¤ “The imageof the world around us, which we carry in our head, is just a model.
Nobody in his head imagines all the world, government or country. He has only
selected concepts, and relationships between them, and uses those to represent the
real system. (Forrester, 1971)”
¤
¤ [Chang+ 17, Cell]
->
¤
¤ ! "# $ !’
¤ &("|!)
¤ MDP
Recap: the reinforcement learning objective
The Anatomy of a Reinforcement Learning Problem
Slide from Sergey Levine
Recap: the reinforcement learning objective
13.
¤
¤
¤
->
¤
¤
¤
¤
1.
2.
3.
4. 2
Model-based RLReview
improve the
policy
Correcting for model errors:
refitting model with new data, replanning with MPC, using local models
Model-based RL from raw observations:
learn latent space, typically with unsupervised learning, or
model &plan directly in observational space
e.g., backprop through model
supervised learning
Even simpler…
generic trajectory
optimization, solve
however you want
• How can we impose constraints on trajectory optimization?
14.
¤
¤
¤
¤
¤
¤ RBF DNN
¤
¤
¤
¤PILCO
¤ Guided policy search (trajectory optimization)
¤ CMA-ES
Policy Search Classification
Yet, it’s a grey zone…
Important Extensions:
• Contextual Policy Search [Kupscik, Deisenroth, Peters & Neumann, AAAI 2013], [Silva, Konidaris & Barto, ICML 2012], [Kober & Peters, IJCAI 2011], [Paresi &
Peters et al., IROS 2015]
• Hierarchical Policy Search [Daniel, Neumann & Peters., AISTATS 2012], [Wingate et al., IJCAI 2011], [Ghavamzadeh & Mahedevan, ICML 2003]
9
Direct Policy
Search
Value-Based
RL
Evolutionary
Strategies,
CMA-ES
Episodic
REPS
Policy
Gradients,
eNAC
Actor Critic,
Natural Actor Critic
Model-based REPS
PS by Trajectory
Optimization
Q-Learning,
Fitted Q
LSPIPILCO
Advantage
Weighted
Regression
Conservative
Policy Iteration
Model-Based Policy Search Methods
85
Learn dynamics model from data-set
+ More data efficient than model-free methods
+ More complex policies can be optimized
• RBF networks [Deisenroth & Rasmussen, 2011]
• Time-dependent feedback controllers [Levine & Koltun, 2014]
• Gaussian Processes [Von Hoof, Peters & Nemann, 2015]
• Deep neural nets [Levine & Koltun, 2014][Levine & Abbeel, 2014]
Limitations:
- Learning good models is often very hard
- Small model errors can have drastic damage
on the resulting policy (due to optimization)
- Some models are hard to scale
- Computational Complexity
15.
PILCO
¤ PILCO (probabilisticinference for learning control) [Deisenroth+ 11]
¤
¤
¤ RBF
¤
1.
2.
¤
¤
3.
Greedy Policy Updates: PILCO [Deisenroth & Rasmussen 2011]
Model Learning:
• Use Bayesian models which integrate out model
uncertainty Gaussian Processes
• Reward predictions are not specialized to a single model
Internal Stimulation:
• Iteratively compute
• Moment matching: deterministic approximate inference
Policy Update:
• Analytically compute expected return and its gradient
• Greedily Optimize with BFGS
88
Greedy Policy Updates: PILCO [Deisenroth & Rasmussen 2011]
Model Learning:
• Use Bayesian models which integrate out model
uncertainty Gaussian Processes
• Reward predictions are not specialized to a single model
Internal Stimulation:
• Iteratively compute
• Moment matching: deterministic approximate inference
Policy Update:
• Analytically compute expected return and its gradient
• Greedily Optimize with BFGS
88
Greedy Policy Updates: PILCO [Deisenroth & Rasmussen 2011]
Model Learning:
• Use Bayesian models which integrate out model
uncertainty Gaussian Processes
• Reward predictions are not specialized to a single model
Internal Stimulation:
• Iteratively compute
• Moment matching: deterministic approximate inference
Policy Update:
• Analytically compute expected return and its gradient
• Greedily Optimize with BFGS
88
Greedy Policy Updates: PILCO [Deisenroth & Rasmussen 2011]
Model Learning:
• Use Bayesian models which integrate out model
uncertainty Gaussian Processes
• Reward predictions are not specialized to a single model
Internal Stimulation:
• Iteratively compute
• Moment matching: deterministic approximate inference
Policy Update:
• Analytically compute expected return and its gradient
• Greedily Optimize with BFGS
88
Greedy Policy Updates: PILCO [Deisenroth & Rasmussen 2011]
Model Learning:
• Use Bayesian models which integrate out model
uncertainty Gaussian Processes
• Reward predictions are not specialized to a single model
Internal Stimulation:
• Iteratively compute
• Moment matching: deterministic approximate inference
Policy Update:
• Analytically compute expected return and its gradient
• Greedily Optimize with BFGS
88
What’s the problem?
backprop backprop
backprop
• Similar parameter sensitivity problems as shooting methods
• But no longer have convenient second order LQR-like method, because policy
parameters couple all the time steps, so no dynamic programming
• Similar problems to training long RNNs with BPTT
• Vanishing and exploding gradients
• Unlike LSTM, we can’t just “choose” a simple dynamics, dynamics are chosen by
nature
¤
¤ Learning deepdynamical models from image pixels [Wahlström+ 14] From Pixels to
Torques: Policy Learning with Deep Dynamical Models [Wahlstrom+ 15]
¤ deep dynamical model DDM
¤
VAE
¤ ! "~$" !
¤
¤ !
(a) Learned Frey Face manifold (b) Learned MNIST manifold
Figure 4: Visualisations of learned data manifold for generative models with two-dimensional latent
space, learned with AEVB. Since the prior of the latent space is Gaussian, linearly spaced coor-
dinates on the unit square were transformed through the inverse CDF of the Gaussian to produce
values of the latent variables z. For each of these values z, we plotted the corresponding generative
p✓(x|z) with the learned parameters ✓.
[Kingma+ 13]
¤
¤ MDN-RNN VAE
¤VAE
¤
¤
¤ Friston
¤ Wahlström M V
¤ VRNN[Chung+ 15]
47
48.
Friston
¤
¤ !"($)
¤
¤
¤
https://en.wikipedia.org/wiki/Free_energy_principle
164 第9 章 考察
ると,内部モデルは生成モデルによって実現される.
内部モデルを機械学習における生成モデルと捉え,行動と結びつけた枠組で有名なのが
Friston による自由エネルギー原理(free-energy principle) [Friston 10] である.自由エネル
ギー原理では,生物学的なシステムが内部状態の自由エネルギーを最小化することによって秩
序を維持していると考えている.
状態 x*8
と潜在変数 z を持つ生成モデル pθ(x, z) を考えて,近似分布を qφ(z) とする.
また,負の周辺尤度の上界である変分自由エネルギー(負の変分下界)を F(x; φ, θ) =
−Eqφ(z)[log p(x, z)] + H[qφ(z)] とする.自由エネルギー原理では,内部パラメータ φ と行動
a は,(変分)自由エネルギーを最小化するように更新すると考える.
ˆφ = arg min
φ
F(x; φ, θ),
ˆa = arg min
a
F(x; φ, θ).
なお,ここでの arg mina は,自由エネルギーが最小になるような x を選ぶ行動 a を取るとい
うことである.また,生成モデルのパラメータ θ については,上記の更新を一定数繰り返した
後に更新する.
自由エネルギー原理では,入力は単純に状態 x として考えられている.ある状態 x を受け
取ったときに内部状態が更新され,その後生成モデルを元に,自由エネルギーが最小になる
ような状態 x を選ぶ行動 a が取られる.しかし実際には,外界からの刺激は五感を通じてマ
ルチモーダル情報として得られるため,自由エネルギーは複数のモダリティ x や w を含んだ
164
ると,内部モデルは生成モデルによって実現される.
内部モデルを機械学習における生成モデルと捉え,行動と結びつけ
Friston による自由エネルギー原理(free-energy principle) [Friston 10
ギー原理では,生物学的なシステムが内部状態の自由エネルギーを最小化
序を維持していると考えている.
状態 x*8
と潜在変数 z を持つ生成モデル pθ(x, z) を考えて,近似分
また,負の周辺尤度の上界である変分自由エネルギー(負の変分下
−Eqφ(z)[log p(x, z)] + H[qφ(z)] とする.自由エネルギー原理では,内部
a は,(変分)自由エネルギーを最小化するように更新すると考える.
ˆφ = arg min
φ
F(x; φ, θ),
ˆa = arg min
a
F(x; φ, θ).
なお,ここでの arg mina は,自由エネルギーが最小になるような x を選
うことである.また,生成モデルのパラメータ θ については,上記の更新
後に更新する.
自由エネルギー原理では,入力は単純に状態 x として考えられている
取ったときに内部状態が更新され,その後生成モデルを元に,自由エネ
ような状態 x を選ぶ行動 a が取られる.しかし実際には,外界からの刺
第 9 章 考察
デルは生成モデルによって実現される.
を機械学習における生成モデルと捉え,行動と結びつけた枠組で有名なのが
自由エネルギー原理(free-energy principle) [Friston 10] である.自由エネル
,生物学的なシステムが内部状態の自由エネルギーを最小化することによって秩
いると考えている.
潜在変数 z を持つ生成モデル pθ(x, z) を考えて,近似分布を qφ(z) とする.
辺尤度の上界である変分自由エネルギー(負の変分下界)を F(x; φ, θ) =
x, z)] + H[qφ(z)] とする.自由エネルギー原理では,内部パラメータ φ と行動
自由エネルギーを最小化するように更新すると考える.
ˆφ = arg min
φ
F(x; φ, θ),
ˆa = arg min
a
F(x; φ, θ).
の arg mina は,自由エネルギーが最小になるような x を選ぶ行動 a を取るとい
.また,生成モデルのパラメータ θ については,上記の更新を一定数繰り返した
.
ギー原理では,入力は単純に状態 x として考えられている.ある状態 x を受け
内部状態が更新され,その後生成モデルを元に,自由エネルギーが最小になる
164 第 9 章 考察
ると,内部モデルは生成モデルによって実現される.
内部モデルを機械学習における生成モデルと捉え,行動と結びつけた枠組で有名なのが
Friston による自由エネルギー原理(free-energy principle) [Friston 10] である.自由エネル
ギー原理では,生物学的なシステムが内部状態の自由エネルギーを最小化することによって秩
序を維持していると考えている.
状態 x*8
と潜在変数 z を持つ生成モデル pθ(x, z) を考えて,近似分布を qφ(z) とする.
また,負の周辺尤度の上界である変分自由エネルギー(負の変分下界)を F(x; φ, θ) =
−Eqφ(z)[log p(x, z)] + H[qφ(z)] とする.自由エネルギー原理では,内部パラメータ φ と行動
a は,(変分)自由エネルギーを最小化するように更新すると考える.
ˆφ = arg min
φ
F(x; φ, θ),
ˆa = arg min
a
F(x; φ, θ).
なお,ここでの arg mina は,自由エネルギーが最小になるような x を選ぶ行動 a を取るとい
うことである.また,生成モデルのパラメータ θ については,上記の更新を一定数繰り返した
後に更新する.
自由エネルギー原理では,入力は単純に状態 x として考えられている.ある状態 x を受け
取ったときに内部状態が更新され,その後生成モデルを元に,自由エネルギーが最小になる
ような状態 x を選ぶ行動 a が取られる.しかし実際には,外界からの刺激は五感を通じてマ
ルチモーダル情報として得られるため,自由エネルギーは複数のモダリティ x や w を含んだ
49.
LeCun
Y LeCun
How MuchInformation Does the Machine Need to Predict?
“Pure” Reinforcement Learning (cherry)
The machine predicts a scalar
reward given once in a while.
A few bits for some samples
Supervised Learning (icing)
The machine predicts a category
or a few numbers for each input
Predicting human-supplied data
10 10,000 bits per sample→
Unsupervised/Predictive Learning (cake)
The machine predicts any part of
its input for any observed part.
Predicts future frames in videos
Millions of bits per sample
(Yes, I know, this picture is slightly offensive to RL folks. But I’ll make it up)





![¤ “The image of the world around us, which we carry in our head, is just a model.
Nobody in his head imagines all the world, government or country. He has only
selected concepts, and relationships between them, and uses those to represent the
real system. (Forrester, 1971)”
¤
¤ [Chang+ 17, Cell]
->](https://image.slidesharecdn.com/20180515-180521094123/85/slide-7-320.jpg)

![¤
¤
¤
¤
¤
¤
¤ PredNet [Watanabe+ 18]
http://www.psy.ritsumei.ac.jp/~akitaoka/rotsnakes.html](https://image.slidesharecdn.com/20180515-180521094123/85/slide-9-320.jpg)



![¤
¤
¤
¤
¤
¤ RBF DNN
¤
¤
¤
¤ PILCO
¤ Guided policy search (trajectory optimization)
¤ CMA-ES
Policy Search Classification
Yet, it’s a grey zone…
Important Extensions:
• Contextual Policy Search [Kupscik, Deisenroth, Peters & Neumann, AAAI 2013], [Silva, Konidaris & Barto, ICML 2012], [Kober & Peters, IJCAI 2011], [Paresi &
Peters et al., IROS 2015]
• Hierarchical Policy Search [Daniel, Neumann & Peters., AISTATS 2012], [Wingate et al., IJCAI 2011], [Ghavamzadeh & Mahedevan, ICML 2003]
9
Direct Policy
Search
Value-Based
RL
Evolutionary
Strategies,
CMA-ES
Episodic
REPS
Policy
Gradients,
eNAC
Actor Critic,
Natural Actor Critic
Model-based REPS
PS by Trajectory
Optimization
Q-Learning,
Fitted Q
LSPIPILCO
Advantage
Weighted
Regression
Conservative
Policy Iteration
Model-Based Policy Search Methods
85
Learn dynamics model from data-set
+ More data efficient than model-free methods
+ More complex policies can be optimized
• RBF networks [Deisenroth & Rasmussen, 2011]
• Time-dependent feedback controllers [Levine & Koltun, 2014]
• Gaussian Processes [Von Hoof, Peters & Nemann, 2015]
• Deep neural nets [Levine & Koltun, 2014][Levine & Abbeel, 2014]
Limitations:
- Learning good models is often very hard
- Small model errors can have drastic damage
on the resulting policy (due to optimization)
- Some models are hard to scale
- Computational Complexity](https://image.slidesharecdn.com/20180515-180521094123/85/slide-14-320.jpg)
![PILCO
¤ PILCO (probabilistic inference for learning control) [Deisenroth+ 11]
¤
¤
¤ RBF
¤
1.
2.
¤
¤
3.
Greedy Policy Updates: PILCO [Deisenroth & Rasmussen 2011]
Model Learning:
• Use Bayesian models which integrate out model
uncertainty Gaussian Processes
• Reward predictions are not specialized to a single model
Internal Stimulation:
• Iteratively compute
• Moment matching: deterministic approximate inference
Policy Update:
• Analytically compute expected return and its gradient
• Greedily Optimize with BFGS
88
Greedy Policy Updates: PILCO [Deisenroth & Rasmussen 2011]
Model Learning:
• Use Bayesian models which integrate out model
uncertainty Gaussian Processes
• Reward predictions are not specialized to a single model
Internal Stimulation:
• Iteratively compute
• Moment matching: deterministic approximate inference
Policy Update:
• Analytically compute expected return and its gradient
• Greedily Optimize with BFGS
88
Greedy Policy Updates: PILCO [Deisenroth & Rasmussen 2011]
Model Learning:
• Use Bayesian models which integrate out model
uncertainty Gaussian Processes
• Reward predictions are not specialized to a single model
Internal Stimulation:
• Iteratively compute
• Moment matching: deterministic approximate inference
Policy Update:
• Analytically compute expected return and its gradient
• Greedily Optimize with BFGS
88
Greedy Policy Updates: PILCO [Deisenroth & Rasmussen 2011]
Model Learning:
• Use Bayesian models which integrate out model
uncertainty Gaussian Processes
• Reward predictions are not specialized to a single model
Internal Stimulation:
• Iteratively compute
• Moment matching: deterministic approximate inference
Policy Update:
• Analytically compute expected return and its gradient
• Greedily Optimize with BFGS
88
Greedy Policy Updates: PILCO [Deisenroth & Rasmussen 2011]
Model Learning:
• Use Bayesian models which integrate out model
uncertainty Gaussian Processes
• Reward predictions are not specialized to a single model
Internal Stimulation:
• Iteratively compute
• Moment matching: deterministic approximate inference
Policy Update:
• Analytically compute expected return and its gradient
• Greedily Optimize with BFGS
88
What’s the problem?
backprop backprop
backprop
• Similar parameter sensitivity problems as shooting methods
• But no longer have convenient second order LQR-like method, because policy
parameters couple all the time steps, so no dynamic programming
• Similar problems to training long RNNs with BPTT
• Vanishing and exploding gradients
• Unlike LSTM, we can’t just “choose” a simple dynamics, dynamics are chosen by
nature](https://image.slidesharecdn.com/20180515-180521094123/85/slide-15-320.jpg)
![Guided Policy Search via trajectory optimization
¤
¤
¤ trajectory optimization
¤ DNN trajectory optimization+
guided policy search
[Levine+ 14]](https://image.slidesharecdn.com/20180515-180521094123/85/slide-16-320.jpg)

![¤
¤ [Gu+ 16]
¤ etc.
¤
¤
¤](https://image.slidesharecdn.com/20180515-180521094123/85/slide-18-320.jpg)
![¤
¤ 1980 Feed-forward neural networks FNN
¤ 1990 RNN
->
¤ RNN
¤ “Making the World Differentiable” [Schmidhuber, 1990]
¤ RNN
RNN](https://image.slidesharecdn.com/20180515-180521094123/85/slide-19-320.jpg)
![¤
¤ Learning deep dynamical models from image pixels [Wahlström+ 14] From Pixels to
Torques: Policy Learning with Deep Dynamical Models [Wahlstrom+ 15]
¤ deep dynamical model DDM
¤](https://image.slidesharecdn.com/20180515-180521094123/85/slide-20-320.jpg)
![VAE
¤ ! "; $
¤
¤ "
¤
¤ Variational autoencoder VAE [Kingma+ 13] [Rezende+ 14]
¤
"
%
&'(%|")
" ~ !,("|%)
% ~ !(%)
&' % " = .(%|/ " , 12
(")) !, " % = ℬ("|/ " )](https://image.slidesharecdn.com/20180515-180521094123/85/slide-21-320.jpg)
![VAE
¤ ! "~$ " !
¤
¤ !
(a) Learned Frey Face manifold (b) Learned MNIST manifold
Figure 4: Visualisations of learned data manifold for generative models with two-dimensional latent
space, learned with AEVB. Since the prior of the latent space is Gaussian, linearly spaced coor-
dinates on the unit square were transformed through the inverse CDF of the Gaussian to produce
values of the latent variables z. For each of these values z, we plotted the corresponding generative
p✓(x|z) with the learned parameters ✓.
[Kingma+ 13]](https://image.slidesharecdn.com/20180515-180521094123/85/slide-22-320.jpg)
![VAE
¤ VAE
¤
¤ GAN
¤ disentangle
¤
¤
¤ β-VAE[Higgins+ 17]
¤
¤ [Burgess+ 18]](https://image.slidesharecdn.com/20180515-180521094123/85/slide-23-320.jpg)




![MDN-RNN M
¤ M !" !"#$
¤ %(!"#$|(", !", ℎ")
¤ ( ℎ RNN
¤ !"#$
¤ M MDN-RNN[Graves + 13, Ha+ 17]
¤ RNN
¤
¤ Ha
28](https://image.slidesharecdn.com/20180515-180521094123/85/slide-28-320.jpg)
![¤ [Bishop+ 94]
¤
¤
¤ ! "
¤
29](https://image.slidesharecdn.com/20180515-180521094123/85/slide-29-320.jpg)
![MDN-RNN
¤ SketchRNN[Ha+ 17]
¤ MDN-RNN
30](https://image.slidesharecdn.com/20180515-180521094123/85/slide-30-320.jpg)













![¤
¤
¤
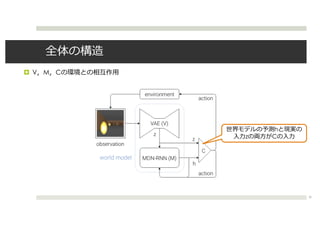
¤ Learning To Think[Schmidhuber+ 15]
1. M C
2.
3. M M C
4. 2
¤ 1
¤ 2
¤ curiosity
¤
45](https://image.slidesharecdn.com/20180515-180521094123/85/slide-45-320.jpg)
![¤
¤ MDN-RNN VAE
¤ VAE
¤
¤
¤ Friston
¤ Wahlström M V
¤ VRNN[Chung+ 15]
47](https://image.slidesharecdn.com/20180515-180521094123/85/slide-47-320.jpg)
![Friston
¤
¤ !"($)
¤
¤
¤
https://en.wikipedia.org/wiki/Free_energy_principle
164 第 9 章 考察
ると,内部モデルは生成モデルによって実現される.
内部モデルを機械学習における生成モデルと捉え,行動と結びつけた枠組で有名なのが
Friston による自由エネルギー原理(free-energy principle) [Friston 10] である.自由エネル
ギー原理では,生物学的なシステムが内部状態の自由エネルギーを最小化することによって秩
序を維持していると考えている.
状態 x*8
と潜在変数 z を持つ生成モデル pθ(x, z) を考えて,近似分布を qφ(z) とする.
また,負の周辺尤度の上界である変分自由エネルギー(負の変分下界)を F(x; φ, θ) =
−Eqφ(z)[log p(x, z)] + H[qφ(z)] とする.自由エネルギー原理では,内部パラメータ φ と行動
a は,(変分)自由エネルギーを最小化するように更新すると考える.
ˆφ = arg min
φ
F(x; φ, θ),
ˆa = arg min
a
F(x; φ, θ).
なお,ここでの arg mina は,自由エネルギーが最小になるような x を選ぶ行動 a を取るとい
うことである.また,生成モデルのパラメータ θ については,上記の更新を一定数繰り返した
後に更新する.
自由エネルギー原理では,入力は単純に状態 x として考えられている.ある状態 x を受け
取ったときに内部状態が更新され,その後生成モデルを元に,自由エネルギーが最小になる
ような状態 x を選ぶ行動 a が取られる.しかし実際には,外界からの刺激は五感を通じてマ
ルチモーダル情報として得られるため,自由エネルギーは複数のモダリティ x や w を含んだ
164
ると,内部モデルは生成モデルによって実現される.
内部モデルを機械学習における生成モデルと捉え,行動と結びつけ
Friston による自由エネルギー原理(free-energy principle) [Friston 10
ギー原理では,生物学的なシステムが内部状態の自由エネルギーを最小化
序を維持していると考えている.
状態 x*8
と潜在変数 z を持つ生成モデル pθ(x, z) を考えて,近似分
また,負の周辺尤度の上界である変分自由エネルギー(負の変分下
−Eqφ(z)[log p(x, z)] + H[qφ(z)] とする.自由エネルギー原理では,内部
a は,(変分)自由エネルギーを最小化するように更新すると考える.
ˆφ = arg min
φ
F(x; φ, θ),
ˆa = arg min
a
F(x; φ, θ).
なお,ここでの arg mina は,自由エネルギーが最小になるような x を選
うことである.また,生成モデルのパラメータ θ については,上記の更新
後に更新する.
自由エネルギー原理では,入力は単純に状態 x として考えられている
取ったときに内部状態が更新され,その後生成モデルを元に,自由エネ
ような状態 x を選ぶ行動 a が取られる.しかし実際には,外界からの刺
第 9 章 考察
デルは生成モデルによって実現される.
を機械学習における生成モデルと捉え,行動と結びつけた枠組で有名なのが
自由エネルギー原理(free-energy principle) [Friston 10] である.自由エネル
,生物学的なシステムが内部状態の自由エネルギーを最小化することによって秩
いると考えている.
潜在変数 z を持つ生成モデル pθ(x, z) を考えて,近似分布を qφ(z) とする.
辺尤度の上界である変分自由エネルギー(負の変分下界)を F(x; φ, θ) =
x, z)] + H[qφ(z)] とする.自由エネルギー原理では,内部パラメータ φ と行動
自由エネルギーを最小化するように更新すると考える.
ˆφ = arg min
φ
F(x; φ, θ),
ˆa = arg min
a
F(x; φ, θ).
の arg mina は,自由エネルギーが最小になるような x を選ぶ行動 a を取るとい
.また,生成モデルのパラメータ θ については,上記の更新を一定数繰り返した
.
ギー原理では,入力は単純に状態 x として考えられている.ある状態 x を受け
内部状態が更新され,その後生成モデルを元に,自由エネルギーが最小になる
164 第 9 章 考察
ると,内部モデルは生成モデルによって実現される.
内部モデルを機械学習における生成モデルと捉え,行動と結びつけた枠組で有名なのが
Friston による自由エネルギー原理(free-energy principle) [Friston 10] である.自由エネル
ギー原理では,生物学的なシステムが内部状態の自由エネルギーを最小化することによって秩
序を維持していると考えている.
状態 x*8
と潜在変数 z を持つ生成モデル pθ(x, z) を考えて,近似分布を qφ(z) とする.
また,負の周辺尤度の上界である変分自由エネルギー(負の変分下界)を F(x; φ, θ) =
−Eqφ(z)[log p(x, z)] + H[qφ(z)] とする.自由エネルギー原理では,内部パラメータ φ と行動
a は,(変分)自由エネルギーを最小化するように更新すると考える.
ˆφ = arg min
φ
F(x; φ, θ),
ˆa = arg min
a
F(x; φ, θ).
なお,ここでの arg mina は,自由エネルギーが最小になるような x を選ぶ行動 a を取るとい
うことである.また,生成モデルのパラメータ θ については,上記の更新を一定数繰り返した
後に更新する.
自由エネルギー原理では,入力は単純に状態 x として考えられている.ある状態 x を受け
取ったときに内部状態が更新され,その後生成モデルを元に,自由エネルギーが最小になる
ような状態 x を選ぶ行動 a が取られる.しかし実際には,外界からの刺激は五感を通じてマ
ルチモーダル情報として得られるため,自由エネルギーは複数のモダリティ x や w を含んだ](https://image.slidesharecdn.com/20180515-180521094123/85/slide-48-320.jpg)

![¤
¤ C
¤
¤ PredNet [Lotter+ 16]
¤](https://image.slidesharecdn.com/20180515-180521094123/85/slide-50-320.jpg)



![[DL輪読会]Dream to Control: Learning Behaviors by Latent Imagination](https://cdn.slidesharecdn.com/ss_thumbnails/20200313furutav2-200313025657-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...](https://cdn.slidesharecdn.com/ss_thumbnails/20190426akuzawa-190426020057-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Learning Latent Dynamics for Planning from Pixels](https://cdn.slidesharecdn.com/ss_thumbnails/taniguchi20181221-190104064850-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Control as Inferenceと発展](https://cdn.slidesharecdn.com/ss_thumbnails/20191004-191204055019-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]World Models](https://cdn.slidesharecdn.com/ss_thumbnails/20180427-180427003856-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Deep Learning 第15章 表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning15-180601023904-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DL輪読会]Weight Agnostic Neural Networks](https://cdn.slidesharecdn.com/ss_thumbnails/dl0906-190906002243-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会] Learning Finite State Representations of Recurrent Policy Networks (I...](https://cdn.slidesharecdn.com/ss_thumbnails/20190830kaitosuzuki-190902060756-thumbnail.jpg?width=640&height=640&fit=bounds)
































