





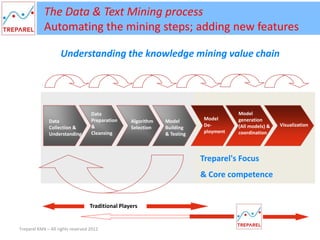






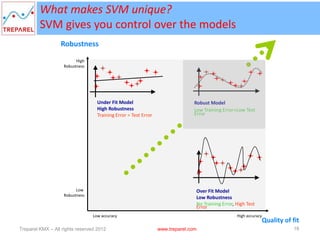
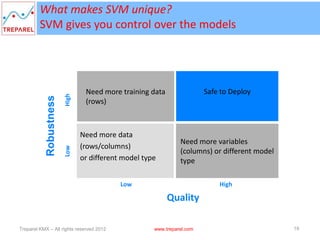


The document presents an introduction to text mining and support vector machines (SVM), outlining Treparel's role as a leading technology solution provider in big data analytics and visualization. It highlights the significance of automating the mining of unstructured data to enable informed decision-making and explores the functionalities of SVM in classification and regression. Additionally, the presentation covers data mining processes, the differences between predictive and descriptive mining tasks, and the advantages of using SVM.








![[db tech showcase Tokyo 2018] #dbts2018 #B38 『Big Data and the Multi-model Da...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts2018b38helibigdataandmultimodeldb-180929171101-thumbnail.jpg?width=640&height=640&fit=bounds)





































































