関連研究: [Ganin+ 2014]
UnsupervisedDomain Adaptation by Backpropagation (RevGrad)
DiscriminatorとFeature Extractorをbackpropで同時に学習する
Gradient Reversal Layer (GRL)を提案
[Ganin+ 2014] Y. Ganin, V. Lempitsky. Unsupervised Domain Adaptation by Backpropagation. ICML2015
• Forward:恒等写像
• Backward:勾配の符号を反転
11.
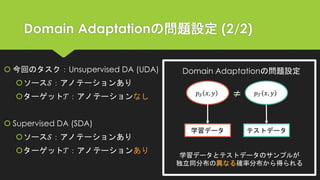
提案手法のアイデア
従来手法の欠点
ドメイン不変の特徴量が識別性能を意味するわけではない
e.g. 𝒯のbackpackと𝒮のcarの特徴量が近くなる写像でもドメイン不変
は満たしている
Supervised DA (SDA)では異なるドメイン・同じクラスの特徴量が
近くなるように学習する手法が提案済み [Motiian+ 2017]
⇒ UDAでも同様のアプローチが可能ならば精度が向上するのでは?
[Motiian+ 2017] S. Motiian, M. Piccirilli, D. A. Adjeroh, G. Doretto; Unified Deep Supervised Domain Adaptation and Generalization. ICCV2017.
12.
関連研究:[Motiian+ 2017]
Unified DeepSupervised Domain Adaptation and Generalization
[Motiian+ 2017] S. Motiian, M. Piccirilli, D. A. Adjeroh, G. Doretto; Unified Deep Supervised Domain Adaptation and Generalization. ICCV2017.
異なるドメイン・異なるクラス:遠ざけたい異なるドメイン・同じクラス:近づけたい







![関連研究: [Tzeng+ 2017]
Adversarial Discriminative Domain Adaptation (ADDA)
Pre-training, Adversarial Adaptation, Testingの3ステップで構成
Fix
Fix
Fix
𝒮のサンプルでSource CNN と
Classifierを学習
Discriminatorが𝒮, 𝒯どちらのサンプルか
見分けられないようにTarget CNNと
Discriminatorを敵対的学習
Target CNNとClassifierを接続して
𝒯のサンプルで評価
[Tzeng+ 2017] E. Tzeng, J. Hoffman, T. Darrell, K. Saenko. Adversarial Discriminative Domain Adaptation. CVPR2017](https://image.slidesharecdn.com/20180728denamstn-180728043709/85/Learning-Semantic-Representations-for-Unsupervised-Domain-Adaptation-9-320.jpg)
![関連研究: [Ganin+ 2014]
Unsupervised Domain Adaptation by Backpropagation (RevGrad)
DiscriminatorとFeature Extractorをbackpropで同時に学習する
Gradient Reversal Layer (GRL)を提案
[Ganin+ 2014] Y. Ganin, V. Lempitsky. Unsupervised Domain Adaptation by Backpropagation. ICML2015
• Forward:恒等写像
• Backward:勾配の符号を反転](https://image.slidesharecdn.com/20180728denamstn-180728043709/85/Learning-Semantic-Representations-for-Unsupervised-Domain-Adaptation-10-320.jpg)
![提案手法のアイデア
従来手法の欠点
ドメイン不変の特徴量が識別性能を意味するわけではない
e.g. 𝒯のbackpackと𝒮のcarの特徴量が近くなる写像でもドメイン不変
は満たしている
Supervised DA (SDA)では異なるドメイン・同じクラスの特徴量が
近くなるように学習する手法が提案済み [Motiian+ 2017]
⇒ UDAでも同様のアプローチが可能ならば精度が向上するのでは?
[Motiian+ 2017] S. Motiian, M. Piccirilli, D. A. Adjeroh, G. Doretto; Unified Deep Supervised Domain Adaptation and Generalization. ICCV2017.](https://image.slidesharecdn.com/20180728denamstn-180728043709/85/Learning-Semantic-Representations-for-Unsupervised-Domain-Adaptation-11-320.jpg)
![関連研究:[Motiian+ 2017]
Unified Deep Supervised Domain Adaptation and Generalization
[Motiian+ 2017] S. Motiian, M. Piccirilli, D. A. Adjeroh, G. Doretto; Unified Deep Supervised Domain Adaptation and Generalization. ICCV2017.
異なるドメイン・異なるクラス:遠ざけたい異なるドメイン・同じクラス:近づけたい](https://image.slidesharecdn.com/20180728denamstn-180728043709/85/Learning-Semantic-Representations-for-Unsupervised-Domain-Adaptation-12-320.jpg)
















![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]AdaShare: Learning What To Share For Efficient Deep Multi-Task Learning](https://cdn.slidesharecdn.com/ss_thumbnails/dl1211-191213002847-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]RobustNet: Improving Domain Generalization in Urban- Scene Segmentatio...](https://cdn.slidesharecdn.com/ss_thumbnails/20210625robustnetlin-210625020332-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]An Iterative Framework for Self-supervised Deep Speaker Representatio...](https://cdn.slidesharecdn.com/ss_thumbnails/20220216dlaniterativeframeworkforself-superviseddeepspeakerrepresentationlearning-220218040109-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]A Higher-Dimensional Representation for Topologically Varying Neural R...](https://cdn.slidesharecdn.com/ss_thumbnails/ahigher-dimensionalrepresentationfortopologicallyvaryingneuralradiancefields1-210924021911-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]SoftTriple Loss: Deep Metric Learning Without Triplet Sampling (ICCV2019)](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20190920dlhack-190920011134-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会] “Asymmetric Tri-training for Unsupervised Domain Adaptation (ICML2017...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20170728-170728025901-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]ドメイン転移と不変表現に関するサーベイ](https://cdn.slidesharecdn.com/ss_thumbnails/20190614iwasawa-190614005939-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Unsupervised Cross-Domain Image Generation](https://cdn.slidesharecdn.com/ss_thumbnails/readingpaper20170310-170310051823-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]High-Fidelity Image Generation with Fewer Labels](https://cdn.slidesharecdn.com/ss_thumbnails/190315dlseminargan-190315004124-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Adversarial Learning for Zero-shot Domain Adaptation](https://cdn.slidesharecdn.com/ss_thumbnails/20200925lin-200925035639-thumbnail.jpg?width=640&height=640&fit=bounds)





![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Geometric Unsupervised Domain Adaptation for Semantic Segmentation](https://cdn.slidesharecdn.com/ss_thumbnails/20220121gudalin-220121050547-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Learning Task Informed Abstractions](https://cdn.slidesharecdn.com/ss_thumbnails/20210709akuzawa-210709021836-thumbnail.jpg?width=640&height=640&fit=bounds)

