Downloaded 562 times


















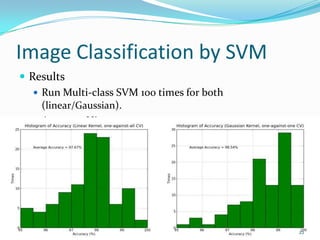



This document discusses support vector machines and their application to image classification. It provides an overview of SVM concepts like functional and geometric margins, optimization to maximize margins, Lagrangian duality, kernels, soft margins, and bias-variance tradeoff. It also covers multiclass SVM approaches, dimensionality reduction techniques, model selection via cross-validation, and results from applying SVM to an image classification problem.
































































































