(メタサーベイ )
by
cvpaper. challenge
【DL輪読会】Flamingo: a Visual Language Model for Few-Shot Learning 画像×言語の大規模基盤モ...
by
Deep Learning JP
【DL輪読会】Dropout Reduces Underfitting
by
Deep Learning JP
ディープラーニングのフレームワークと特許戦争
by
Yosuke Shinya
【DL輪読会】How Much Can CLIP Benefit Vision-and-Language Tasks?
by
Deep Learning JP
[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...
by
Deep Learning JP
[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...
by
Deep Learning JP
【DL輪読会】Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
by
Deep Learning JP
深層生成モデルを用いたマルチモーダル学習
by
Masahiro Suzuki
【DL輪読会】DiffRF: Rendering-guided 3D Radiance Field Diffusion [N. Muller+ CVPR2...
by
Deep Learning JP
[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
by
Deep Learning JP
オープンワールド認識 (第34回全脳アーキテクチャ若手の会 勉強会)
by
Takuma Yagi
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
Transformer メタサーベイ
by
cvpaper. challenge
【DL輪読会】Contrastive Learning as Goal-Conditioned Reinforcement Learning
by
Deep Learning JP
【DL輪読会】Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Mo...
by
Deep Learning JP
文献紹介:Token Shift Transformer for Video Classification
by
Toru Tamaki
Similar to 【DL輪読会】Factory: Fast Contact for Robotic Assembly
PDF
Robotpaper.Challenge 2019-08
by
robotpaperchallenge
PDF
[DL輪読会]Making Sense of Vision and Touch: Self-Supervised Learning of Multimod...
by
Deep Learning JP
PDF
IROS2020 survey
by
robotpaperchallenge
PDF
ヒューマノイドのアプリ開発とモーション生成AIの導入 ROS JP UG #51
by
holypong
PDF
Icra2020 v1
by
robotpaperchallenge
PDF
Pre-Survey 2020 05-04:2020-05-10
by
robotpaperchallenge
PPTX
AI robot car
by
Akira Sasaki
PDF
論文 Solo Advent Calendar
by
諒介 荒木
PDF
Deep Learningを用いたロボット制御
by
Ryosuke Okuta
PDF
実社会・実環境におけるロボットの機械学習 ver. 2
by
Kuniyuki Takahashi
PDF
実社会・実環境におけるロボットの機械学習
by
Kuniyuki Takahashi
PPTX
A Generalist Agent
by
harmonylab
PDF
201110 01 Polytech Center 1
by
openrtm
PPTX
Robosemi - a brief survey on surveys on robotic manipulation researches
by
Fukuoka Institute of Technology
PPTX
Plen2で始めるロボット制御の基本
by
Masuda Tomoaki
PPTX
2020 08-01 ALGYAN AI&ロボティクス (1)
by
Akira Tateishi
PDF
Pre-Survey 2020 04-27:2020-05-03
by
robotpaperchallenge
PDF
Pre-Survey 2020 04-20:2020-04-26
by
robotpaperchallenge
PDF
Variable Stiffness Mechanism(VSM):可変剛性機構に関する研究紹介
by
Kenji Urai
PDF
RobotPaperChallenge 2019-07
by
robotpaperchallenge
Robotpaper.Challenge 2019-08
by
robotpaperchallenge
[DL輪読会]Making Sense of Vision and Touch: Self-Supervised Learning of Multimod...
by
Deep Learning JP
IROS2020 survey
by
robotpaperchallenge
ヒューマノイドのアプリ開発とモーション生成AIの導入 ROS JP UG #51
by
holypong
Icra2020 v1
by
robotpaperchallenge
Pre-Survey 2020 05-04:2020-05-10
by
robotpaperchallenge
AI robot car
by
Akira Sasaki
論文 Solo Advent Calendar
by
諒介 荒木
Deep Learningを用いたロボット制御
by
Ryosuke Okuta
実社会・実環境におけるロボットの機械学習 ver. 2
by
Kuniyuki Takahashi
実社会・実環境におけるロボットの機械学習
by
Kuniyuki Takahashi
A Generalist Agent
by
harmonylab
201110 01 Polytech Center 1
by
openrtm
Robosemi - a brief survey on surveys on robotic manipulation researches
by
Fukuoka Institute of Technology
Plen2で始めるロボット制御の基本
by
Masuda Tomoaki
2020 08-01 ALGYAN AI&ロボティクス (1)
by
Akira Tateishi
Pre-Survey 2020 04-27:2020-05-03
by
robotpaperchallenge
Pre-Survey 2020 04-20:2020-04-26
by
robotpaperchallenge
Variable Stiffness Mechanism(VSM):可変剛性機構に関する研究紹介
by
Kenji Urai
RobotPaperChallenge 2019-07
by
robotpaperchallenge
More from Deep Learning JP
PPTX
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
PPTX
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
PPTX
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
PPTX
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
PPTX
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
PPTX
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
PDF
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
PPTX
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
PDF
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
PPTX
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
PPTX
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
PDF
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
PDF
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
PPTX
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
PPTX
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
PDF
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
PPTX
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
PDF
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
PDF
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
PPTX
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
Recently uploaded
PDF
Team Topology Adaptive Organizational Design for Rapid Delivery of Valuable S...
by
akipii ogaoga
PDF
maisugimoto_曖昧さを含む仕様書の改善を目的としたアノテーション支援ツールの検討_HCI2025.pdf
by
Matsushita Laboratory
PDF
ST2024_PM1_2_Case_study_of_local_newspaper_company.pdf
by
akipii ogaoga
PDF
20260119_VIoTLT_vol22_kitazaki_v1___.pdf
by
Ayachika Kitazaki
PDF
TomokaEdakawa_職種と講義の関係推定に基づく履修支援システムの基礎検討_HCI2026
by
Matsushita Laboratory
PDF
自転車ユーザ参加型路面画像センシングによる点字ブロック検出における性能向上方法の模索 (20260123 SeMI研)
by
Yuto Matsuda
Team Topology Adaptive Organizational Design for Rapid Delivery of Valuable S...
by
akipii ogaoga
maisugimoto_曖昧さを含む仕様書の改善を目的としたアノテーション支援ツールの検討_HCI2025.pdf
by
Matsushita Laboratory
ST2024_PM1_2_Case_study_of_local_newspaper_company.pdf
by
akipii ogaoga
20260119_VIoTLT_vol22_kitazaki_v1___.pdf
by
Ayachika Kitazaki
TomokaEdakawa_職種と講義の関係推定に基づく履修支援システムの基礎検討_HCI2026
by
Matsushita Laboratory
自転車ユーザ参加型路面画像センシングによる点字ブロック検出における性能向上方法の模索 (20260123 SeMI研)
by
Yuto Matsuda
【DL輪読会】Factory: Fast Contact for Robotic Assembly
1.
1 DEEP LEARNING JP [DL
Papers] http://deeplearning.jp/ Factory: Fast Contact for Robotic Assembly Koki Ishimoto
2.
書誌情報 • Title: Factory:
Fast Contact for Robotic Assembly • Author: Yashraj Narang*, Kier Storey*, Iretiayo Akinola*, Miles Macklin*, Philipp Reist*, Lukasz Wawrzyniak*, Ynrong Guo*, Adam Moravanszky*, Gavriel State*, Michelle Lu*, Ankur Handa*, Dieter Fox*† • * NVIDIA • †University of Washington • Project page: https://sites.google.com/nvidia.com/factory/ 2
3.
概要 3 • Contact-Richなシミュレーションをreal-timeに動かすことに成功した • 高品質なCADファイルとメモリ消費を抑えた接触シミュレーション手法により、A50001枚で 1000個のボルトScrew環境を作成可能にした。 •
従来手法に比べて2桁早い • 並列化でシングルスレッドのreal-time計算に比べて3桁の高速化 • AssemblyタスクのBenchmarkを提供した • 4つのpolicyを1-1.5hで学習可能(RTX 3090 1枚)
4.
関連研究 Contact-rich simulation •
従来のcontact-richなタスクを解くsimulatorは、nut-bolt taskのレンダリングにreal-time の20倍以上の時間がかかることが多い • Implicit Multibody Penalty-BasedDistributed Contact (2014): 1/460 real-time • Intersection-free rigid body dynamics(2021): 1/350 real-time • Sim-to-Real Transfer of Bolting Tasks with Tight Tolerance(2020): 4* real-time (ただしタスクが簡 単) 4 https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9341644
5.
Contact-Rich Simulation Methods •
RLタスクなどのために、十分高速に回せるcontact-richなシミュレータの開発 5
6.
SDF Collisions 6 • SDF:
物体の表面を0として外部と内部を正負で表現した関数 • 256^3より大きい解像度のSDFを用意 • 右の画像引用元の手法で物体のcontactの初期情報を計算 • 物体間で最も近い点をSDFの勾配情報から求めていく • M4 (径が4mm) ナットとボルトで16k個のcontactsが生成された • Contact: 物体間に生じるinteraction, 接触力(ベクトル) https://dl.acm.org/doi/pdf/10 .1145/3384538
7.
Contact Reduction and
Solver Selection • 処理の高速化のために、GPUメモリの節約を考える • Contact生成において、各contactに必要なのは7つのfloat(point, normal vector, distance)と2つの inteters(rigid body indices) 合わせて36bytes • およそ160bytesをcontactとその制約に必要なメモリ量として見積もる • M4 ナットとボルト(16k contacts)で約2.5MB/timestep • Jacobi solver(Δt=1/60)の条件で、, 8 sub-steps と 64 iterationsが安定的なシミュレーションのた めに必要 • 上記の設定で、メモリバンド幅はおよそ1.28GB/frame, 76.8GB/s • もしContactsを16k → 300に減らせたら、1つ当たり24MB/frame, 1.4GB/sでシミュレーション可能。 • A5000を使った場合、最大1100個のナット・ボルトアセンブリをsimulationできるはず • Contactsが300程度なら、Gauss-Seidel solverを使用できる(1 substepと16 iterationsで安定的な シミュレーションが可能) 7
8.
Implementation of Contact
Reduction • 近いmesh同士でnormal vector(contact)を共有 することでcontactを減らす 1: SDF collisionを用いてcontactsの生成 2: 法線の類似度でcontactを統合 3: 割り当てられていないものについては、その中で deepest penetrationなcontactを見つける 4: 3で見つけたcontactに、割り当てられていない contactを統合していく 8
9.
Implementation of Contact
Reduction • 削減されたcontact • 300contactsの場合: contactの生成と削減に11ms, contactの制約の解決に3msかかる 9
10.
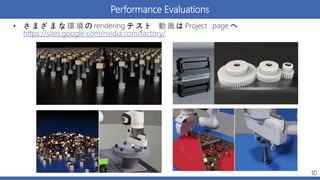
Performance Evaluations • さ
ま ざ ま な 環 境 の rendering テ ス ト 動 画 は Project page へ https://sites.google.com/nvidia.com/factory/ 10
11.
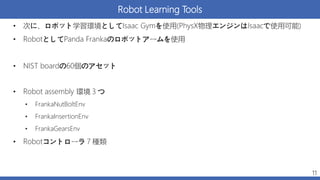
Robot Learning Tools •
次に、ロボット学習環境としてIsaac Gymを使用(PhysX物理エンジンはIsaacで使用可能) • RobotとしてPanda Frankaのロボットアームを使用 • NIST boardの60個のアセット • Robot assembly 環境3つ • FrankaNutBoltEnv • FrankaInsertionEnv • FrankaGearsEnv • Robotコントローラ7種類 11
12.
Robot Learning Tools •
NIST boardの60個のアセット • NISTの公開されているアセットは、正確なシミュレーションを行 う上では精度が不十分 • 電気コネクターなどはCADがピッタリ噛み合わなかったり、手作業で計測 されてたりする • 自作の、より精度の高いCADファイルを作成 12
13.
Scenes • Robot assembly
環境3つ • FrankaNutBoltEnv • ナットとボルトの嵌め込み • M4,M8,M12,M16,M20(使 用 し た ボルトのサイズ) • FrankaInsertionEnv • 丸 型 ま た は 正 方 形 型 の pegs- and-holes/コネクタ類の差し込 み • FrankaGearsEnv • ギア3つとマウンタ1つの嵌め 込み 13
14.
Controllers • Robotコントローラ7種類 • IK(inverse
kinematics) • ID(inverse dynamics) • インピーダンス制御 • Operational-space motion controller • 慣性モーメント・重力補償付きのID • 開ループ力制御 • 閉ループ位置制御 • Hybrid force-motion controller • Motion controllerとforce controllerの組み合わせ(軸によって使い分ける) 14
15.
Reinforcement Learning • タスクを三つに分解 •
Pick • Place • Screw • Pick&Placeタスク自体は古典的 • 特にContact-RichなScrewタスクに注目 15
16.
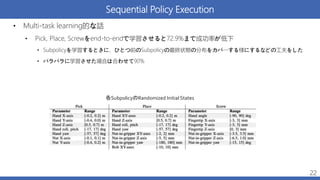
Shared Framework: Pick,
Place, Screw • PPOのハイパラは共通(右表) • 3-4個のpolicyはRTX 3090で同時にバッジ学習 • それぞれのpolicyで128個のsimulation環境を使用 • 各バッジ1024 policy updateに 1-1.5 h • 行動空間 • 開ループ制御と閉ループ制御は3次元力ベクトル • それ以外のコントローラはハンドの相対姿勢(6DoF) 16 各SubpolicyのRandomized Initial States
17.
Subpolicy: Pick and
Place • Pick(成功率 100%) • 観測: ハンド・ナットの姿勢、ハンド速度・角速度 • 行動空間: IK(inverse kinematics) • Dense reward: • kn, kf: ナットの中心軸とハンドの approach axisに関する2-4個のキーポイントからなるテンソル • Success: Pickに成功したら • Place(成功率 98.4%) • 観測: ハンド・ナット・ボルトの姿勢、ハンド+ナットの速度・角速度 • 行動空間: IK • Dense reward: Placeと同様(ボルトとナットに関する距離) • Success: ボルトとナットのキーポイントが0.8mm 以内 17
18.
SubPolicy: Screw • Screw •
観測:複数で比較 • 行動空間:複数で比較 • Dense Reward: ボルトとナット、ナットとハンドのキーポイントの距離の和 • Success: ナットとボルトが最後まで回りきったら成功(最後から1巻以内なら成功) • ハンドの関節角を無限回転と仮定(Frankaは本来無限回転しない) • ハンドをナットから離さずに回すため • さまざまな失敗軌道も見られた • ボルトとの衝突、ナットとボルトが接触した際のroll-pitch軸のずれ、回している際のジャミング、歳差運動に よるハンドとナットのスリップ • ⇨観測・行動空間の比較、baseline_rewardの追加 18
19.
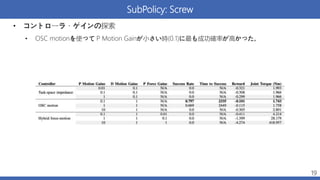
SubPolicy: Screw • コントローラ・ゲインの探索 •
OSC motionを使って P Motion Gainが小さい時(0.1)に最も成功確率が高かった。 19
20.
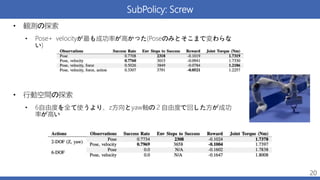
SubPolicy: Screw • 観測の探索 •
Pose+ velocityが最も成功率が高かった(Poseのみとそこまで変わらな い) • 行動空間の探索 • 6自由度を全て使うより、z方向とyaw軸の2自由度で回した方が成功 率が高い 20
21.
SubPolicy: Screw • Baseline_rewardの探索 •
Linearを使用した場合が最も成功率が高かった • d: キーポイント間の距離 21
22.
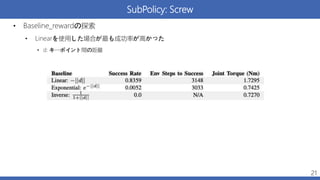
Sequential Policy Execution •
Multi-task learning的な話 • Pick, Place, Screwをend-to-endで学習させると72.9%まで成功率が低下 • Subpolicyを学習するときに、ひとつ前のSubpolicyの最終状態の分布をカバーする様にするなどの工夫をした • バラバラに学習させた場合は合わせて90% 22 各SubpolicyのRandomized Initial States
23.
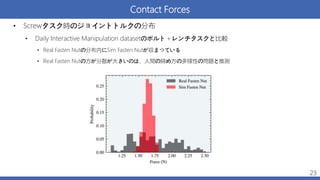
Contact Forces • Screwタスク時のジョイントトルクの分布 •
Daily Interactive Manipulation datasetのボルト+レンチタスクと比較 • Real Fasten Nutの分布内にSim Fasten Nutが収まっている • Real Fasten Nutの方が分散が大きいのは、人間の締め方の多様性の問題と推測 23
24.
Limitations • 要改善点 • SDFの衝突スキーム •
薄い素材でできたボトルや箱の衝突をロバストに処理する機能 • Mesh1つあたりが大きい場合の処理の改善 • Meshひとつごとに一つの接触が生成されるため、平坦で大きい表面の衝突がうまく表現できていない • Sparse SDF representationを用いたメモリの削減 • Deformable objectsのFEMベースのサポート(コネクタケーブルなど) 24
25.
Conclusion • Contact-Richなシミュレーションをreal-timeに動かすことに成功した • 高品質なCADファイルとメモリ消費を抑えた接触シミュレーション手法により、A50001枚で 1000個のボルトScrew環境などを作成可能にした。 •
従来手法に比べて2桁早い • 並列化でシングルスレッドのreal-time計算に比べて3桁の高速化 • AssemblyタスクのBenchmarkを提供した • 4つのpolicyを1-1.5hで学習可能(RTX 3090 1枚) • Screwタスクだけでなく、他のContact-Richなタスクにも応用可能性がある • 非凸形状の把持 • 不均一な屋外地形での移動 など 25
Download
![1
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
Factory: Fast Contact for Robotic Assembly
Koki Ishimoto](https://image.slidesharecdn.com/dlp220610ishimotov0-220613042441-81a9e27c/85/DL-Factory-Fast-Contact-for-Robotic-Assembly-1-320.jpg)




















![[DL輪読会]Progressive Growing of GANs for Improved Quality, Stability, and Varia...](https://cdn.slidesharecdn.com/ss_thumbnails/kuboshizuma20180316-180525003941-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://cdn.slidesharecdn.com/ss_thumbnails/swintransformer-210514020542-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...](https://cdn.slidesharecdn.com/ss_thumbnails/20190426akuzawa-190426020057-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerfdlseminar1-200327021512-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]Making Sense of Vision and Touch: Self-Supervised Learning of Multimod...](https://cdn.slidesharecdn.com/ss_thumbnails/20190802dl-190808102241-thumbnail.jpg?width=640&height=640&fit=bounds)











































