More Related Content

PDF

PDF

PDF

PDF

PDF

PDF
![[DL輪読会]Depth Prediction Without the Sensors: Leveraging Structure for Unsuper...](https://cdn.slidesharecdn.com/ss_thumbnails/struct2depth0301-190304050917-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]Depth Prediction Without the Sensors: Leveraging Structure for Unsuper... 
PPT
What's hot

PPTX

PPTX

PDF
論文紹介 LexToMap: lexical-based topological mapping ![[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerfdlseminar1-200327021512-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis 
PDF
【DL輪読会】Perceiver io a general architecture for structured inputs & outputs 
PDF
論文紹介 Semantic Mapping for Mobile Robotics Tasks: A Survey 
PDF

PPTX
DLフレームワークChainerの紹介と分散深層強化学習によるロボット制御 
PDF
LSTM (Long short-term memory) 概要 
PPTX
MIRU2014 tutorial deeplearning 
PDF
Deep Learningによる画像認識革命 ー歴史・最新理論から実践応用までー ![[論文紹介] Convolutional Neural Network(CNN)による超解像](https://cdn.slidesharecdn.com/ss_thumbnails/cnn-presen-161218113749-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[論文紹介] Convolutional Neural Network(CNN)による超解像 
PDF

PDF

PDF
人間とのインタラクションにより言葉と行動を学習するロボット, 岩橋直人 
PDF

PDF

PPTX
Unsupervised Learning of Probably Symmetric Deformable 3D Objects from Images... 
PPTX

PDF
Similar to I

PDF
記号を用いたコミュニケーションを実現するために何が必要か?― 記号創発ロボティクスの 視点から ― 
PDF
第8回Language and Robotics研究会20221010_AkiraTaniguchi 
PDF

PPTX

PDF

PDF
子どもの言語獲得のモデル化とNN Language ModelsNN 
PPTX
東京大学2020年度深層学習(Deep learning基礎講座) 第9回「深層学習と自然言語処理」 
PDF

PDF
Grammatical inference メモ 1 
PDF
TensorFlow math ja 05 word2vec 
PDF

PPTX

PDF

PDF
ロボットによる言語獲得とインタラクション ~ロボットの”gaga to water”~(長井隆行) 
PDF
東京大学2020年度深層学習(Deep learning基礎講座) 第9回「深層学習と自然言語処理」(一部文字が欠けてます) 
PDF
CluBERT: A Cluster-Based Approach for Learning Sense Distributions in Multipl... 
PDF
transformer解説~Chat-GPTの源流~ 
PDF
文法誤り訂正モデルは訂正に必要な文法を学習しているか(NLP2021) 
PPTX
Deep Learning による視覚×言語融合の最前線 
PDF
東京大学2021年度深層学習(Deep learning基礎講座2021) 第8回「深層学習と自然言語処理」 I
- 1.
- 2.
1/22
1.1 研究の背景
サービスロボットへの期待が高まる
人間とのコミュニケーション(言語能力)が重要な要素
従来型ロボットの問題点(タスク依存)
プログラムされた状況しか対応できない
プログラムされていない言葉で話しかけられると・・・
プログラムされていない状況に対応するには?
知らない言葉でも、見たり、聞いたりして意味を獲得
できれば良い
オンラインで追加的に言語能力を獲得
できるロボットが求められている
- 3.
- 4.
3/22
1.3 既存研究
問題点 ・確率的な処理→大量の学習データが必要
・バッチ処理→オンライン・追加学習ができない
単語グラウンディング
Roy, Pentlandら(2002)
手法:音と映像のクロスモーダル情報を最大化
問題点:静止画像を利用(動的概念を獲得できない)
Yu, Ballardら(2004)
手法:マルチモーダル情報の確率的な対応付け
問題点:物体と単語が1対1に対応、追加学習に問題がある
文法の学習
岩橋ら(2003)
手法:HMMによる動的概念と語順の獲得
問題点:事前にデータを用意し、バッチ学習
- 5.
4/22
1.4 本研究の特徴
実環境で追加的・自律的に概念を獲得
言語の意味を発達的に学習
従来研究に対する優位性
事前知識なしで、概念を分類
1つのデータから学習できる
オンラインで文法(語順)を学習
柔軟な追加学習を実現
- 6.
5/22
1.5 研究に使用したロボット
ステレオカメラ
色、形、位置を取得
自由度:12
(首:2、片腕:5)
指定位置に手を移動
物体を握る・放す
- 7.
6/22
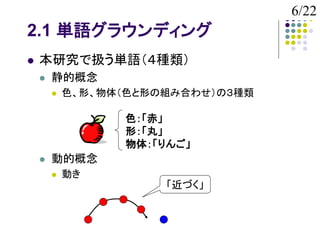
2.1 単語グラウンディング
本研究で扱う単語(4種類)
静的概念
色、形、物体(色と形の組み合わせ)の3種類
色:「赤」
形:「丸」
物体:「りんご」
動的概念
動き
「近づく」
- 8.
7/22
2.2 静的概念の獲得
概念とは
特徴ベクトルをクラスタリング
抽出されたクラスを概念とする
概念と音声ラベルの対応付け
音声の入力数を基に確率的に対応付け
→概念の分類が可能
例 色を表す言葉?
「赤」は 形を表す言葉?
物体を表す言葉?
- 9.
8/22
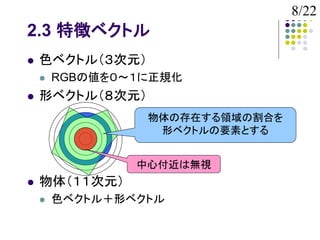
2.3 特徴ベクトル
色ベクトル(3次元)
RGBの値を0~1に正規化
形ベクトル(8次元)
物体の存在する領域の割合を
形ベクトルの要素とする
中心付近は無視
物体(11次元)
色ベクトル+形ベクトル
- 10.
- 11.
- 12.
11/22
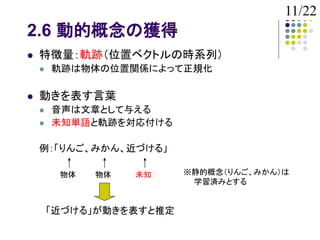
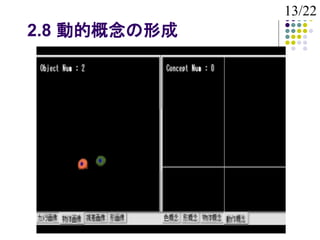
2.6 動的概念の獲得
特徴量:軌跡(位置ベクトルの時系列)
軌跡は物体の位置関係によって正規化
動きを表す言葉
音声は文章として与える
未知単語と軌跡を対応付ける
例:「りんご、みかん、近づける」
物体 物体 未知 ※静的概念(りんご、みかん)は
学習済みとする
「近づける」が動きを表すと推定
- 13.
12/22
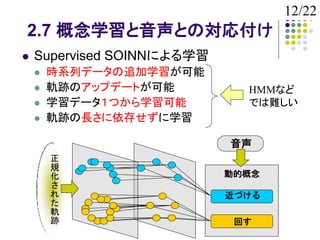
2.7 概念学習と音声との対応付け
Supervised SOINNによる学習
時系列データの追加学習が可能
軌跡のアップデートが可能 HMMなど
学習データ1つから学習可能 では難しい
軌跡の長さに依存せずに学習
音声
正
規
化 動的概念
さ
れ 近づける
た
軌
跡 回す
- 14.
- 15.
14/22
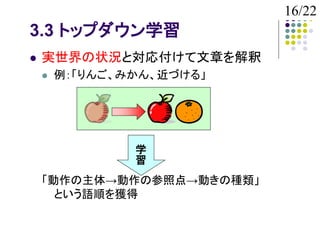
3.1 文法の学習
ボトムアップ学習とトップダウン学習の融合
少数の学習例から正しい文法を獲得
アップデート可能
ボトムアップ学習
単語クラスの遷移確率を学習
様々な長さの文章を生成できる
トップダウン学習
実世界の状況との対応付け
文法の解釈が一意に定まる
- 16.
- 17.
- 18.
17/22
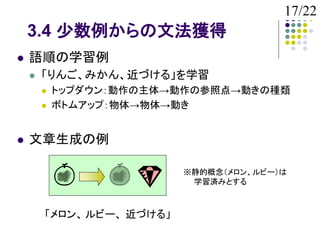
3.4 少数例からの文法獲得
語順の学習例
「りんご、みかん、近づける」を学習
トップダウン:動作の主体→動作の参照点→動きの種類
ボトムアップ:物体→物体→動き
文章生成の例
※静的概念(メロン、ルビー)は
学習済みとする
「メロン、 ルビー、 近づける」
- 19.
18/22
4.1 実験の概要
実験に使用した物体(9種類)
色(3種類):赤、黄色、緑
形(3種類):丸、三角、四角
提示した動き(6種類)
近づける、遠ざける、またぐ、回す、上げる、下げ
る
- 20.
- 21.
- 22.
- 23.
22/22
5 まとめと課題
実現されたシステム
事前知識のない状態から、発達的に言語能力を獲得
人間とコミュニケーションしながら、オンラインで学習
見たり、聞いたりすることで発達するロボットの
最初の一歩を実現
今後の課題
動作を増やす(現在は6種類)
概念を増やす(現在は、色、形など4種類)
複雑な文法に対応する(現在は「語順」のみ)