Downloaded 118 times







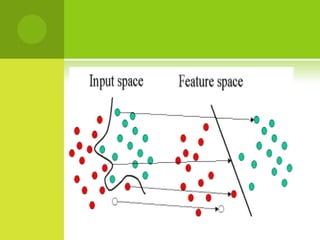


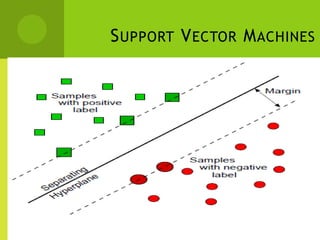




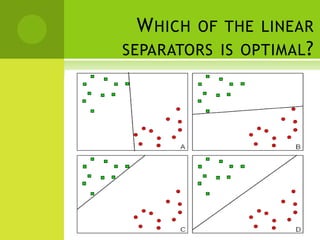
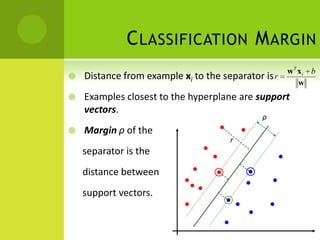
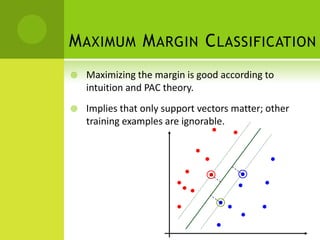









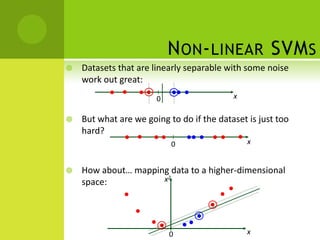





The document discusses support vector machines (SVMs) for classification. It begins by defining classifiers and the difference between classification and clustering. It then introduces SVMs, explaining that they find optimal decision boundaries that separate classes through mapping data points into higher dimensional space. The document outlines linear and non-linear SVMs, describing how non-linear SVMs can find more complex separating structures through kernels. It also discusses supervised learning with SVMs and how to solve the optimization problem to train linear SVMs, including soft-margin classification to handle non-separable data.