⽬標: 実装レベルでVQ-VAEを理解する
n 第⼀著者:Aaron van den Oord
n 同著者が書いた関連論⽂
n Neural Discrete Representation Learning (NIPS 2017)
n Generating Diverse High-Fidelity Images with VQ-VAE-2 (NIPS 2019)
n 概要:
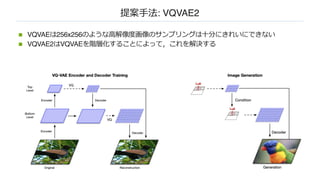
n VAEのフレームワークで離散的な潜在変数の学習を可能にし,posterior collapseの問題を解決する
ことで,⾼いクオリティの画像,ビデオ,⾳声のサンプリングを可能にした
VQVAE2による256x256のサンプル
3.
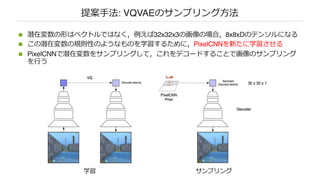
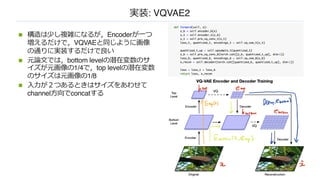
提案⼿法: VQVAEの学習⽅法
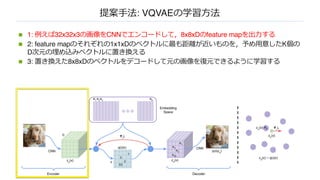
n 1:例えば32x32x3の画像をCNNでエンコードして,8x8xDのfeature mapを出⼒する
n 2: feature mapのそれぞれの1x1xDのベクトルに最も距離が近いものを,予め⽤意したK個の
D次元の埋め込みベクトルに置き換える
n 3: 置き換えた8x8xDのベクトルをデコードして元の画像を復元できるように学習する
4.
提案⼿法: VQVAEの学習⽅法
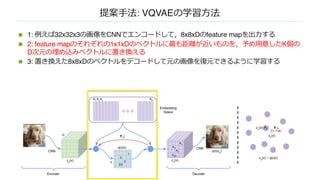
n 1:例えば32x32x3の画像をCNNでエンコードして,8x8xDのfeature mapを出⼒する
n 2: feature mapのそれぞれの1x1xDのベクトルに最も距離が近いものを,予め⽤意したK個の
D次元の埋め込みベクトルに置き換える
n 3: 置き換えた8x8xDのベクトルをデコードして元の画像を復元できるように学習する
5.
提案⼿法: VQVAEの学習⽅法
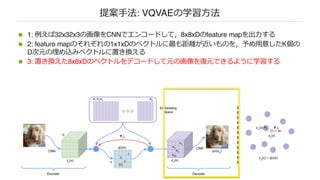
n 1:例えば32x32x3の画像をCNNでエンコードして,8x8xDのfeature mapを出⼒する
n 2: feature mapのそれぞれの1x1xDのベクトルに最も距離が近いものを,予め⽤意したK個の
D次元の埋め込みベクトルに置き換える
n 3: 置き換えた8x8xDのベクトルをデコードして元の画像を復元できるように学習する
6.
提案⼿法: VQVAEの学習⽅法
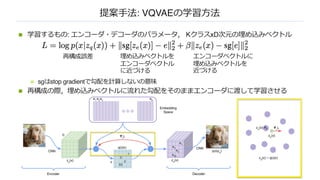
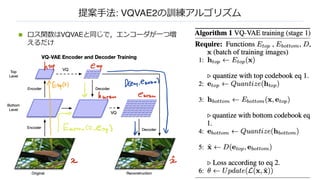
n 学習するもの:エンコーダ・デコーダのパラメータ, KクラスxD次元の埋め込みベクトル
n sgはstop gradientで勾配を計算しないの意味
n 再構成の際,埋め込みベクトルに流れた勾配をそのままエンコーダに渡して学習させる
再構成誤差 埋め込みベクトルを
エンコーダベクトル
に近づける
エンコーダベクトルに
埋め込みベクトルを
近づける
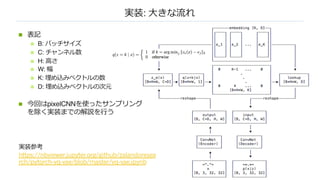
実装: ⼤きな流れ
n 表記
nB: バッチサイズ
n C: チャンネル数
n H: ⾼さ
n W: 幅
n K: 埋め込みベクトルの数
n D: 埋め込みベクトルの次元
n 今回はpixelCNNを使ったサンプリング
を除く実装までの解説を⾏う
実装参考
https://nbviewer.jupyter.org/github/zalandoresea
rch/pytorch-vq-vae/blob/master/vq-vae.ipynb
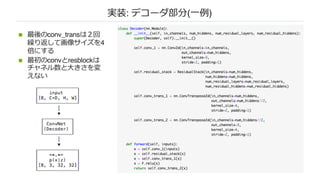
実装: VQ部分
n encoding_indices:(B*W*H, 1)
n 距離で⼀番近い部分をとる
n encodings: (B*W*H, K)
n 0の⾏列をつくる
n encodings.scatter_(1, encoding_indices, 1)
n 1番⽬のaxisでインデックス番号の0を1に変換する
(one hotになる)
n quantized: (B, H, W, D)
n エンコードベクトルを埋め込みベクトルにする
quantized
encodings
encoding
indices
17.
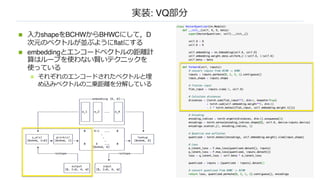
実装: VQ部分
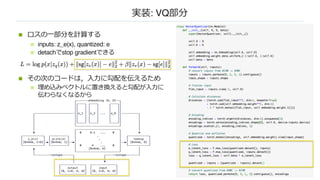
n ロスの⼀部分を計算する
ninputs: z_e(x), quantized: e
n detachでstop gradientできる
n その次のコードは,⼊⼒に勾配を伝えるため
n 埋め込みベクトルに置き換えると勾配が⼊⼒に
伝わらなくなるから
18.
実装: VQ部分
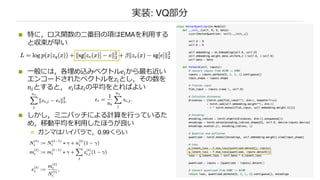
n 特に,ロス関数の⼆番⽬の項はEMAを利⽤する
と収束が早い
n⼀般には,各埋め込みベクトル𝑒"から最も近い
エンコードされたベクトルを𝑧"とし,その数を
𝑛"とすると, 𝑒"は𝑧"の平均をとればよい
n しかし,ミニバッチによる計算を⾏っているた
め,移動平均を利⽤したほうが良い
n ガンマはハイパラで,0.99くらい











![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会] Spectral Norm Regularization for Improving the Generalizability of De...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhackspectralnorm1-170907072536-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Glow: Generative Flow with Invertible 1×1 Convolutions](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20180720-180723071258-thumbnail.jpg?width=640&height=640&fit=bounds)


![[解説スライド] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerf20200327slideshare-200326131430-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerfdlseminar1-200327021512-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://cdn.slidesharecdn.com/ss_thumbnails/swintransformer-210514020542-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]DropBlock: A regularization method for convolutional networks](https://cdn.slidesharecdn.com/ss_thumbnails/dlyokota20190222-190222002832-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing](https://cdn.slidesharecdn.com/ss_thumbnails/glide2-220107030326-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=640&height=640&fit=bounds)




![SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向](https://cdn.slidesharecdn.com/ss_thumbnails/os2-03latest-210610045610-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Variational Autoencoder with Arbitrary Conditioning](https://cdn.slidesharecdn.com/ss_thumbnails/190412nonakadlhacksv2-190422075347-thumbnail.jpg?width=640&height=640&fit=bounds)












![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=640&height=640&fit=bounds)
























