Downloaded 418 times













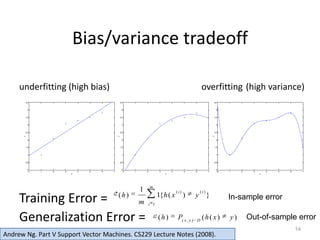











This document provides an overview of support vector machines (SVMs). It discusses how SVMs can be used to perform classification tasks by finding optimal separating hyperplanes that maximize the margin between different classes. The document outlines how SVMs solve an optimization problem to find these optimal hyperplanes using techniques like Lagrange duality, kernels, and soft margins. It also covers model selection methods like cross-validation and discusses extensions of SVMs to multi-class classification problems.












































































