References
Bengio, Y.,Louradour, J., Collobert, R. and Weston, J. Curriculum Learning. ICML 2009.
Gers, F. Long Short-Term Memory in Recurrent Neural Networks. Ph.D thesis, 2001.
Graves, A., Wayne, G. and Danihelka, I. Neural Turing Machines. arXiv:1410.5401v1, 2014.
Hochreiter, S. and Schmidhuber, J. LONG SHORT-TERM MEMORY. Neural Computation, 9(8):
1735-1780, 1997.
Mnih, V., Heess, N., Graves, A. and Kavukcuglu, K. Recurrent Models of Visual Attention. ICML, 2014.
Pascanu, R., Gulcehre, C., Cho, K. and Bengio, Y. How to Construct Deep Recurrent Neural Networks.
ICLR, 2014.
Sutskever, I., Vinyals, O. and Le, Q. V. Sequence to Sequence Learning with Neural Networks. NIPS
2014.
Williams, R. J. Simple statistical gradient-following algorithms for connectionist reinforcement learning.
Machine Learning, 8(e):229-256, 1992.
Zaremba, W. and Sutskever, I. Learning to Execute. arXiv:1410.4615v1, 2014.
42



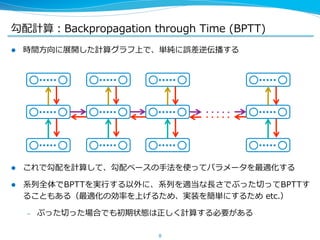

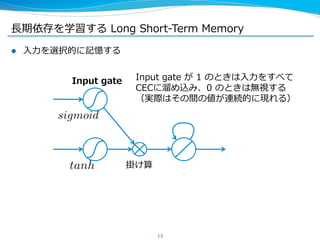
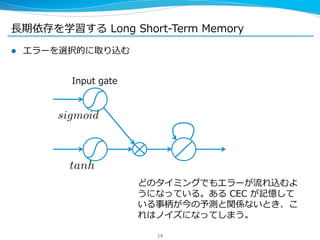
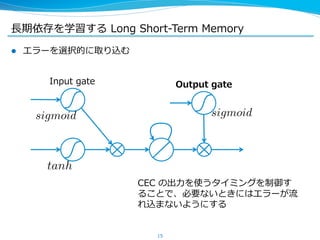
![⻑⾧長期依存を学習する Long Short-‐‑‒Term Memory
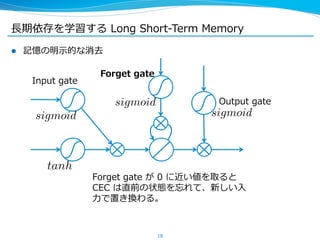
l ここまでが [HochreiterSchmidhuber, ʻ‘97] で提案された
Long Short-‐‑‒Term Memory ユニット
sigmoid
※ もともとは CEC の後ろにもう⼀一回 sigmoid 等をかませていたが、最近
は省省くことが多い
16
Input gate
tanh
Output gate
sigmoid](https://image.slidesharecdn.com/pfiseminar20141030rnn-141029232616-conversion-gate02/85/Recurrent-Neural-Networks-16-320.jpg)
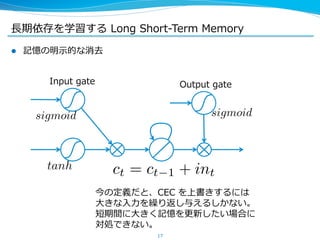
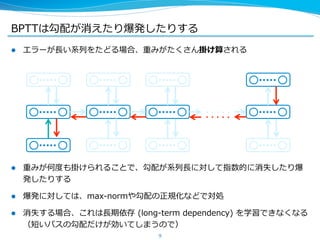
![⻑⾧長期依存を学習する Long Short-‐‑‒Term Memory
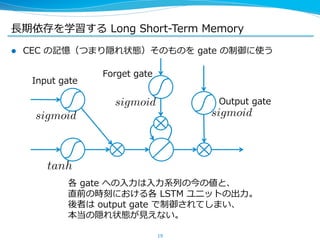
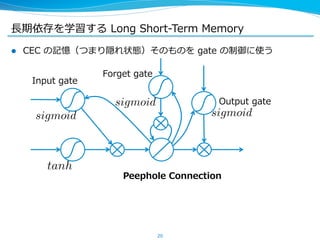
l これが [Gers, ʻ‘01] などでまとめられている拡張された LSTM ユニッ
ト
sigmoid
Forget gate
l 現在よく⽤用いられているものは、このバージョンや peephole
connection を省省いたもの
l 学習は BPTT で⾏行行うのが主流流
21
Input gate
tanh
Output gate
sigmoid
sigmoid](https://image.slidesharecdn.com/pfiseminar20141030rnn-141029232616-conversion-gate02/85/Recurrent-Neural-Networks-21-320.jpg)
![RNN を Deep にする⽅方法 [Pascanu+, ICLR ʻ‘14]
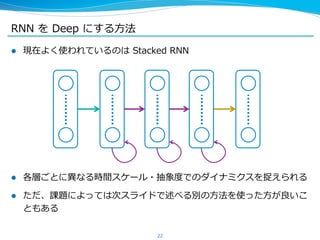
l RNN ⾃自体を stack する以外に、RNN の遷移層、出⼒力力層をそれぞれ
deep にすることもできる(下図の⽩白い層は何段あってもよい)
l 上の (b*) のように、遷移層を deep にする場合は backprop のパスが
さらに⻑⾧長くなってしまうので、ショートカットを⼊入れると良良い
– 短い時間で予測に⾮非線形な影響をあたえるような⼊入⼒力力をとらえるのに deep な接続を
使い、⻑⾧長期のラグを経て予測に影響を与えるような現象をとらえるのにショートカッ
トを使う
23](https://image.slidesharecdn.com/pfiseminar20141030rnn-141029232616-conversion-gate02/85/Recurrent-Neural-Networks-23-320.jpg)
![応⽤用:機械翻訳 [Sutskever+, NIPS ʻ‘14]
l “Sequence to Sequence Learning with Neural Networks”
– RNN を機械翻訳に使う研究は最近とても多いが、この論論⽂文は RNN のみで機械翻訳を
⾏行行うところが特徴
l 英語の単語列列を⼊入⼒力力として、フランス語の単語列列を出⼒力力する
l まず英語の⽂文章 ABC を⼊入れて、EOS(⽂文末)に到達したらフランス語
の⽂文章 WXYZ を出⼒力力する
24](https://image.slidesharecdn.com/pfiseminar20141030rnn-141029232616-conversion-gate02/85/Recurrent-Neural-Networks-24-320.jpg)
![応⽤用:機械翻訳 [Sutskever+, NIPS ʻ‘14]
⼯工夫
l 英語を読むときとフランス語を出⼒力力するときで異異なるパラメータを使う
l 英語(⼊入⼒力力)は前後を反転させて読ませる
– 英語とフランス語は語順が近いため、対応する単語ペアで近い位置
にあるものが多い⽅方が学習の初期時に⾜足がかりにしやすい
– このテクニックはおそらく、出⼒力力の最初の⽅方を予測するのに⼊入⼒力力の
最初の⽅方が強く効くような問題で有効
25](https://image.slidesharecdn.com/pfiseminar20141030rnn-141029232616-conversion-gate02/85/Recurrent-Neural-Networks-25-320.jpg)
![応⽤用:機械翻訳 [Sutskever+, NIPS ʻ‘14]
26](https://image.slidesharecdn.com/pfiseminar20141030rnn-141029232616-conversion-gate02/85/Recurrent-Neural-Networks-26-320.jpg)
![応⽤用:⾔言語処理理系の学習 [ZarembaSutskever, ʻ‘14]
l “Learning to Execute”
l 簡単な Python コードが⼊入⼒力力
l print 結果を出⼒力力させる
– 結果は必ずドットで終わる
l データはランダムに⽣生成。
以下のパラメータを持つ:
– 現れる数値の桁数
– 構⽂文⽊木の深さ
27](https://image.slidesharecdn.com/pfiseminar20141030rnn-141029232616-conversion-gate02/85/Recurrent-Neural-Networks-27-320.jpg)
![応⽤用:⾔言語処理理系の学習 [ZarembaSutskever, ʻ‘14]
l (Peepholeのない)Stacked LSTM RNN で学習
l ⼯工夫:Curriculum Learning [Bengio+, ICMLʼ’09]
– 簡単な問題を先に解かせることで難しい問題の最適化を容易易にする
(去年年のPFIセミナー後半を参照
http://www.slideshare.net/beam2d/deep-‐‑‒learning-‐‑‒22544096)
– ここではデータを⽣生成するときのパラメータ(桁数、構⽂文⽊木の深
さ)について、⼩小さな値を⽤用いて⽣生成したデータからまず学習させ、
段々⽣生成パラメータを⼤大きくしていく
– ただし、ナイーブにやるとダメ
u ⼩小さなパラメータのデータに特化した RNN が学習されてしまう
u 序盤から少量量の難しい問題を混ぜておくことでこれを回避
28](https://image.slidesharecdn.com/pfiseminar20141030rnn-141029232616-conversion-gate02/85/Recurrent-Neural-Networks-28-320.jpg)
![応⽤用:⾔言語処理理系の学習 [ZarembaSutskever, ʻ‘14]
l 出⼒力力例例
29](https://image.slidesharecdn.com/pfiseminar20141030rnn-141029232616-conversion-gate02/85/Recurrent-Neural-Networks-29-320.jpg)
![応⽤用:アルゴリズムの学習 [Graves+, ʻ‘14]
l “Neural Turing Machines”
l メモリのくっついた (R)NN を考案している(下は模式図)
コントローラ
⼊入⼒力力出⼒力力
30
読み取り
ヘッド
書き込み
ヘッド
書き込み
内容
メモリ⾏行行列列](https://image.slidesharecdn.com/pfiseminar20141030rnn-141029232616-conversion-gate02/85/Recurrent-Neural-Networks-30-320.jpg)
![応⽤用:アルゴリズムの学習 [Graves+, ʻ‘14]
l メモリ⾏行行列列から読んだり書いたりできる
l 読み書きにはヘッドを使う
l ヘッドは確率率率ベクトル
メモリ⾏行行列列
ヘッド:確率率率ベクトル
(⾮非負値で和が1)
– One-‐‑‒hot だとチューリ
ングマシンのように⼀一
箇所だけから読むことに
なる
– これを backprop できるように
連続値に拡張している
l 書く時は書き込む内容(⾏行行ベクトル)も⼀一緒に
出⼒力力して、⾏行行ごとに書き込む強度度をヘッドで指定する
31
×
wt
Mt](https://image.slidesharecdn.com/pfiseminar20141030rnn-141029232616-conversion-gate02/85/Recurrent-Neural-Networks-31-320.jpg)
![応⽤用:アルゴリズムの学習 [Graves+, ʻ‘14]
l ヘッドの指定は2つのアドレッシング⽅方法を組合せる
l まずはコンテンツベースのアドレッシング
– コントローラが出⼒力力した⾏行行ベクトル とのコサイン距離離 の
softmax で確率率率を割当てる
wc
t (i) / exp(tK(kt,Mt(i))
– これを前回のヘッドと混ぜたものを次のロケーションベースのアド
レッシングへの⼊入⼒力力にする(混合係数 はコントローラが指定す
る)
– 混合係数が 0 ならコンテンツベースアドレッシングは無視される
32
kt K
gt](https://image.slidesharecdn.com/pfiseminar20141030rnn-141029232616-conversion-gate02/85/Recurrent-Neural-Networks-32-320.jpg)
![応⽤用:アルゴリズムの学習 [Graves+, ʻ‘14]
l 次にロケーションベースのアドレッシング
– 指定した数だけヘッドを右か左にシフトさせたい
– だが同時に backprop もできるようにしたいので、代わりにコント
ローラが指定したベクトルとの畳み込み演算で補う(添字が端を越
えるところでは循環させる)
– このときベクトル が one-‐‑‒hot なら完全なシフトになる
– Softmax などで指定する場合、なだらかな値を取り値がボケてしま
うので、シャープにする( もコントローラが指定)
33
st
t 1
wt(i) / ˜ wt(i)t](https://image.slidesharecdn.com/pfiseminar20141030rnn-141029232616-conversion-gate02/85/Recurrent-Neural-Networks-33-320.jpg)
![応⽤用:アルゴリズムの学習 [Graves+, ʻ‘14]
l ⼊入⼒力力系列列を読んだあとに出⼒力力系列列を予測する課題(機械翻訳と同じ)
l 処理理の順序
– コントローラが読み取りヘッドを出⼒力力
– 読み取りヘッド(⾏行行ベクトル)とメモリ⾏行行列列の積によってメモリ内容を読み出す
– ⼊入⼒力力、メモリの読み出し結果、コントローラの直前の状態(コントローラが RNN の
場合)をもとにコントローラの状態を更更新
– コントローラが書き込みヘッドと書き込み内容を出⼒力力
u 書き込みは「消してから⾜足す」というやりかたをしている(詳細は論論⽂文参照)
– 書き込みヘッド(⾏行行ベクトル)と書き込み内容(列列ベクトル)の outer product を
取ってメモリ⾏行行列列を更更新
– コントローラが予測を出⼒力力
l すべての処理理は微分可能なので、ヘッドの位置(確率率率ベクトル)や書き
込み内容を含めてシステム全体を BPTT で学習できる
34](https://image.slidesharecdn.com/pfiseminar20141030rnn-141029232616-conversion-gate02/85/Recurrent-Neural-Networks-34-320.jpg)
![応⽤用:アルゴリズムの学習 [Graves+, ʻ‘14]
l コピー課題(上)
– ⼊入⼒力力と同じものを出⼒力力する
l 繰り返しコピー課題(下)
– ⼊入⼒力力はコピー対象系列列の末尾に
コピー回数を書いたもの。これを
読んで、コピー回数だけ対象系列列
を繰り返し出⼒力力する課題
– つまり For ループができるかを
確かめる実験
l どちらも LSTM RNN より速く
学習している
– 下のほうが LSTM でも良良いのは
上の実験より系列列を短くしてるから
35](https://image.slidesharecdn.com/pfiseminar20141030rnn-141029232616-conversion-gate02/85/Recurrent-Neural-Networks-35-320.jpg)
![応⽤用:アルゴリズムの学習 [Graves+, ʻ‘14]
l 繰り返しコピー課題でのヘッドの内容
l 毎コピー後に繰り返し回数をチェックしに⾏行行ってるのがわかる
36](https://image.slidesharecdn.com/pfiseminar20141030rnn-141029232616-conversion-gate02/85/Recurrent-Neural-Networks-36-320.jpg)
![応⽤用:アルゴリズムの学習 [Graves+, ʻ‘14]
l Neural Turing Machines でコントローラに LSTM を使う場合、LSTM
はレジスタのように使われる
– 先ほどのコピー課題ではおそらく、現在の繰り返し回数が LSTM の
中に保持されていると予想される
u 繰り返し中にはメモリへの書き込みがないため
l コピー回数やコピー内容のように、⻑⾧長期にわたって覚えておく必要があ
る内容をメモリに書いている
l 論論⽂文ではもっと複雑なタスクも解かせているので、実験のところだけで
も読むと⾯面⽩白いです
– 系列列を任意の場所から思い出す、N-‐‑‒gram モデルの学習アルゴリズム⾃自体を
学習する、インデックス順に並び替えるタスク(Priority Sort)
37](https://image.slidesharecdn.com/pfiseminar20141030rnn-141029232616-conversion-gate02/85/Recurrent-Neural-Networks-37-320.jpg)
![応⽤用:Visual Attention [Mnih+, ICML ʻ‘14]
l “Recurrent Models of Visual Attention”
l 画像認識識(分類や検出)において、画像全体を⾒見見たくない
l ⼩小さな矩形を⼊入⼒力力として⾒見見て、次に⾒見見る位置を出⼒力力。これを繰り返しな
がら予測やアクションを改善していく
38](https://image.slidesharecdn.com/pfiseminar20141030rnn-141029232616-conversion-gate02/85/Recurrent-Neural-Networks-38-320.jpg)
![応⽤用:Visual Attention [Mnih+, ICML ʻ‘14]
l ⼿手法の名前は Recurrent Attention Model (RAM)
l ⼊入⼒力力は静⽌止画でも動画(系列列)でも良良い
– 論論⽂文では静⽌止画(MNIST をランダムに平⾏行行移動したもの)と簡単なゲームで実験
– 動画(ゲーム)の場合には LSTM を使うと良良い
l ⾒見見る位置から画像を取ってくる部分は微分できない
l そこで強化学習を⾏行行う
– 分類の場合、毎フレーム予測が当たったら報酬がもらえる
– 学習には REINFORCE 法 [Williams, ʻ‘92] と呼ばれる勾配のサンプリング法を使って
いる(NNの強化学習で昔からある⼿手法)
l 強化学習なので分類以外の⽬目的にも使える
– 論論⽂文では簡単なゲームプレイを試している
39](https://image.slidesharecdn.com/pfiseminar20141030rnn-141029232616-conversion-gate02/85/Recurrent-Neural-Networks-39-320.jpg)
![応⽤用:Visual Attention [Mnih+, NIPS ʻ‘14]
l RAM が視線をどう動かすかの可視化
l 論論⽂文にもっといろいろ載ってます
l ゲームプレイの動画:
http://www.cs.toronto.edu/~∼vmnih/docs/attention.mov
l Attention に関する研究(特に NN と絡めた話)はここ最近増えている
ように思う
40](https://image.slidesharecdn.com/pfiseminar20141030rnn-141029232616-conversion-gate02/85/Recurrent-Neural-Networks-40-320.jpg)










![[DL輪読会]Conditional Neural Processes](https://cdn.slidesharecdn.com/ss_thumbnails/conditionalneuralprocesses-180727001730-thumbnail.jpg?width=640&height=640&fit=bounds)







![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)





![SSII2020 [OS2-02] 教師あり事前学習を凌駕する「弱」教師あり事前学習](https://cdn.slidesharecdn.com/ss_thumbnails/200611ssii2020os2weaksupervision-200609142553-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)




























![[旧版] JSAI2018 チュートリアル「"深層学習時代の" ゼロから始める自然言語処理」](https://cdn.slidesharecdn.com/ss_thumbnails/jsai2018tutorialslideshare-180606065226-thumbnail.jpg?width=640&height=640&fit=bounds)


![[最新版] JSAI2018 チュートリアル「"深層学習時代の" ゼロから始める自然言語処理」](https://cdn.slidesharecdn.com/ss_thumbnails/jsai2018tutorialslideshare-180607030706-thumbnail.jpg?width=640&height=640&fit=bounds)

























