Extract and Edit:
AnAlternative to Back-Translation
for Unsupervised Neural Machine
Translation [1]
2019/07/23
1
[1] Wu, Jiawei, Xin Wang, and William Yang Wang. "Extract and Edit: An
Alternative to Back-Translation for Unsupervised Neural Machine
Translation." arXiv preprint arXiv:1904.02331(2019).
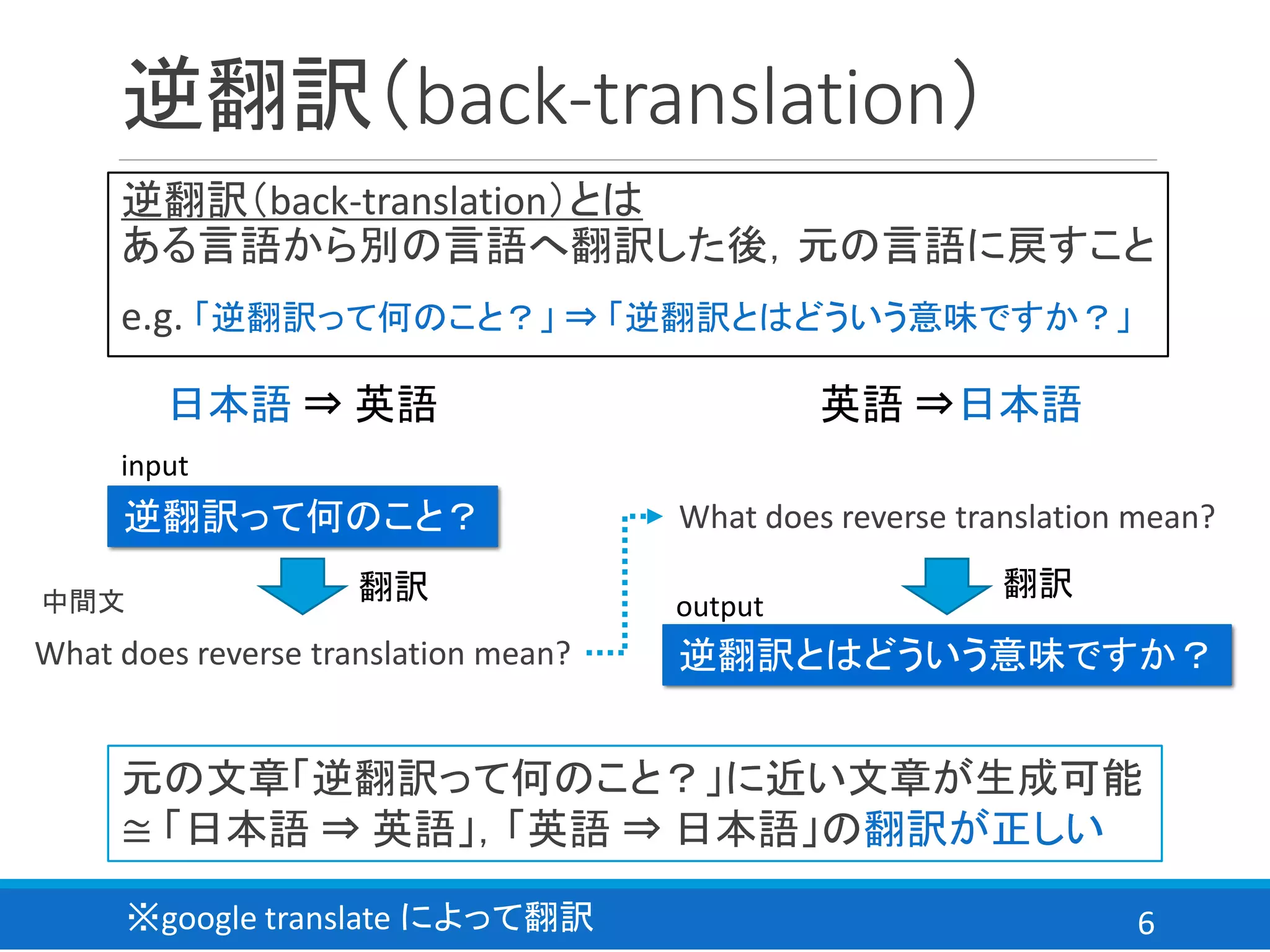
※大変なので,今回はほとんど作図してません.
26
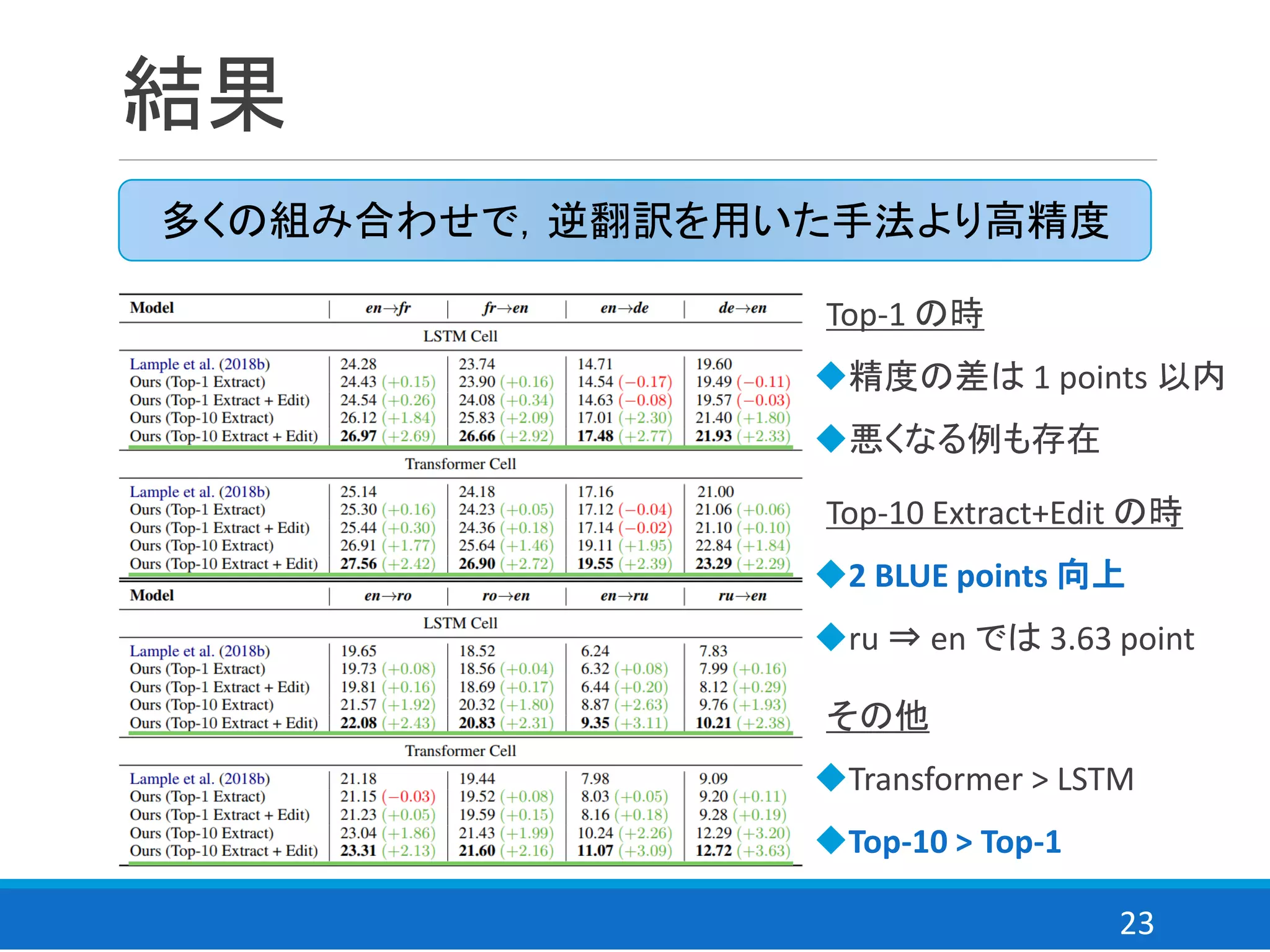
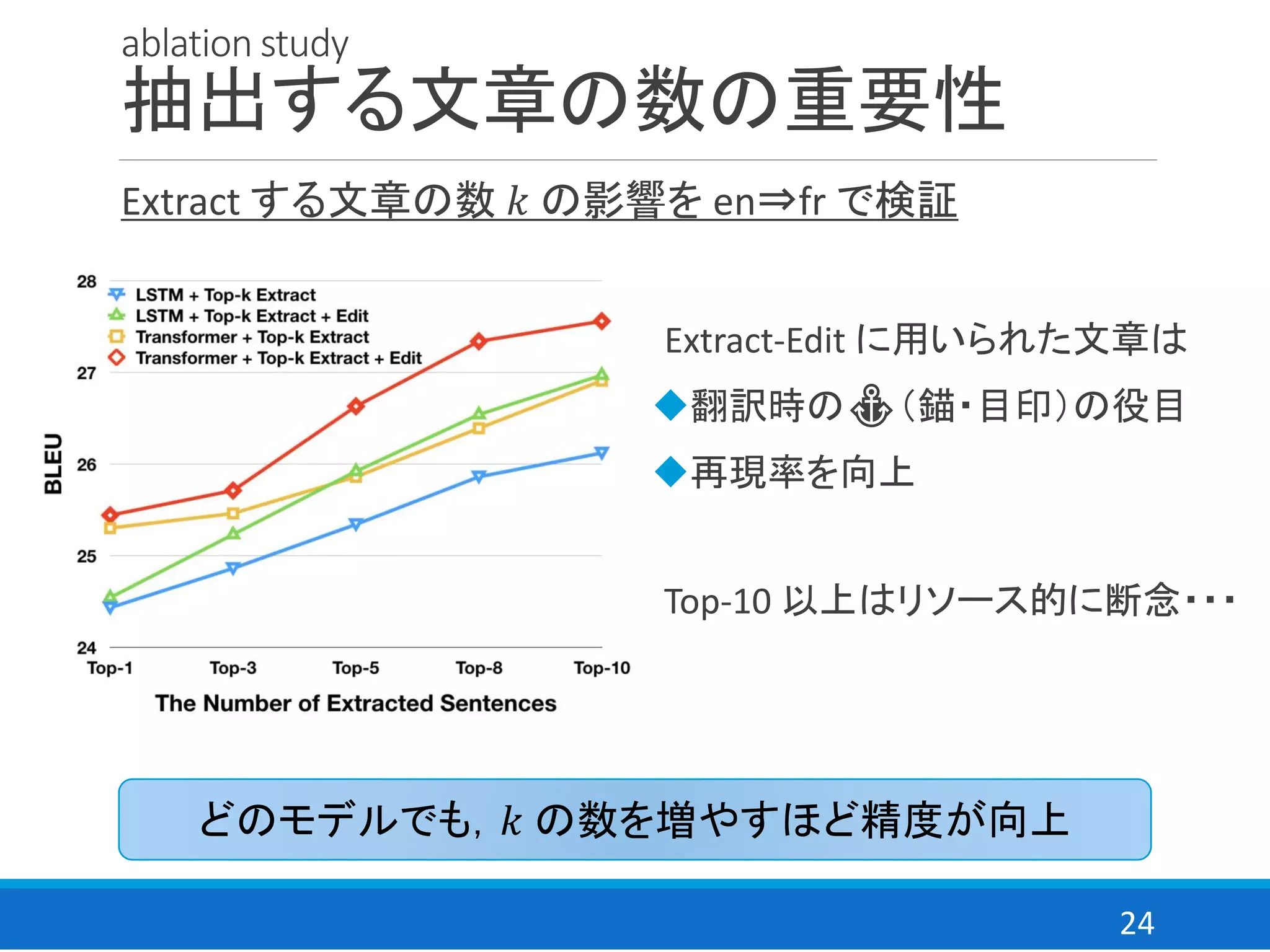
ablation study
comparable lossの効果
comparable translation loss の効果を en⇒fr で検証
Extract-Edit による文を正解として最尤推定した場合と比較※
comparable loss により,ノイズの影響を避けて学習可能
最尤推定(Maximum Likelihood Estimation)
= 通常の学習をした場合
⇒ 精度が 50%減
◆ニューラル機械翻訳はノイズの割合が強く影響
◆comparable loss はノイズとなる文を多く抽出しても学習可能
※本来の対訳コーパスを Extract-Edit によって拡張したデータで
comparable loss ではなく,MLE loss を用いて学習した場合
27.
27
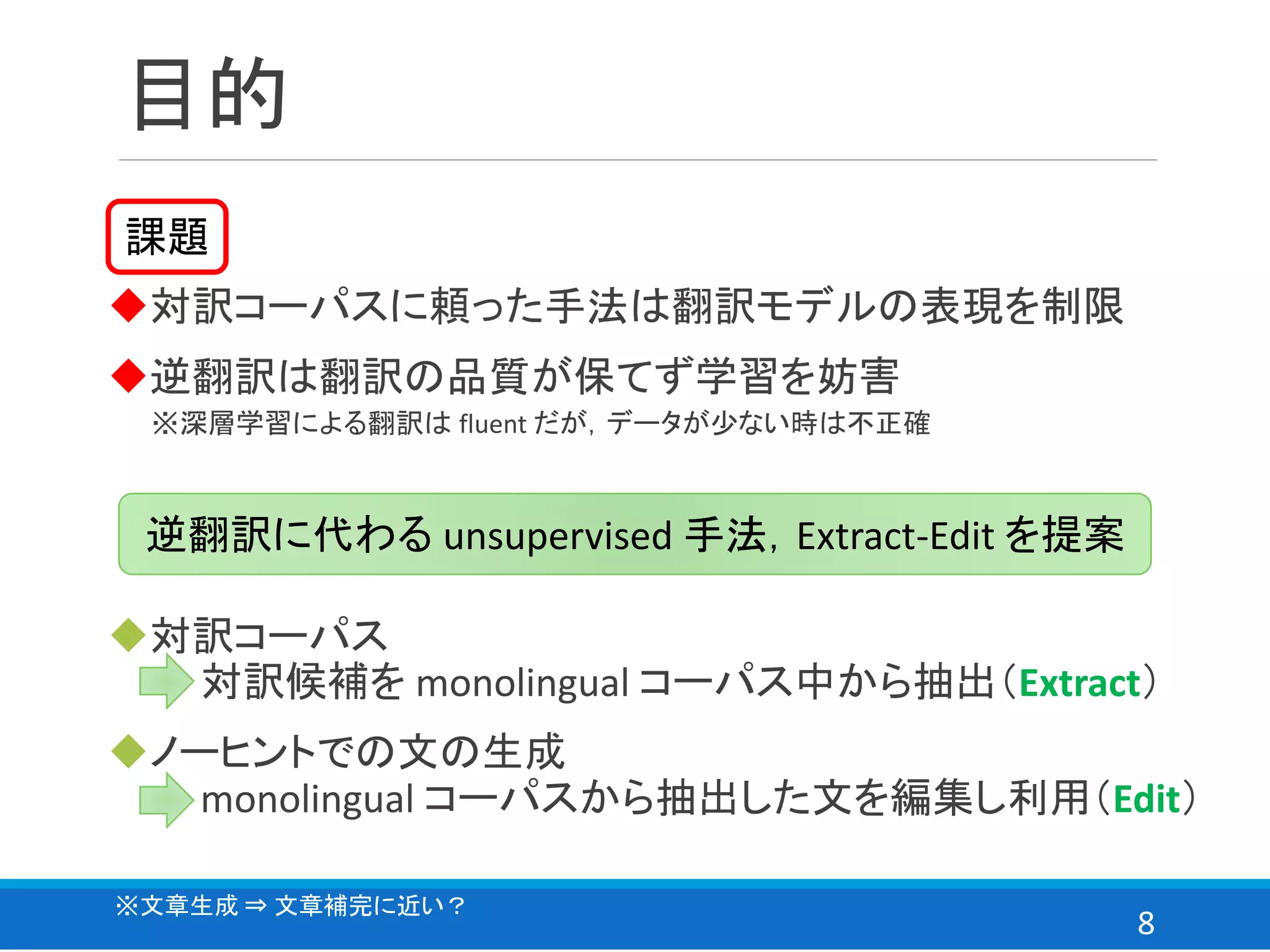
まとめ
◆reconstruction loss からcomparable loss へ
◆Extract-Edit に使用した文章は翻訳時の⚓(錨)であり目印
◆Top-10 Extract+Edit の時,2 BLUE points 向上
逆翻訳に代わる unsupervised 手法,Extract-Edit を提案
2言語間でドメインの重複が多い程,精度が向上
⇒ Wikipedia や news 記事を用いても精度が向上するかも?
今後の発展
28.
おまけ
◆ supervised と比べると?
⇒まだまだ良くはない
◆ 一方,1位は
Transformer + back-translation
⇒ 今後の発展に期待
[9] paper with code,
https://paperswithcode.com/sota/
machine-translation-on-wmt2014-
english-French 2019/07/23
28
Transformer
+ back-translation
Transformer[5]
seq2seq[4]
比較手法’[7]
比較手法[7]
今回(27.56)
paper with code の WMT en-fr [9]
※今回は比較対象外
29.
29
参考文献
[4] Sutskever, Ilya,Oriol Vinyals, and Quoc V. Le. "Sequence to sequence learning
with neural networks." In Advances in neural information processing systems, pp.
3104-3112. 2014.
[5] Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones,
Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. "Attention is all you need."
In Advances in neural information processing systems, pp. 5998-6008. 2017.
[6] 根石 将人,吉永 直樹.”英日翻訳タスクにおけるスワップモデルを通した
seq2seq と Transformer の比較” 言語処理学会(2019).
https://www.anlp.jp/proceedings/annual_meeting/2019/pdf_dir/P5-21.pdf
「Phrase-Based & Neural Unsupervised Machine Translation.」‘s video,
https://vimeo.com/306145842
![Extract and Edit:
An Alternative to Back-Translation
for Unsupervised Neural Machine
Translation [1]
2019/07/23
1
[1] Wu, Jiawei, Xin Wang, and William Yang Wang. "Extract and Edit: An
Alternative to Back-Translation for Unsupervised Neural Machine
Translation." arXiv preprint arXiv:1904.02331(2019).
※大変なので,今回はほとんど作図してません.](https://image.slidesharecdn.com/extractandedit-190723082004/75/Extract-and-edit-1-2048.jpg)




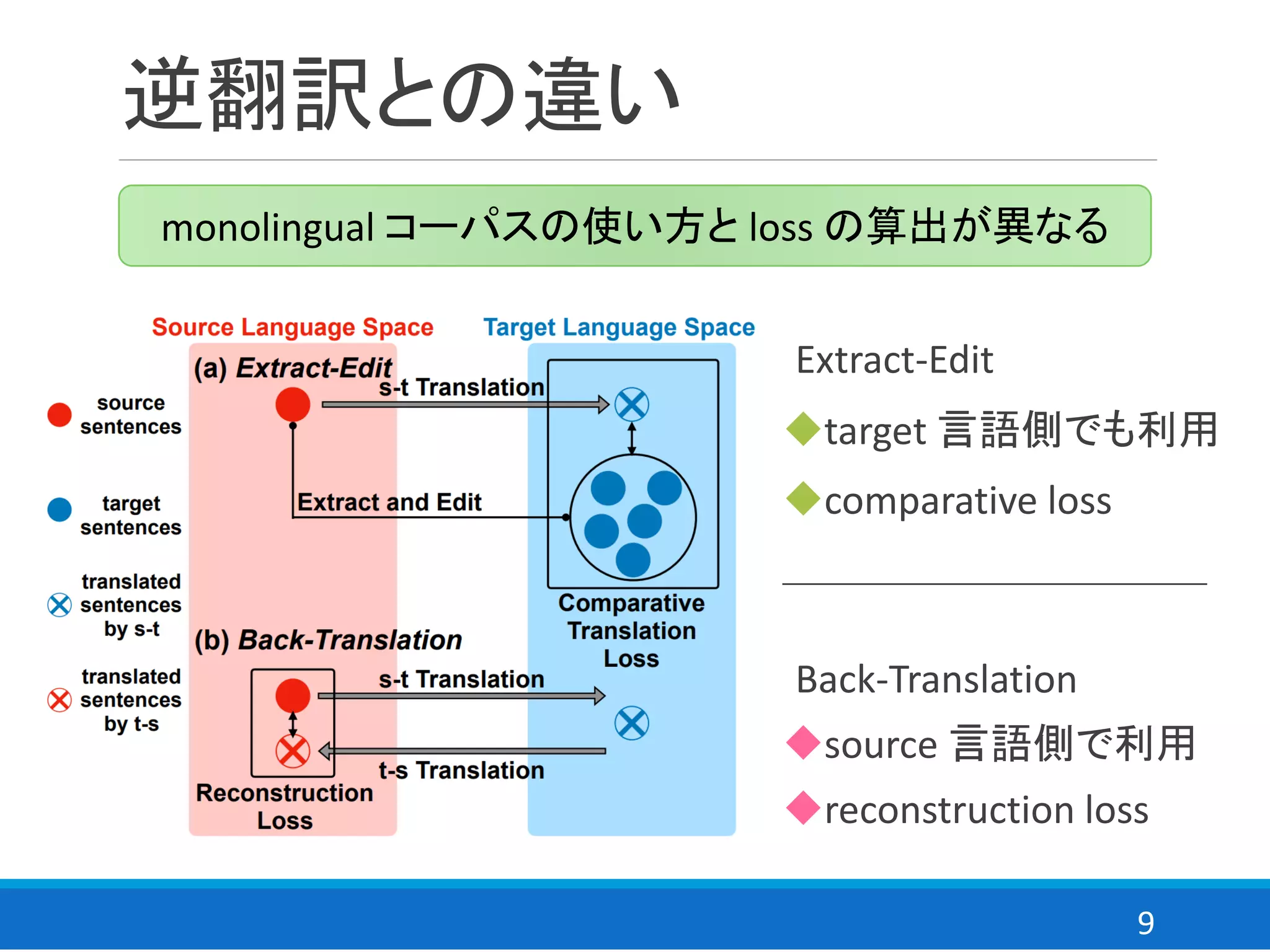
![7
逆翻訳の抱える課題
逆翻訳は対訳コーパスを必要としない学習手法
逆翻訳は元の文章を再生成するシナリオ
⇒ ・・・これは,Auto Encoder (AE) の一種では!
Lample らは Denoising AE, discriminator の両方を使用[2]
逆翻訳は AE と類似し,モデルが持つ性質も類似
AE はぼやけた画像を生成し,詳細な画像の生成が困難
⇒ 逆翻訳における翻訳(特に中間文)もぼやけた文に
[2] Lample, Guillaume, Alexis Conneau, Ludovic Denoyer, and Marc'Aurelio Ranzato. "Unsupervised
machine translation using monolingual corpora only." arXiv preprint arXiv:1711.00043 (2017).](https://image.slidesharecdn.com/extractandedit-190723082004/75/Extract-and-edit-7-2048.jpg)
![10
関連研究
Comparable Corpora Mining
BiRNN による識別器
[3] Grégoire, Francis, and Philippe Langlais. "Extracting parallel sentences with bidirectional recurrent
neural networks to improve machine translation." arXiv preprint arXiv:1806.05559(2018).
学習した識別器を用いて対訳文を見つける試み
source language target language
ラベルの振られた target 文を識別
◆正例:対訳文
◆負例:negative sampling による文
80% 近い precision を達成
◆919k の対訳文を使用し学習
◆未知の対訳文で検証](https://image.slidesharecdn.com/extractandedit-190723082004/75/Extract-and-edit-10-2048.jpg)
![11
関連研究
一般的な翻訳モデル
seq2seq[4, 6]
Recurrent Neural Network (RNN) によるエンコーダ・デコーダ
Transformer[5]
Attention 構造と全結合層によるエンコーダ・デコーダ
エンコーダ デコーダ
エンコーダ デコーダ
ℎ0 ℎ1 ℎ2 ℎ3
ℎ 𝑓𝑖𝑛𝑎𝑙
𝒉
: RNN の各 cell
ℎ0: 0番目の隠れ層の状態
ℎ 𝑓𝑖𝑛𝑎𝑙: 2層のbiRNNの結合
𝒉 = [ℎ0, ℎ1, ℎ2, ℎ3]
: Attention 構造
◆ Attention による接続
◆ Attention 構造後に順序
毎に独立の全結合層
ℎ0 ℎ1 ℎ2 ℎ3
𝒉](https://image.slidesharecdn.com/extractandedit-190723082004/75/Extract-and-edit-11-2048.jpg)
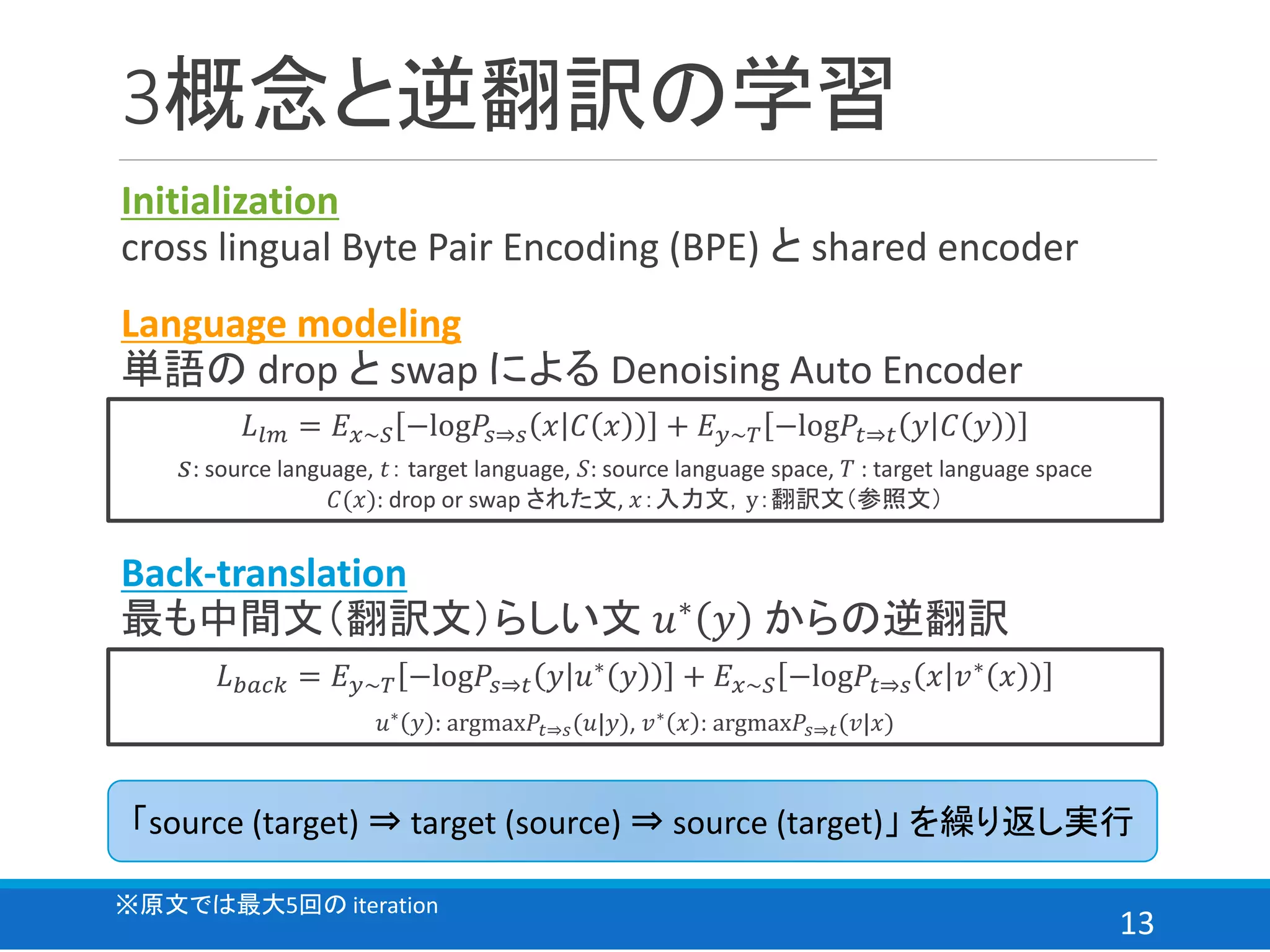
![12
関連研究
back-translation における3概念[7]
各言語の
文章が存在
Initialization
言語間の
分布を整理
Language
modeling
データの構造
を推論
Back-
translation
翻訳と逆翻訳
3つの概念に従い学習
[7] Lample, Guillaume, Myle Ott, Alexis Conneau, Ludovic Denoyer, and Marc'Aurelio Ranzato.
"Phrase-based & neural unsupervised machine translation." arXiv preprint arXiv:1804.07755 (2018).](https://image.slidesharecdn.com/extractandedit-190723082004/75/Extract-and-edit-12-2048.jpg)


![17
Learning
学習に関連するパラメータ
𝜃𝑒𝑛𝑐: encoder (LSTM or Transformer)
𝜃 𝑑𝑒𝑐: decoder (LSTM or Transformer)
𝜃 𝑅: evaluation network (多層パーセプトロン)
学習に使用される誤差関数
min
𝜃 𝑒𝑛𝑐,𝜃 𝑑𝑒𝑐
max
𝜃 𝑅
𝐿(𝜃𝑒𝑛𝑐, 𝜃 𝑑𝑒𝑐, 𝜃 𝑅)
= −𝐿 𝑅 𝜃 𝑅 + 𝐿 𝑠⇒𝑡(𝜃𝑒𝑛𝑐, 𝜃 𝑑𝑒𝑐|𝜃 𝑅)
Extract-Edit を generator, Evaluate を discriminator とし学習(≅ GAN)
adversarial comparable + Language Model
GAN[8] の minimax 関数
min
𝑑𝑖𝑠𝑐𝑟𝑖𝑚𝑖𝑛𝑎𝑡𝑜𝑟
max
𝑔𝑒𝑛𝑒𝑟𝑎𝑡𝑜𝑟
𝑉(𝑑𝑖𝑠𝑐𝑟𝑖𝑚𝑖𝑛𝑎𝑡𝑜𝑟, 𝑔𝑒𝑛𝑒𝑟𝑎𝑡𝑜𝑟)
[8] Goodfellow, Ian, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and
Yoshua Bengio. "Generative adversarial nets." In Advances in neural information processing systems, pp. 2672-2680. 2014.](https://image.slidesharecdn.com/extractandedit-190723082004/75/Extract-and-edit-17-2048.jpg)

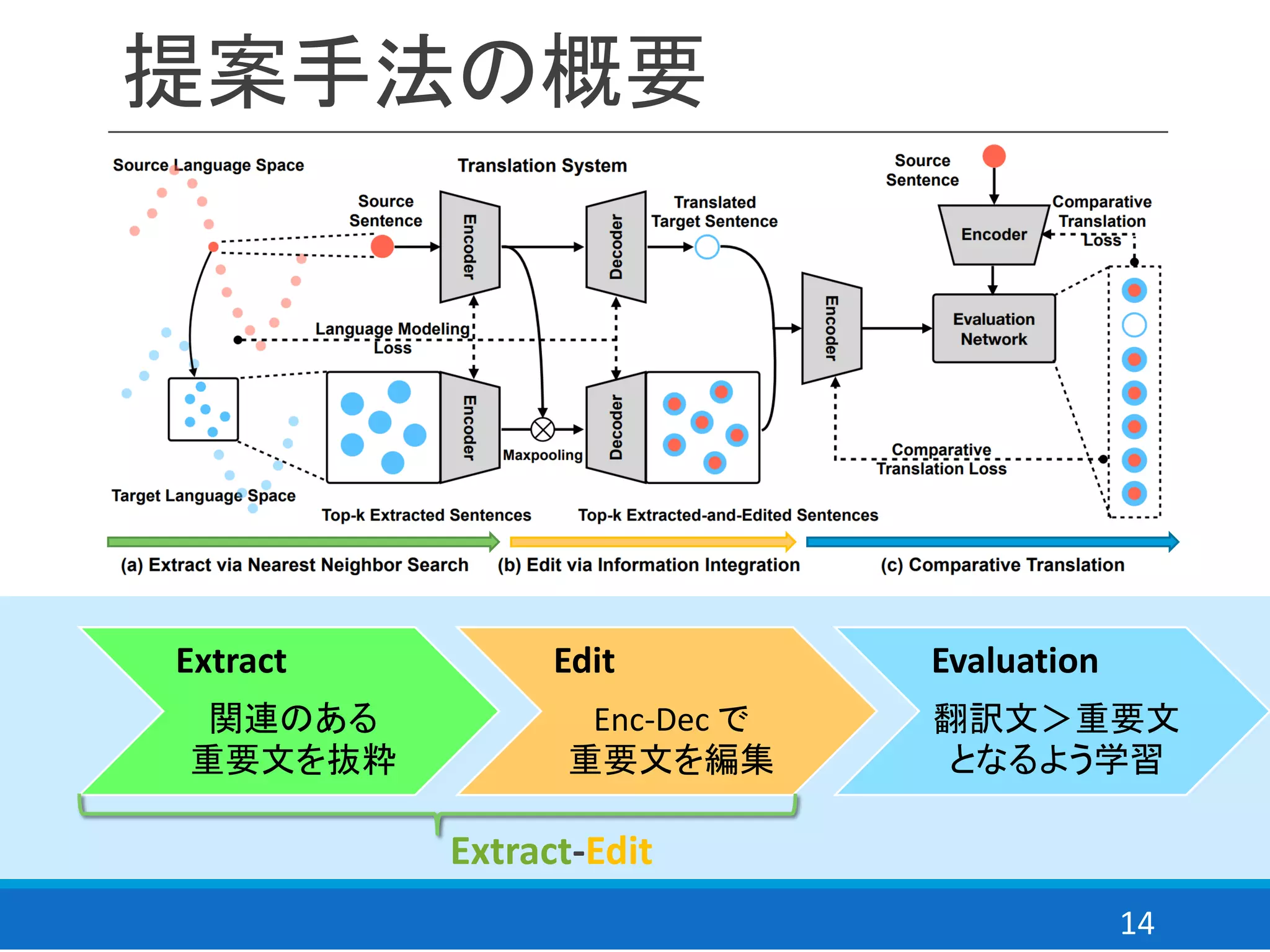
![学習全体の流れ
1. Extract
2. Edit
3. Evaluate
4. evaluate network の更新
5. encoder, decoder の更新
6. 翻訳モデル(言語モデル?)の更新
19
学習の流れとモデル選択
モデル選択
翻訳文の順位の期待値(> Extracted-Edit)によりモデル選択
𝐷𝑠⇒𝑡 = 𝐸𝑠∈𝑆[𝐸(log𝑃 𝑡∗
= 𝑉𝑠⇒𝑡 𝑠 |𝑠, 𝑀′ )]
※対訳文は用いない
1~6の繰り返し](https://image.slidesharecdn.com/extractandedit-190723082004/75/Extract-and-edit-19-2048.jpg)
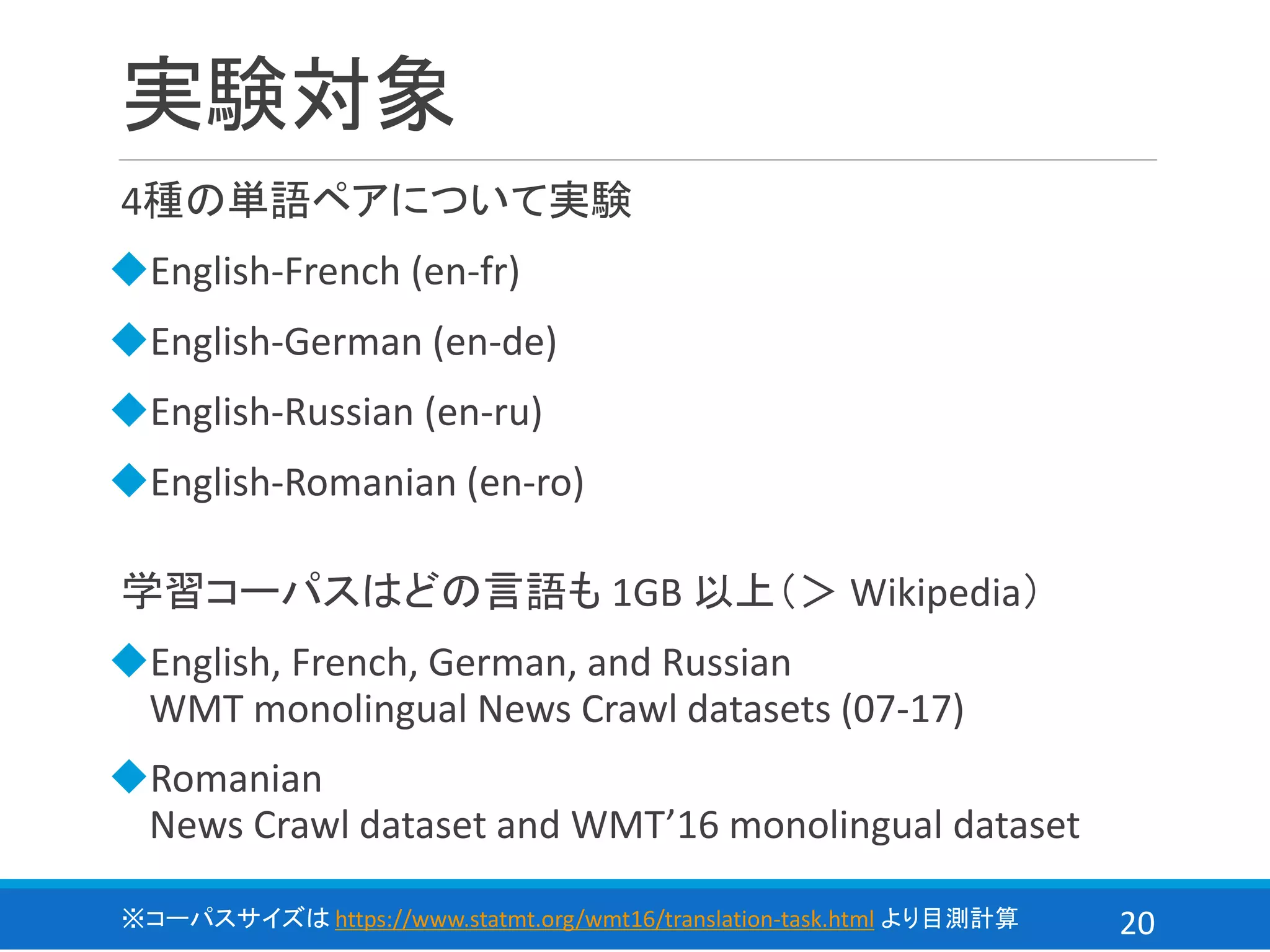
![21
評価方法
評価実験
各言語が 3k sentence ある newstest を使用
◆2014年: en-fr
◆2016年: en-de, en-ru, en-ro
比較手法
lample らの unsupervised NMT[7]
評価指標
BLUE = 𝐵𝑃𝐵𝐿𝑈𝐸 ∙ exp(σ 𝑛=1
𝑁 1
𝑁
log𝑝 𝑛)
𝑝 𝑛:
σ 𝑖 翻訳文 𝑖 と参照訳 𝑖 で一致した 𝑛−𝑔𝑟𝑎𝑚 数
σ 𝑖 翻訳文 𝑖 中の 𝑛−𝑔𝑟𝑎𝑚 数
, 𝐵𝑃𝐵𝐿𝑈𝐸: 翻訳文が短い際のペナルティ](https://image.slidesharecdn.com/extractandedit-190723082004/75/Extract-and-edit-21-2048.jpg)
![25
ablation study
抽出された文章の品質の検証
Extract された文章の質を en⇒fr で検証
Grégoire らの supervised 手法[3]と抽出のヒット率@𝑘を比較
精度と計算コストの観点から,𝑘 = 10 が最適と再確認
◆文章の数 𝑘 を増やすと,Grégoire らの手法に近い精度に
◆ノイズを増やすと精度が低下.ノイズに弱い可能性
※ノイズは検証のため](https://image.slidesharecdn.com/extractandedit-190723082004/75/Extract-and-edit-25-2048.jpg)


![おまけ
◆ supervised と比べると?
⇒ まだまだ良くはない
◆ 一方,1位は
Transformer + back-translation
⇒ 今後の発展に期待
[9] paper with code,
https://paperswithcode.com/sota/
machine-translation-on-wmt2014-
english-French 2019/07/23
28
Transformer
+ back-translation
Transformer[5]
seq2seq[4]
比較手法’[7]
比較手法[7]
今回(27.56)
paper with code の WMT en-fr [9]
※今回は比較対象外](https://image.slidesharecdn.com/extractandedit-190723082004/75/Extract-and-edit-28-2048.jpg)
![29
参考文献
[4] Sutskever, Ilya, Oriol Vinyals, and Quoc V. Le. "Sequence to sequence learning
with neural networks." In Advances in neural information processing systems, pp.
3104-3112. 2014.
[5] Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones,
Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. "Attention is all you need."
In Advances in neural information processing systems, pp. 5998-6008. 2017.
[6] 根石 将人,吉永 直樹.”英日翻訳タスクにおけるスワップモデルを通した
seq2seq と Transformer の比較” 言語処理学会(2019).
https://www.anlp.jp/proceedings/annual_meeting/2019/pdf_dir/P5-21.pdf
「Phrase-Based & Neural Unsupervised Machine Translation.」‘s video,
https://vimeo.com/306145842](https://image.slidesharecdn.com/extractandedit-190723082004/75/Extract-and-edit-29-2048.jpg)




![[DL輪読会]BERT: Pre-training of Deep Bidirectional Transformers for Language Und...](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20181019-181019010218-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]ドメイン転移と不変表現に関するサーベイ](https://cdn.slidesharecdn.com/ss_thumbnails/20190614iwasawa-190614005939-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]It's not just size that maters small language models are also few sho...](https://cdn.slidesharecdn.com/ss_thumbnails/itsnotjustsizethatmaterssmalllanguagemodelsarealsofew-shotlearners-210910034516-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)













![[最新版] JSAI2018 チュートリアル「"深層学習時代の" ゼロから始める自然言語処理」](https://cdn.slidesharecdn.com/ss_thumbnails/jsai2018tutorialslideshare-180607030706-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]Unsupervised Neural Machine Translation](https://cdn.slidesharecdn.com/ss_thumbnails/dlyokota20180316-180316003237-thumbnail.jpg?width=640&height=640&fit=bounds)


![[旧版] JSAI2018 チュートリアル「"深層学習時代の" ゼロから始める自然言語処理」](https://cdn.slidesharecdn.com/ss_thumbnails/jsai2018tutorialslideshare-180606065226-thumbnail.jpg?width=640&height=640&fit=bounds)
