



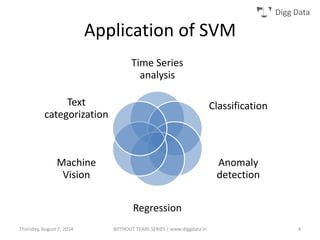
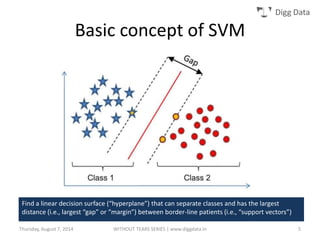
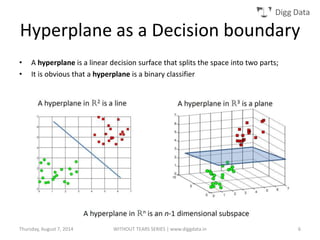

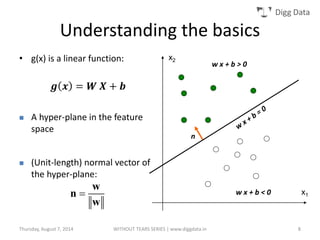
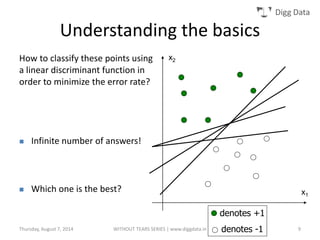
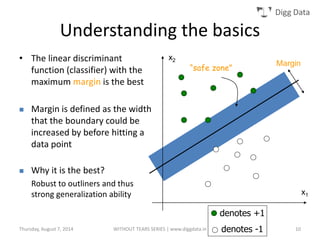
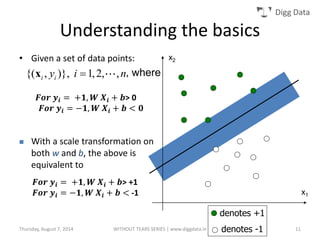
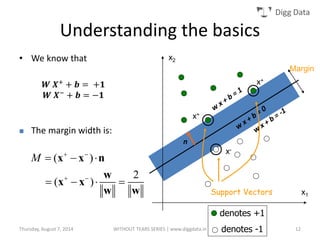
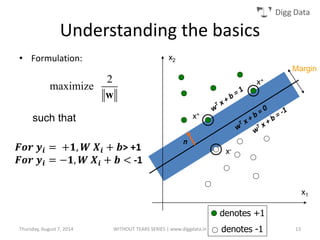
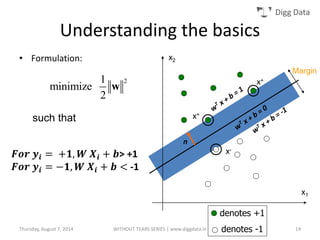
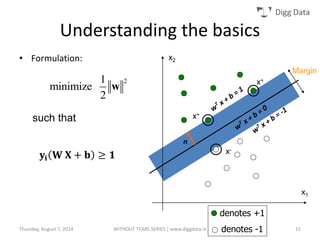
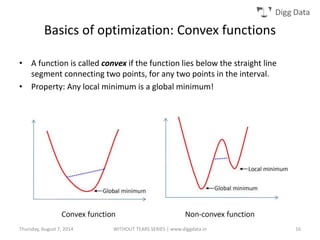





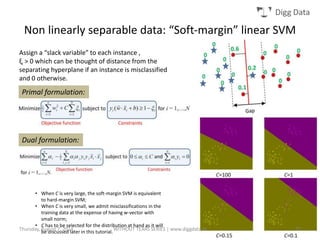

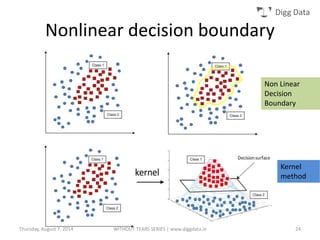



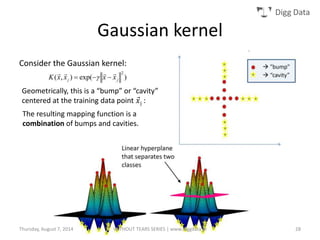
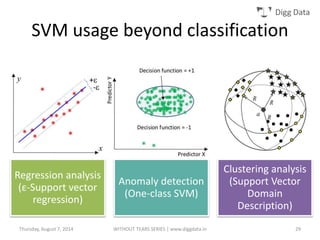


This document provides an overview of support vector machines (SVMs), including their basic concepts, formulations, and applications. SVMs are supervised learning models that analyze data, recognize patterns, and are used for classification and regression. The document explains key SVM properties, the concept of finding an optimal hyperplane for classification, soft margin SVMs, dual formulations, kernel methods, and how SVMs can be used for tasks beyond binary classification like regression, anomaly detection, and clustering.
















































![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)











![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)






