[DL輪読会] Towards an Automatic Turing Test: Learning to Evaluate Dialogue Responses
1.
DEEP LEARNING JP
[DLPapers]
“Towards an AutomaticTuringTest:
Learning to Evaluate Dialog Response (ACL2017)”
Hiromi Nakagawa, Matsuo Lab
http://deeplearning.jp/
2.
1. Paper Information
2.Introduction
3. Related Works
4. Proposed Model
5. Experiments
6. Results
7. Discussion
2
Agenda
3.
1. Paper Information
2.Introduction
3. Related Works
4. Proposed Model
5. Experiments
6. Results
7. Discussion
3
Agenda
4.
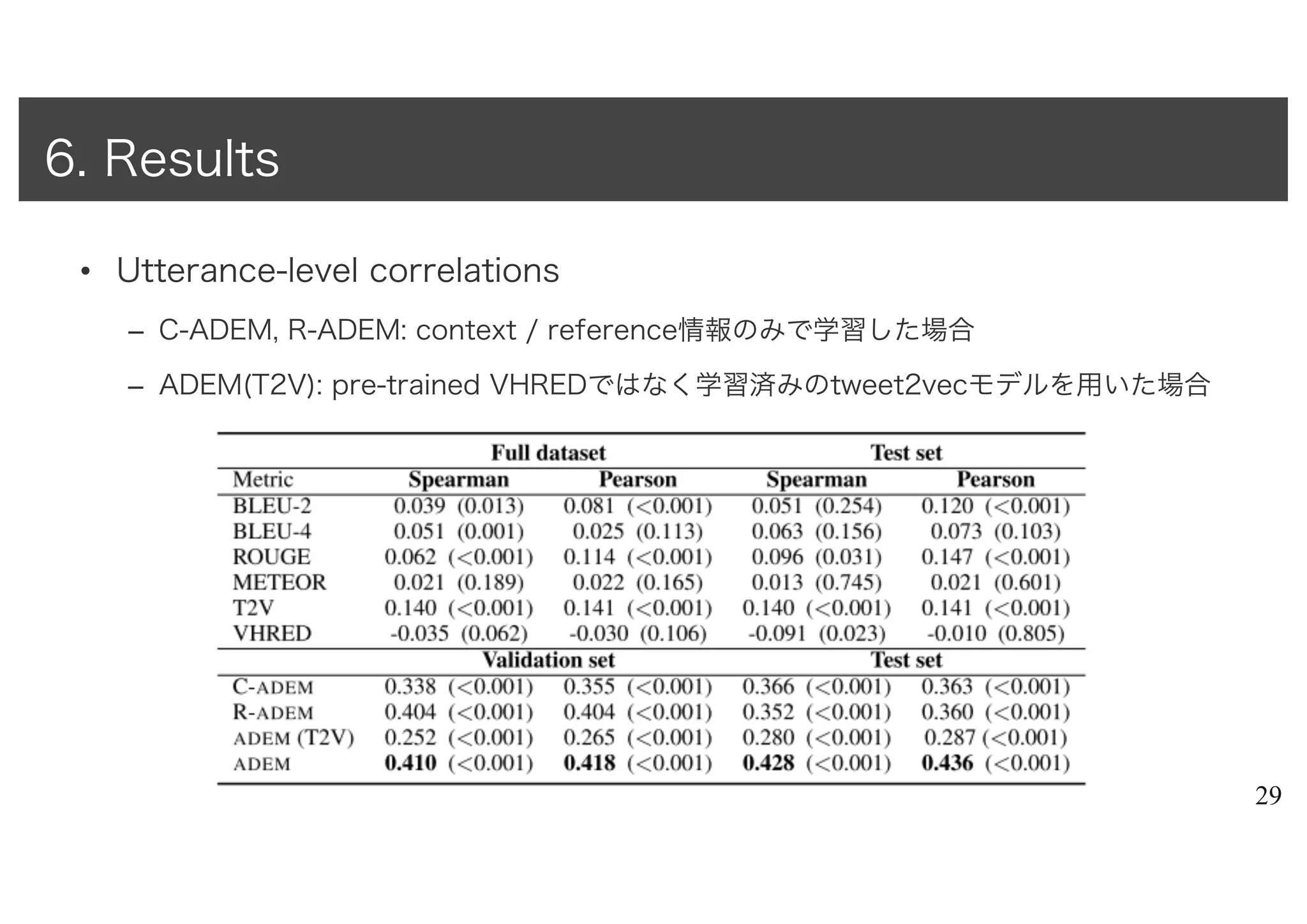
• Author
– RyanLowe1, Michael Noseworthy1, Iulian V.Serban1, Nicolas A.-Gontier1,
– Yoshua Bengio2,3, Joelle Pineau1,3
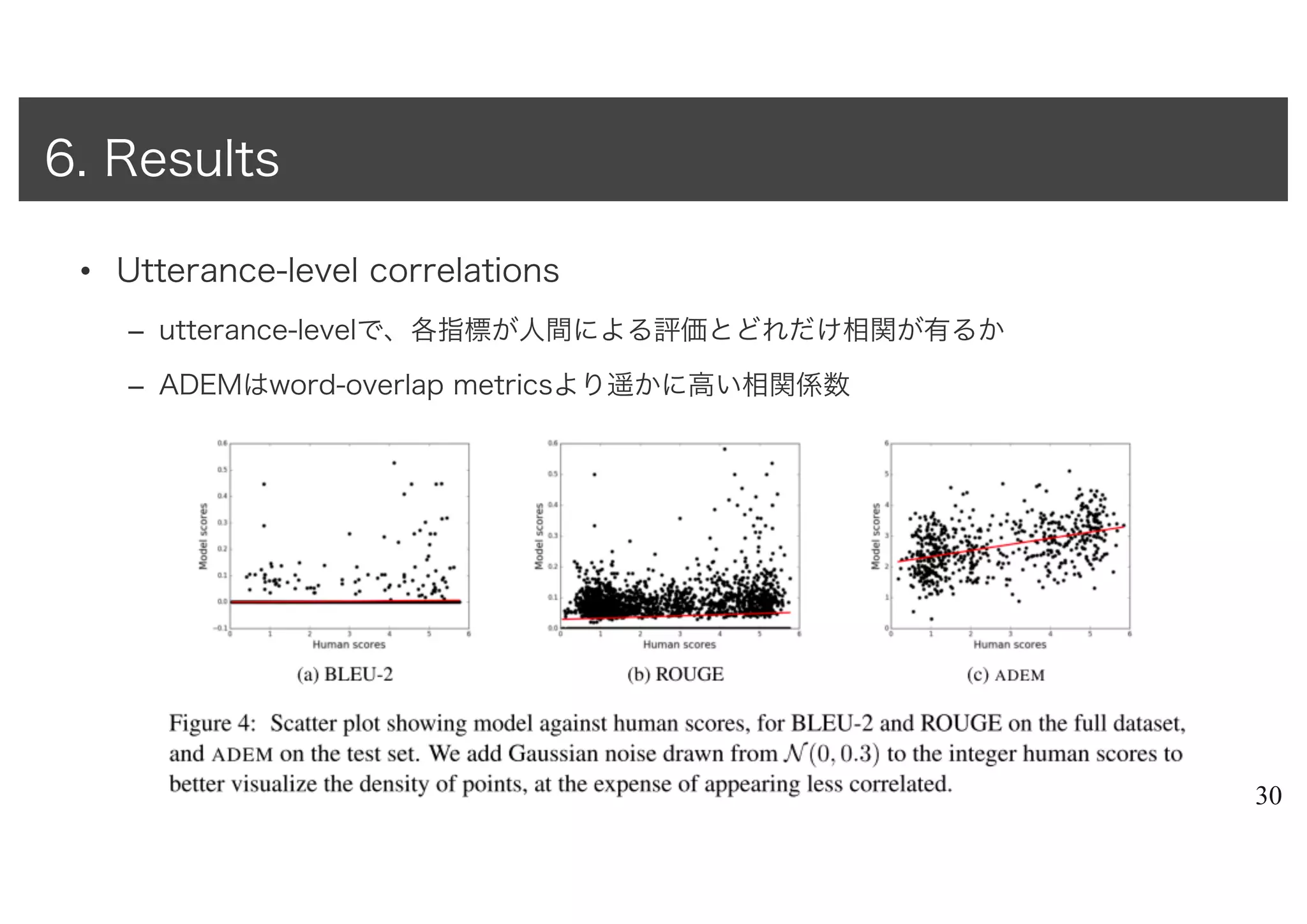
1. Reasoning and Learning Lab, School of Computer Science, McGill University
2. Montreal Institute for Learning Algorithms, Universite de Monreal
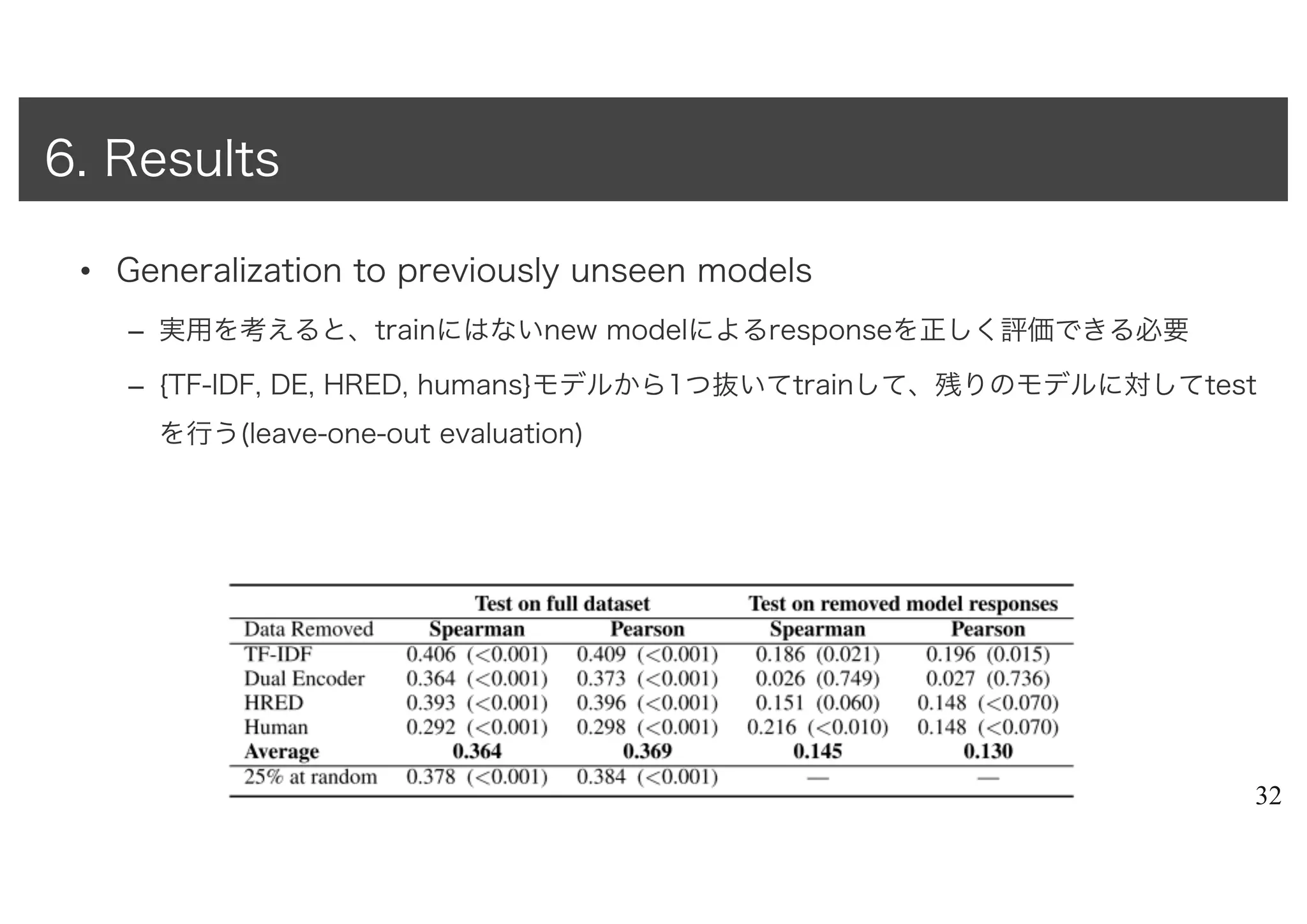
3. CIFAR Senior Fellow
• ACL 2017
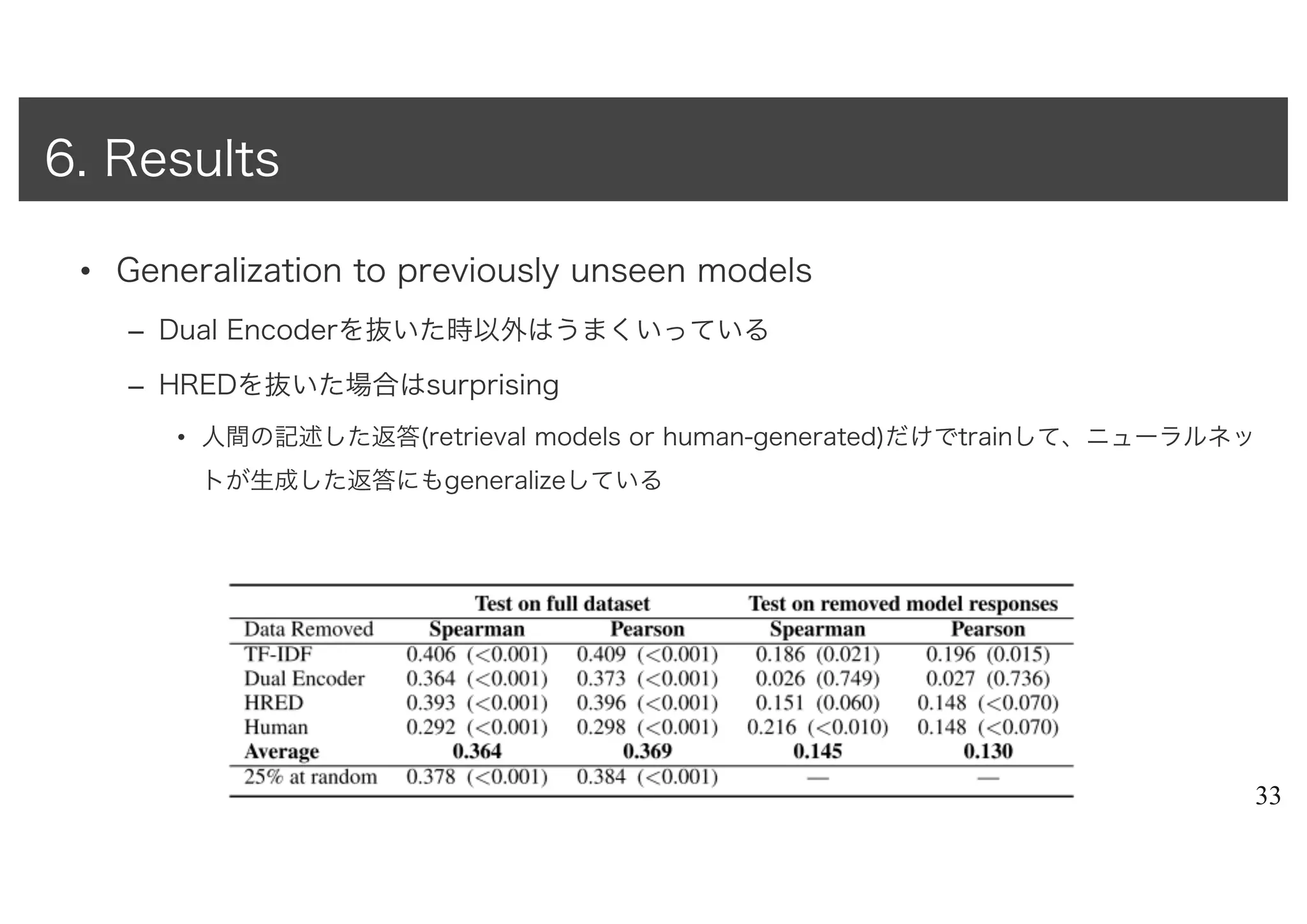
– https://arxiv.org/abs/1708.07149
• Summary
– BLEUなどword-overlap metricによる対話生成の評価は人間による評価とほとんど相関がない
– 人間のスコアリングを学習したモデルを用いて生成結果を評価する手法を提案(ADEM)
– 人間のスコアリングと高い相関性を持つスコアを自動で出力できることを検証
• 実装と学習済みモデルが公開 (https://github.com/mike-n-7/ADEM)
4
1. Paper Information
5.
1. Paper Information
2.Introduction
3. Related Works
4. Proposed Model
5. Experiments
6. Results
7. Discussion
5
Agenda
6.
• 対話システム開発の歴史
– 「人間らしく」人間と対話できる(non-task-oriented)システムの構築はAI研究の歴史の中
でも大きなゴールの1つ[Turing,1950; Weizenbaum, 1966]
– 近年ではneural networkの活用で大規模なnon-task-orientedな対話システム研究が活発
化[Sordoni et al., 2015b; Shang et al., 2015; Vinyals and Le, 2015; Serban et al., 2016a; Li et al., 2015]
– 特定の目的のためにend-to-endで学習されたモデルが成功しているケースもある
• Google’s Smart Reply system[Kannen et al. 2016], Microsoft’s Xiaoice chatbot[Markoff and Mozur, 2015]
• 一方、対話システムの開発で常に課題となってきたのがパフォーマンスの評価
6
2. Introduction
• What isa ‘good’ chatbot ?
– one whose response aarree ssccoorreedd hhiigghhllyy on appropriateness bbyy hhuummaann evaluators.
– 現状の(破綻した返答をするような)対話システムの改善には十分な指標のはず
• 多様な対話に対する人間の評価スコアを収集し、automatic dialogue
evaluation model (ADEM) を学習させる
– hierarchical RNN で human scoresをsemi-supervisedに学習
– ADEMのscoreはutterance-levelでもsystem-levelでも人手評価と高い相関関係を示した
10
2. Introduction
11.
1. Paper Information
2.Introduction
3. Related Works
4. Proposed Model
5. Experiments
6. Results
7. Discussion
11
Agenda
12.
• word-overlap metrics
–BLEU[Papineni et al. 2002]
• 機械翻訳の用途で利用
– ROUGE[Lin, 2004]
• 要約の用途で利用
– 意味的類似性や文脈依存性を測れない
• 単語の共通度合いしか見れない
• 機械翻訳ではそこまで問題にならない(reasonable translationが大体限られている)
• 対話生成ではresponse diversityが非常に高い[Artstein et al., 2009]ためcriticalな問題
– 対話生成では人間の評価とほとんど相関がないことが指摘されている[Liu et al. 2016]
12
3. Related Works
参考:BLEU
N-gramのprecisionを計算し、短文に対するpenaltyを考慮
13.
• chat-oriented dialoguesystemsで返答の質を推定する研究
– automatic dialogue policy evaluation metric [DeVault et al., 2011]
– semi-automatic evaluation metric for dialogue coherence (similar to BLEU and
ROUGE)[Gandle and Traum, 2016]
– a framework to predict utterance-level problematic situations using intent and
sentiment factors[Xiang et al., 2014]
– train a classifier to distinguish user utterances from system-generated utterances
using various dialogue features[Higashinaka et al., 2014]
13
3. Related Works
14.
• hand-crafted rewardfeaturesによる強化学習の活用
– ease of answering and information flow [Li et al., 2016b]
– turn-level appropriateness and conversational depth [Yu et al., 2016]
• hand-crafted featuresであり、対話の一側面しか捉えられていない
– sub-optimal performance
– これがretrieval-based cross-entropyやword-level maximum log-likelihoodの最適化より良
いかはunclear
• conversational-levelでの評価のため、single dialogue responseを評価できない事
が多い
– response-levelで評価できる指標は提案指標に組み込むことが可能
14
3. Related Works
15.
• task-orientedな対話システムについては評価手法の開発が進んでいる
– ex)finding a restaurant
– task completion signalを考慮する指標(PARADISE[Walker et al., 1997], MeMo[Moller et al,, 2006])
– task completionやtask complexityが計測できる領域でないと利用できない
15
3. Related Works
16.
1. Paper Information
2.Introduction
3. Related Works
4. Proposed Model
5. Experiments
6. Results
7. Discussion
16
Agenda
17.
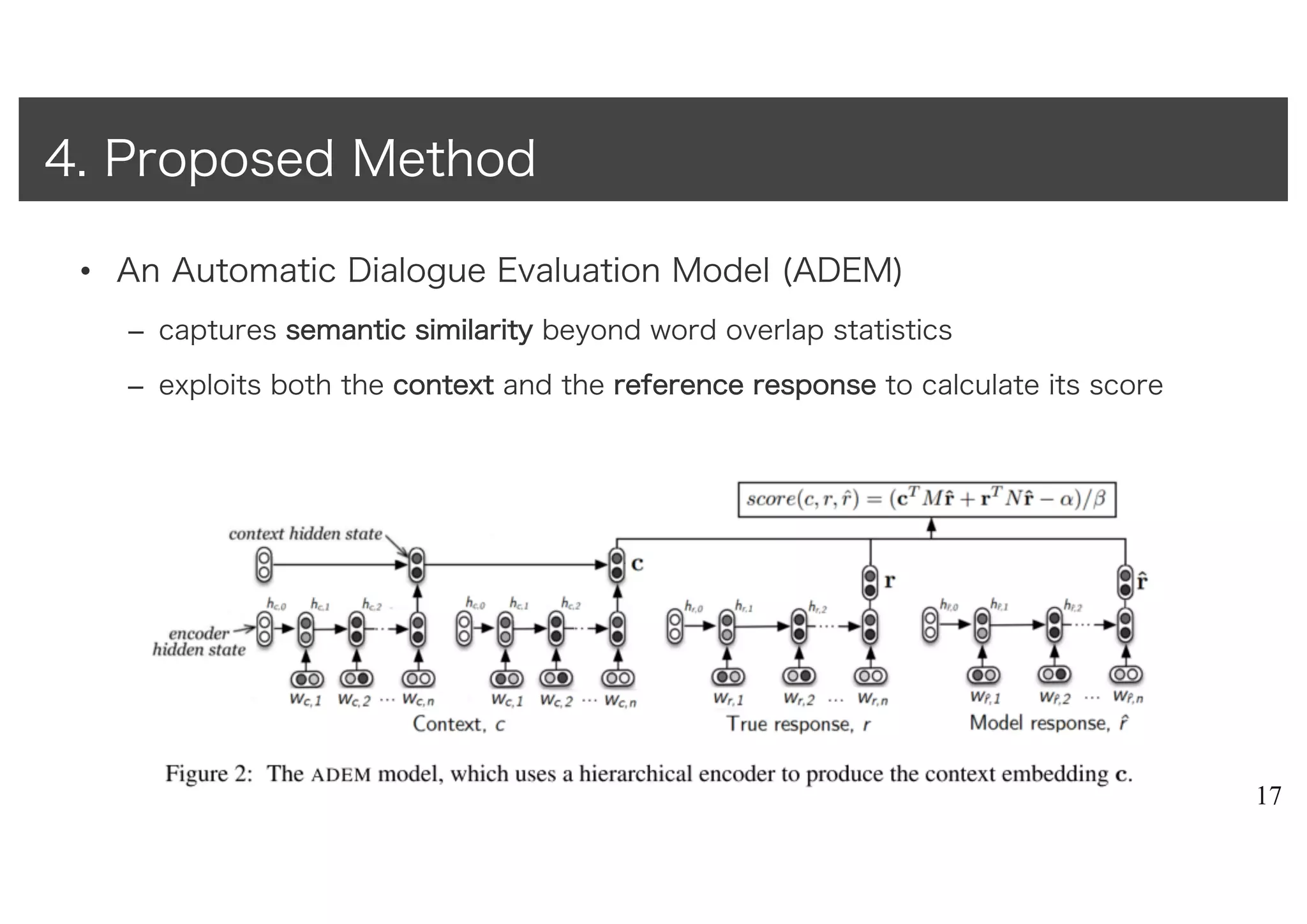
• An AutomaticDialogue Evaluation Model (ADEM)
– captures sseemmaannttiicc ssiimmiillaarriittyy beyond word overlap statistics
– exploits both the ccoonntteexxtt and the rreeffeerreennccee rreessppoonnssee to calculate its score
17
4. Proposed Method
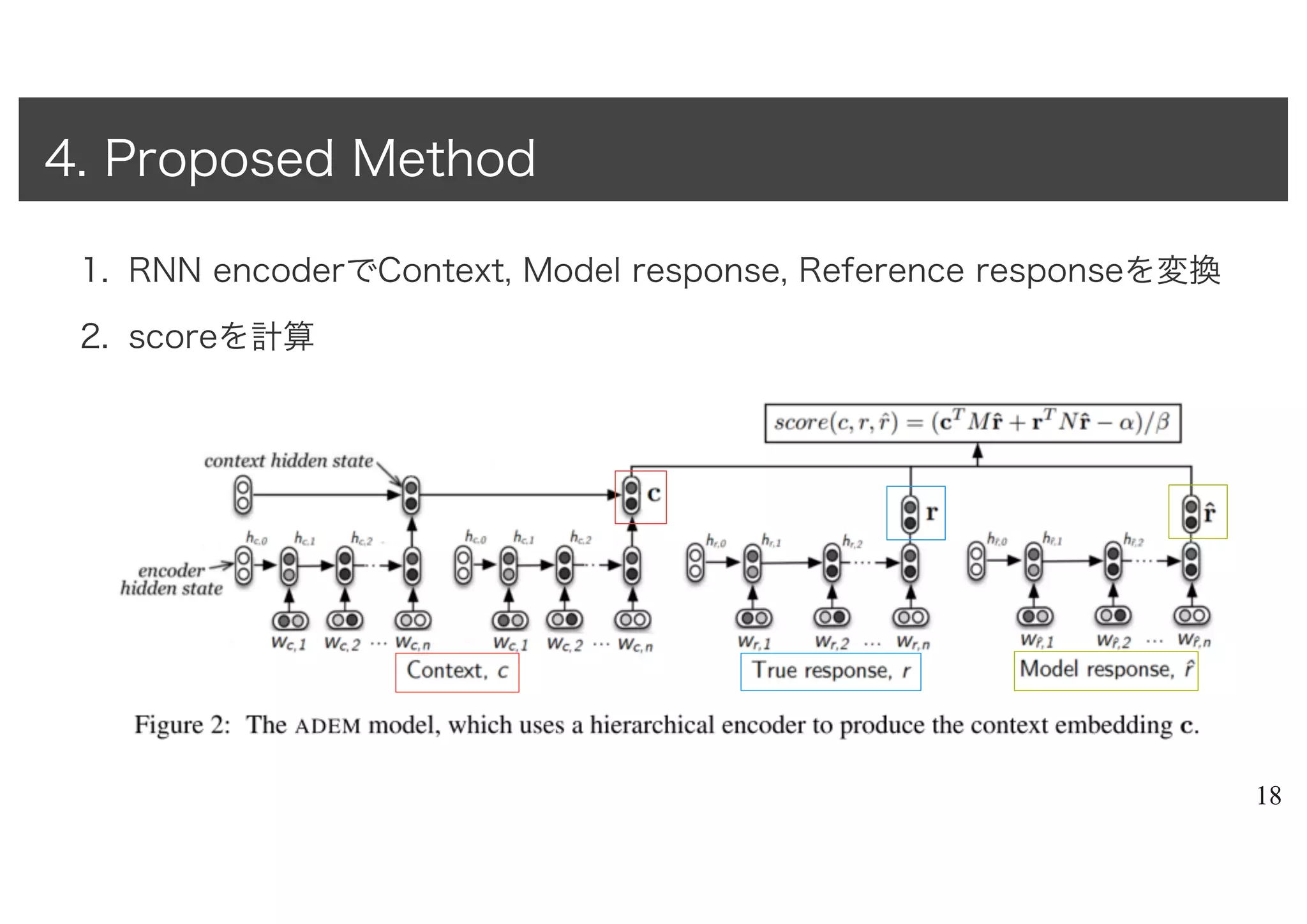
• Hierarchical RNNencoder[El Hihi and Bengio, 1995; Sordoni et al., 2015a]
– utterance-level encoder
• input : word
• output : a vector at the end of each utterance
– context-level encoder
• input : utterance
• output: a vector representation of the context
– Why hierarchical? -> incorporate information from early utterances
– RNN部分のパラメータはpre-trained(後述)
• not learned from human scores
19
4. Proposed Method
20.
•
– パラメータ:M, N
•linear projection
• map !̂ -> # & ! space
– 定数:α, β
• モデルの出力が1~5の範囲に収まるようにscalingする
– contextとreference responseと似たresponseベクトルに対して高いscoreを出力
– scoreと人間の評価スコアの二乗誤差を最小化するように学習(L2正則化)
• simple -> accurate prediction & fast evaluation (cf. supp. material in original paper)
20
4. Proposed Method
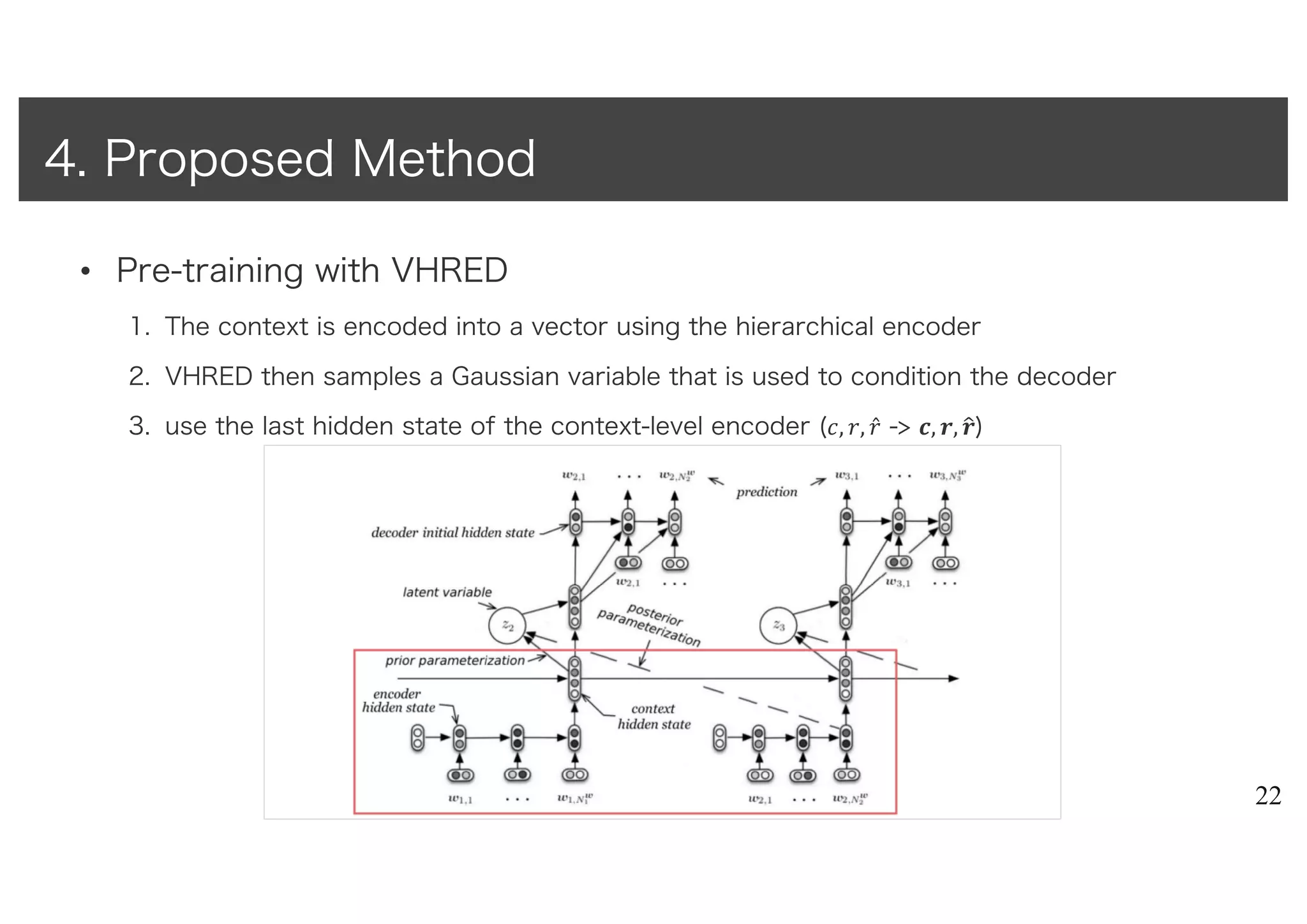
• Pre-training withVHRED
1. The context is encoded into a vector using the hierarchical encoder
2. VHRED then samples a Gaussian variable that is used to condition the decoder
3. use the last hidden state of the context-level encoder (#, !, !̂ -> ', (, ())
22
4. Proposed Method
23.
1. Paper Information
2.Introduction
3. Related Works
4. Proposed Model
5. Experiments
6. Results
7. Discussion
23
Agenda
24.
• Settings
– BPE(BytePair Encoding)[Gage, 1994; Sennrich et al., 2015]
• reduce the effective vocabulary size
– layer normalization[Ba et al., 2016] for hierarchical encoder
• better than batch normalization[Ioffe and Szegedy, 2015; Cooijmans et al., 2016]
– used several of techniques to train the VHRED[Serban et al., 2016b; Bowman et al., 2016]
• drop words in the decoder 25%
• anneal the KL linearly from 0 to1 over the first 60,000batches
– Adam[Kingma and Ba, 2014] optimizer
24
5. Experiments
25.
• Settings
– trainingADEM
• employ a subsampling procedure based on the model response length
• ensure that ADEM does not use response length to predict the score
– humans have a tendency to give a higher rating to give a higher rating to shorter responses
– training VHRED
• embedding size = 2,000
– after training VHRED, use PCA to reduce the dimensionality (n = 50)
– Early stopping
25
5. Experiments
26.
• Data Collection
–Twitter Corpus[Ritter et al., 2011]を対象にresponseを生成し、クラウドソーシング(Amazon
Mechanical Turk)で人間がスコアリング
• relevant / irrelevant responses
• coherent / incoherent responses
– 4パターンのCandidate responsesを用意してresponse varietyを増やす
• a response selected by TF-IFD retrieval-based model
• a response selected by the Dual Encoder(DE)[Lowe et al., 2015]
• a response generated by the hierarchical recurrent encoder-decoder(HRED)
• human-generated responses
– novel human response, different from a fixed corpus
26
5. Experiments
27.
1. Paper Information
2.Introduction
3. Related Works
4. Proposed Model
5. Experiments
6. Results
7. Discussion
27
Agenda
![DEEP LEARNING JP
[DL Papers]
“Towards an AutomaticTuringTest:
Learning to Evaluate Dialog Response (ACL2017)”
Hiromi Nakagawa, Matsuo Lab
http://deeplearning.jp/](https://image.slidesharecdn.com/170925dlhackstowardsanautomaticturingtest-170925104902/75/DL-Towards-an-Automatic-Turing-Test-Learning-to-Evaluate-Dialogue-Responses-1-2048.jpg)




![• 対話システム開発の歴史
– 「人間らしく」人間と対話できる(non-task-oriented)システムの構築はAI研究の歴史の中
でも大きなゴールの1つ[Turing, 1950; Weizenbaum, 1966]
– 近年ではneural networkの活用で大規模なnon-task-orientedな対話システム研究が活発
化[Sordoni et al., 2015b; Shang et al., 2015; Vinyals and Le, 2015; Serban et al., 2016a; Li et al., 2015]
– 特定の目的のためにend-to-endで学習されたモデルが成功しているケースもある
• Google’s Smart Reply system[Kannen et al. 2016], Microsoft’s Xiaoice chatbot[Markoff and Mozur, 2015]
• 一方、対話システムの開発で常に課題となってきたのがパフォーマンスの評価
6
2. Introduction](https://image.slidesharecdn.com/170925dlhackstowardsanautomaticturingtest-170925104902/75/DL-Towards-an-Automatic-Turing-Test-Learning-to-Evaluate-Dialogue-Responses-6-2048.jpg)
![• 対話システムのパフォーマンス評価
– Turing test:システムか人間かを見分ける評価を人間が行う
• 合理的ではあるが、制約も多く、人手による評価が必要なためスケーリングしにくい
• 相当注意深く評価システムを設計しないと、バイアスがかかりやすい
– 「見分ける」まではせず、対話の質を人間が主観評価する
• いずれにせよ時間/費用/スケールしにくい問題は解決しない
• 特にspecific conversation domainsではその評価を行える有識者の用意が大変[Lowe et al., 2015]
7
2. Introduction](https://image.slidesharecdn.com/170925dlhackstowardsanautomaticturingtest-170925104902/75/DL-Towards-an-Automatic-Turing-Test-Learning-to-Evaluate-Dialogue-Responses-7-2048.jpg)
![• Neural network-based modelの発展にもかかわらず、non-task-orientedな
タスクでは評価指標が依然として問題となっている
– BLEU含めword-overlap指標は、人間の評価とほとんど相関がない[Liu et al. 2016]
– response間のsemantic similarityを考慮できないことが問題
8
2. Introduction](https://image.slidesharecdn.com/170925dlhackstowardsanautomaticturingtest-170925104902/75/DL-Towards-an-Automatic-Turing-Test-Learning-to-Evaluate-Dialogue-Responses-8-2048.jpg)



![• word-overlap metrics
– BLEU[Papineni et al. 2002]
• 機械翻訳の用途で利用
– ROUGE[Lin, 2004]
• 要約の用途で利用
– 意味的類似性や文脈依存性を測れない
• 単語の共通度合いしか見れない
• 機械翻訳ではそこまで問題にならない(reasonable translationが大体限られている)
• 対話生成ではresponse diversityが非常に高い[Artstein et al., 2009]ためcriticalな問題
– 対話生成では人間の評価とほとんど相関がないことが指摘されている[Liu et al. 2016]
12
3. Related Works
参考:BLEU
N-gramのprecisionを計算し、短文に対するpenaltyを考慮](https://image.slidesharecdn.com/170925dlhackstowardsanautomaticturingtest-170925104902/75/DL-Towards-an-Automatic-Turing-Test-Learning-to-Evaluate-Dialogue-Responses-12-2048.jpg)
![• chat-oriented dialogue systemsで返答の質を推定する研究
– automatic dialogue policy evaluation metric [DeVault et al., 2011]
– semi-automatic evaluation metric for dialogue coherence (similar to BLEU and
ROUGE)[Gandle and Traum, 2016]
– a framework to predict utterance-level problematic situations using intent and
sentiment factors[Xiang et al., 2014]
– train a classifier to distinguish user utterances from system-generated utterances
using various dialogue features[Higashinaka et al., 2014]
13
3. Related Works](https://image.slidesharecdn.com/170925dlhackstowardsanautomaticturingtest-170925104902/75/DL-Towards-an-Automatic-Turing-Test-Learning-to-Evaluate-Dialogue-Responses-13-2048.jpg)
![• hand-crafted reward featuresによる強化学習の活用
– ease of answering and information flow [Li et al., 2016b]
– turn-level appropriateness and conversational depth [Yu et al., 2016]
• hand-crafted featuresであり、対話の一側面しか捉えられていない
– sub-optimal performance
– これがretrieval-based cross-entropyやword-level maximum log-likelihoodの最適化より良
いかはunclear
• conversational-levelでの評価のため、single dialogue responseを評価できない事
が多い
– response-levelで評価できる指標は提案指標に組み込むことが可能
14
3. Related Works](https://image.slidesharecdn.com/170925dlhackstowardsanautomaticturingtest-170925104902/75/DL-Towards-an-Automatic-Turing-Test-Learning-to-Evaluate-Dialogue-Responses-14-2048.jpg)
![• task-orientedな対話システムについては評価手法の開発が進んでいる
– ex) finding a restaurant
– task completion signalを考慮する指標(PARADISE[Walker et al., 1997], MeMo[Moller et al,, 2006])
– task completionやtask complexityが計測できる領域でないと利用できない
15
3. Related Works](https://image.slidesharecdn.com/170925dlhackstowardsanautomaticturingtest-170925104902/75/DL-Towards-an-Automatic-Turing-Test-Learning-to-Evaluate-Dialogue-Responses-15-2048.jpg)

![• Hierarchical RNN encoder[El Hihi and Bengio, 1995; Sordoni et al., 2015a]
– utterance-level encoder
• input : word
• output : a vector at the end of each utterance
– context-level encoder
• input : utterance
• output: a vector representation of the context
– Why hierarchical? -> incorporate information from early utterances
– RNN部分のパラメータはpre-trained(後述)
• not learned from human scores
19
4. Proposed Method](https://image.slidesharecdn.com/170925dlhackstowardsanautomaticturingtest-170925104902/75/DL-Towards-an-Automatic-Turing-Test-Learning-to-Evaluate-Dialogue-Responses-19-2048.jpg)

![• Pre-training with VHRED
– encoderをneural dialogue modelとして学習させる
• encoder outputを受け取ってnext utteranceを予測する3rd decoder RNNを追加
– VHRED (latent variable hierarchical recurrent encoder decoder[Serban et al., 2016b])
• stochastic latent variable
• HREDよりもdiverseでcoherentな返答を生成できる
21
4. Proposed Method](https://image.slidesharecdn.com/170925dlhackstowardsanautomaticturingtest-170925104902/75/DL-Towards-an-Automatic-Turing-Test-Learning-to-Evaluate-Dialogue-Responses-21-2048.jpg)

![• Settings
– BPE(Byte Pair Encoding)[Gage, 1994; Sennrich et al., 2015]
• reduce the effective vocabulary size
– layer normalization[Ba et al., 2016] for hierarchical encoder
• better than batch normalization[Ioffe and Szegedy, 2015; Cooijmans et al., 2016]
– used several of techniques to train the VHRED[Serban et al., 2016b; Bowman et al., 2016]
• drop words in the decoder 25%
• anneal the KL linearly from 0 to1 over the first 60,000batches
– Adam[Kingma and Ba, 2014] optimizer
24
5. Experiments](https://image.slidesharecdn.com/170925dlhackstowardsanautomaticturingtest-170925104902/75/DL-Towards-an-Automatic-Turing-Test-Learning-to-Evaluate-Dialogue-Responses-24-2048.jpg)

![• Data Collection
– Twitter Corpus[Ritter et al., 2011]を対象にresponseを生成し、クラウドソーシング(Amazon
Mechanical Turk)で人間がスコアリング
• relevant / irrelevant responses
• coherent / incoherent responses
– 4パターンのCandidate responsesを用意してresponse varietyを増やす
• a response selected by TF-IFD retrieval-based model
• a response selected by the Dual Encoder(DE)[Lowe et al., 2015]
• a response generated by the hierarchical recurrent encoder-decoder(HRED)
• human-generated responses
– novel human response, different from a fixed corpus
26
5. Experiments](https://image.slidesharecdn.com/170925dlhackstowardsanautomaticturingtest-170925104902/75/DL-Towards-an-Automatic-Turing-Test-Learning-to-Evaluate-Dialogue-Responses-26-2048.jpg)





![• 提案モデルは多様な目的のデータセットに適用可能
– 一度pre-trainedモデルが公開されれば、その目的のために利用が可能
• domain transfer ability はfuture work
• 人間が高評価する返答を出力するdialogue modelは、chatbotのdesired end-goalではない
– generic responseの問題(人間は無難な/汎用性の高い返答を好む[Shang et al., 2016])
– このbiasがかからないようにADEMを拡張することがfuture work
• 長さに対して情報量の少ない返答を許容しないようにする
• adversarial evaluation model[Kannan and Vinyals, 2017; Li et al., 2017]
– 人間の返答かそうでないかを見分ける。generic responsesはeasy to distinguishableなのでスコアが低くなる
• 対話システムが人間と魅力的で意味深いinteractionをしているかを評価できるモデルが重要
– 難しいが、提案手法がこれを達成する過程での1つのstepになるはず
37
7. Discussion](https://image.slidesharecdn.com/170925dlhackstowardsanautomaticturingtest-170925104902/75/DL-Towards-an-Automatic-Turing-Test-Learning-to-Evaluate-Dialogue-Responses-37-2048.jpg)


![[DL輪読会]Imagination-Augmented Agents for Deep Reinforcement Learning / Learnin...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacksshioya201707281-170728054152-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Training RNNs as Fast as CNNs](https://cdn.slidesharecdn.com/ss_thumbnails/20171002dlhacks-171002105129-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Meta-Learning Probabilistic Inference for Prediction](https://cdn.slidesharecdn.com/ss_thumbnails/20181214dl-181218052422-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Learning Latent Dynamics for Planning from Pixels](https://cdn.slidesharecdn.com/ss_thumbnails/taniguchi20181221-190104064850-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Adversarial Feature Matching for Text Generation](https://cdn.slidesharecdn.com/ss_thumbnails/dljp170707-170707035929-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会] Spectral Norm Regularization for Improving the Generalizability of De...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhackspectralnorm1-170907072536-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]The Neural Process Family−Neural Processes関連の実装を読んで動かしてみる−](https://cdn.slidesharecdn.com/ss_thumbnails/20190415dlhacks-190422075753-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]QUASI-RECURRENT NEURAL NETWORKS](https://cdn.slidesharecdn.com/ss_thumbnails/quasi-recurrentneuralnetworks-170512014332-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Convolutional Sequence to Sequence Learning](https://cdn.slidesharecdn.com/ss_thumbnails/dl0519-170519005603-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Learning to Adapt: Meta-Learning for Model-Based Control](https://cdn.slidesharecdn.com/ss_thumbnails/20180511dl-180511004107-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]StyleNet: Generating Attractive Visual Captions with Styles](https://cdn.slidesharecdn.com/ss_thumbnails/170707dljp-170707014759-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Dream to Control: Learning Behaviors by Latent Imagination](https://cdn.slidesharecdn.com/ss_thumbnails/20200313furutav2-200313025657-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DLHacks 実装] DeepPose: Human Pose Estimation via Deep Neural Networks](https://cdn.slidesharecdn.com/ss_thumbnails/20170821onodeepposepresentation-170928100207-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Dense Captioning分野のまとめ](https://cdn.slidesharecdn.com/ss_thumbnails/dlseminar-201202012355-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Deep Face Recognition: A Survey](https://cdn.slidesharecdn.com/ss_thumbnails/20181221-181221023935-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Learning Task Informed Abstractions](https://cdn.slidesharecdn.com/ss_thumbnails/20210709akuzawa-210709021836-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DLHacks 実装]Neural Machine Translation in Linear Time](https://cdn.slidesharecdn.com/ss_thumbnails/0925dlhacks-171005051158-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会] The Conditional Analogy GAN: Swapping Fashion Articles on People Images](https://cdn.slidesharecdn.com/ss_thumbnails/20170925gotodl-170925105116-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DLHacks] DLHacks説明資料](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks-170919004557-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DLHacks 実装] The statistical recurrent unit](https://cdn.slidesharecdn.com/ss_thumbnails/dlhackssru0828-170928101102-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会] DeepNav: Learning to Navigate Large Cities](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20170911yokota-170921075407-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Parallel Multiscale Autoregressive Density Estimation](https://cdn.slidesharecdn.com/ss_thumbnails/2017-10-021-171002104912-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DLHacks 実装]Network Dissection: Quantifying Interpretability of Deep Visual R...](https://cdn.slidesharecdn.com/ss_thumbnails/171030netdissectimple1-171030120240-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DLHacks 実装]Perceptual Adversarial Networks for Image-to-Image Transformation](https://cdn.slidesharecdn.com/ss_thumbnails/20171017dlhacks-171019082642-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Opening the Black Box of Deep Neural Networks via Information](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks10161-171027055615-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DLHacks LT] PytorchのDataLoader -torchtextのソースコードを読んでみた-](https://cdn.slidesharecdn.com/ss_thumbnails/torchtextupload-170918235754-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会] MoCoGAN: Decomposing Motion and Content for Video Generation](https://cdn.slidesharecdn.com/ss_thumbnails/0911mocogan-170911121936-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Energy-based generative adversarial networks](https://cdn.slidesharecdn.com/ss_thumbnails/energy-basedgenerativeadversarialnetworks-171030102253-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Mastering the Dungeon: Grounded Language Learning by Mechanical Turker...](https://cdn.slidesharecdn.com/ss_thumbnails/180126groundedlanguagelearningbymechanicalturkerdecent1-180126004830-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]It's not just size that maters small language models are also few sho...](https://cdn.slidesharecdn.com/ss_thumbnails/itsnotjustsizethatmaterssmalllanguagemodelsarealsofew-shotlearners-210910034516-thumbnail.jpg?width=640&height=640&fit=bounds)

![[PaperReading]Unsupervised Discrete Sentence Representation Learning for Inte...](https://cdn.slidesharecdn.com/ss_thumbnails/paperreading-20180702shinoda-180702111612-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Temporal Abstraction in NeurIPS2019](https://cdn.slidesharecdn.com/ss_thumbnails/20191115-191112082849-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Experience Grounds Language](https://cdn.slidesharecdn.com/ss_thumbnails/20200515iwasawa-200515060537-thumbnail.jpg?width=640&height=640&fit=bounds)


























