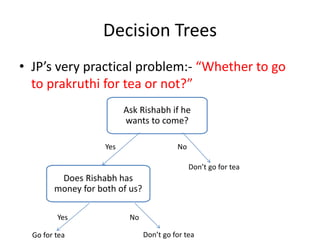
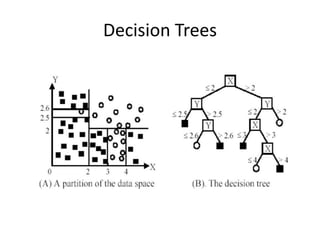
1) Decision trees are models that partition the feature space into rectangular regions and make predictions based on the region a sample falls into. They can be used for both classification and regression problems.
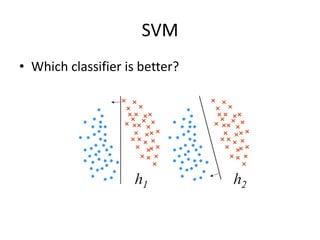
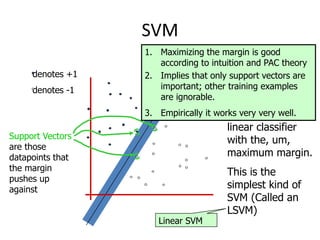
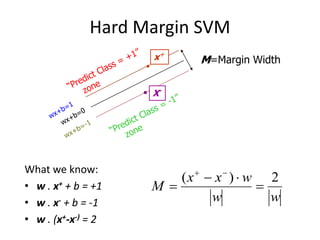
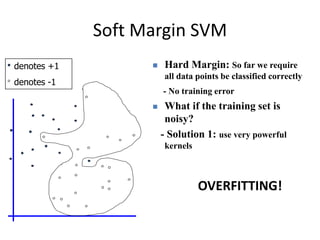
2) Support vector machines (SVMs) look for the optimal separating hyperplane that maximizes the margin between the classes. The hard margin SVM requires all samples to be classified correctly while the soft margin SVM allows for some misclassification using slack variables.
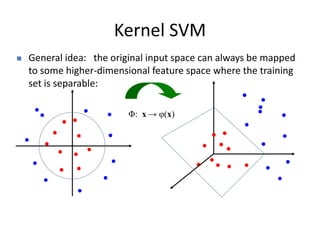
3) Kernel SVMs map the input data into a higher dimensional feature space to allow for nonlinear decision boundaries using kernel functions such as the radial basis function kernel. This helps address the limitations of linear SVMs.