【DL輪読会】Language Conditioned Imitation Learning over Unstructured Data
1.
DEEP LEARNING JP
[DLPapers]
http://deeplearning.jp/
Language Conditioned Imitation Learning over
Unstructured Data
Koki Ishimoto
1
2.
書誌情報
• Title: LanguageConditioned Imitation Learning over Unstructured
Data
• Author: Corey Lynch* and Pierre Sermanet*
• *Robotics at Google
• Conference: Robotics: Science and Systems 2021(Held Virtually: July
12-16, 2021)
• Project page: https://language-play.github.io/
2
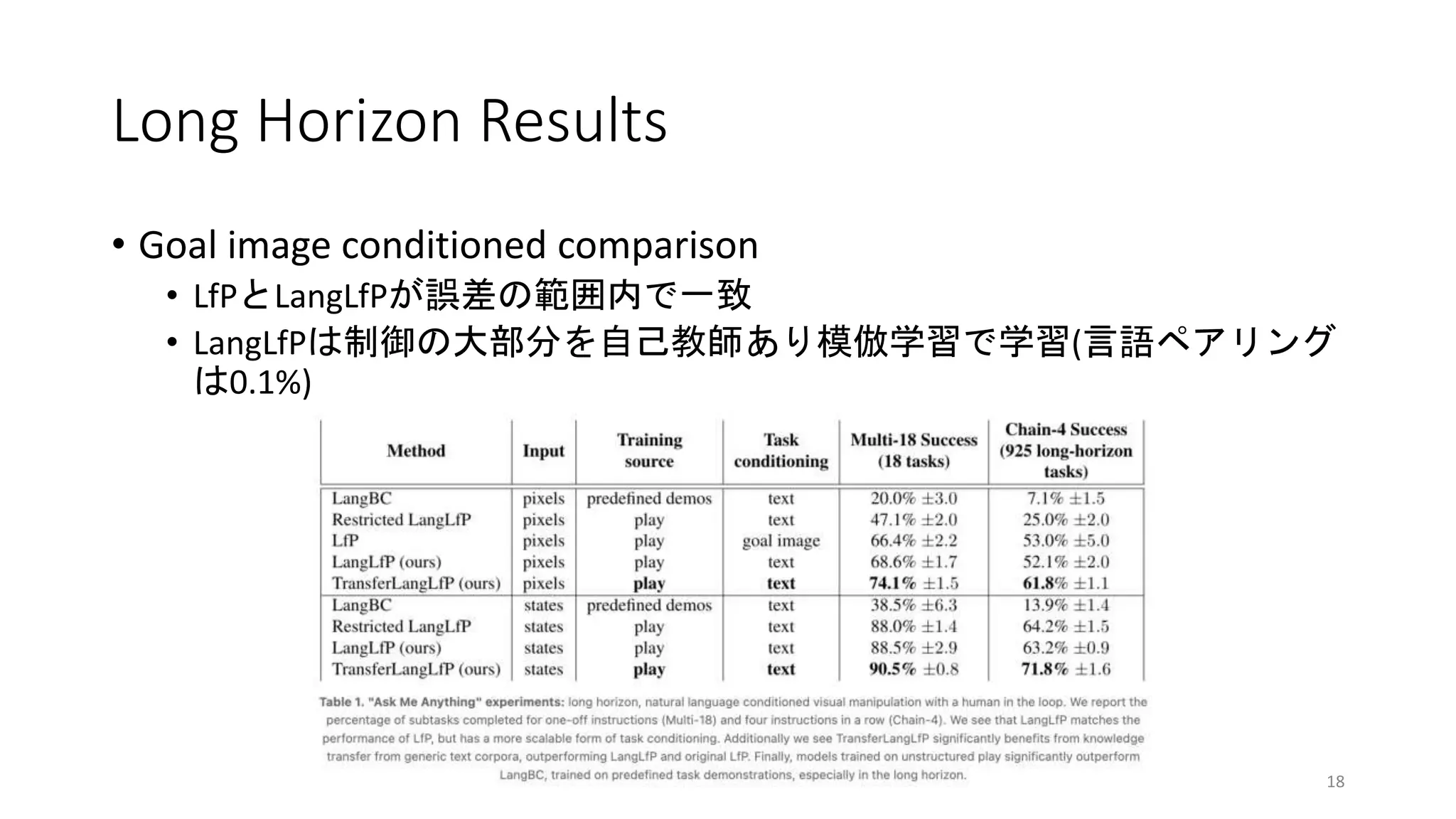
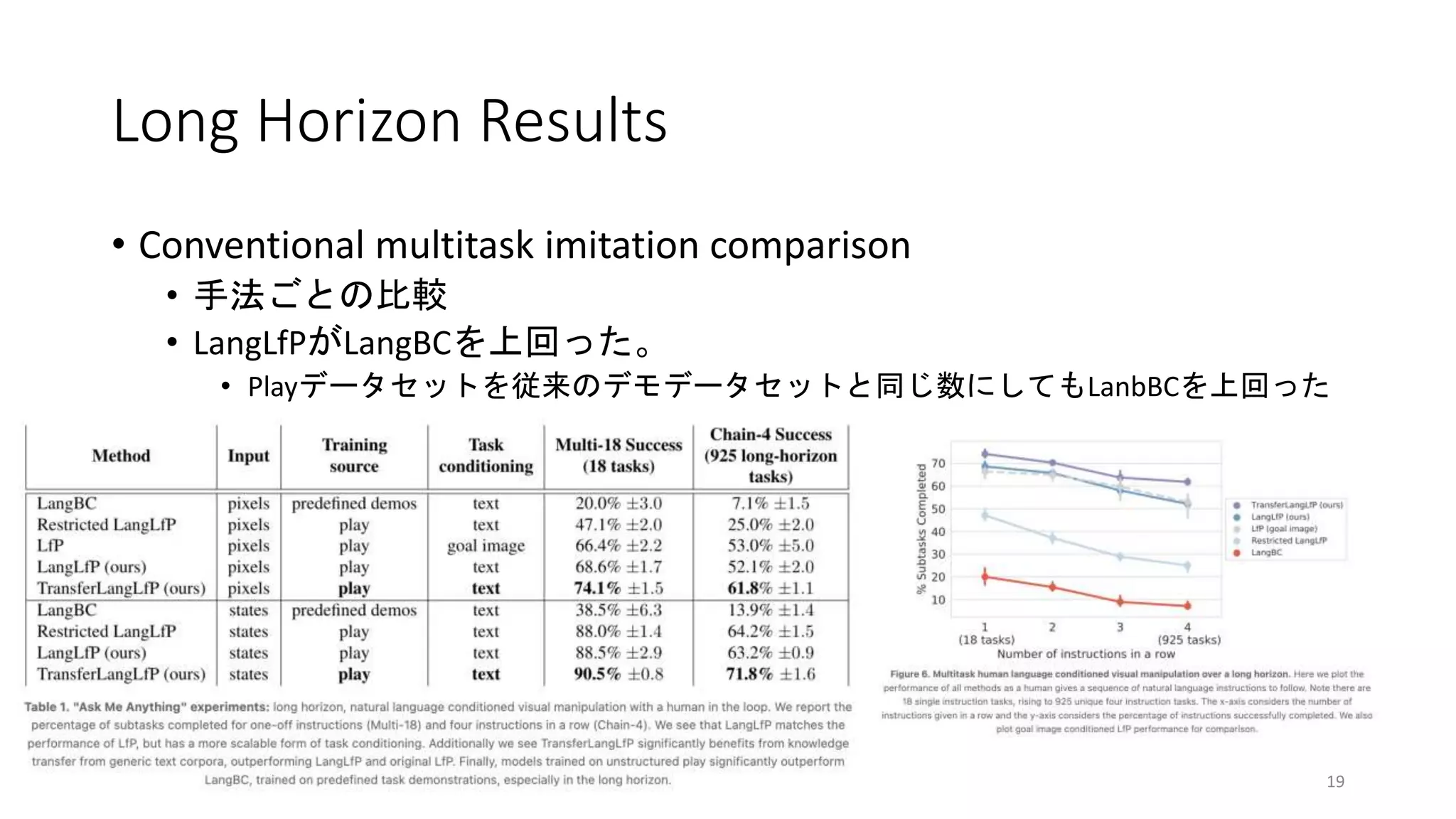
研究の概要
• Cover thespace with teleoperational play(Learning from Play)
• テレオペでstate-action logを取る
• Pair play with human language
• 行動を後付けで言語にペアリングする
• Multicontext imitation learning
• 自己教師あり模倣学習により、行動と言語のペアリング数を減らせる(全デー
タ中1%程度)
• Condition on human language at test time
• テスト時に言語指示で複数のスキルを連続実行
• Transfer learning from unlabeled text corpora to robotic manipulation
• ラベル付されてないテキストコーパスからロボットマニピュレーションへの
転移学習
4
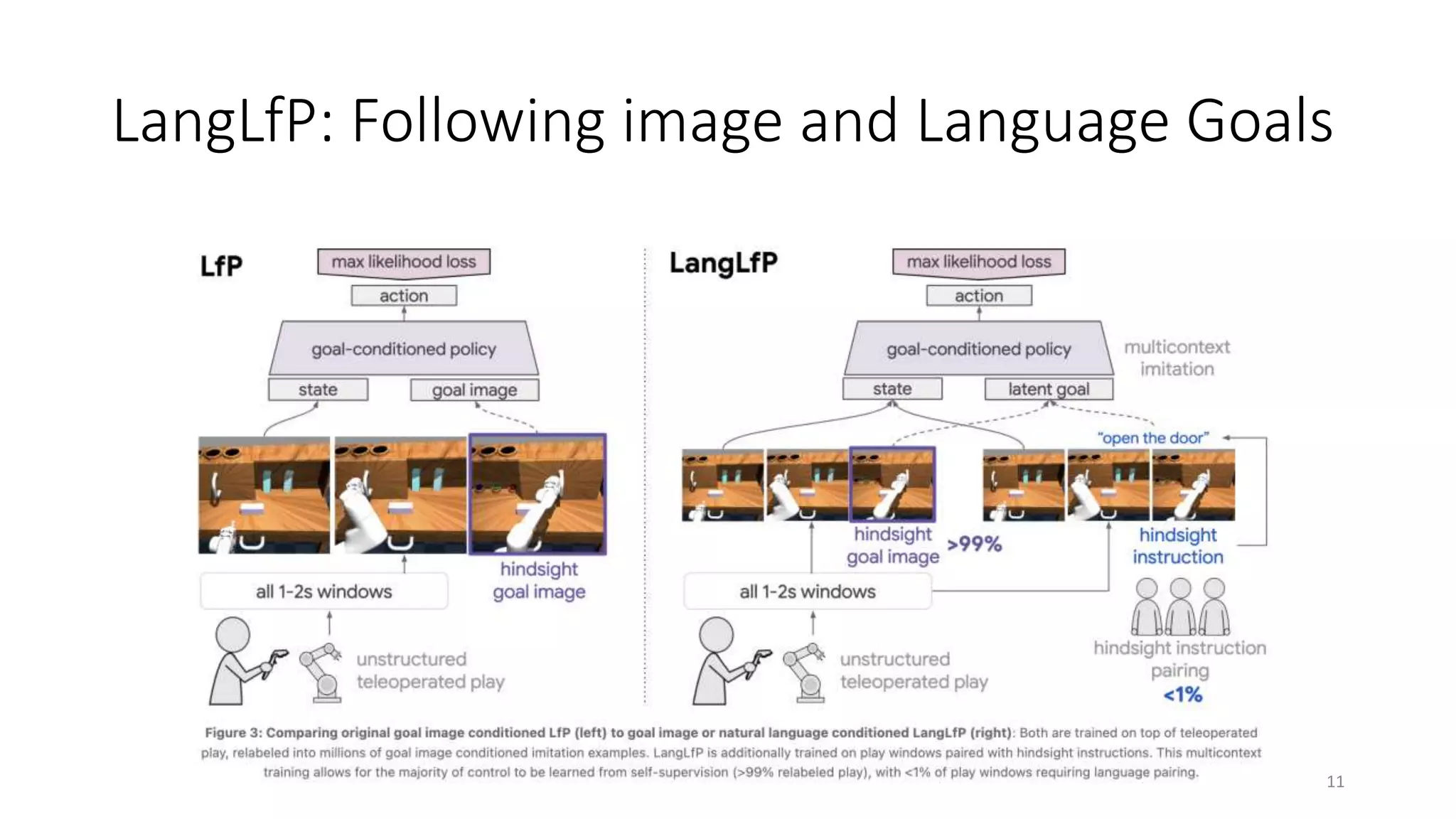
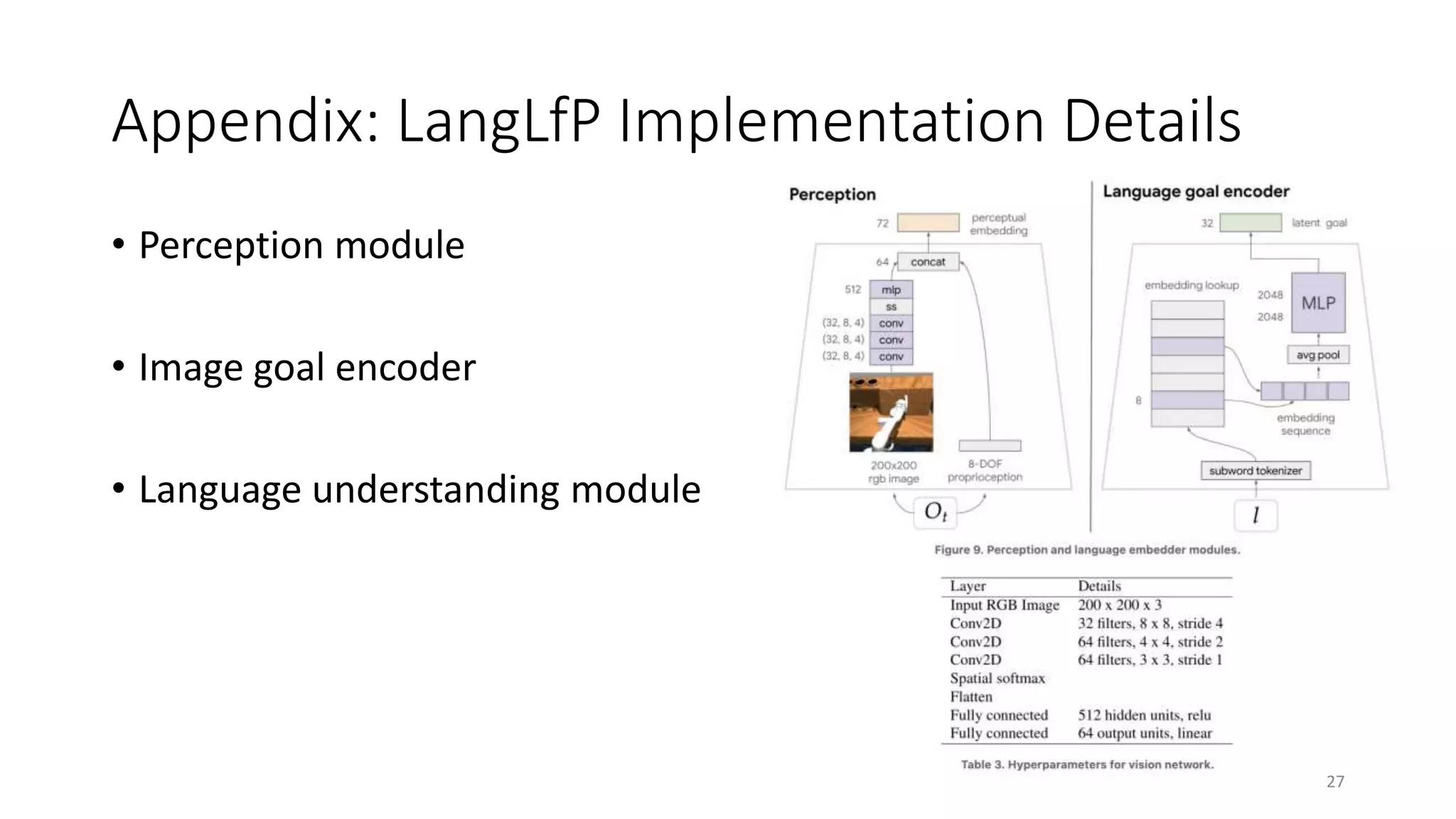
Learning to FollowHuman Language
Instructons
• Pairing robot experience with human language
• Hindsight Instruction Pairingを導入
• ロボットセンサデータと関連する言語をペアリングする手法
• Multicontext Imitation Learning
• LangLfP: Following image and Language Goals
9
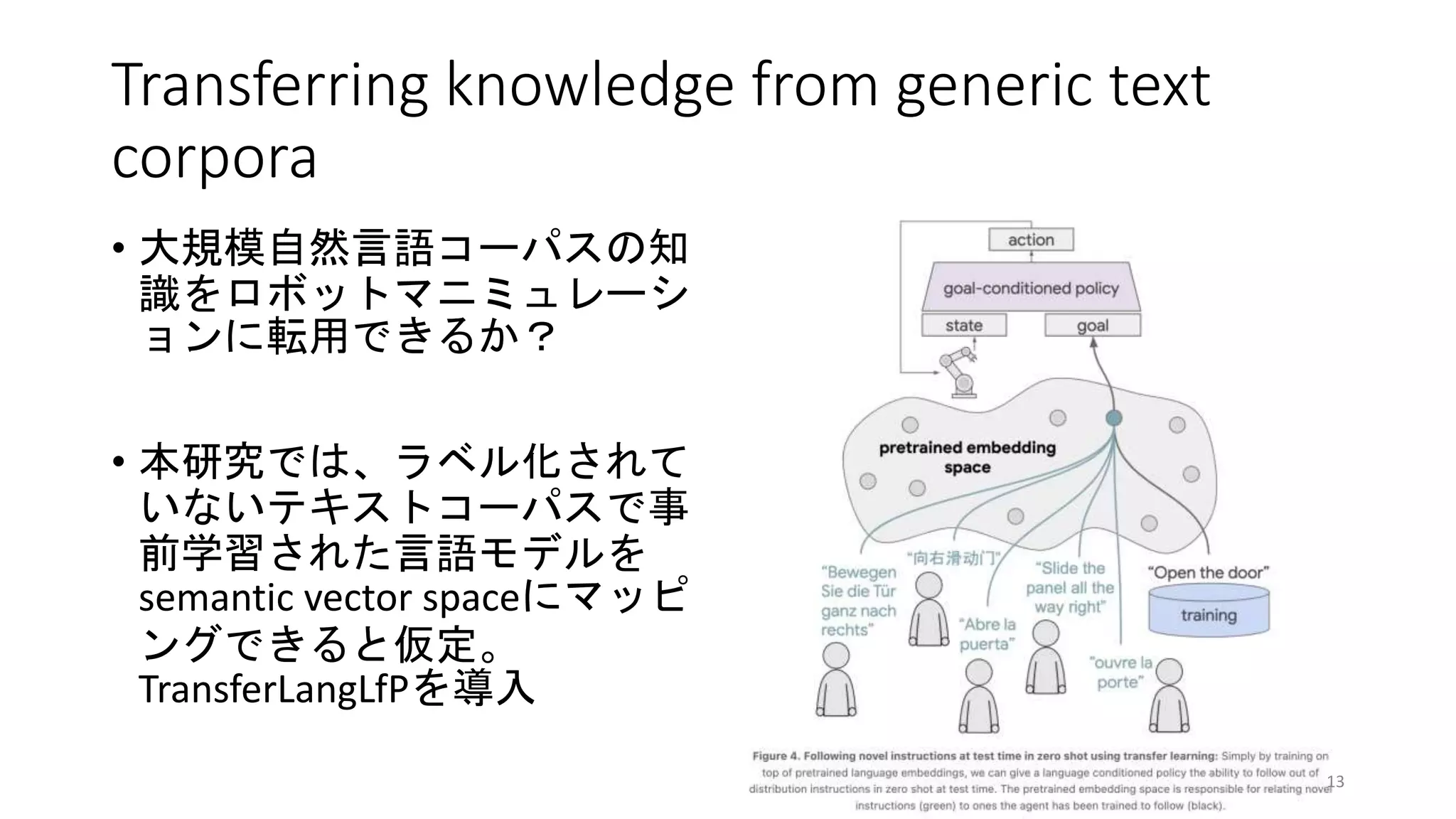
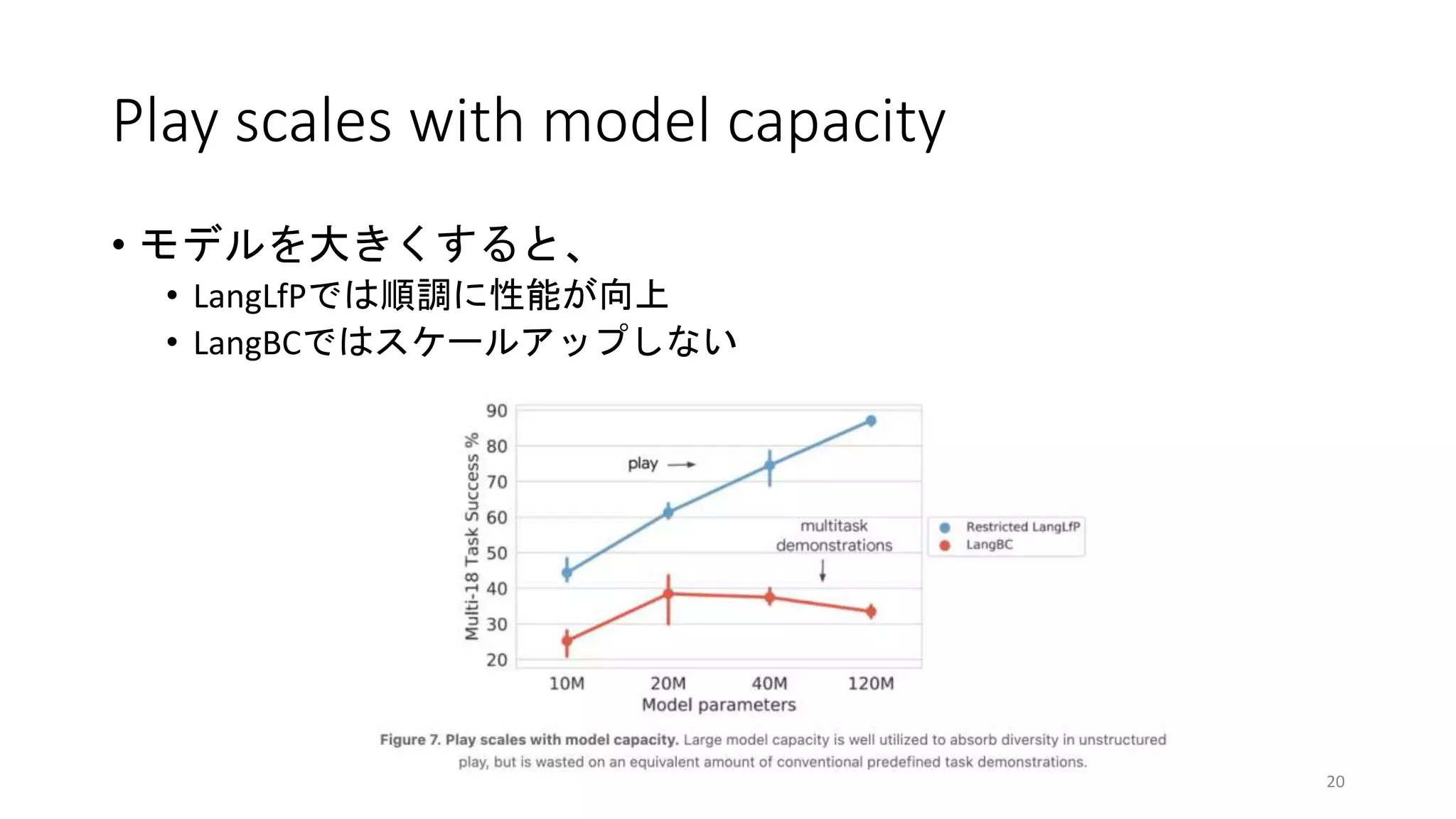
Knowledge transfer results
•Positive transfer to robotic manipulation
• TransferLangLfPがLangLfPよりも良い性能
を示した
• 大量のテキストに反映された世界の知
識が、言語指示ロボット操作の改善に
活用されたと考えられる
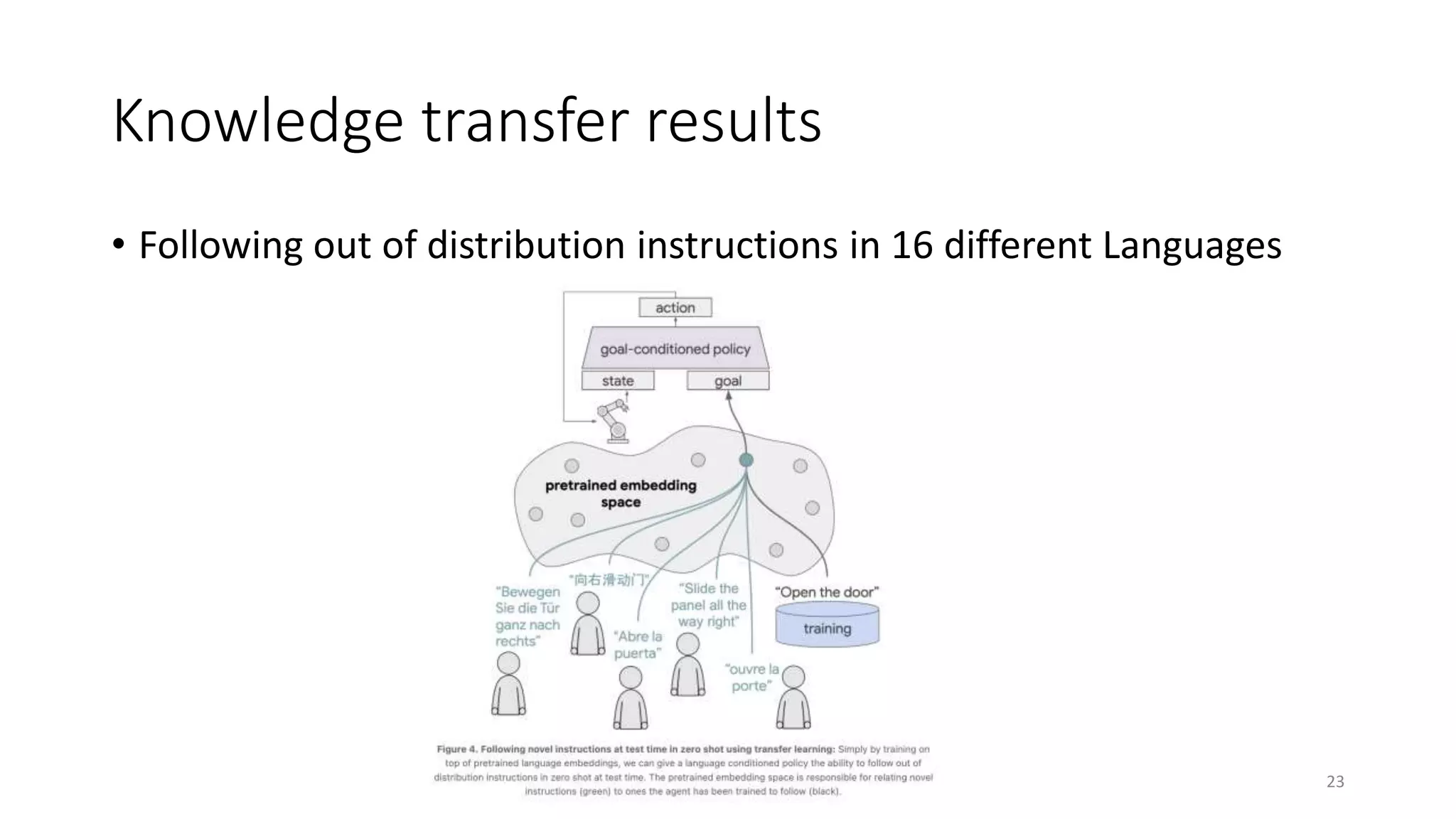
• Following out of distribution “synonym
instructions”
• 同義語の指示に関して、TransferLanngLfP
の方が優位な性能を示した
• 例:「ブロックを拾う」と「レンガを拾
う」などの同じような指示に対する汎化
性の高い対応
22
![DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
Language Conditioned Imitation Learning over
Unstructured Data
Koki Ishimoto
1](https://image.slidesharecdn.com/dlp220729ishimotov0-220729033500-f96d9101/75/DL-Language-Conditioned-Imitation-Learning-over-Unstructured-Data-1-2048.jpg)




























![[DL輪読会]World Models](https://cdn.slidesharecdn.com/ss_thumbnails/20180427-180427003856-thumbnail.jpg?width=640&height=640&fit=bounds)














![[DL輪読会]SoftTriple Loss: Deep Metric Learning Without Triplet Sampling (ICCV2019)](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20190920dlhack-190920011134-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Objects as Points](https://cdn.slidesharecdn.com/ss_thumbnails/20190614centernetkuboshizuma-190614004246-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...](https://cdn.slidesharecdn.com/ss_thumbnails/20190426akuzawa-190426020057-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]画像を使ったSim2Realの現況](https://cdn.slidesharecdn.com/ss_thumbnails/imagesim2real-201030025320-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Mastering the Dungeon: Grounded Language Learning by Mechanical Turker...](https://cdn.slidesharecdn.com/ss_thumbnails/180126groundedlanguagelearningbymechanicalturkerdecent1-180126004830-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Learning to Adapt: Meta-Learning for Model-Based Control](https://cdn.slidesharecdn.com/ss_thumbnails/20180511dl-180511004107-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Temporal Abstraction in NeurIPS2019](https://cdn.slidesharecdn.com/ss_thumbnails/20191115-191112082849-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Temporal DifferenceVariationalAuto-Encoder](https://cdn.slidesharecdn.com/ss_thumbnails/20181130new-190205051636-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Learning agile and dynamic motor skills for legged robots](https://cdn.slidesharecdn.com/ss_thumbnails/dlseminar0125nishimura-190125001509-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Imagination-Augmented Agents for Deep Reinforcement Learning / Learnin...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacksshioya201707281-170728054152-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Autonomous Reinforcement Learning: Formalism and Benchmarking](https://cdn.slidesharecdn.com/ss_thumbnails/20220311arlfinal-220314025127-thumbnail.jpg?width=640&height=640&fit=bounds)


























