










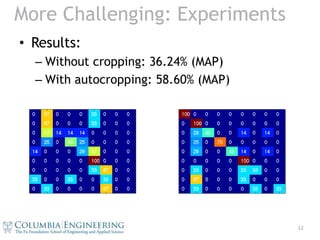


This document describes a book cover recognition system that takes an image containing a book as input and outputs the book title or ID. The baseline model uses bag-of-words with dense SIFT features, visual word learning via vector quantization, spatial pooling, and linear SVM classification. On a dataset of 9 books with 15 training and 15 test images per book, the baseline achieves nearly perfect recognition results. More challenging test images with clutter and occlusion lead to poorer results. The document explores using Hough transform for automatic book cropping before classification, which improves results from 36.24% to 58.60% mean average precision.

























































