Downloaded 368 times













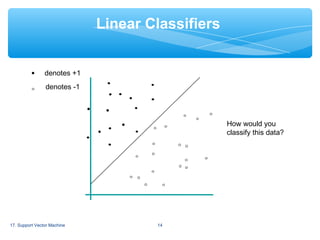




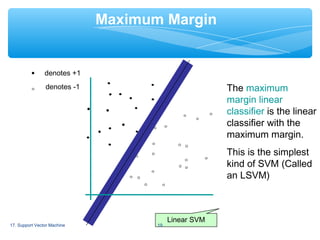















Support Vector Machine (SVM) is a supervised machine learning algorithm that can be used for both classification and regression analysis. It works by finding a hyperplane in an N-dimensional space that distinctly classifies the data points. SVM selects the hyperplane that has the largest distance to the nearest training data points of any class, since larger the margin lower the generalization error of the classifier. SVM can efficiently perform nonlinear classification by implicitly mapping their inputs into high-dimensional feature spaces.























































































