Downloaded 276 times























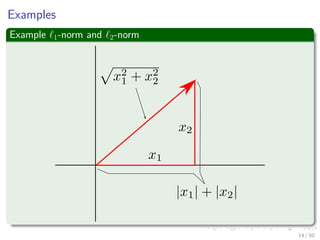

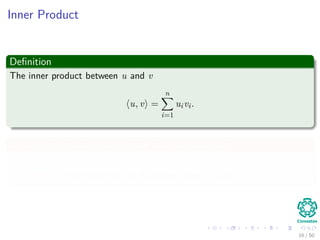
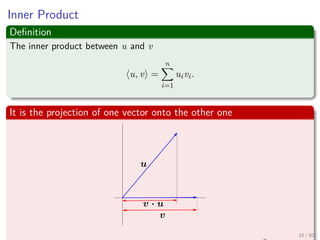

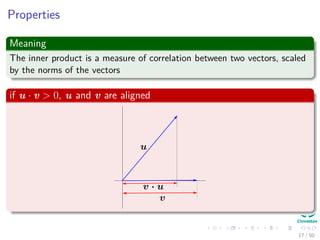
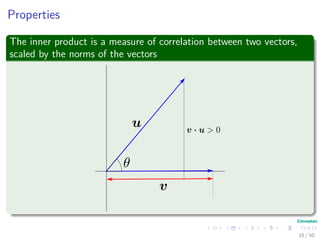
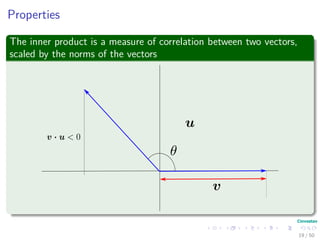
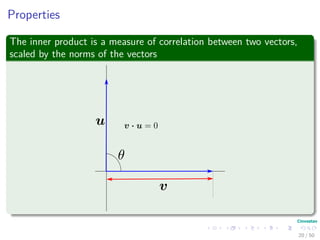




































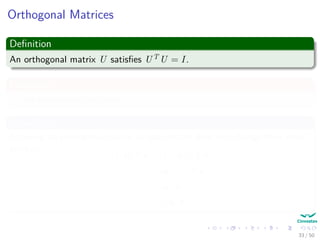
















































The document provides an introduction to linear algebra concepts for machine learning. It defines vectors as ordered tuples of numbers that express magnitude and direction. Vector spaces are sets that contain all linear combinations of vectors. Linear independence and basis of vector spaces are discussed. Norms measure the magnitude of a vector, with examples given of the 1-norm and 2-norm. Inner products measure the correlation between vectors. Matrices can represent linear operators between vector spaces. Key linear algebra concepts such as trace, determinant, and matrix decompositions are outlined for machine learning applications.






























































































