1
DEEP LEARNING JP
[DLPapers]
http://deeplearning.jp/
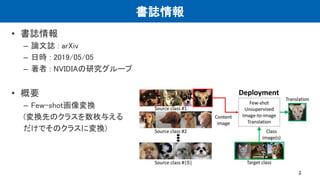
Few-Shot Unsupervised Image-to-ImageTranslation
Kento Doi, Iwasaki lab (the Department of Aeronautics and
Astronautics)
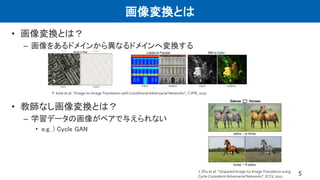
画像変換とは
• 画像変換とは?
– 画像をあるドメインから異なるドメインへ変換する
•教師なし画像変換とは?
– 学習データの画像がペアで与えられない
• e.g. ) Cycle GAN
5
P. Isola et al. “Image-to-ImageTranslation with ConditionalAdversarial Networks”,CVPR, 2017.
J. Zhu et al. “Unpaired Image-to-ImageTranslation using
Cycle-Consistent Adversarial Networks”, ICCV, 2017.
6.
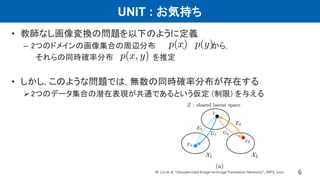
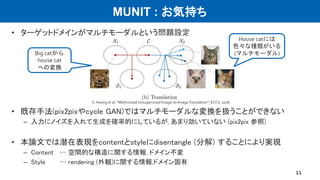
UNIT : お気持ち
•教師なし画像変換の問題を以下のように定義
– 2つのドメインの画像集合の周辺分布 , から,
それらの同時確率分布 を推定
• しかし, このような問題では, 無数の同時確率分布が存在する
2つのデータ集合の潜在表現が共通であるという仮定 (制限) を与える
6M. Liu et al. “Unsupervised Image-to-ImageTranslation Networks”, NIPS, 2017.
7.
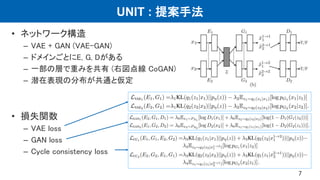
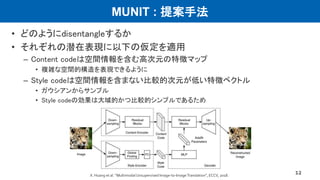
UNIT : 提案手法
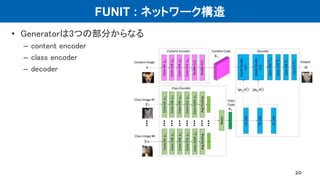
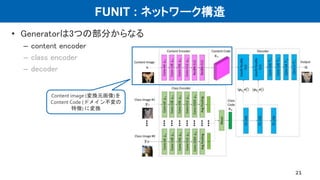
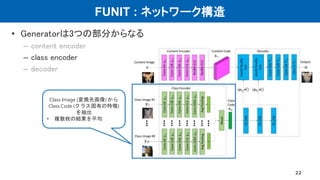
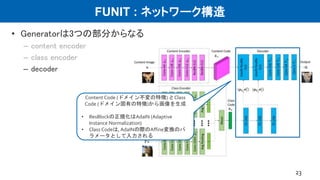
•ネットワーク構造
– VAE + GAN (VAE-GAN)
– ドメインごとにE, G, Dがある
– 一部の層で重みを共有 (右図点線 CoGAN)
– 潜在表現の分布が共通と仮定
• 損失関数
– VAE loss
– GAN loss
– Cycle consistency loss
7
8.
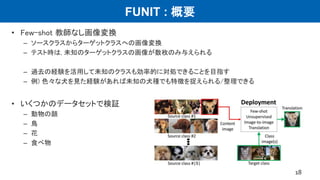
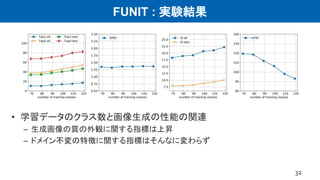
UNIT : 実験(画像変換)
8M. Liu et al. “Unsupervised Image-to-ImageTranslation Networks”, NIPS, 2017.
9.
UNIT : 実験(ドメイン適応)
• 以下のマルチタスク学習
1. ソースドメインとターゲットドメインで画像変換
2. ソースドメインの画像をdiscriminatorから得た特徴で分類
3. 変換前後の画像でdiscriminatorの出力が近くなるように
9
M. Liu et al. “Unsupervised Image-to-ImageTranslation Networks”, NIPS, 2017.
参考文献
1. M. Liuet al. “Few-Shot Unsupervised Image-to-Image Translation”, arXiv, 2019.
2. M. Liu et al. “Unsupervised Image-to-Image Translation Networks”, NIPS, 2017.
3. X. Huang et al. “Multimodal Unsupervised Image-to-Image Translation”, ECCV, 2018.
4. P. Isola et al. “Image-to-Image Translation with Conditional Adversarial Networks”, CVPR, 2017.
5. J. Zhu et al. “Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks”,
ICCV, 2017.
6. A. B. L. Larsen, S. K. Sønderby, H. Larochelle, and O. Winther. “Autoencoding beyond pixels using a
learned similarity metric”, International Conference on Machine Learning, 2016.
7. M.-Y. Liu and O. Tuzel. “Coupled generative adversarial networks”, Advances in Neural Information
Processing Systems, 2016.
8. X. Huang and S. Belongie. Arbitrary style transfer in realtime with adaptive instance normalization. In
IEEE International Conference on Computer Vision (ICCV), 2017.
9. T. Miyato and M. Koyama. “cGANs with projection discriminator”, ICLR, 2018.
10. T. Park et al. “Semantic Image Synthesis with Spatially-Adaptive Normalization”, arXiv, 2019.
11. A. Noguchi et al. “Image Generation from Small Datasets via Batch Statistics Adaptation”, arXiv, 2019.
39
40.
12. Y. Choiet al. “StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image
Translation”, CVPR, 2018.
40
![1
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
Few-Shot Unsupervised Image-to-ImageTranslation
Kento Doi, Iwasaki lab (the Department of Aeronautics and
Astronautics)](https://image.slidesharecdn.com/dlseminarfunit-190517005148/85/DL-Few-Shot-Unsupervised-Image-to-Image-Translation-1-320.jpg)
![1
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
Few-Shot Unsupervised Image-to-ImageTranslation
Kento Doi, Iwasaki lab (the Department of Aeronautics and
Astronautics)](https://image.slidesharecdn.com/dlseminarfunit-190517005148/75/DL-Few-Shot-Unsupervised-Image-to-Image-Translation-1-2048.jpg)




























![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)











![[DL輪読会]StarGAN: Unified Generative Adversarial Networks for Multi-Domain Ima...](https://cdn.slidesharecdn.com/ss_thumbnails/171222stargan-171225064145-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)

![[第2回3D勉強会 研究紹介] Neural 3D Mesh Renderer (CVPR 2018)](https://cdn.slidesharecdn.com/ss_thumbnails/201807263dv-180728060959-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]MetaFormer is Actually What You Need for Vision](https://cdn.slidesharecdn.com/ss_thumbnails/20220121metaformer-220121085750-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Life-Long Disentangled Representation Learning with Cross-Domain Laten...](https://cdn.slidesharecdn.com/ss_thumbnails/20180914iwasawa-180919025635-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]近年のエネルギーベースモデルの進展](https://cdn.slidesharecdn.com/ss_thumbnails/energybasedmodel-200124020855-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing](https://cdn.slidesharecdn.com/ss_thumbnails/glide2-220107030326-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Unsupervised Cross-Domain Image Generation](https://cdn.slidesharecdn.com/ss_thumbnails/readingpaper20170310-170310051823-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]High-Fidelity Image Generation with Fewer Labels](https://cdn.slidesharecdn.com/ss_thumbnails/190315dlseminargan-190315004124-thumbnail.jpg?width=640&height=640&fit=bounds)





























