本論文の選定理由
• ACL 2012Tutorial Deep Learning for NLPにて紹介さ
れている
• 代表的なNLPタスクにDeep Learningを適用している
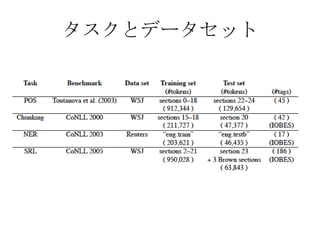
– POS tagging
– Chunking
– Named Entity Recognition
– Semantic Role Labeling
• NLP with Deep Learningの代表的な研究者が執筆し
ている
– Chris Manning
– Ronan Collobert
3.
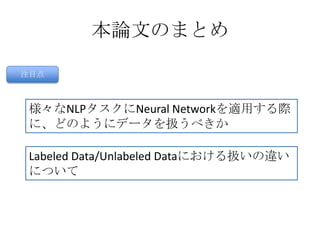
本論文のまとめ
目的
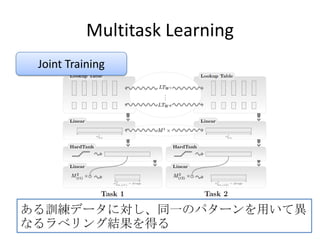
Propose a unifiedneural network architecture and
learning algorithm that can be applied to various
NLP tasks
POS tagging, Chunking, NER, SLR
結論
人手でfeatureを作成する代わりに、大量のlabeled/unlabeled training
dataからinternal representationを学習する
本研究の成果は、高精度で低計算コストなfreely available tagging
systemを構築するための基礎となる
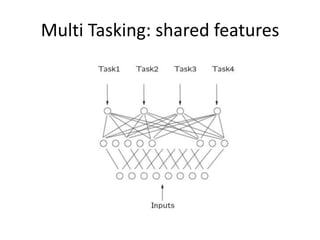
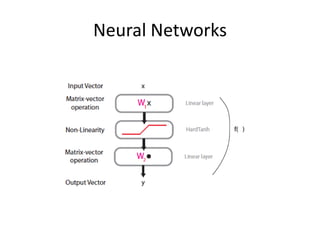
提案手法
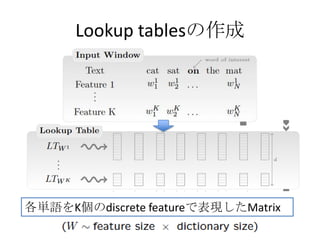
• Transforming wordinto Feature Vectors
• Extracting Higher Level Features from Word
Feature Vectors
• Training
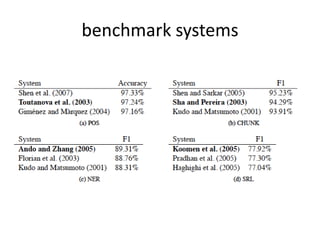
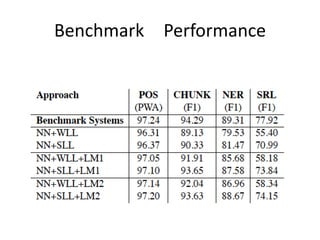
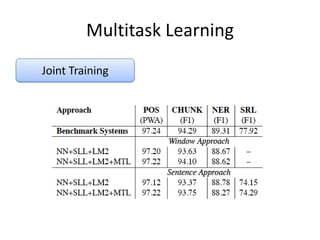
• Benchmark Result
37.
Pre Processing
• uselower case words in the dictionary
• add “caps” feature to words had at least one
non-initial capital letter
• number with in a word are replace with the
string “NUMBER”
Lots of UnlabeledData
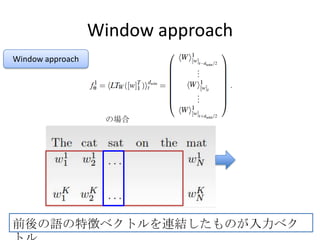
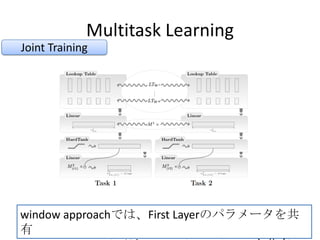
• Two window approach (11) networks (100HU) trained on
two corpus
• LM1
– Wikipedia: 631 Mwords
– order dictionary words by frequency
– increase dictionary size: 5000, 10; 000, 30; 000, 50; 000, 100;
000
– 4 weeks of training
• LM2
– Wikipedia + Reuter=631+221=852M words
– initialized with LM1, dictionary size is 130; 000
– 30,000 additional most frequent Reuters words
– 3 additional weeks of training
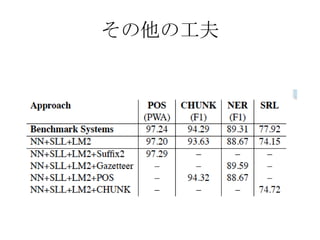
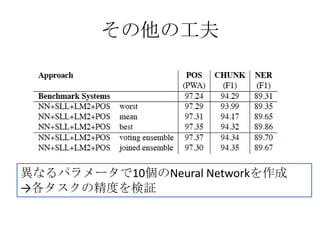
その他の工夫
• Suffix Features
–Use last two characters as feature
• Gazetters
– 8,000 locations, person names, organizations and
misc entries from CoNLL2003
• POS
– use POS as a feature for CHUNK &NER
• CHUNK
– use CHUNK as a feature for SRL
Conclusion
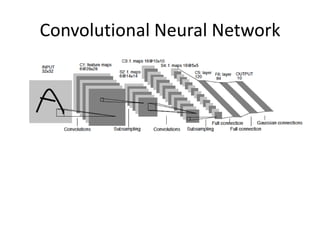
• Achievements
– “Allpurpose" neural network architecture for NLP tagging
– Limit task-specic engineering
– Rely on very large unlabeled datasets
– We do not plan to stop here
• Critics
– Why forgetting NLP expertise for neural network training
skills?
• NLP goals are not limited to existing NLP task
• Excessive task-specic engineering is not desirable
– Why neural networks?
• Scale on massive datasets
• Discover hidden representations
• Most of neural network technology existed in 1997 (Bottou, 1997)




























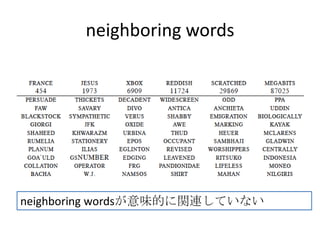













![[DL輪読会]Parallel WaveNet: Fast High-Fidelity Speech Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/0105-180105000252-thumbnail.jpg?width=640&height=640&fit=bounds)




















![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)


















![[DL輪読会]Convolutional Sequence to Sequence Learning](https://cdn.slidesharecdn.com/ss_thumbnails/dl0519-170519005603-thumbnail.jpg?width=640&height=640&fit=bounds)



![[PaperReading]Unsupervised Discrete Sentence Representation Learning for Inte...](https://cdn.slidesharecdn.com/ss_thumbnails/paperreading-20180702shinoda-180702111612-thumbnail.jpg?width=640&height=640&fit=bounds)
![[ML論文読み会資料] Teaching Machines to Read and Comprehend](https://cdn.slidesharecdn.com/ss_thumbnails/ml2-171222014201-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]It's not just size that maters small language models are also few sho...](https://cdn.slidesharecdn.com/ss_thumbnails/itsnotjustsizethatmaterssmalllanguagemodelsarealsofew-shotlearners-210910034516-thumbnail.jpg?width=640&height=640&fit=bounds)

![[旧版] JSAI2018 チュートリアル「"深層学習時代の" ゼロから始める自然言語処理」](https://cdn.slidesharecdn.com/ss_thumbnails/jsai2018tutorialslideshare-180606065226-thumbnail.jpg?width=640&height=640&fit=bounds)
















