Downloaded 238 times












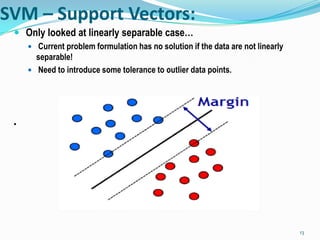


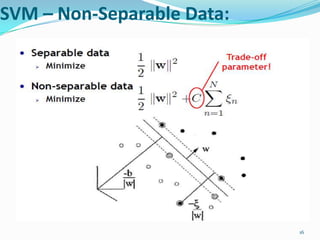






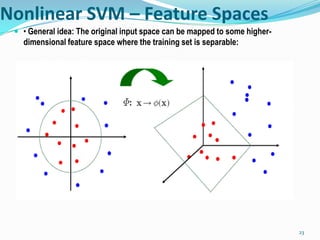










This document discusses support vector machines (SVMs) for classification. It explains that SVMs find the optimal separating hyperplane that maximizes the margin between positive and negative examples. This is formulated as a convex optimization problem. Both primal and dual formulations are presented, with the dual having fewer variables that scale with the number of examples rather than dimensions. Methods for handling non-separable data using soft margins and kernels for nonlinear classification are also summarized. Popular kernel functions like polynomial and Gaussian kernels are mentioned.

























































![SVM[Support vector Machine] Machine learning](https://cdn.slidesharecdn.com/ss_thumbnails/svm-250403184638-1cd9afdb-thumbnail.jpg?width=640&height=640&fit=bounds)





























