More Related Content
![[DL輪読会]Disentangling by Factorising](https://cdn.slidesharecdn.com/ss_thumbnails/20180720disentanglingbyfactorising-180720000930-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]Disentangling by Factorising ![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX

PDF

PDF
![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant... ![[DL輪読会]近年のエネルギーベースモデルの進展](https://cdn.slidesharecdn.com/ss_thumbnails/energybasedmodel-200124020855-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
![[DL輪読会]Diffusion-based Voice Conversion with Fast Maximum Likelihood Samplin...](https://cdn.slidesharecdn.com/ss_thumbnails/20220318akuzawa-220322065615-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]Diffusion-based Voice Conversion with Fast Maximum Likelihood Samplin... 
PPTX
Curriculum Learning (関東CV勉強会) What's hot

PDF
Transformerを多層にする際の勾配消失問題と解決法について ![[DL輪読会]Deep Learning 第15章 表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning15-180601023904-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]Deep Learning 第15章 表現学習 ![[DL輪読会]Life-Long Disentangled Representation Learning with Cross-Domain Laten...](https://cdn.slidesharecdn.com/ss_thumbnails/20180914iwasawa-180919025635-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]Life-Long Disentangled Representation Learning with Cross-Domain Laten... 
PPTX

PDF

PDF
DQNからRainbowまで 〜深層強化学習の最新動向〜 
PPTX
【DL輪読会】Flow Matching for Generative Modeling 
PPTX
【DL輪読会】Efficiently Modeling Long Sequences with Structured State Spaces 
PPTX
【DL輪読会】ViT + Self Supervised Learningまとめ 
PPTX
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料 ![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜 
PDF
ゼロから始める深層強化学習(NLP2018講演資料)/ Introduction of Deep Reinforcement Learning 
PDF
【論文読み会】Deep Clustering for Unsupervised Learning of Visual Features ![[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv... ![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision ![[DL輪読会]近年のオフライン強化学習のまとめ —Offline Reinforcement Learning: Tutorial, Review, an...](https://cdn.slidesharecdn.com/ss_thumbnails/20200626journalclubpub-200630064755-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]近年のオフライン強化学習のまとめ —Offline Reinforcement Learning: Tutorial, Review, an... 
PDF
![[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing](https://cdn.slidesharecdn.com/ss_thumbnails/glide2-220107030326-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing 
PDF

PDF
【DL輪読会】Mastering Diverse Domains through World Models Similar to Disentanglement Survey:Can You Explain How Much Are Generative models Disentangled?

PDF

PPTX
猫でも分かるVariational AutoEncoder 
PDF

PDF

PDF

PDF
行列およびテンソルデータに対する機械学習(数理助教の会 2011/11/28) 
PPTX
MASTERING ATARI WITH DISCRETE WORLD MODELS (DreamerV2) 
PPTX
DeBERTaV3: Improving DeBERTa using ELECTRA-Style Pre-Training with Gradient-D... 
PPTX
![[DL輪読会]Temporal DifferenceVariationalAuto-Encoder](https://cdn.slidesharecdn.com/ss_thumbnails/20181130new-190205051636-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]Temporal DifferenceVariationalAuto-Encoder 
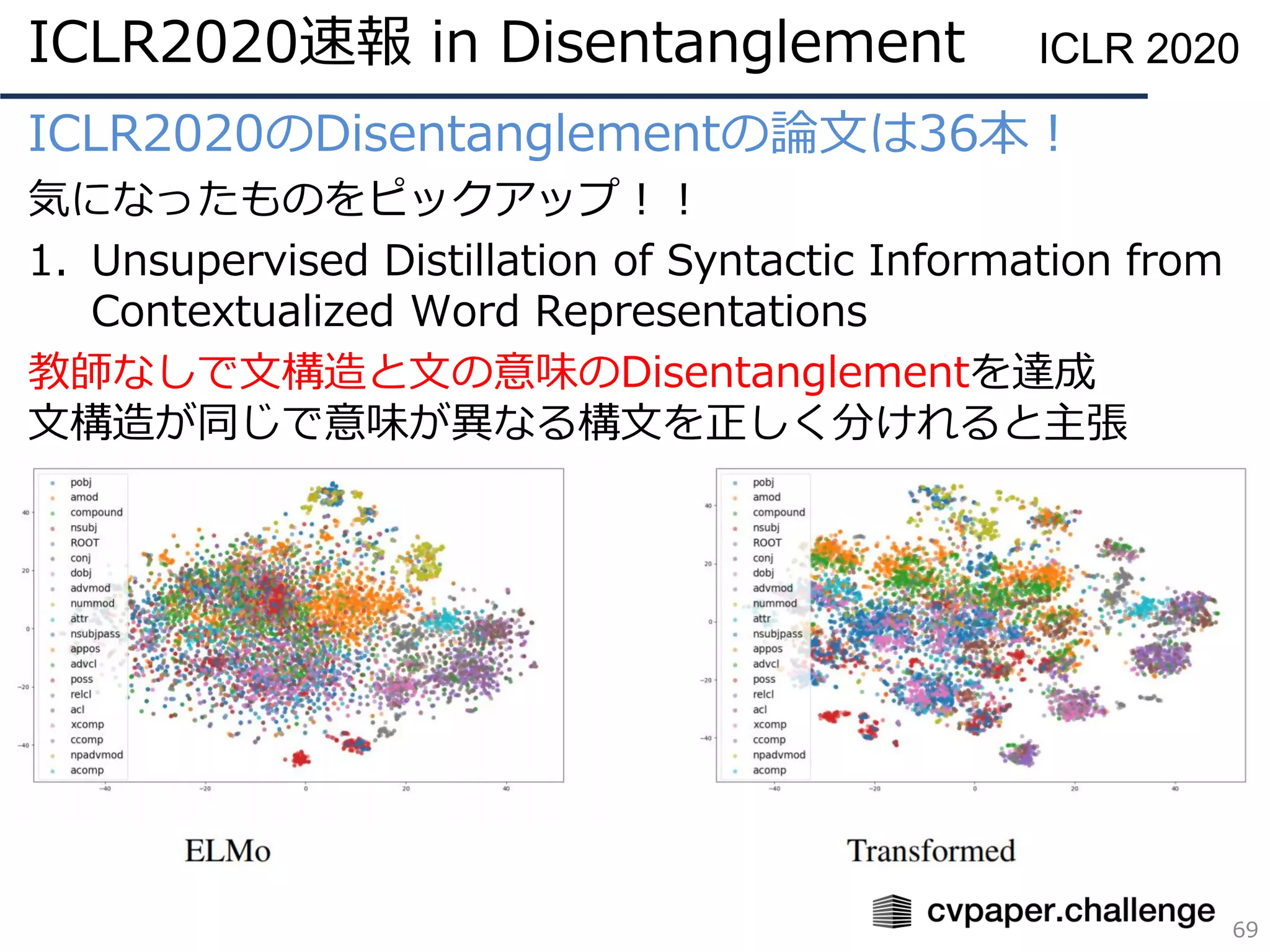
PDF
CVPR2019@ロングビーチ参加速報(後編 ~本会議~) 
PDF
Unified Expectation Maximization ![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]Flow-based Deep Generative Models 
PDF
深層学習と確率プログラミングを融合したEdwardについて 
PDF
Math in Machine Learning / PCA and SVD with Applications 
PDF
AI2: Safety and Robustness Certification of Neural Networks with Abstract Int... 
PDF

PDF
PCSJ/IMPS2021 講演資料:深層画像圧縮からAIの生成モデルへ (VAEの定量的な理論解明) 
PPTX
Semi supervised, weakly-supervised, unsupervised, and active learning 
PDF
Disentanglement Survey:Can You Explain How Much Are Generative models Disentangled?
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
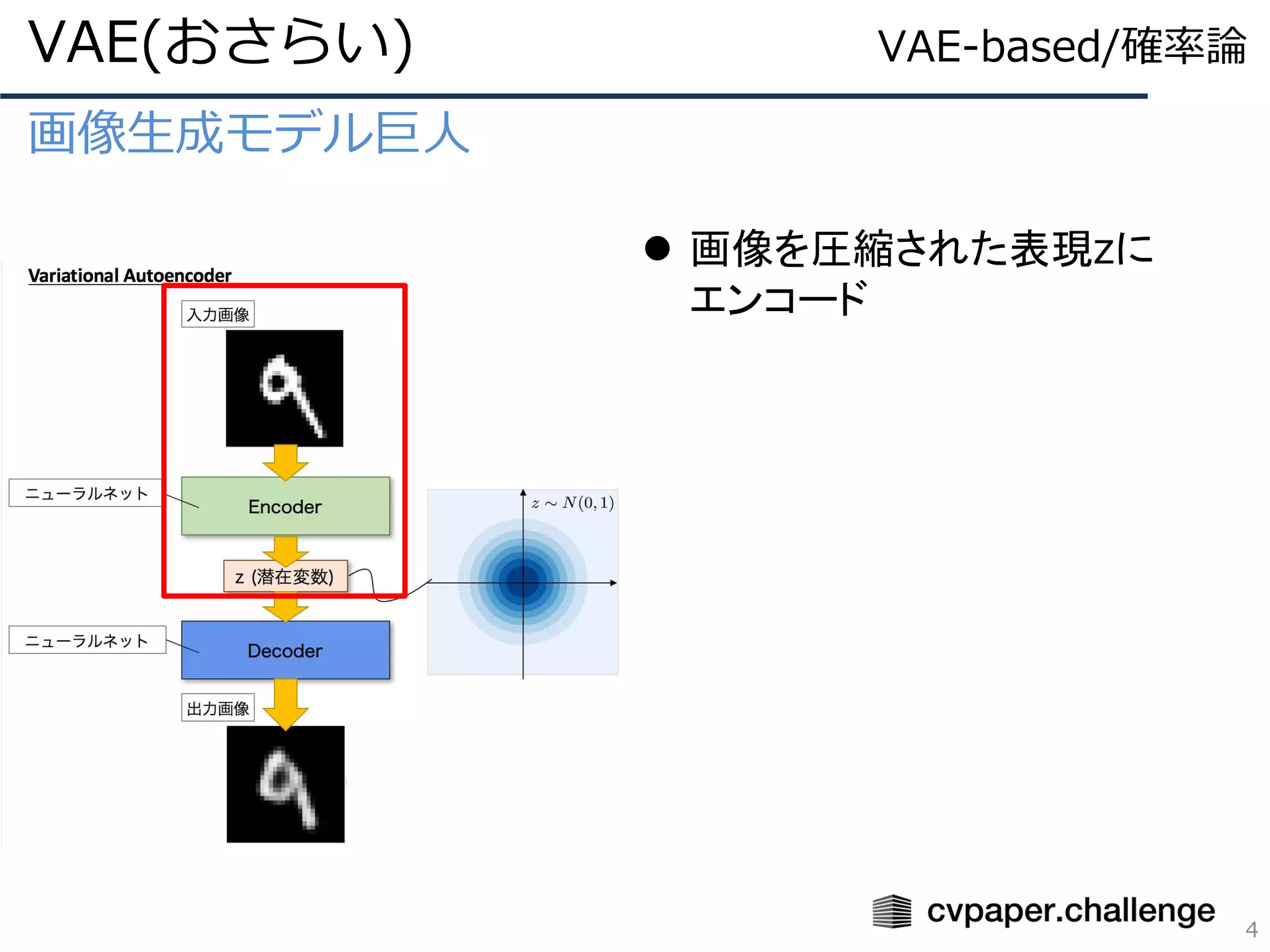
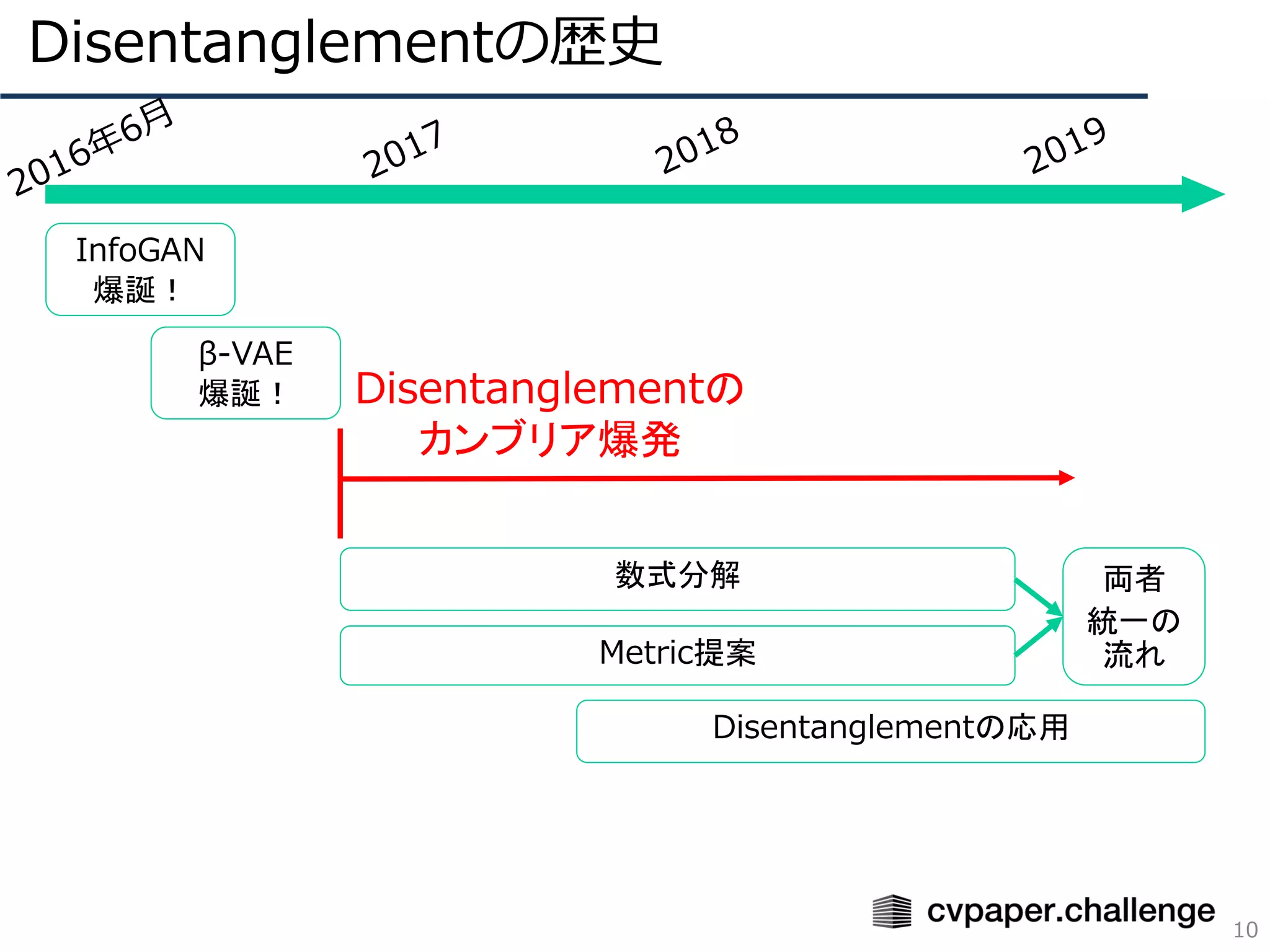
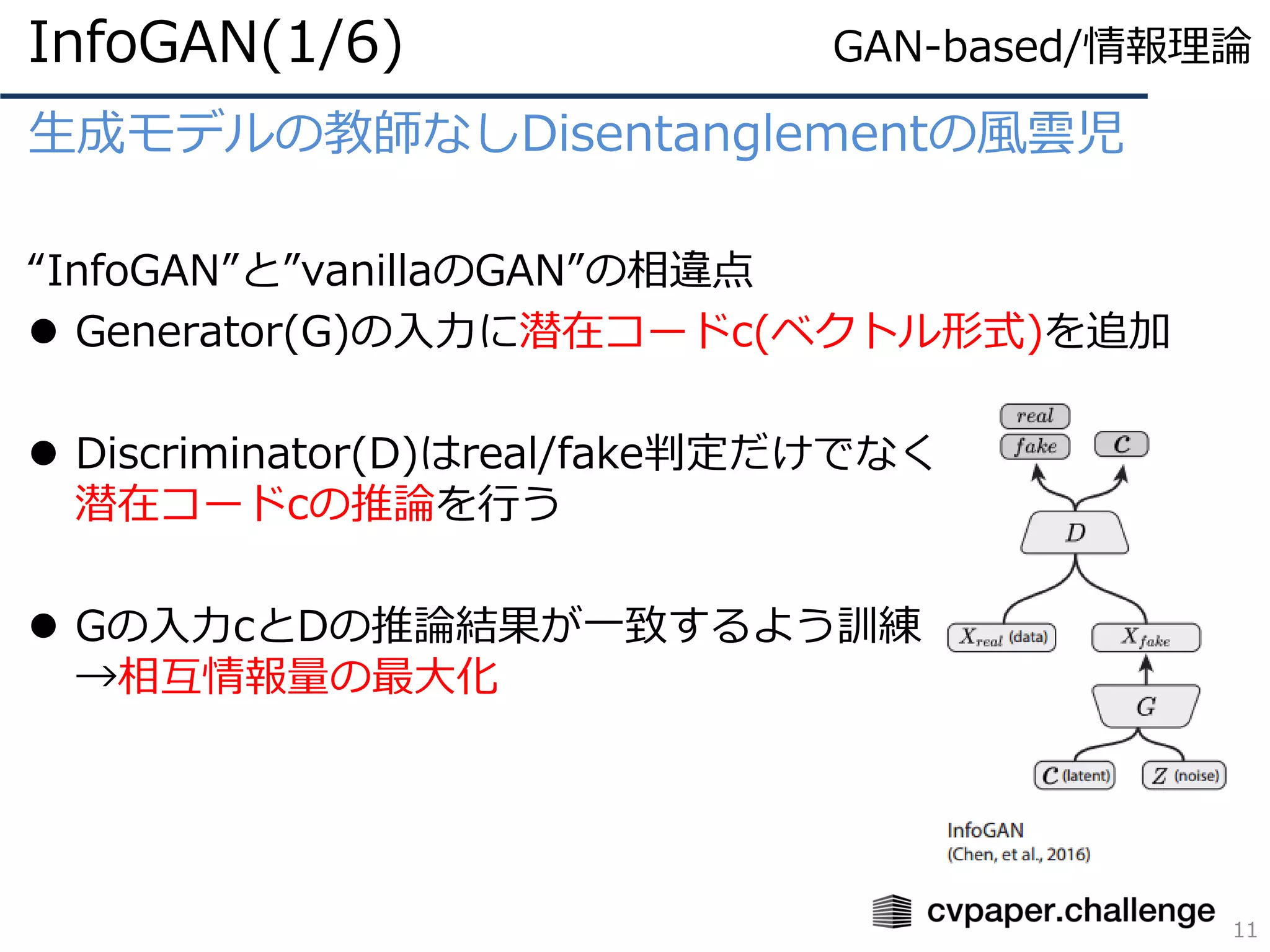
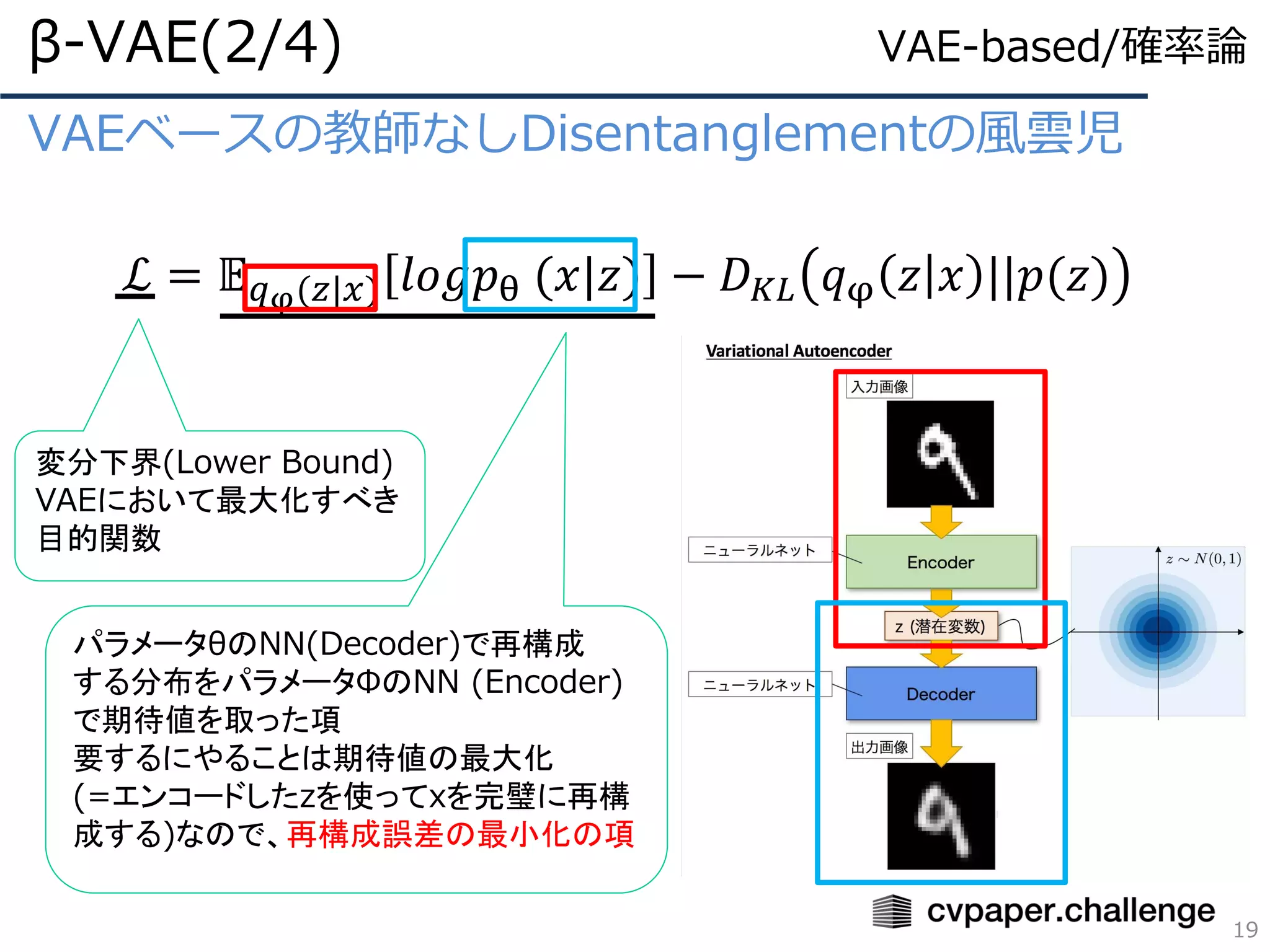
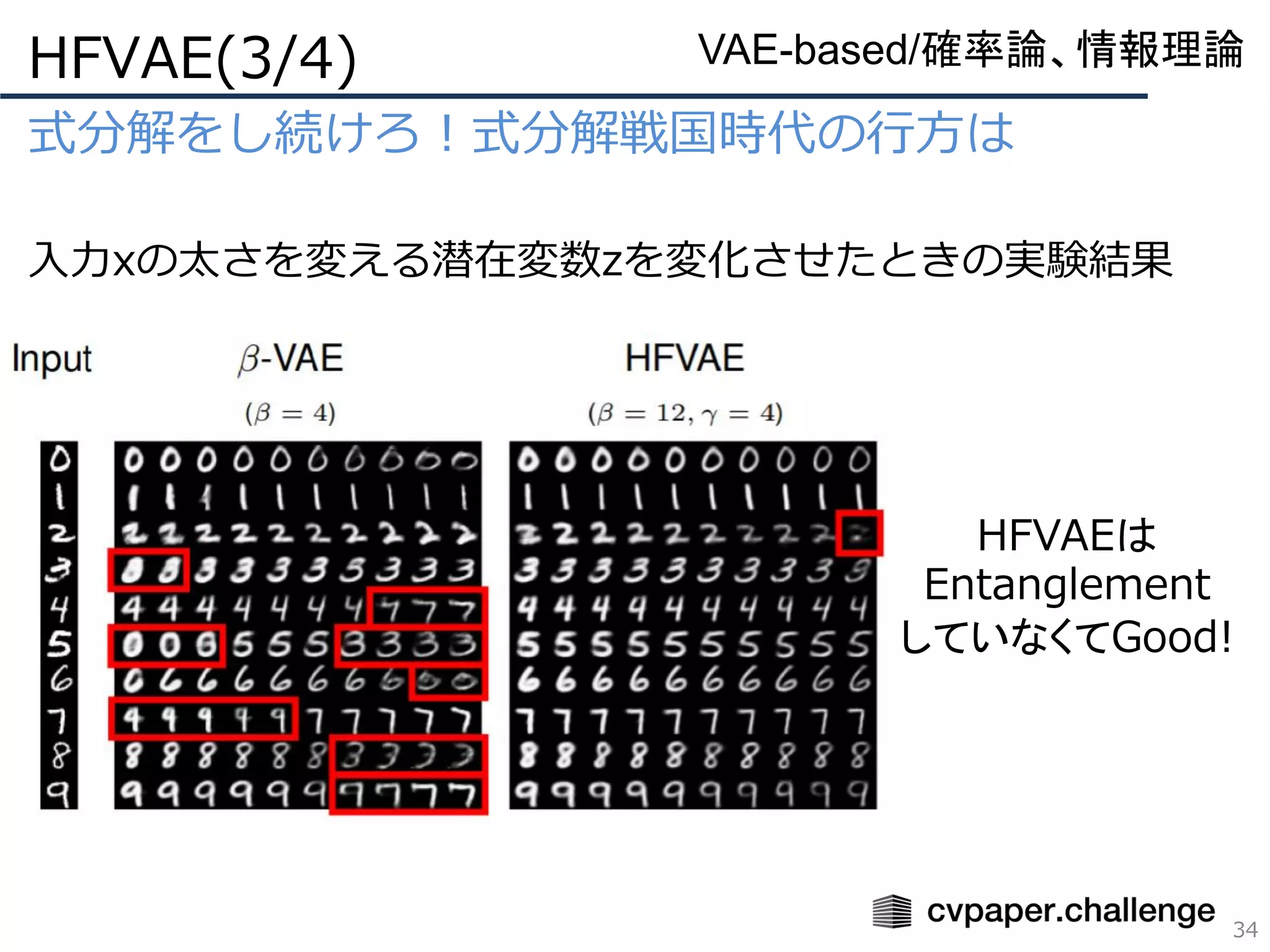
VAEベースの教師なしDisentanglementの風雲児
ℒ = 𝔼𝑞φ(𝑧|𝑥) 𝑙𝑜𝑔𝑝θ (𝑥|𝑧) − 𝐷 𝐾𝐿 𝑞φ 𝑧 𝑥 ||𝑝(𝑧)
β-VAE(2/4)
19
変分下界(Lower Bound)
VAEにおいて最大化すべき
目的関数
パラメータθのNN(Decoder)で再構成
する分布をパラメータΦのNN (Encoder)
で期待値を取った項
要するにやることは期待値の最大化
(=エンコードしたzを使ってxを完璧に再構
成する)なので、再構成誤差の最小化の項
VAE-based/確率論
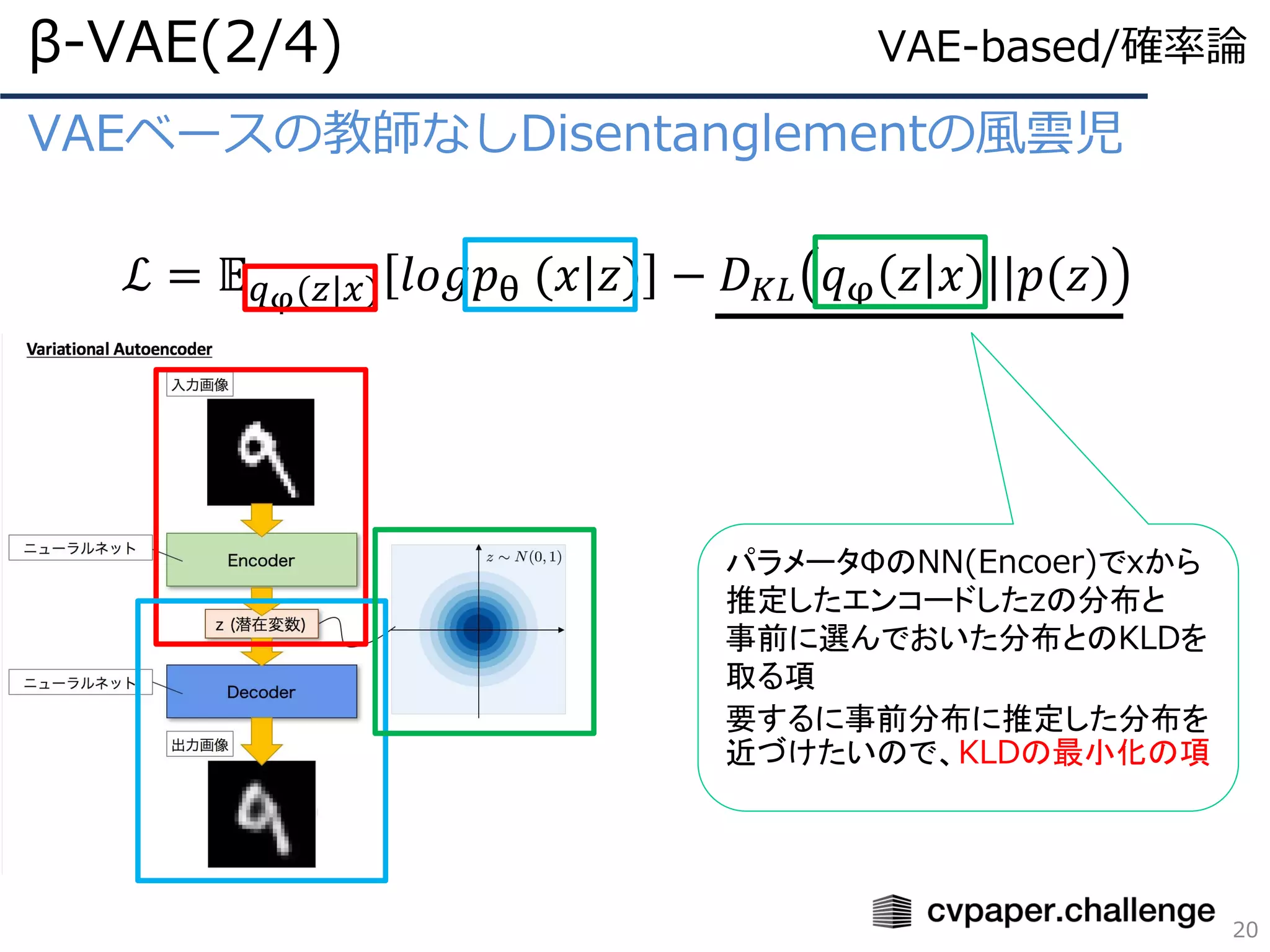
- 20.
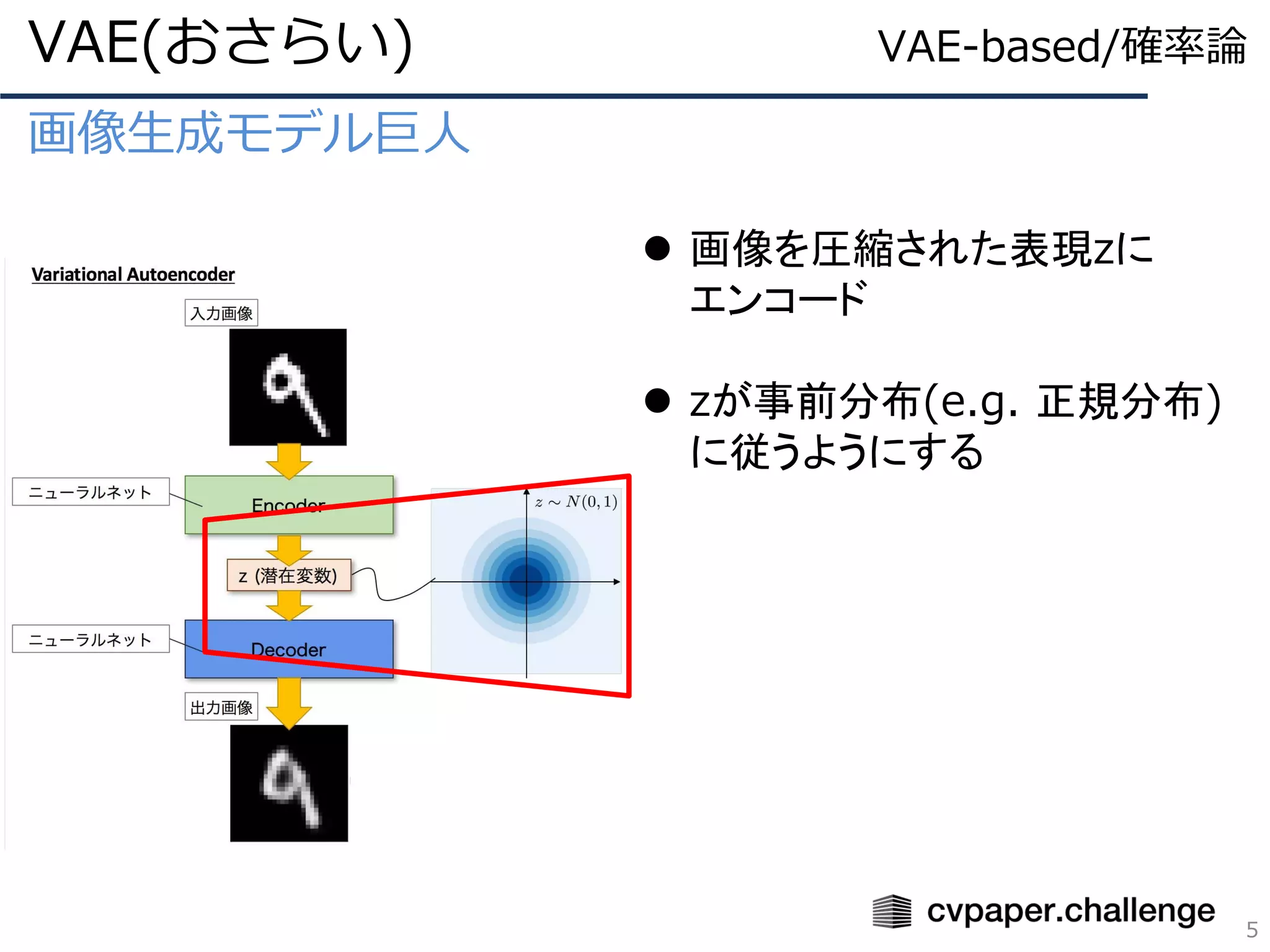
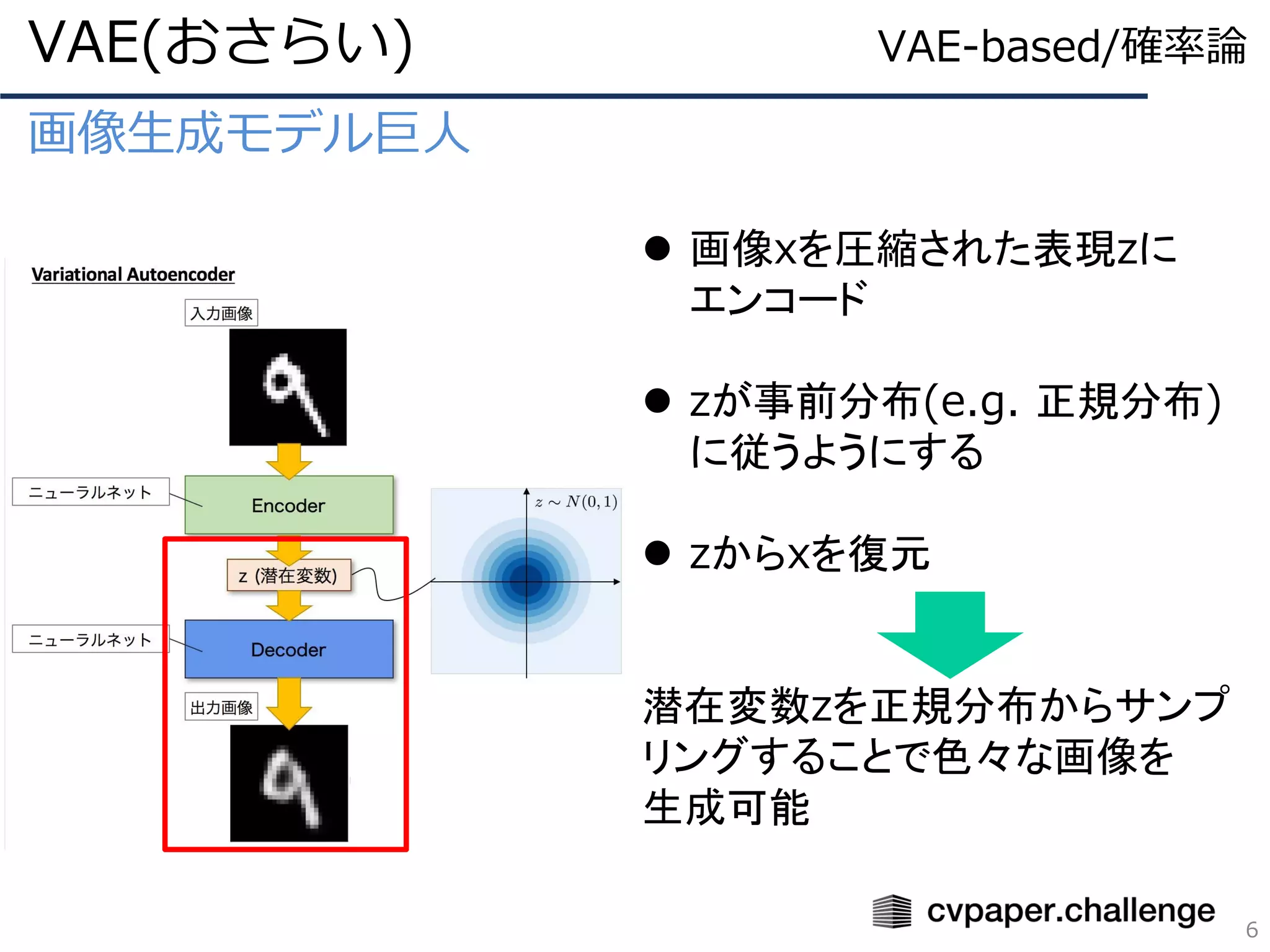
VAEベースの教師なしDisentanglementの風雲児
ℒ = 𝔼𝑞φ(𝑧|𝑥) 𝑙𝑜𝑔𝑝θ (𝑥|𝑧) − 𝐷 𝐾𝐿 𝑞φ 𝑧 𝑥 ||𝑝(𝑧)
β-VAE(2/4)
20
パラメータΦのNN(Encoer)でxから
推定したエンコードしたzの分布と
事前に選んでおいた分布とのKLDを
取る項
要するに事前分布に推定した分布を
近づけたいので、KLDの最小化の項
VAE-based/確率論
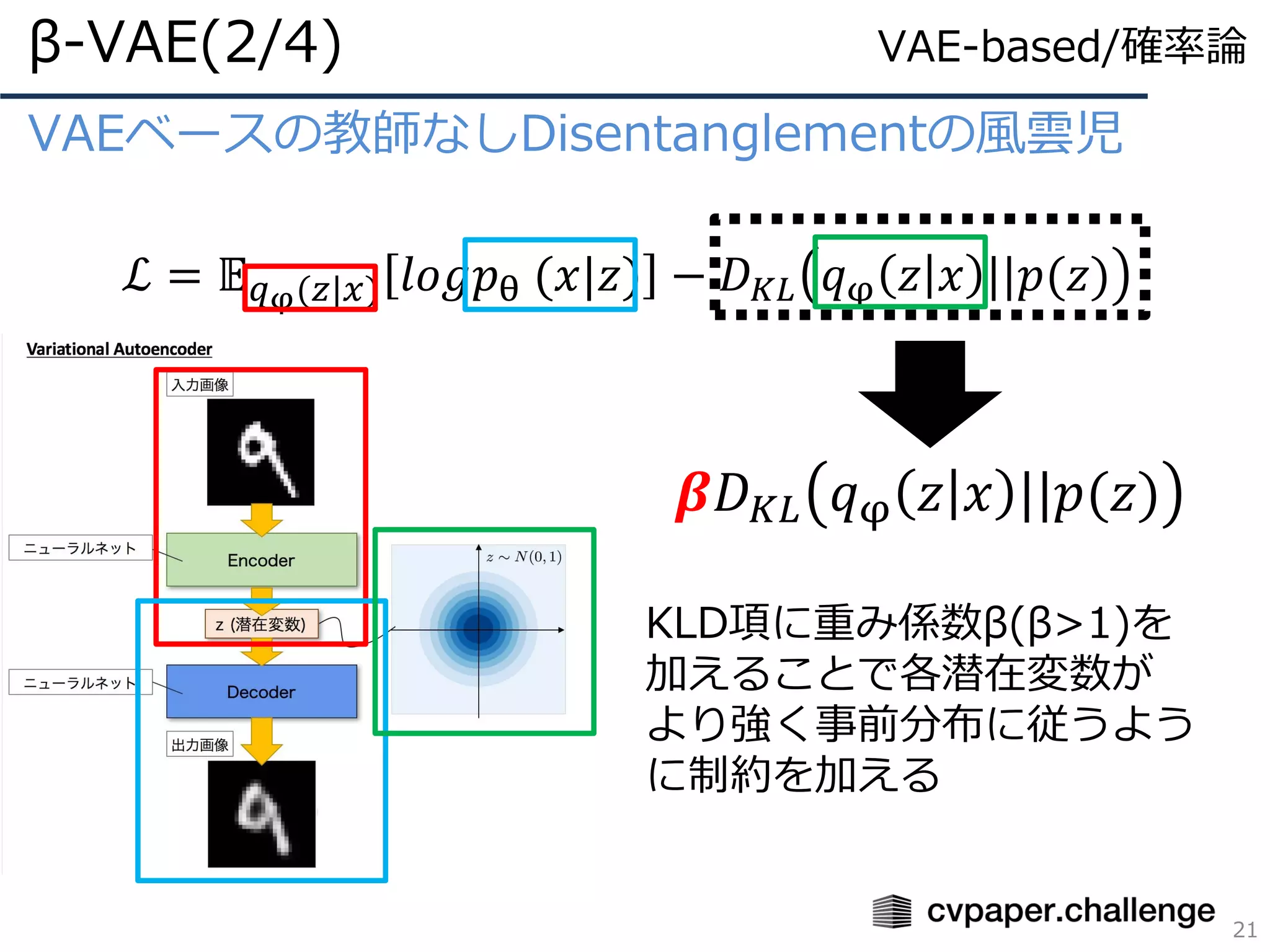
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
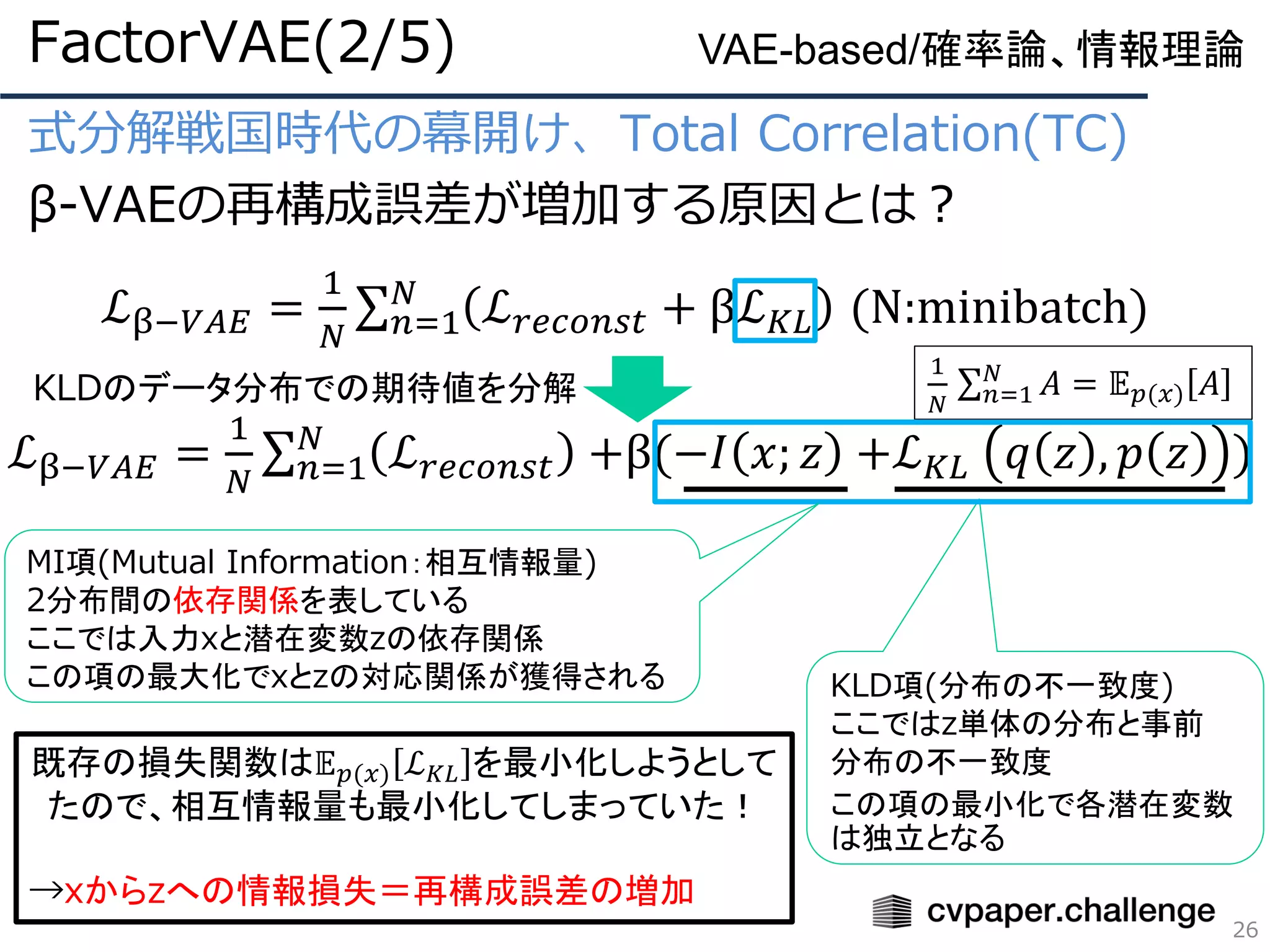
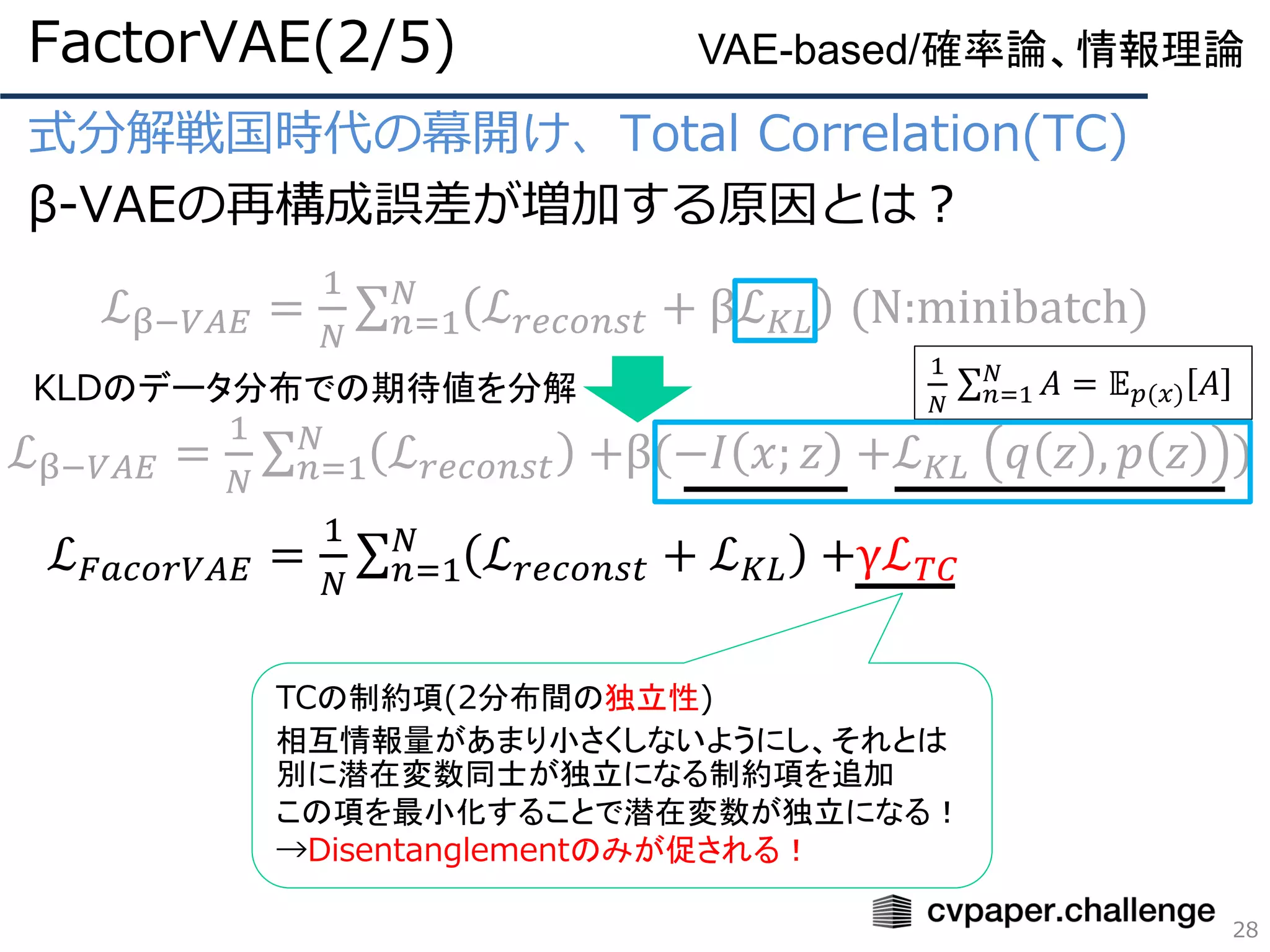
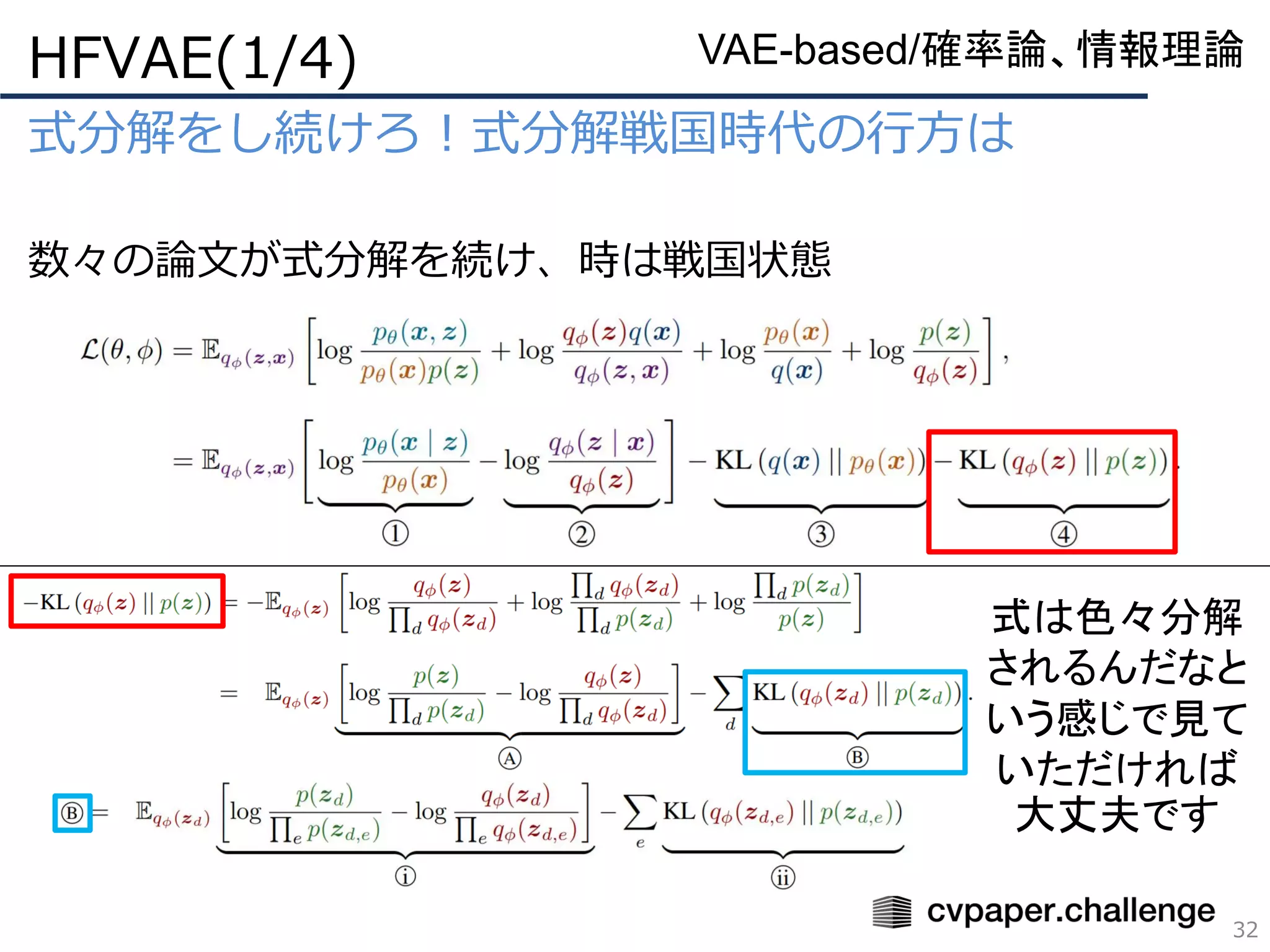
式分解戦国時代の幕開け、Total Correlation(TC)
β-VAEの再構成誤差が増加する原因とは?
ℒβ−𝑉𝐴𝐸 =
1
𝑁
σ𝑛=1
𝑁
ℒ 𝑟𝑒𝑐𝑜𝑛𝑠𝑡 +β(−𝐼 𝑥; 𝑧 +ℒ 𝐾𝐿 𝑞 𝑧 , 𝑝 𝑧 )
FactorVAE(2/5)
26
VAE-based/確率論、情報理論
KLD項(分布の不一致度)
ここではz単体の分布と事前
分布の不一致度
この項の最小化で各潜在変数
は独立となる
ℒβ−𝑉𝐴𝐸 =
1
𝑁
σ 𝑛=1
𝑁
ℒ 𝑟𝑒𝑐𝑜𝑛𝑠𝑡 + βℒ 𝐾𝐿 (N:minibatch)
KLDのデータ分布での期待値を分解
1
𝑁
σ 𝑛=1
𝑁
𝐴 = 𝔼 𝑝(𝑥) 𝐴
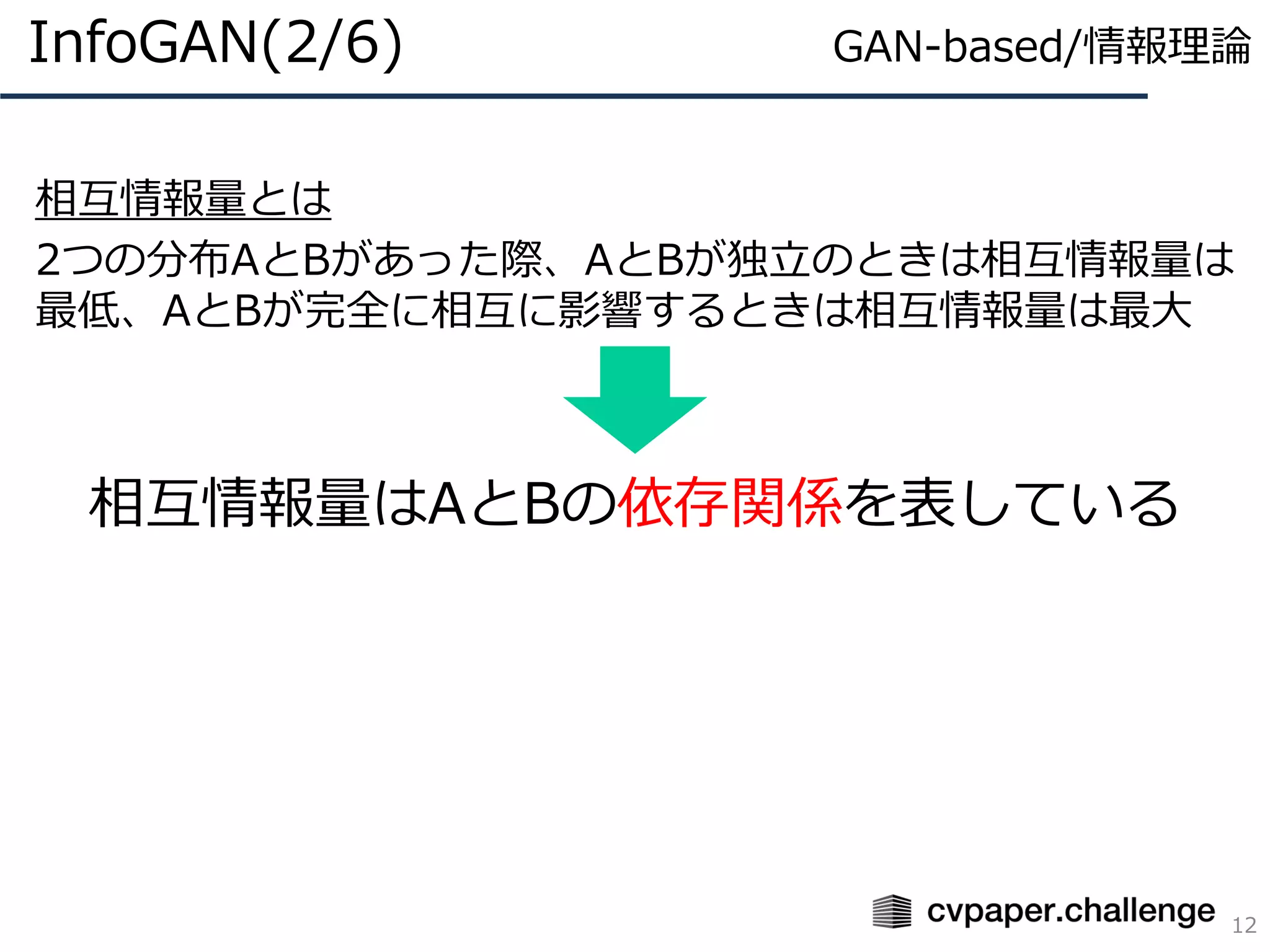
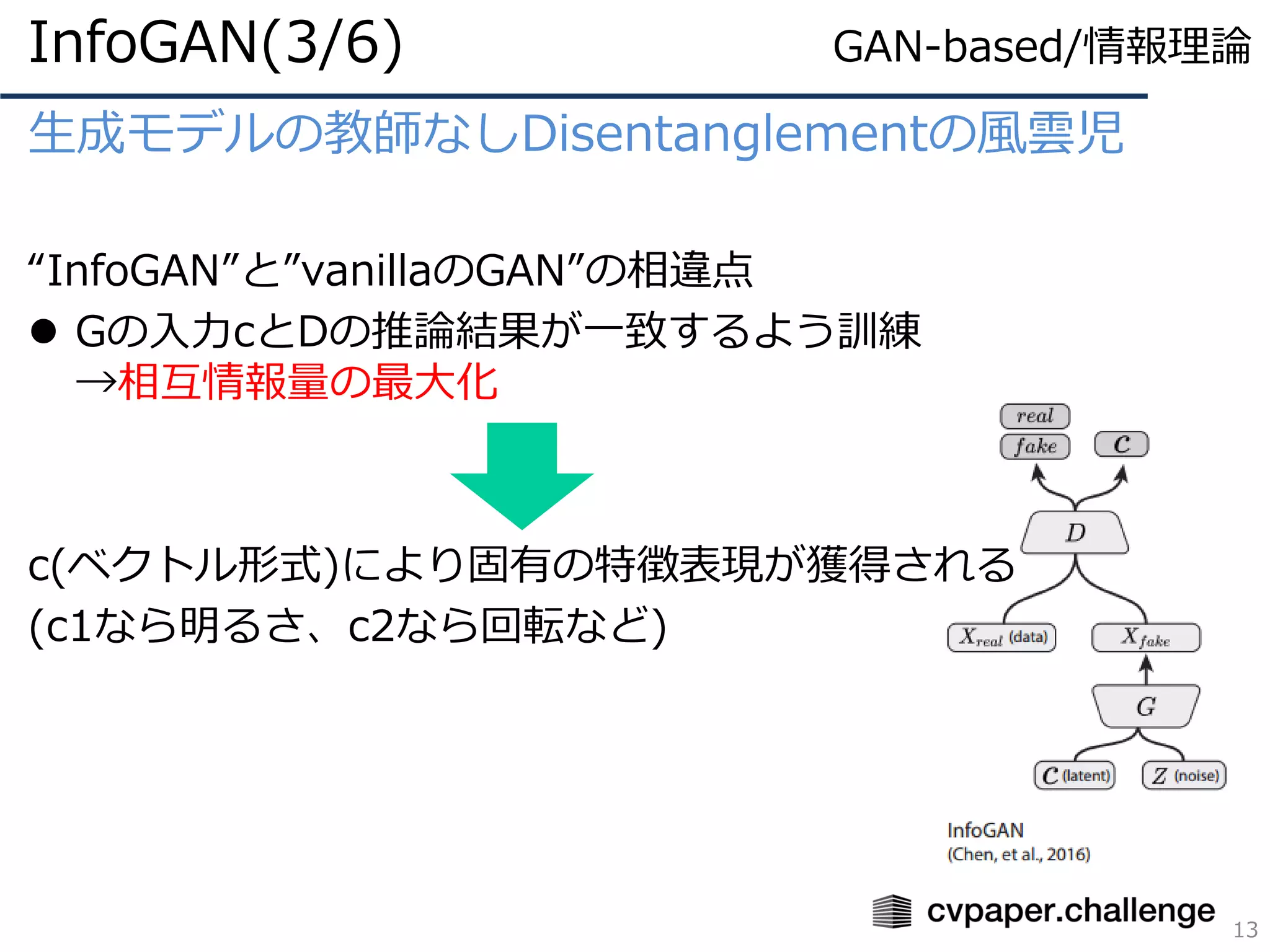
MI項(Mutual Information:相互情報量)
2分布間の依存関係を表している
ここでは入力xと潜在変数zの依存関係
この項の最大化でxとzの対応関係が獲得される
既存の損失関数は𝔼 𝑝(𝑥) ℒ 𝐾𝐿 を最小化しようとして
たので、相互情報量も最小化してしまっていた!
→xからzへの情報損失=再構成誤差の増加
- 27.
- 28.
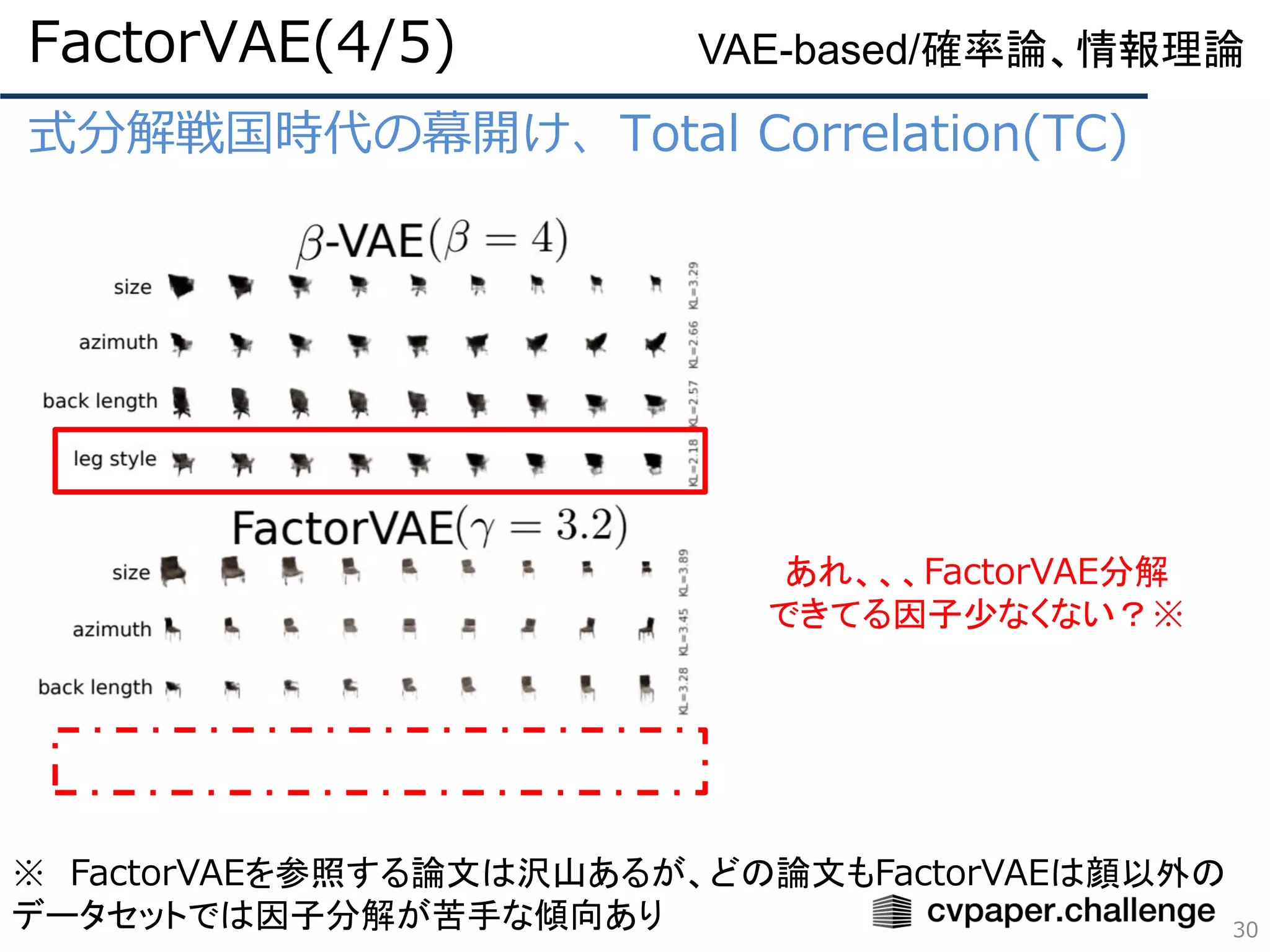
式分解戦国時代の幕開け、Total Correlation(TC)
β-VAEの再構成誤差が増加する原因とは?
ℒ 𝐹𝑎𝑐𝑜𝑟𝑉𝐴𝐸=
1
𝑁
σ 𝑛=1
𝑁
ℒ 𝑟𝑒𝑐𝑜𝑛𝑠𝑡 + ℒ 𝐾𝐿 +γℒ 𝑇𝐶
FactorVAE(2/5)
28
VAE-based/確率論、情報理論
ℒβ−𝑉𝐴𝐸 =
1
𝑁
σ 𝑛=1
𝑁
ℒ 𝑟𝑒𝑐𝑜𝑛𝑠𝑡 + βℒ 𝐾𝐿 (N:minibatch)
KLDのデータ分布での期待値を分解
1
𝑁
σ 𝑛=1
𝑁
𝐴 = 𝔼 𝑝(𝑥) 𝐴
TCの制約項(2分布間の独立性)
相互情報量があまり小さくしないようにし、それとは
別に潜在変数同士が独立になる制約項を追加
この項を最小化することで潜在変数が独立になる!
→Disentanglementのみが促される!
ℒβ−𝑉𝐴𝐸 =
1
𝑁
σ 𝑛=1
𝑁
ℒ 𝑟𝑒𝑐𝑜𝑛𝑠𝑡 +β(−𝐼 𝑥; 𝑧 +ℒ 𝐾𝐿 𝑞 𝑧 , 𝑝 𝑧 )
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
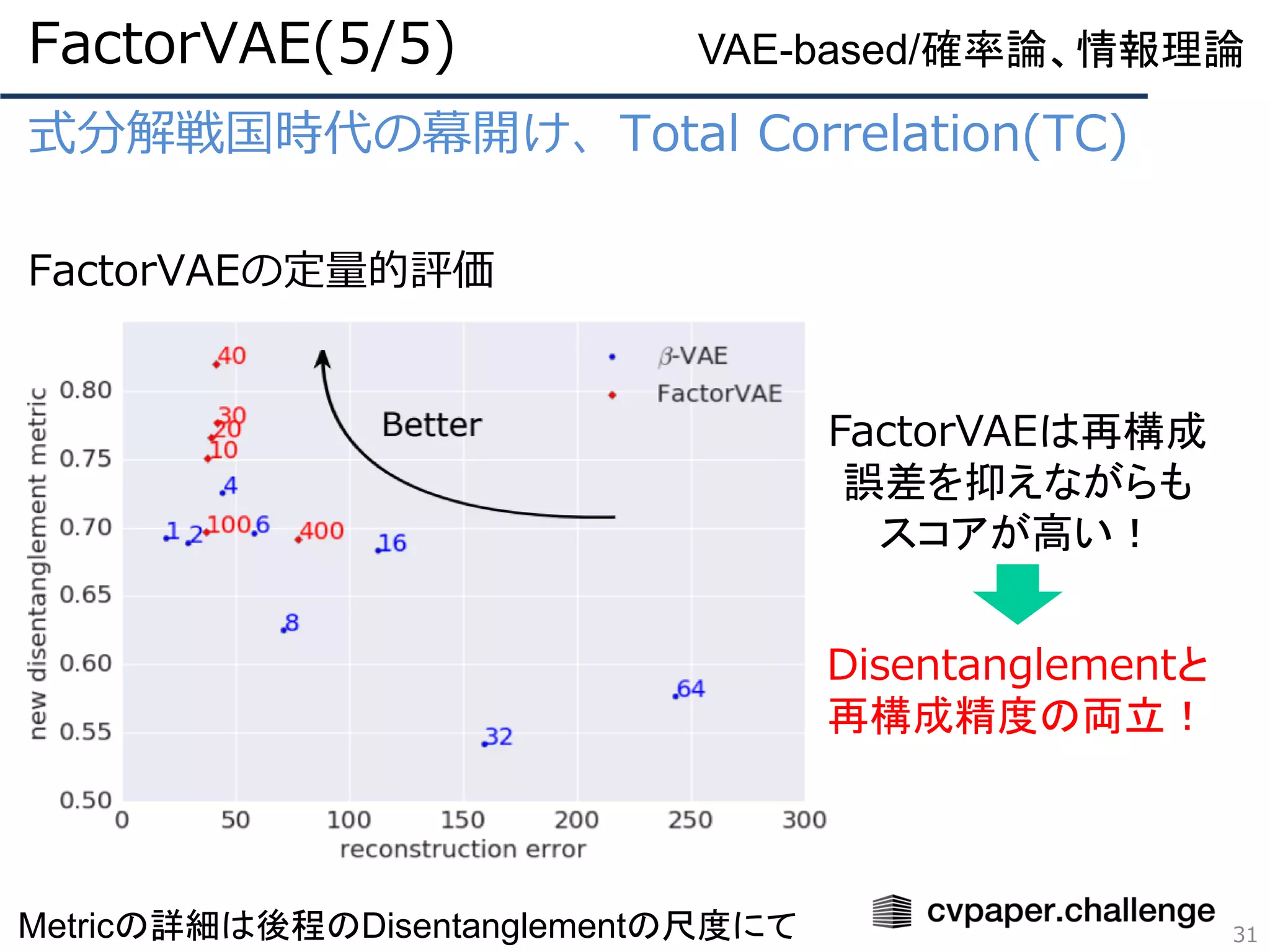
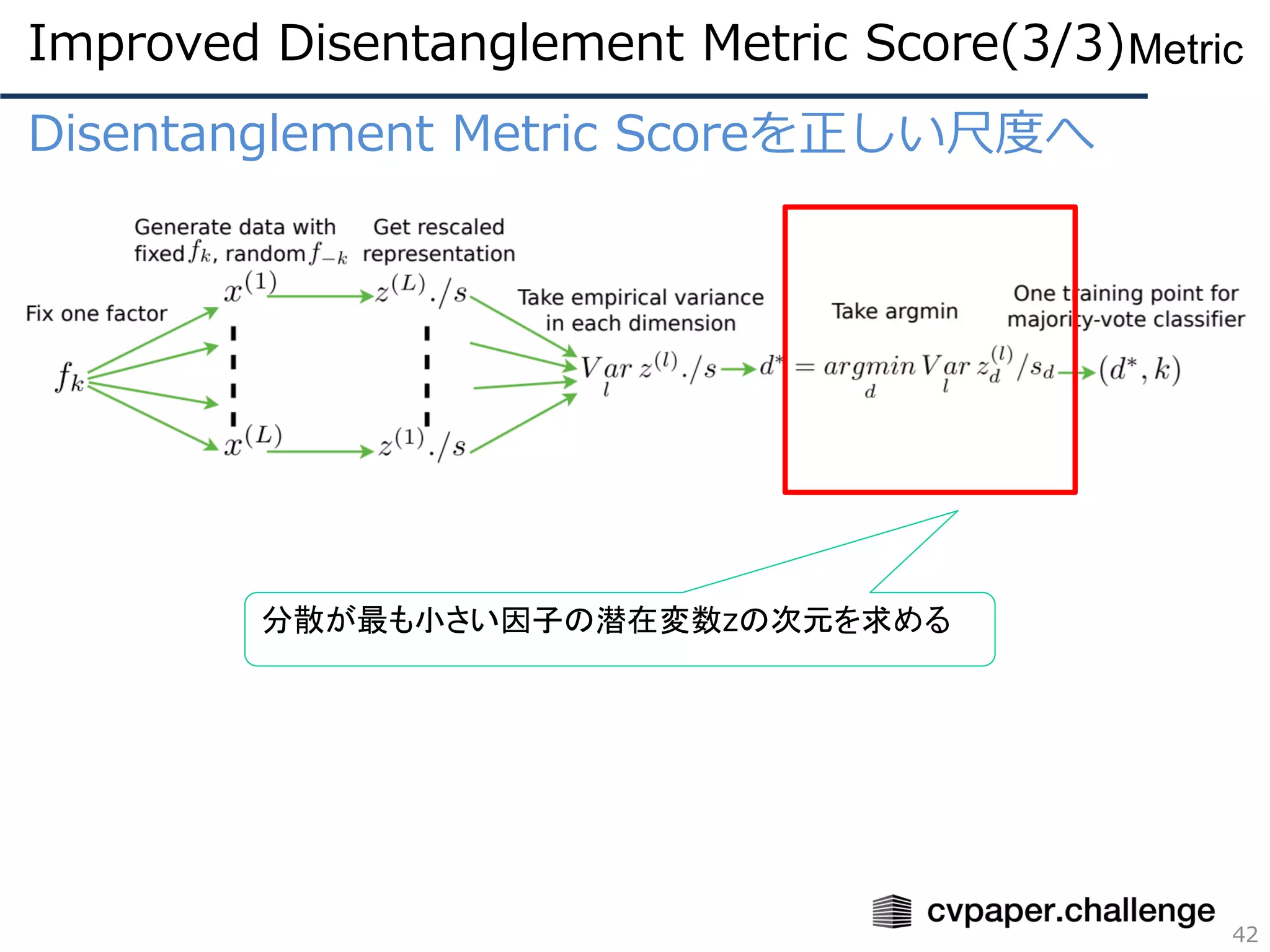
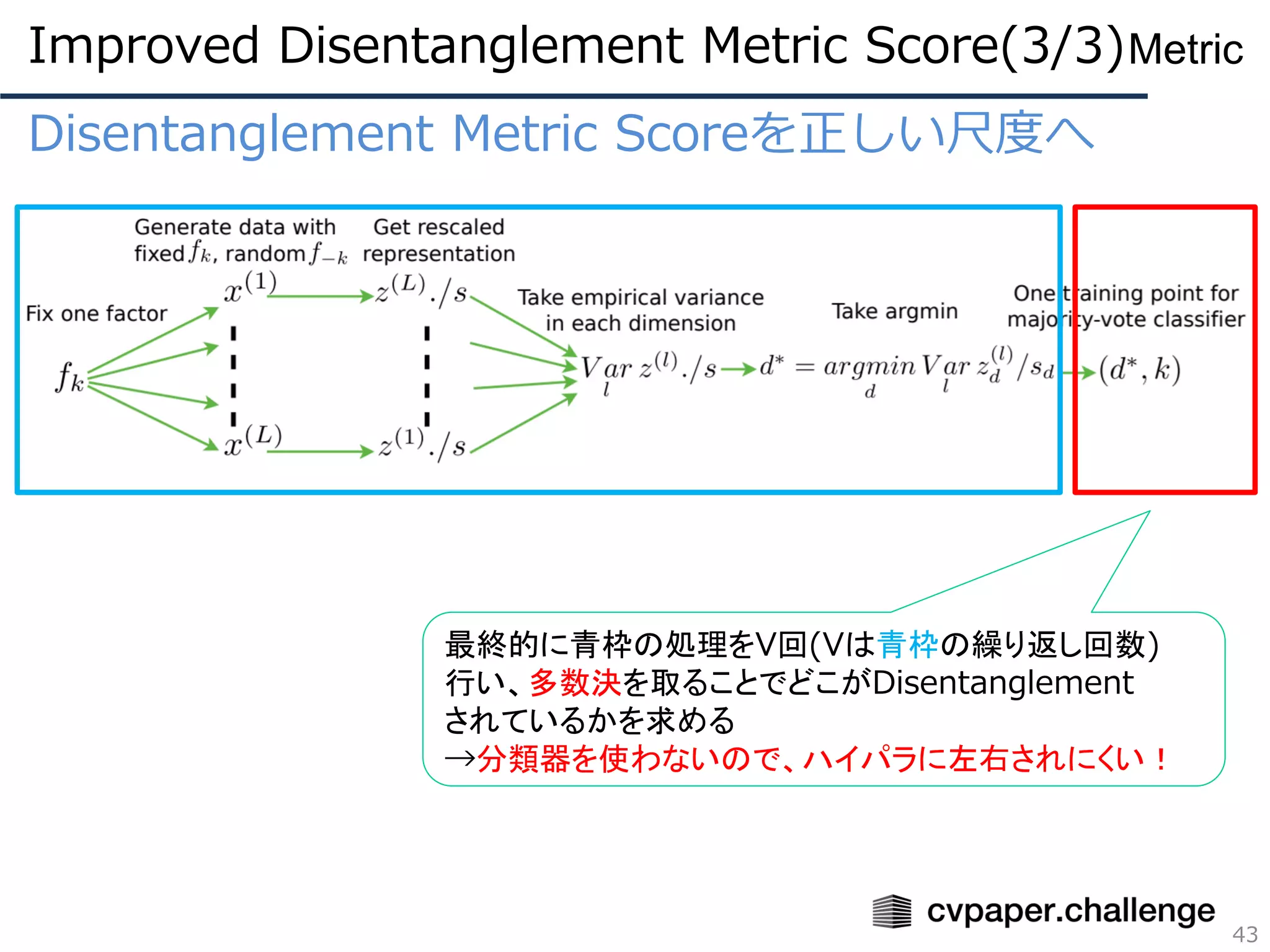
Disentanglement Metric Scoreを正しい尺度へ
DisentanglementMetric Scoreを改良した評価尺度について
⚫ FactorVAEで提案された評価尺度
⚫ 分解される因子(e.g. 回転、太さ)があらかじめわかっている
ときのみ使用可能
⚫ クラス分類ではなく多数決で因子を決定することでハイパラ
に敏感でなくなった
⚫ 旧手法に比べてトータルの速度は210倍~1800倍!!※
(旧手法:30分、本手法:数秒)
39
Metric
※ 旧手法はクラス分類器の訓練が必要なので遅い
Improved Disentanglement Metric Score(2/3)
- 40.
- 41.
- 42.
- 43.
- 44.
乱立するDisentanglement Metric
⚫ SAP(Separated Attribute Predictability)
線形回帰を行うことでハイパラに依存しないMetricの提案
(Factor VAE Metric以前に登場)
⚫ Modularity
ModularityとExplicitnessを評価
Modularity:1つの因子に分解されているか
Explicitness:ロジスティック回帰で容易に回帰できるか
→容易に回帰可能なら説明性も高いという解釈
その他のDisentanglement Metric
44
Metric
- 45.
乱立するDisentanglement Metric
⚫ DCIDisentanglement (論文中では名称なし)
Disentanglement、Completeness、Informativenessを評価
Lasso回帰またはランダムフォレスト分類器を用いる
Disentanglement:因子分類において有益な潜在変数
Completeness:分類された因子のエントロピーの差
→どれだけ因子分解がしっかり行われているか
Informativeness:分類器の予測誤差
→正しくDisentanglementできているか
⚫ MIG (Mutual Information Gap)
相互情報量の最も高い因子と次点の因子の差※
現在最新のDisentanglementのMetric
※ 相互情報量は高いほどDisentanglementが出来ている
その他のDisentanglement Metric
45
Metric
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
- 72.
- 73.
- 74.
- 75.
- 76.
- 77.
- 78.
- 79.










![VAEベースの教師なしDisentanglementの風雲児
“VAE”と”β-VAE”の相違点
⚫ KLダイバージェンス(KLD)
に重み係数βを追加
各潜在変数がそれぞれ正規分布に
落ちるよう強く制約をかける
ことで各潜在変数が独立になる
β-VAE(1/4)
18[2] Yosua Bengio et al. hogehoge
[5] Yosua Bengio et al. hogehoge
VAE-based/確率論](https://image.slidesharecdn.com/magurodisentanglementverdistribution-191005033805/75/Disentanglement-Survey-Can-You-Explain-How-Much-Are-Generative-models-Disentangled-18-2048.jpg)



![式分解戦国時代の幕開け、Total Correlation(TC)
“β-VAE”の問題点
⚫ KLD項に重みを掛けると再構成誤差が軽視される
→画像がぼやけやすくなる
再構成誤差に影響を与えないようにしよう!
FactorVAE(1/5)
25[6] Yosua Bengio et al. hogehoge
InfoGANは訓練が安定せず実用的ではない
VAE-based/確率論、情報理論](https://image.slidesharecdn.com/magurodisentanglementverdistribution-191005033805/75/Disentanglement-Survey-Can-You-Explain-How-Much-Are-Generative-models-Disentangled-25-2048.jpg)























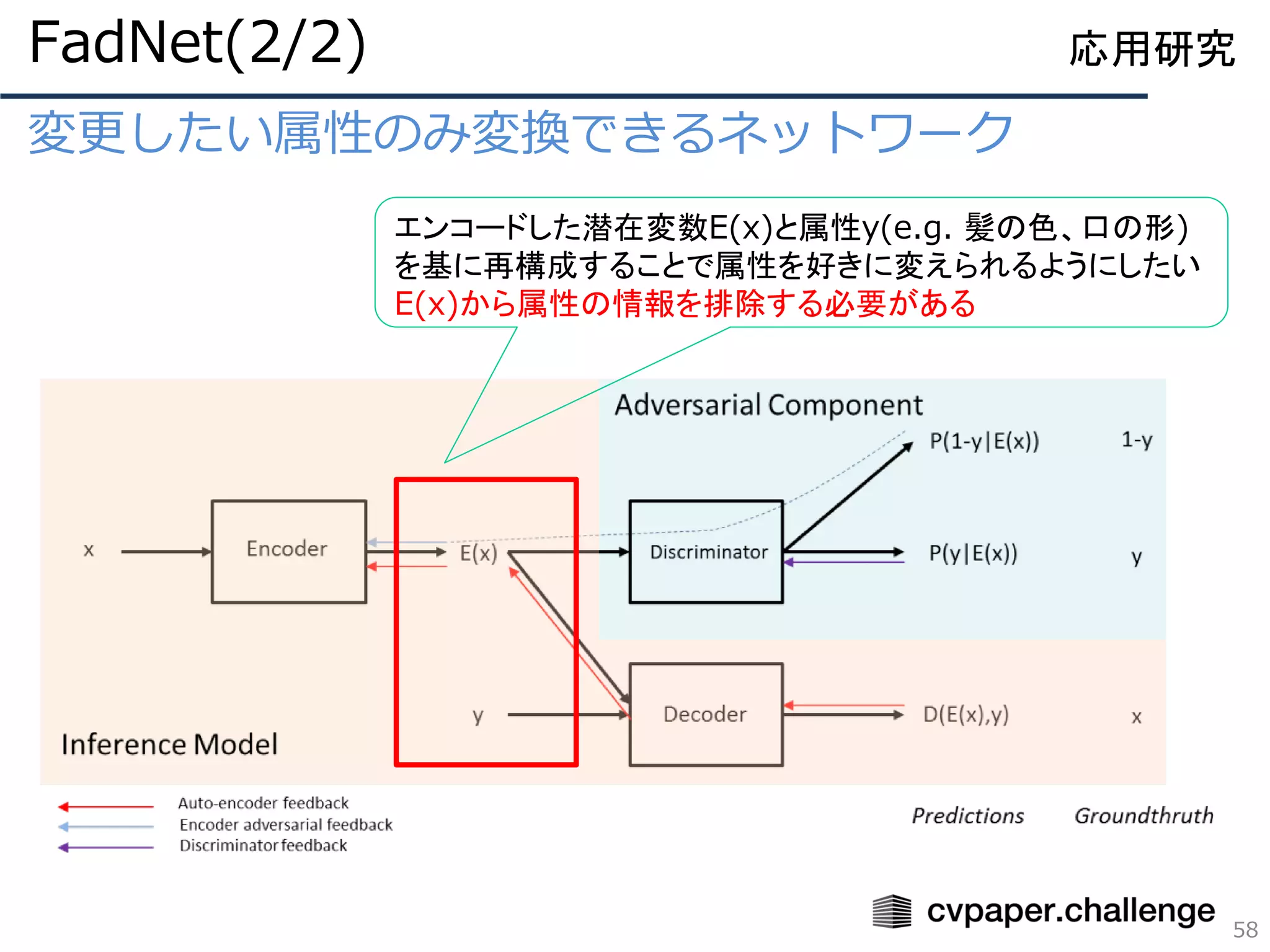
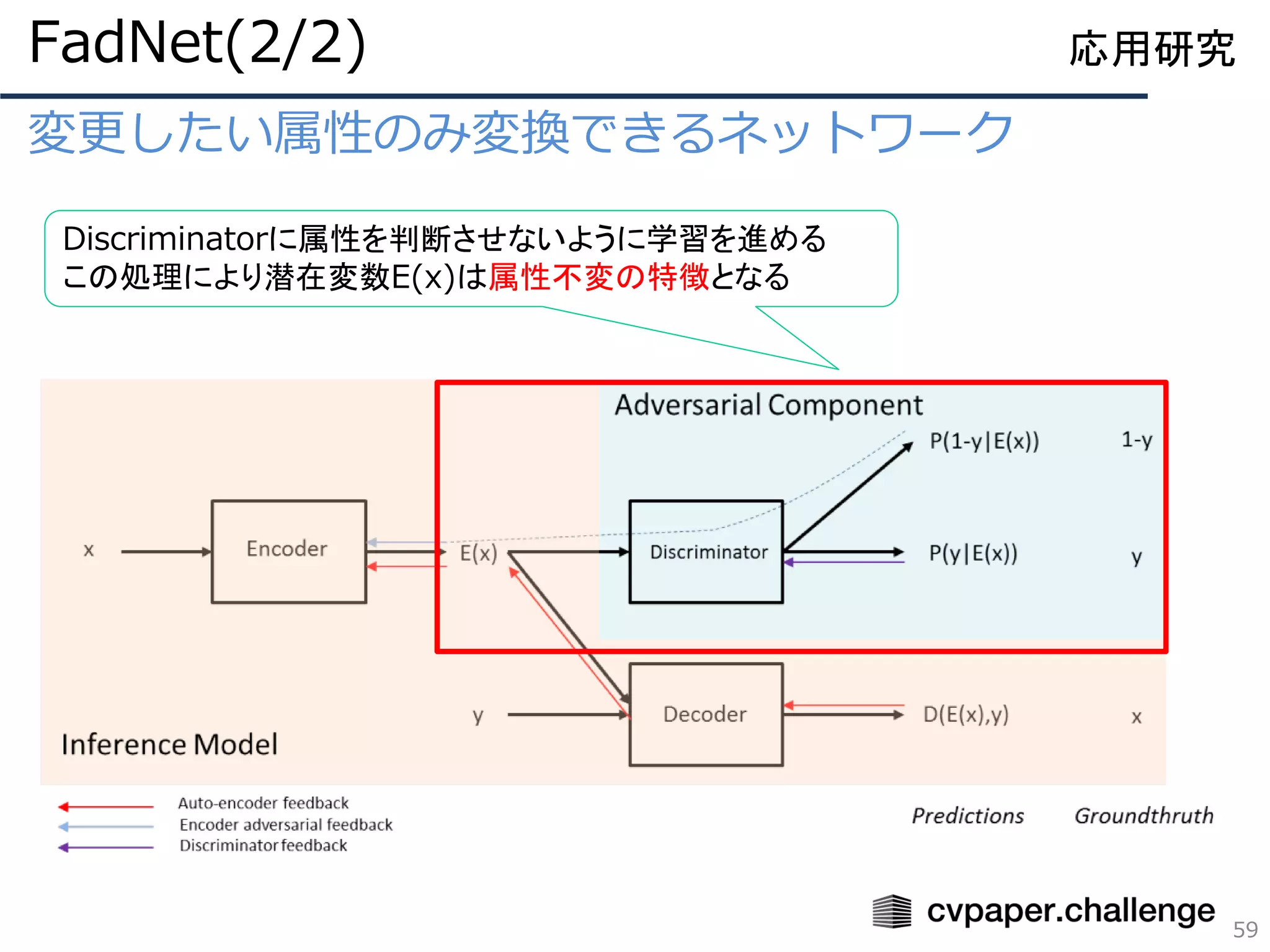
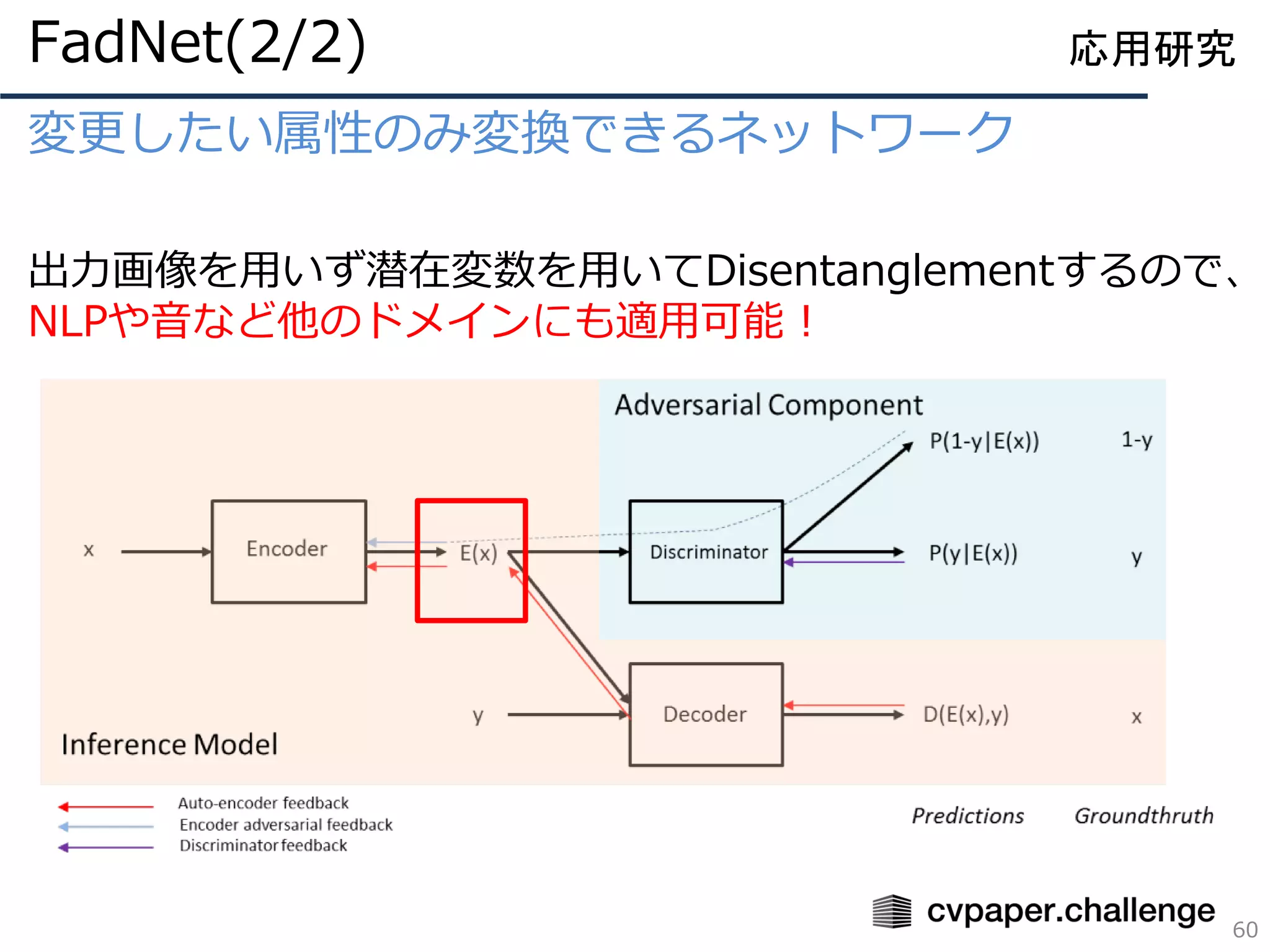
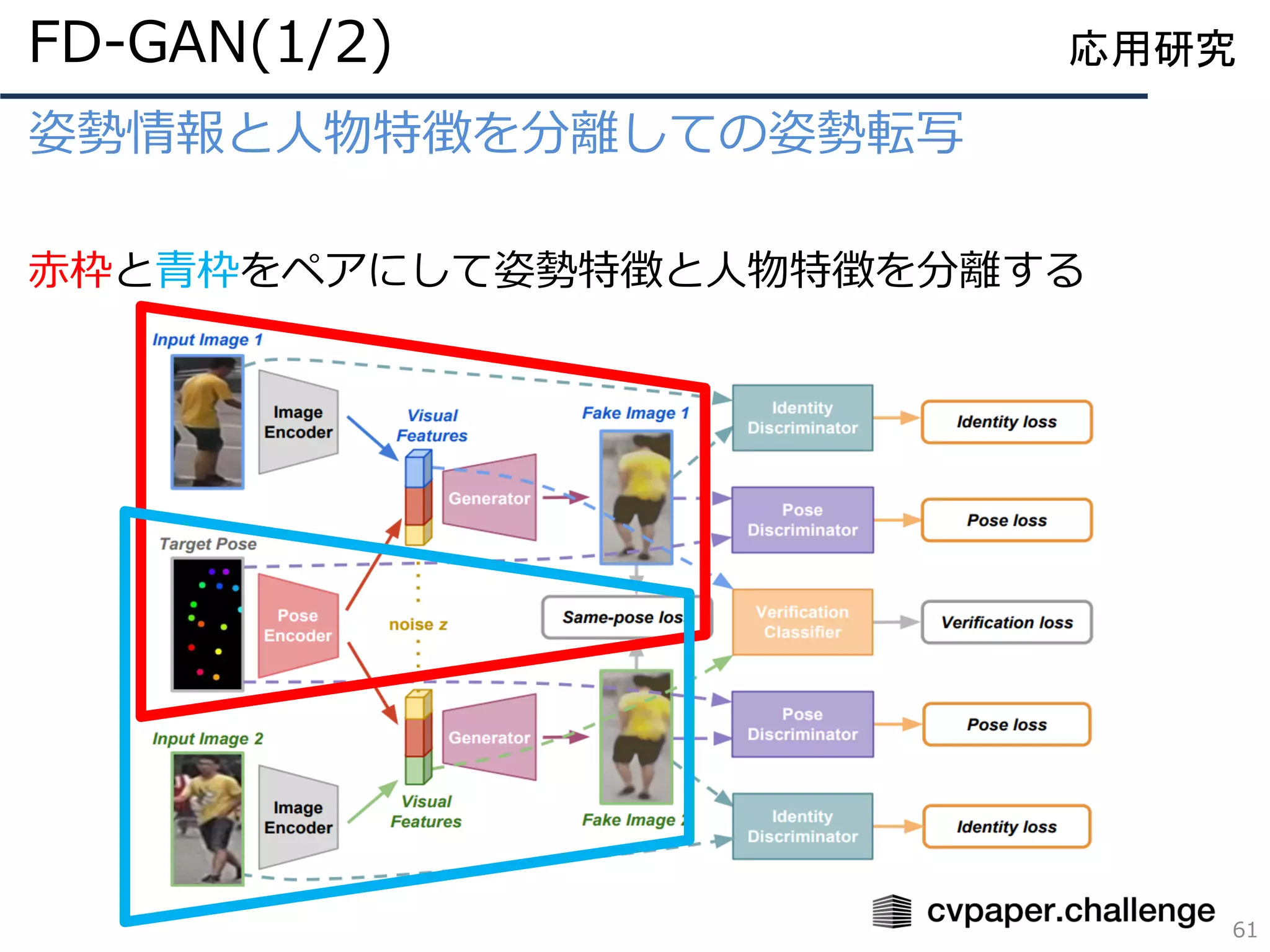
![姿勢情報と人物特徴を分離しての姿勢転写
62
応用研究FD-GAN(2/2)
既存手法[18, 19]に対して
FD-GANは正しく転写できている
しかし、まだまだ鞄は課題ありか](https://image.slidesharecdn.com/magurodisentanglementverdistribution-191005033805/75/Disentanglement-Survey-Can-You-Explain-How-Much-Are-Generative-models-Disentangled-62-2048.jpg)