Downloaded 565 times






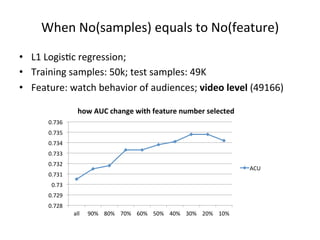
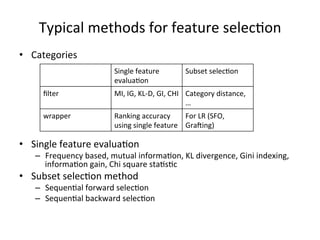






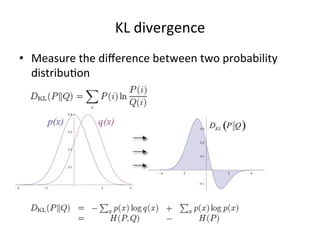

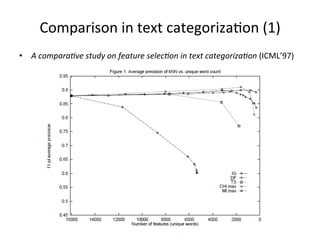
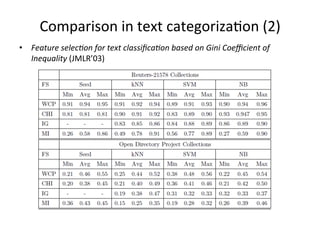









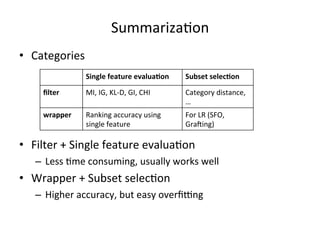



This document summarizes a machine learning workshop on feature selection. It discusses typical feature selection methods like single feature evaluation using metrics like mutual information and Gini indexing. It also covers subset selection techniques like sequential forward selection and sequential backward selection. Examples are provided showing how feature selection improves performance for logistic regression on large datasets with more features than samples. The document outlines the workshop agenda and provides details on when and why feature selection is important for machine learning models.


























































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)
















