【DL輪読会】How Much Can CLIP Benefit Vision-and-Language Tasks?
1.
http://deeplearning.jp/
How Much CanCLIP Benefit Vision-and-Language Tasks?
CLIPは画像×言語タスクにどれだけ貢献できるだろうか?(ICLR 2022)
山本 貴之(ヤフー株式会社)
DEEP LEARNING JP
[DL Papers]
1
2.
書誌情報
How Much CanCLIP Benefit Vision-and-Language Tasks?
CLIPは画像×言語タスクにどれだけ貢献できるだろうか?
https://openreview.net/pdf?id=zf_Ll3HZWgy
タイトル:
著者: Sheng Shen∗†, Liunian Harold Li∗‡, Hao Tan◦ , Mohit Bansal◦ , Anna Rohrbach† , Kai-Wei Chang‡ , Zhewei Yao† and Kurt Keutzer†
†University of California, Berkeley, ‡University of California, Los Angeles ◦University of North Carolina at Chapel Hill
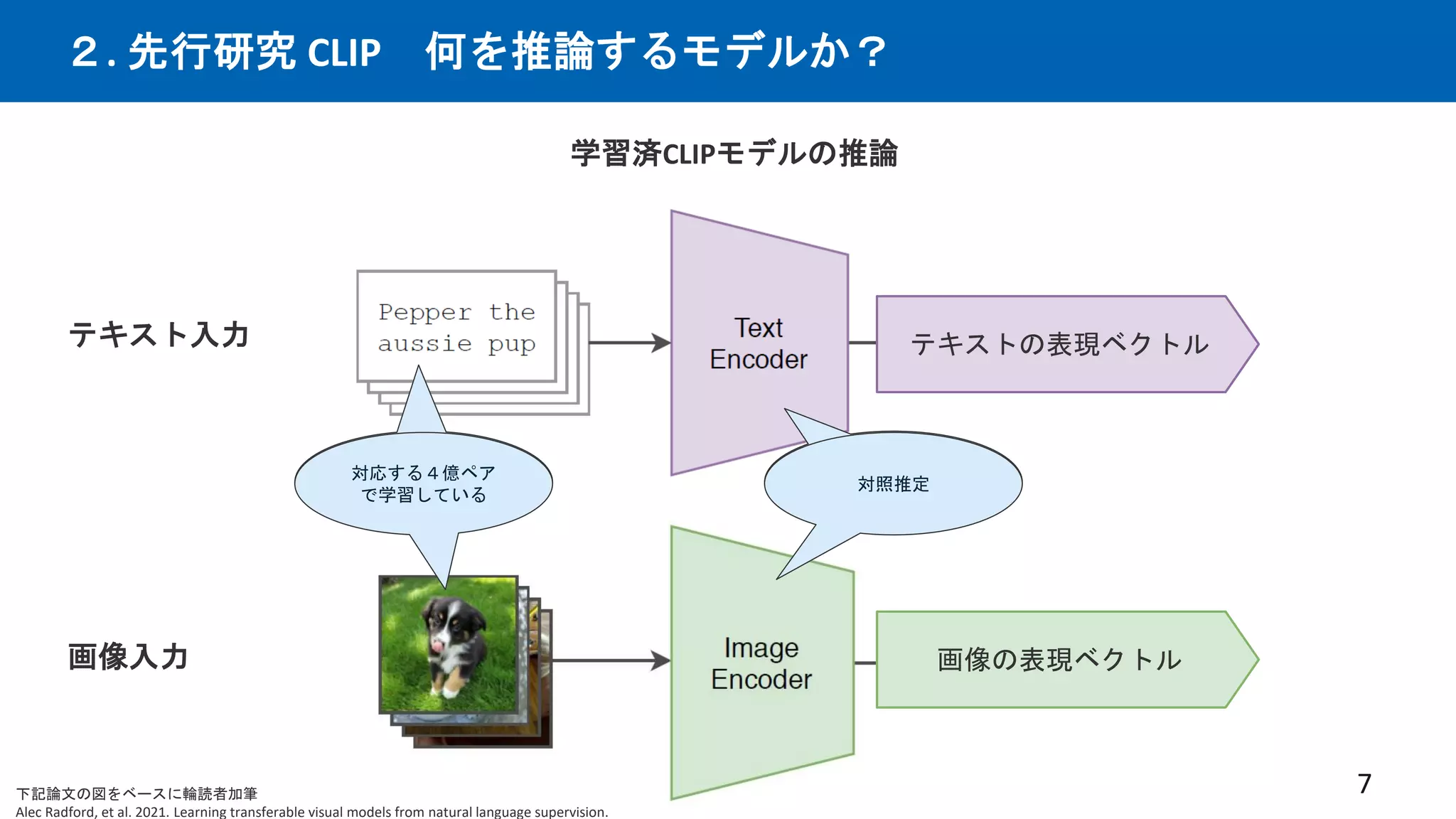
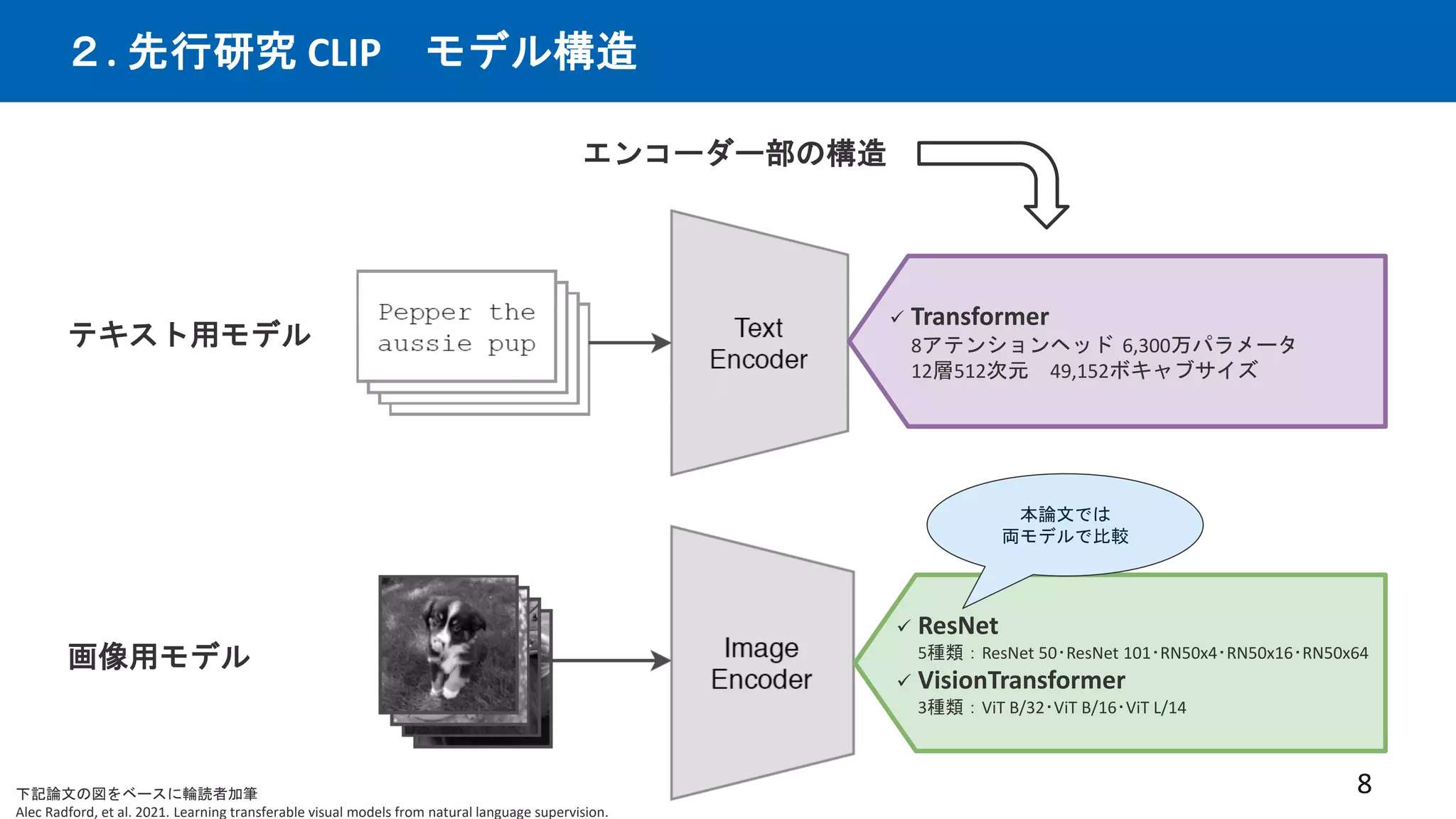
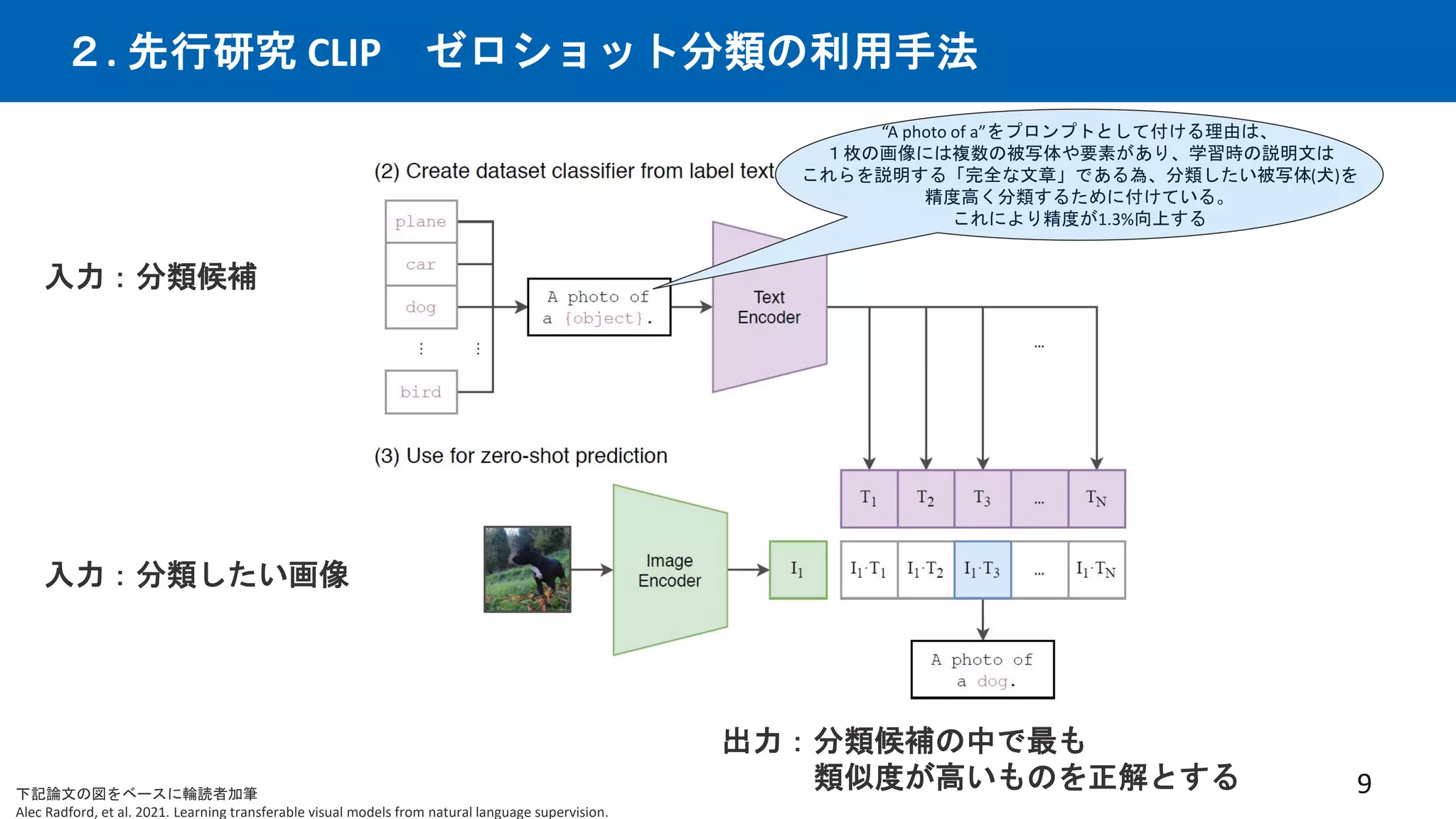
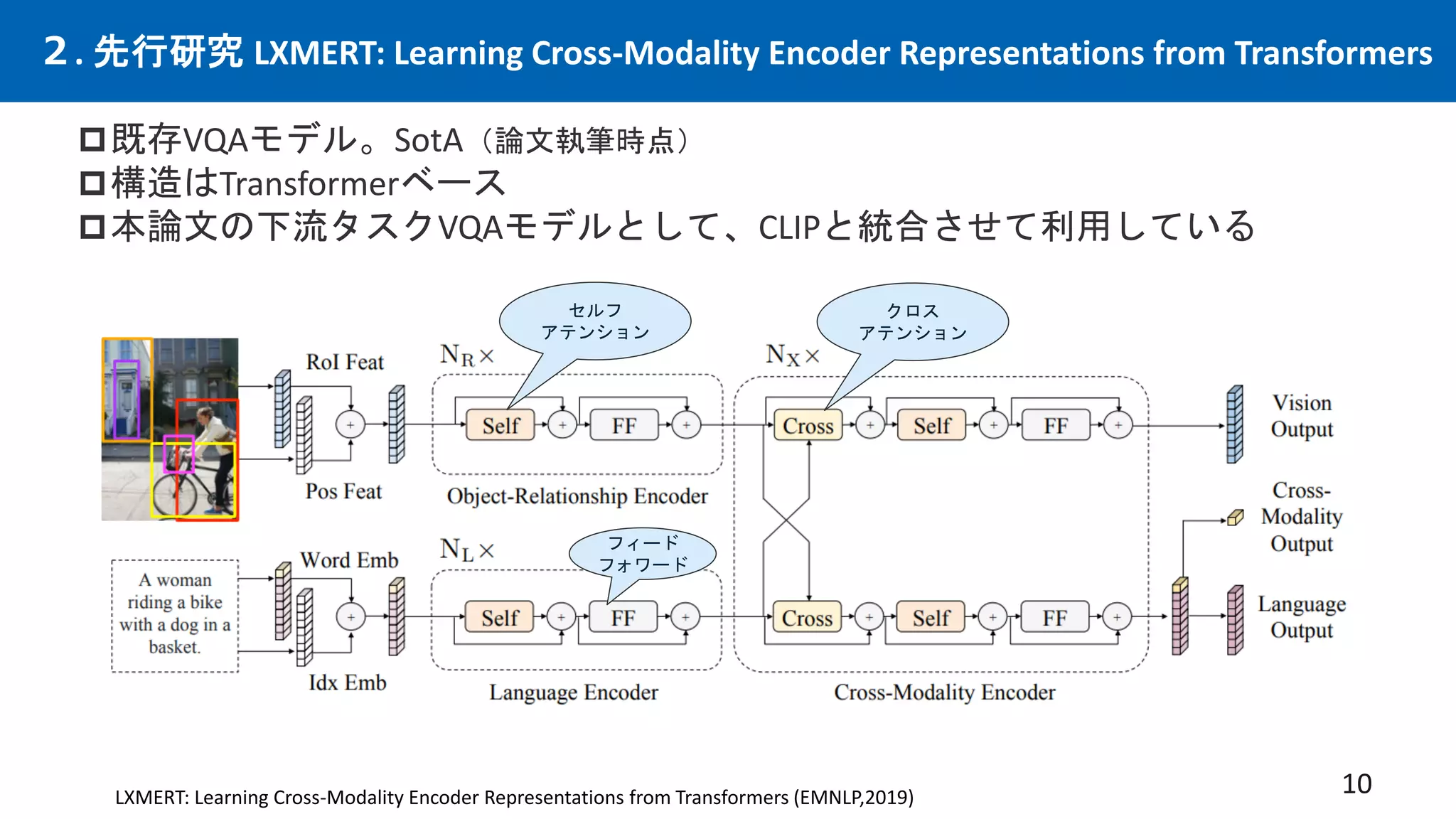
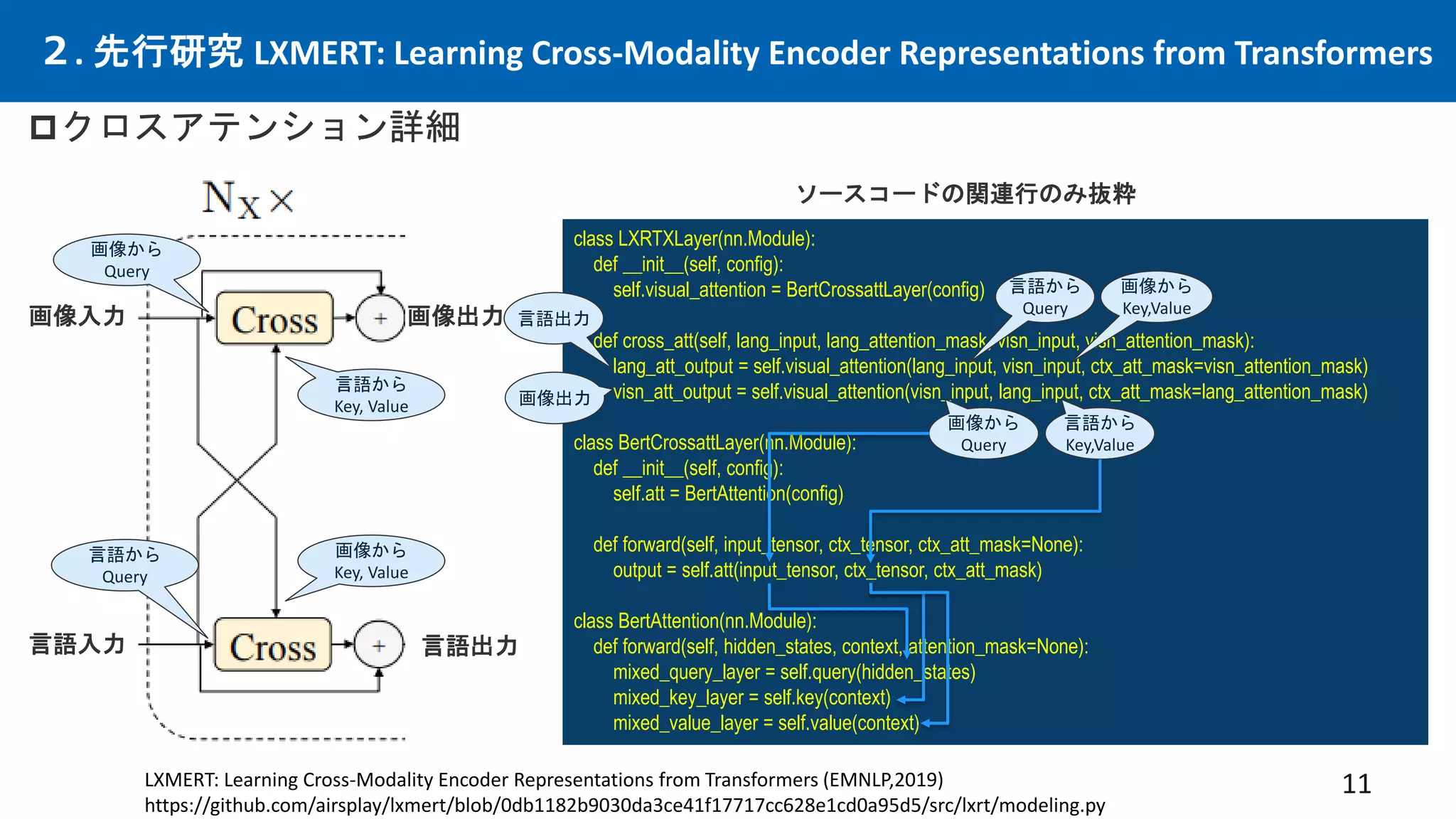
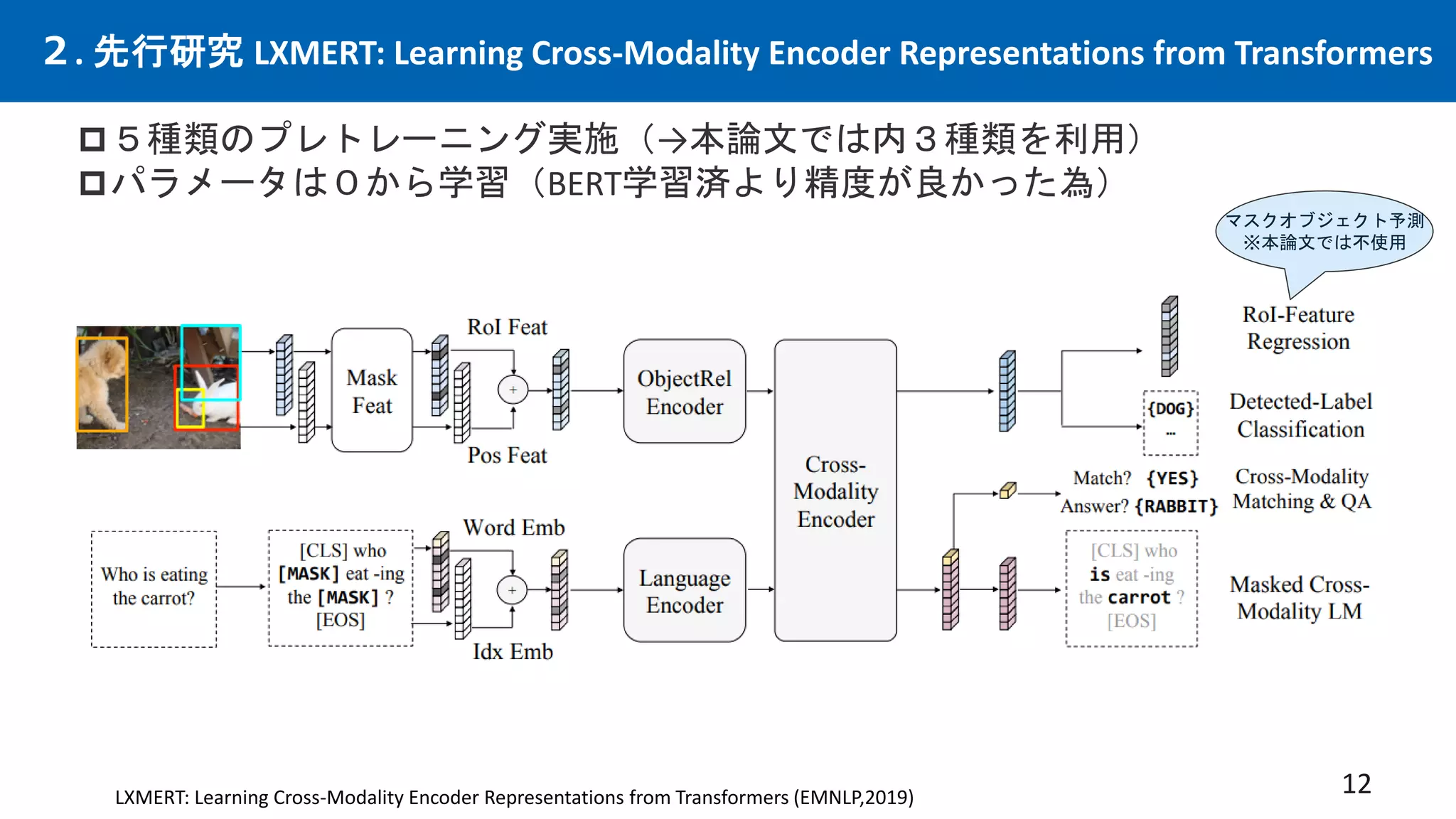
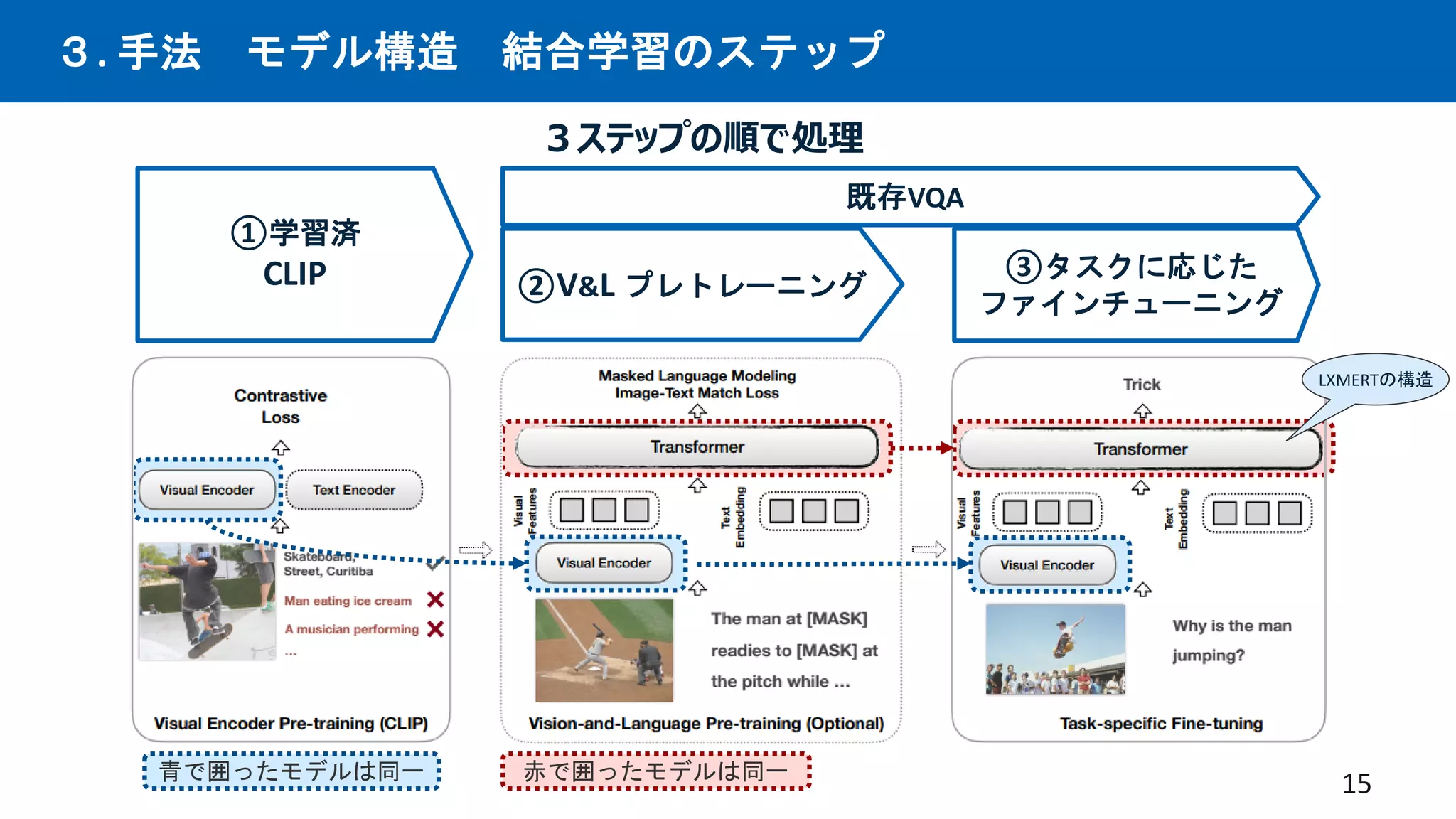
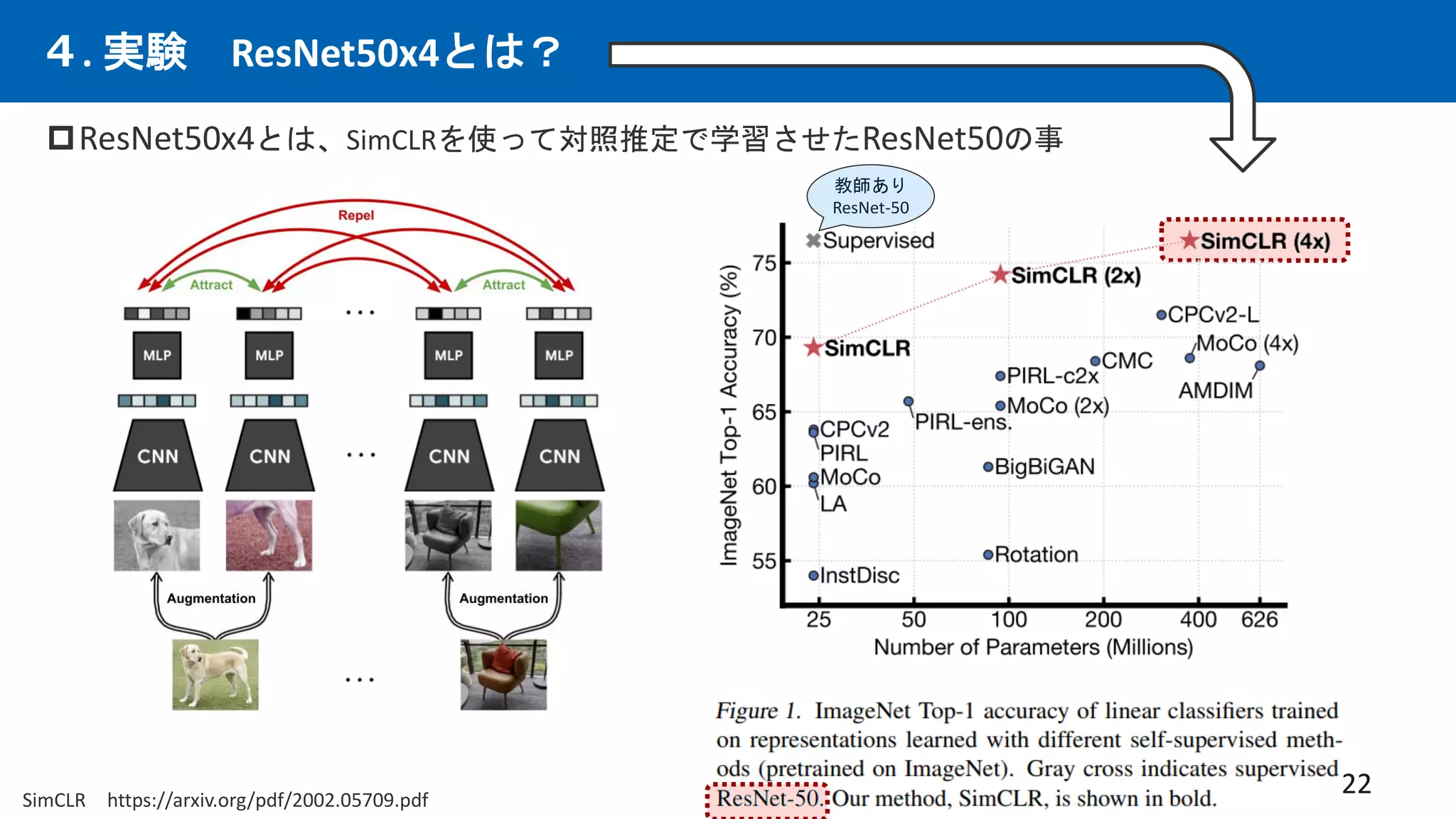
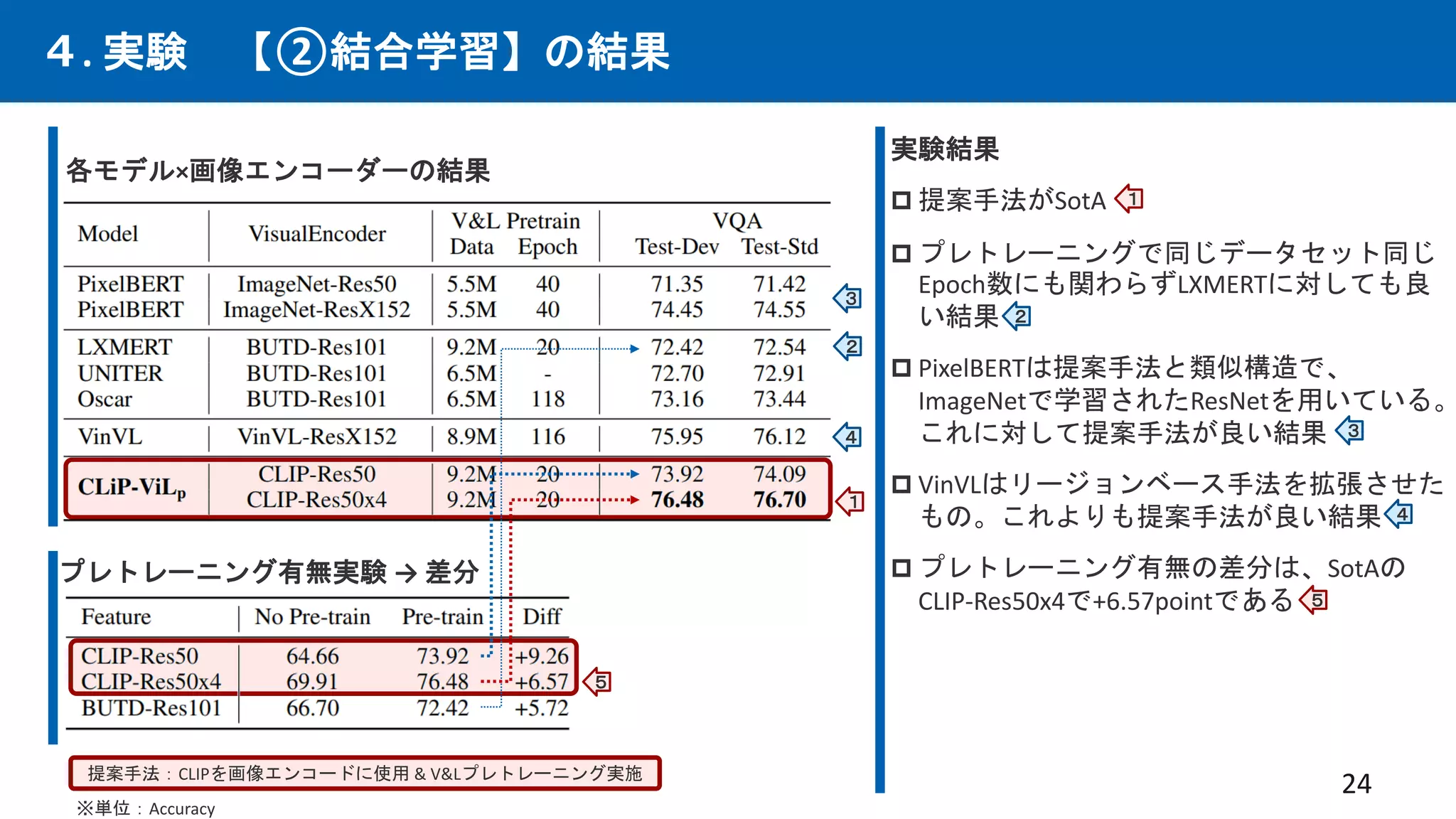
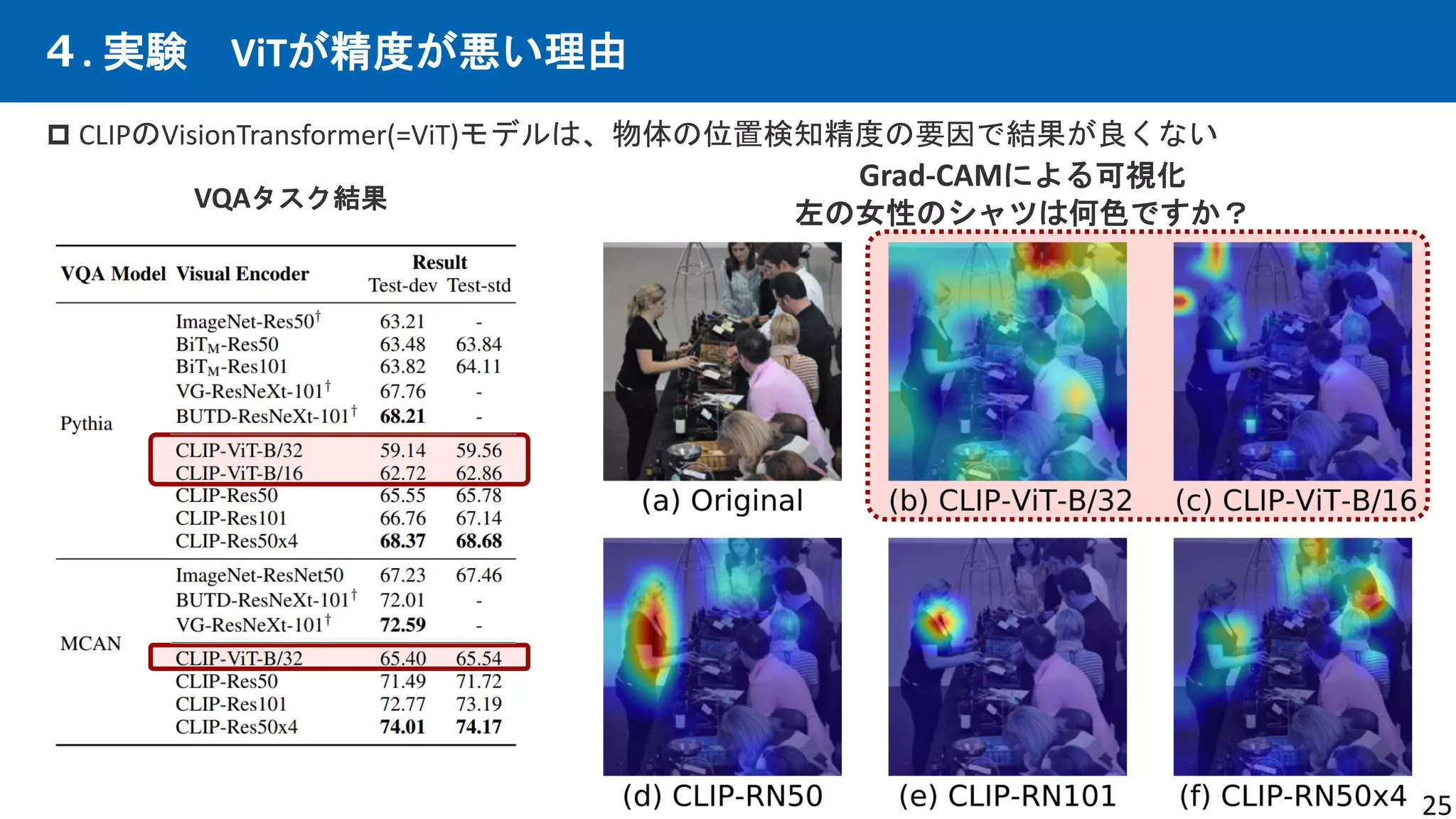
先行研究CLIPは優れた画像×言語エンコーダーという仮定の下、CLIPを下流タスクと統合する事で、
従来の下流タスクでSotAを出せるはずという仮説。多数の実験を行い検証。手法を提案
概要:
2
選定理由: 1) マルチモーダル大規模基盤モデルが、シングルモーダルタスクの性能を上げる(ここへの興味)
2) 言語込でマルチモーダル学習すると、人の知恵の記録である言語の力を活かせるのでは(仮説)
(ICLR 2022 Poster)
公式実装: https://github.com/clip-vil/CLIP-ViL
※出典記載の無い図表は本論文からの引用
![http://deeplearning.jp/
How Much Can CLIP Benefit Vision-and-Language Tasks?
CLIPは画像×言語タスクにどれだけ貢献できるだろうか?(ICLR 2022)
山本 貴之(ヤフー株式会社)
DEEP LEARNING JP
[DL Papers]
1](https://image.slidesharecdn.com/dl20220701clipbenefitfin-220707033349-8c240e7f/75/DL-How-Much-Can-CLIP-Benefit-Vision-and-Language-Tasks-1-2048.jpg)


















![[DL輪読会]MetaFormer is Actually What You Need for Vision](https://cdn.slidesharecdn.com/ss_thumbnails/20220121metaformer-220121085750-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Object-Centric Learning with Slot Attention](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0717-200717023021-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]Disentangling by Factorising](https://cdn.slidesharecdn.com/ss_thumbnails/20180720disentanglingbyfactorising-180720000930-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Life-Long Disentangled Representation Learning with Cross-Domain Laten...](https://cdn.slidesharecdn.com/ss_thumbnails/20180914iwasawa-180919025635-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]An Image is Worth 16x16 Words: Transformers for Image Recognition at S...](https://cdn.slidesharecdn.com/ss_thumbnails/dl10161-201016015214-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]The Neuro-Symbolic Concept Learner: Interpreting Scenes, Words, and Se...](https://cdn.slidesharecdn.com/ss_thumbnails/theneuro-symbolicconceptlearnerinterpretingsceneswordsandsentencesfromnaturalsupervision-190906012005-thumbnail.jpg?width=640&height=640&fit=bounds)











![[DL輪読会]One Model To Learn Them All](https://cdn.slidesharecdn.com/ss_thumbnails/dljp20170714ono-170714005853-thumbnail.jpg?width=640&height=640&fit=bounds)



































