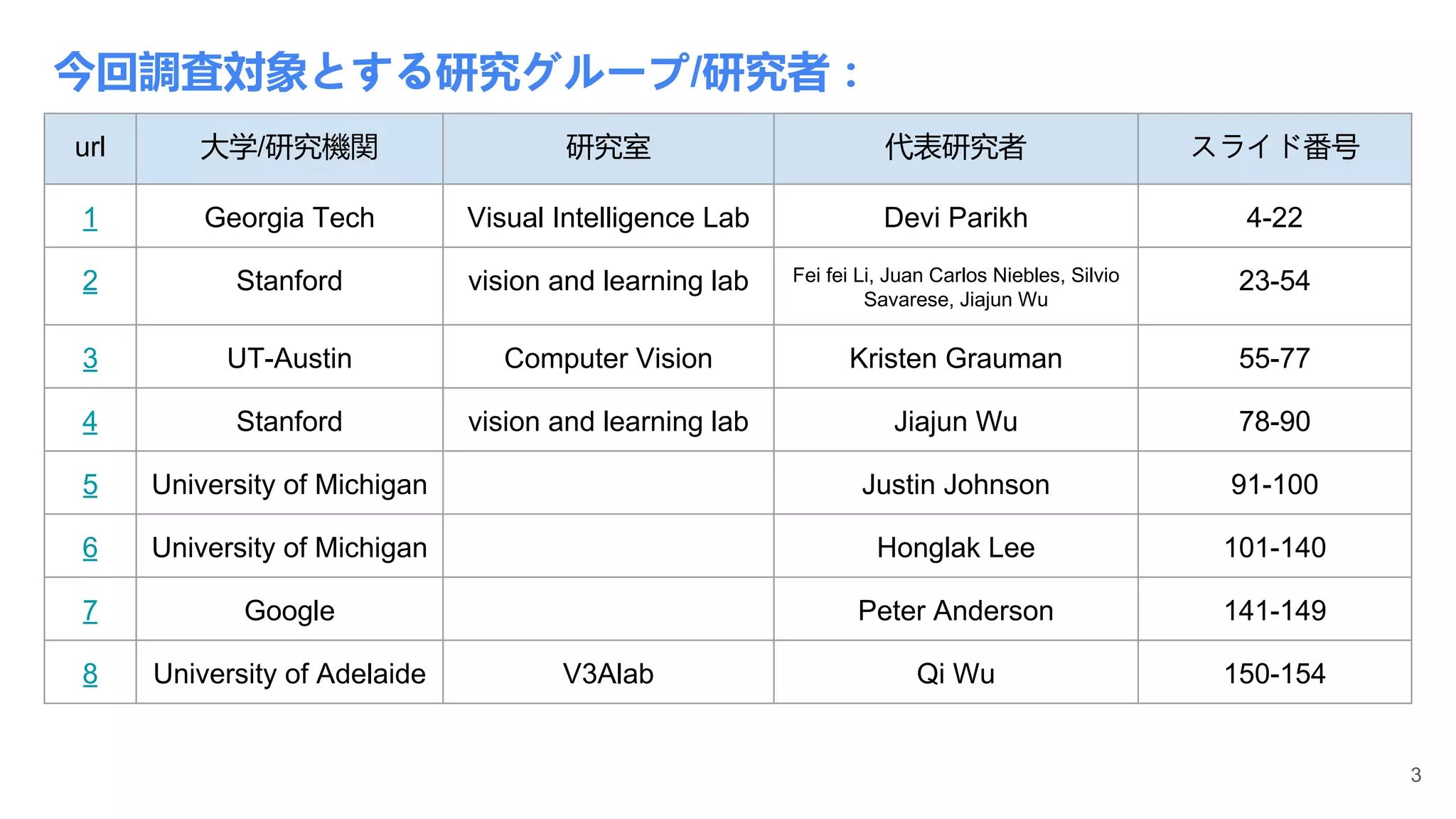
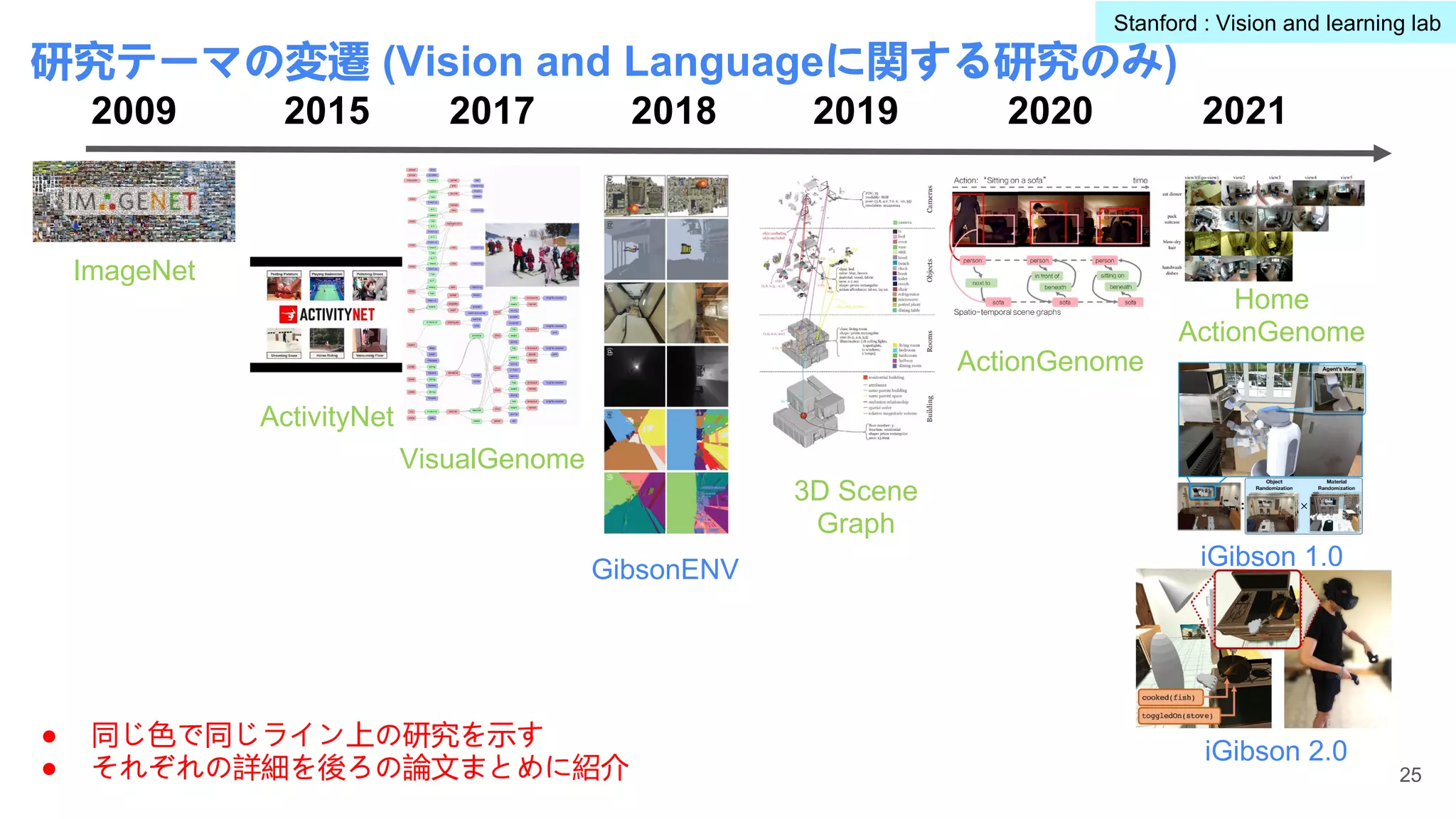
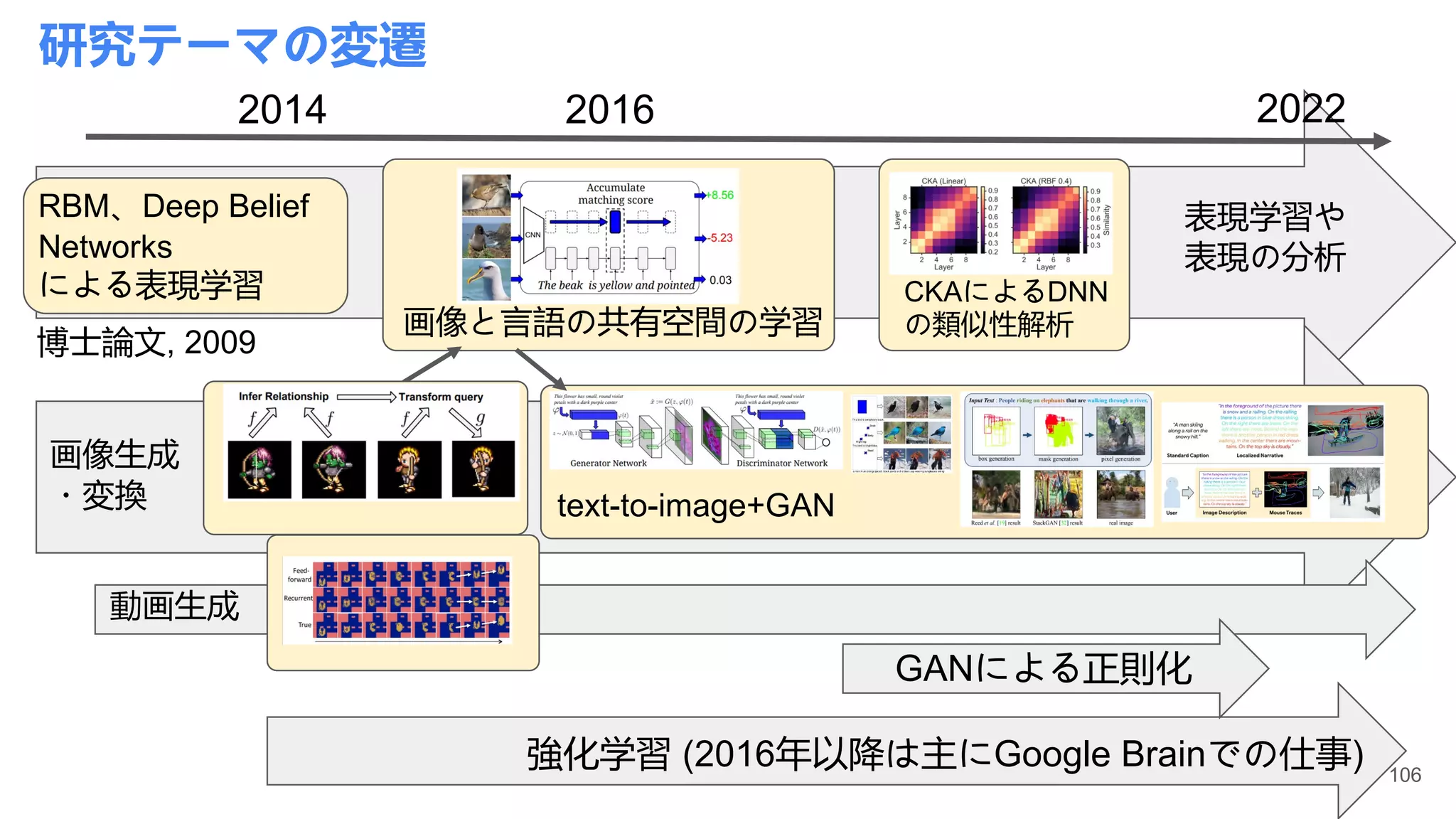
今回調査対象とする研究グループ/研究者:
url 大学/研究機関 研究室代表研究者 スライド番号
1 Georgia Tech Visual Intelligence Lab Devi Parikh 4-22
2 Stanford vision and learning lab Fei fei Li, Juan Carlos Niebles, Silvio
Savarese, Jiajun Wu
23-54
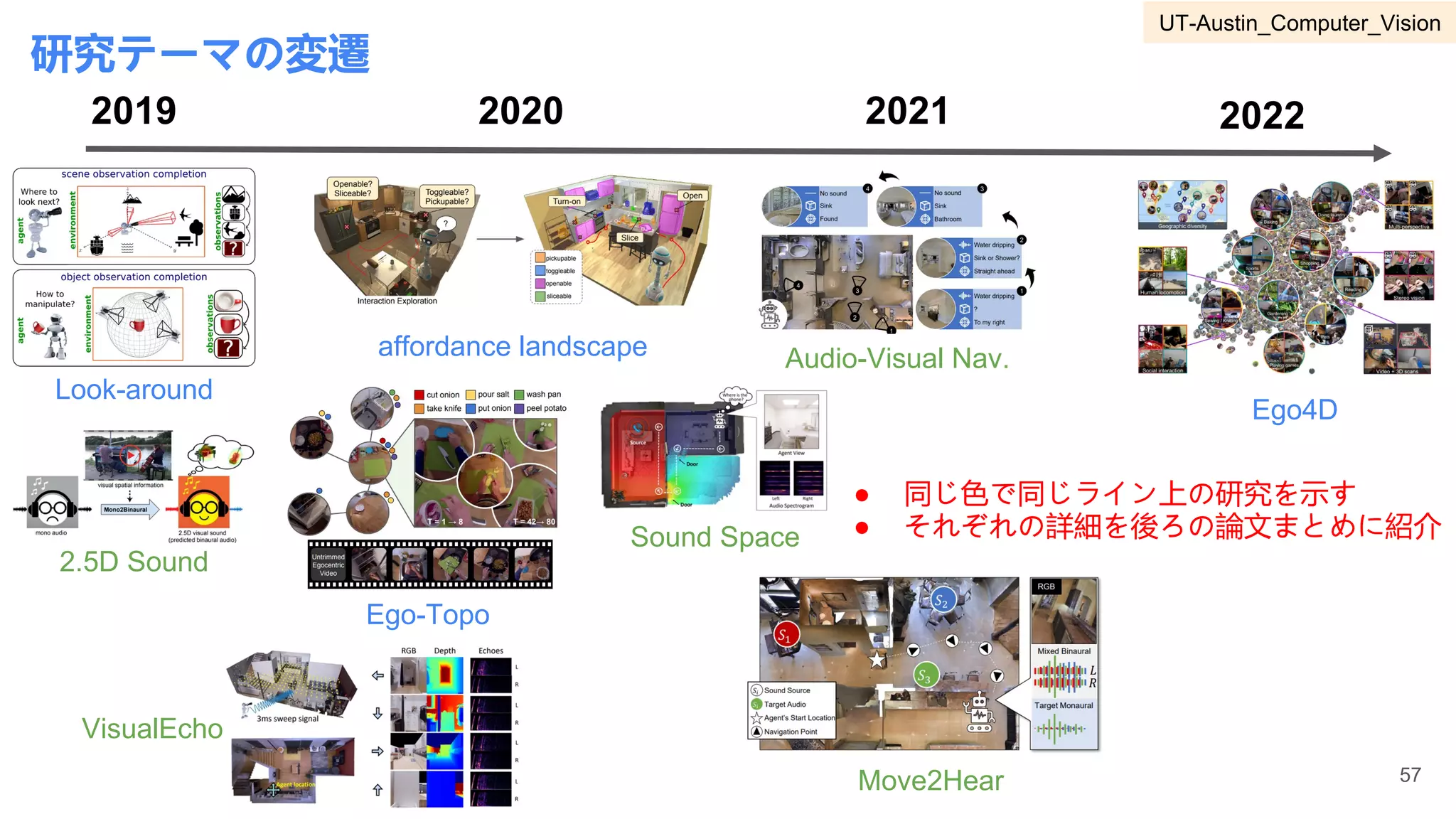
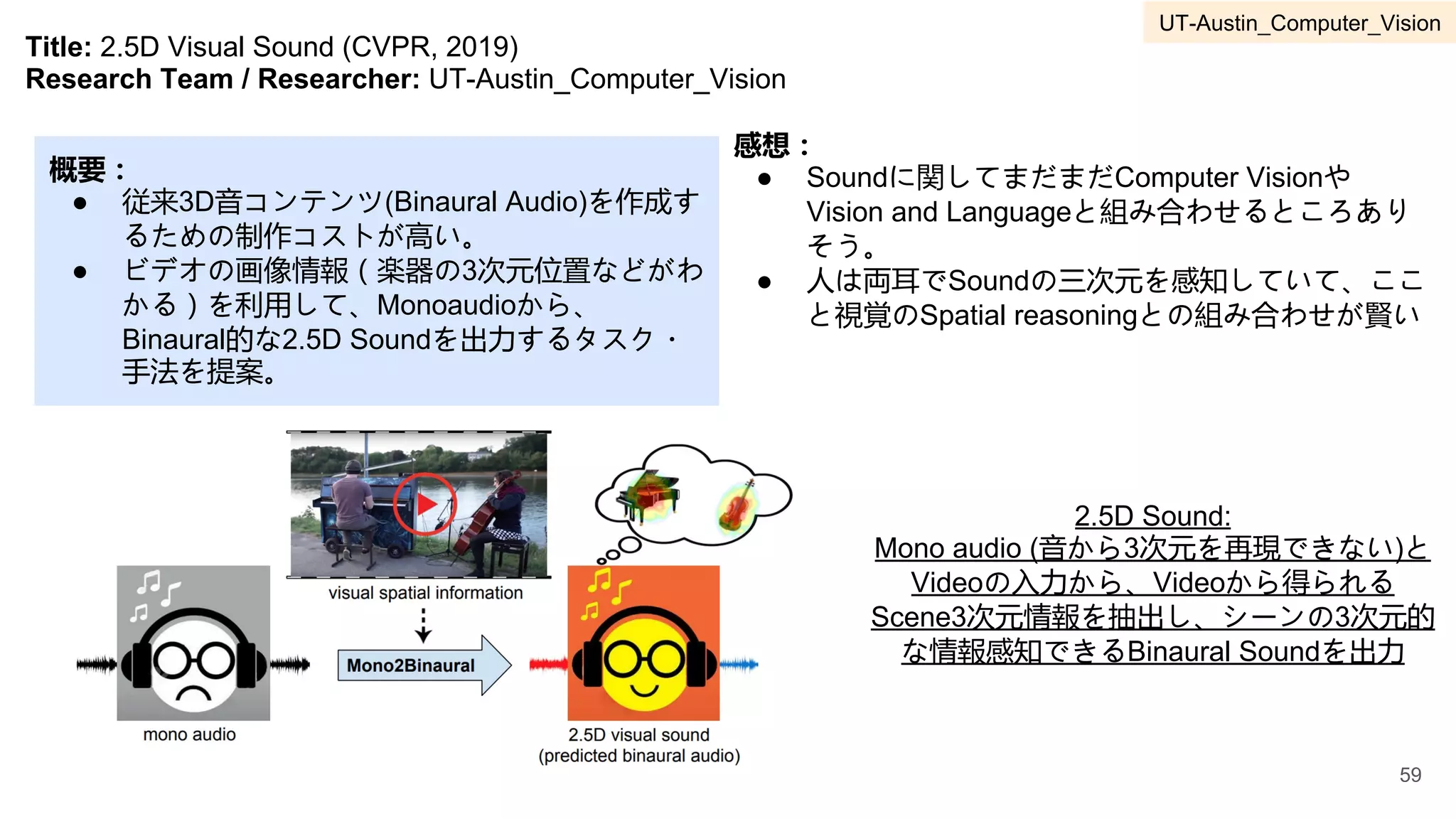
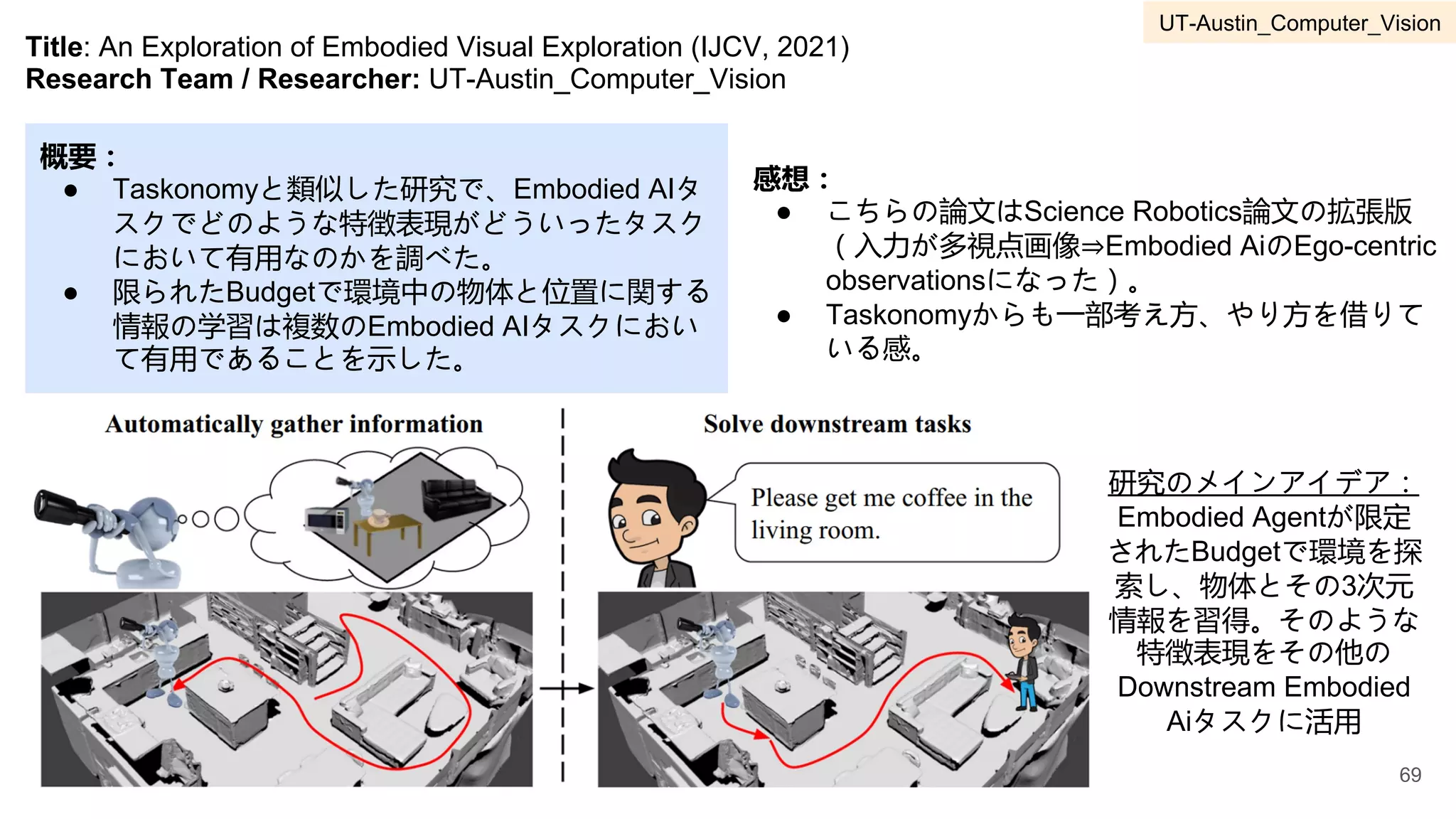
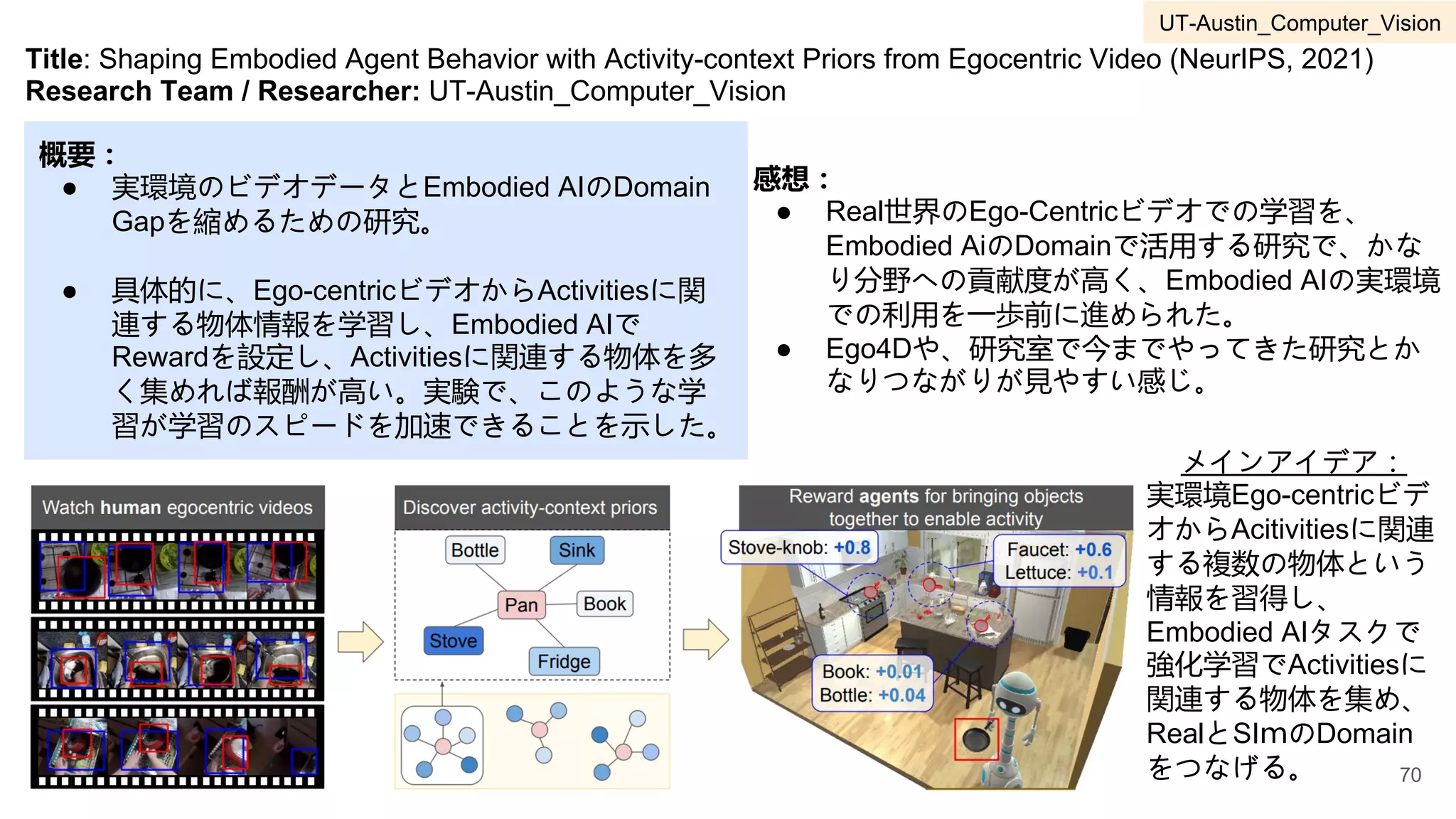
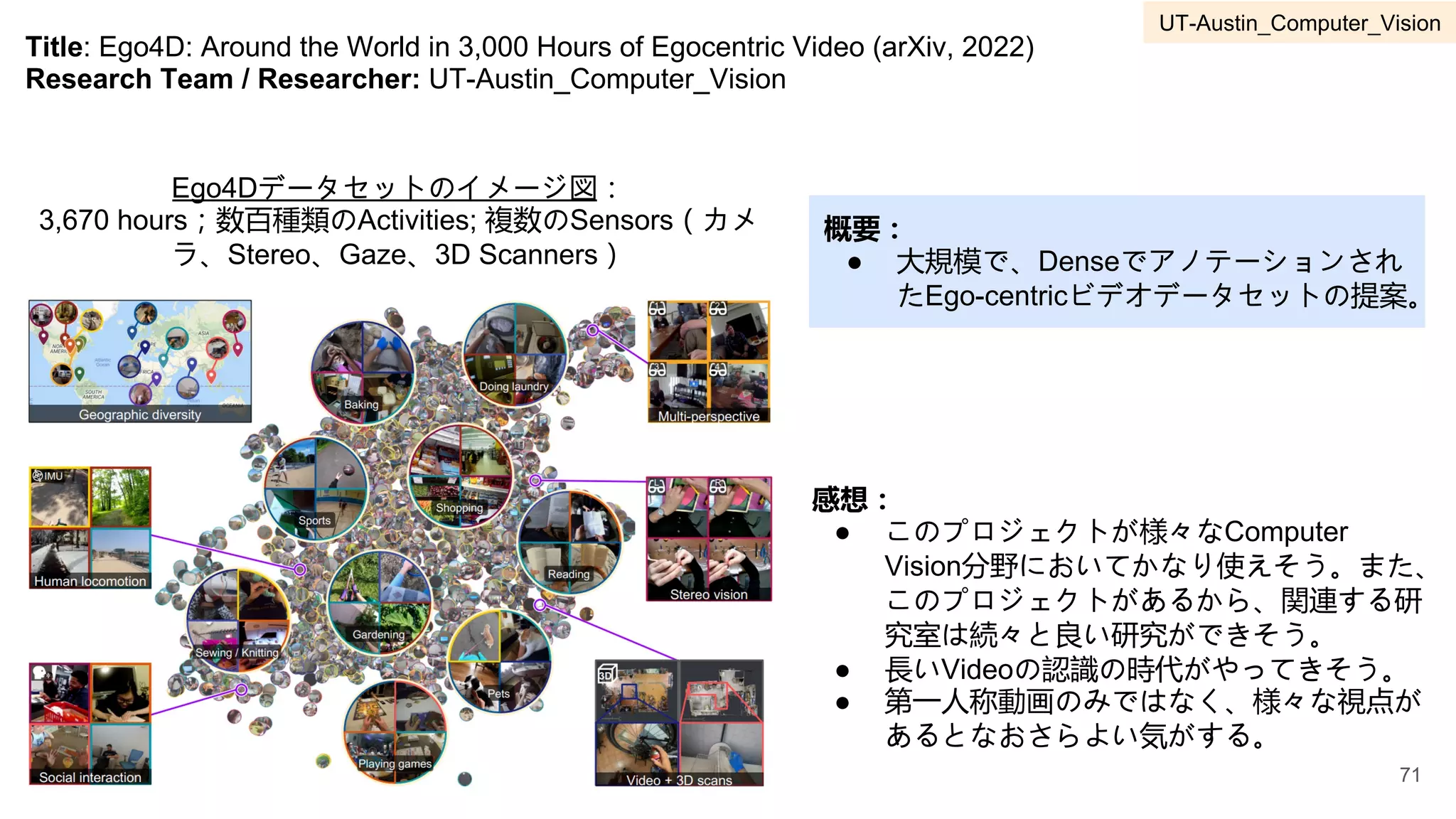
3 UT-Austin Computer Vision Kristen Grauman 55-77
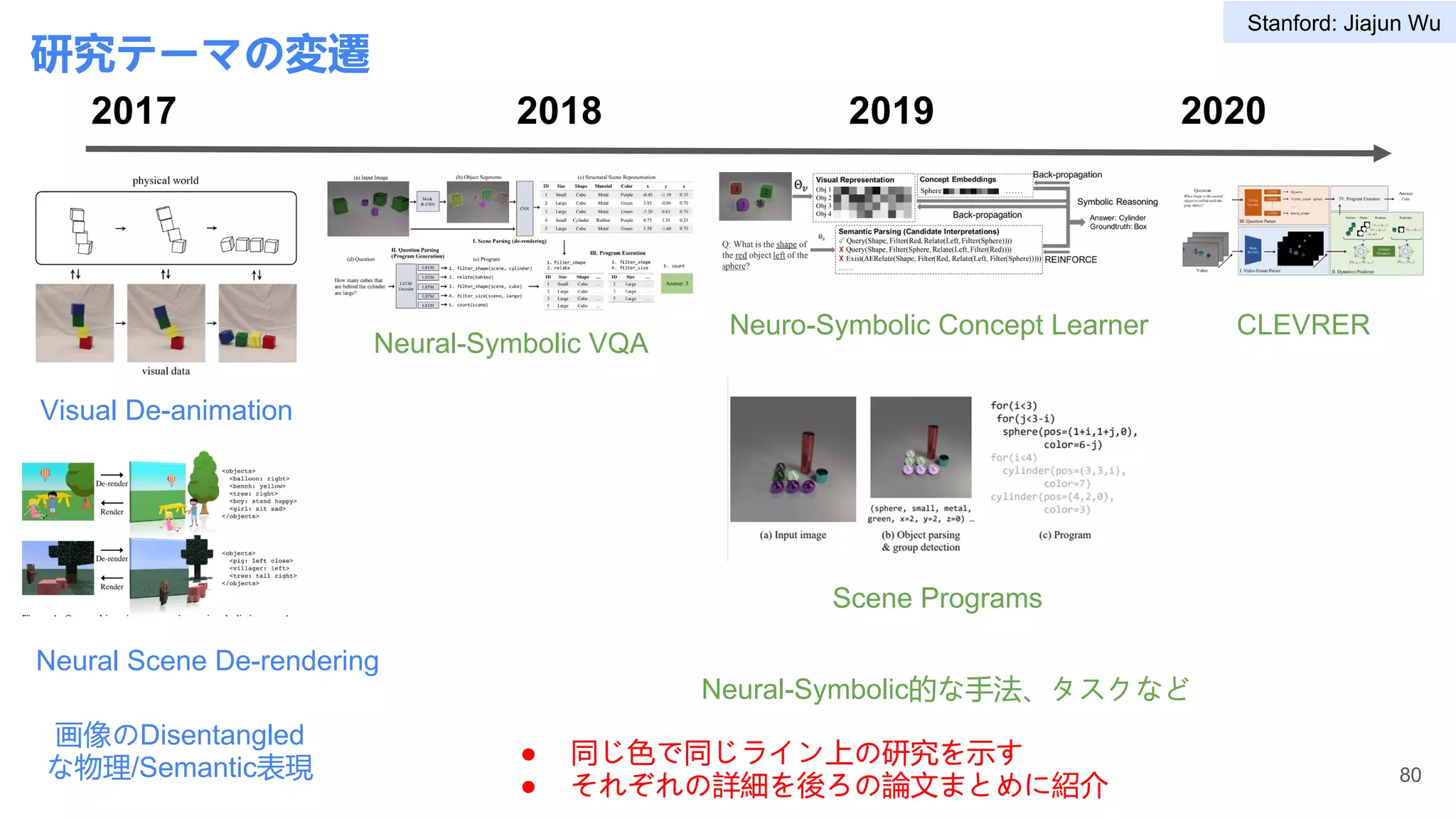
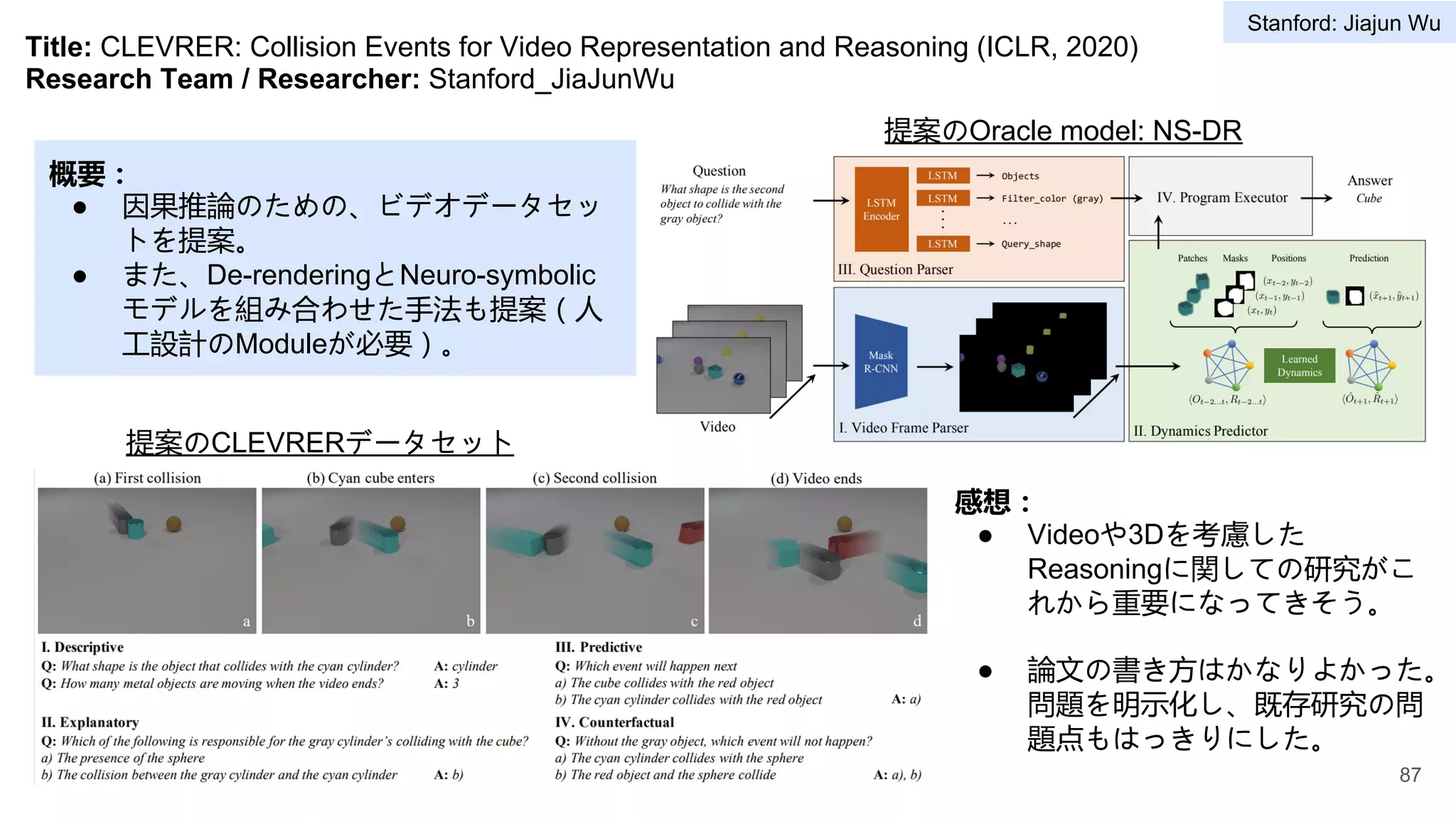
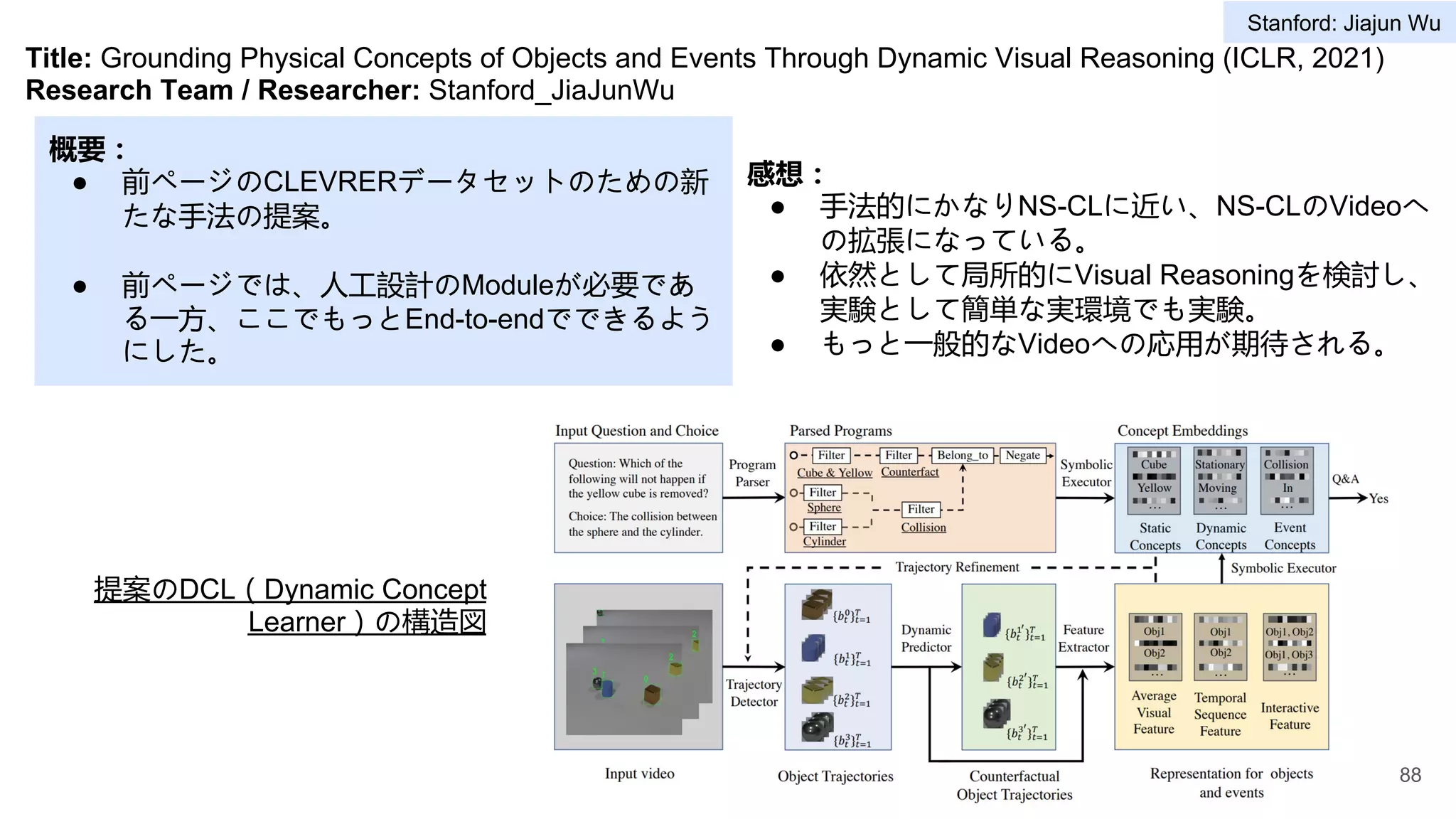
4 Stanford vision and learning lab Jiajun Wu 78-90
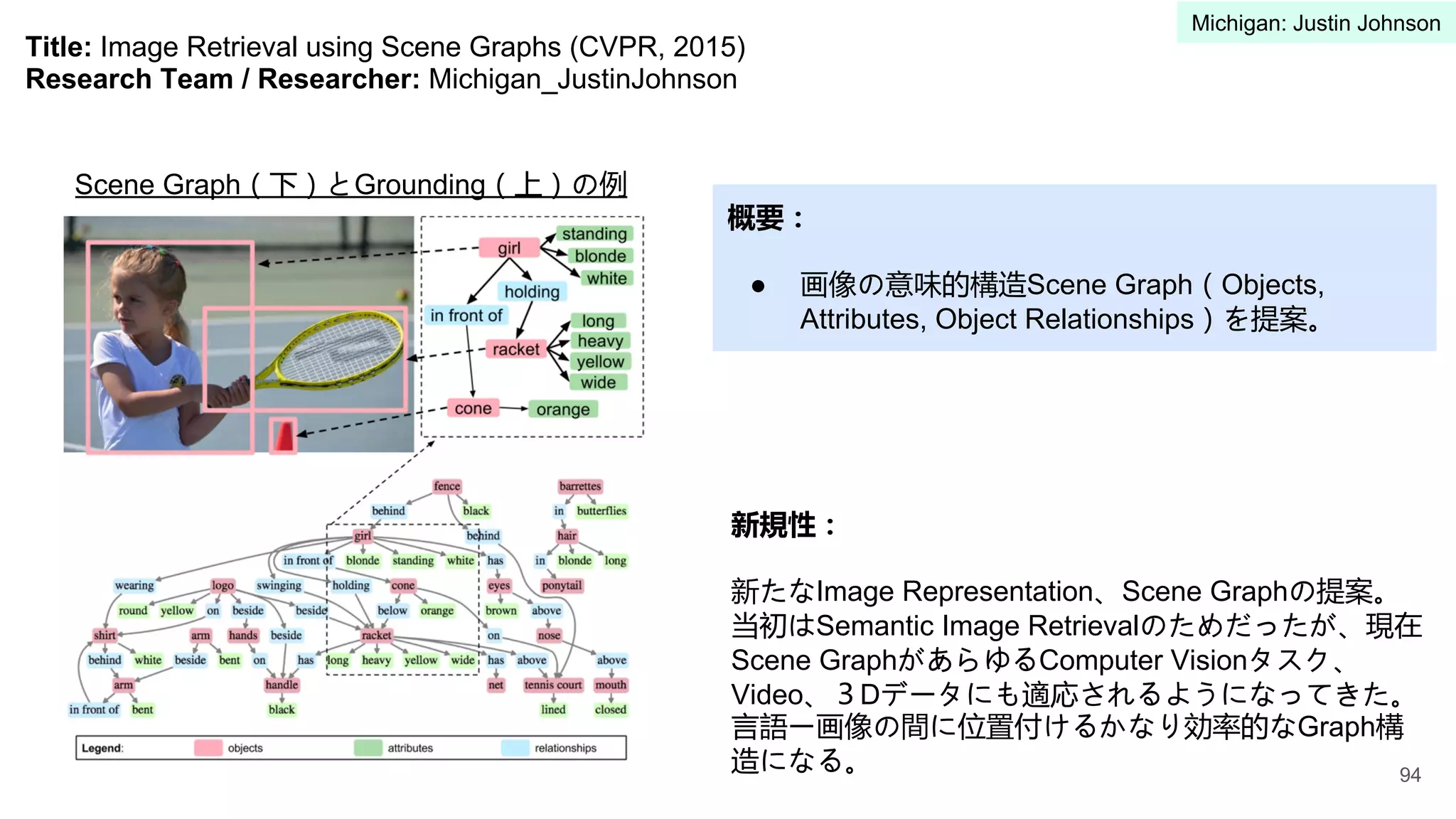
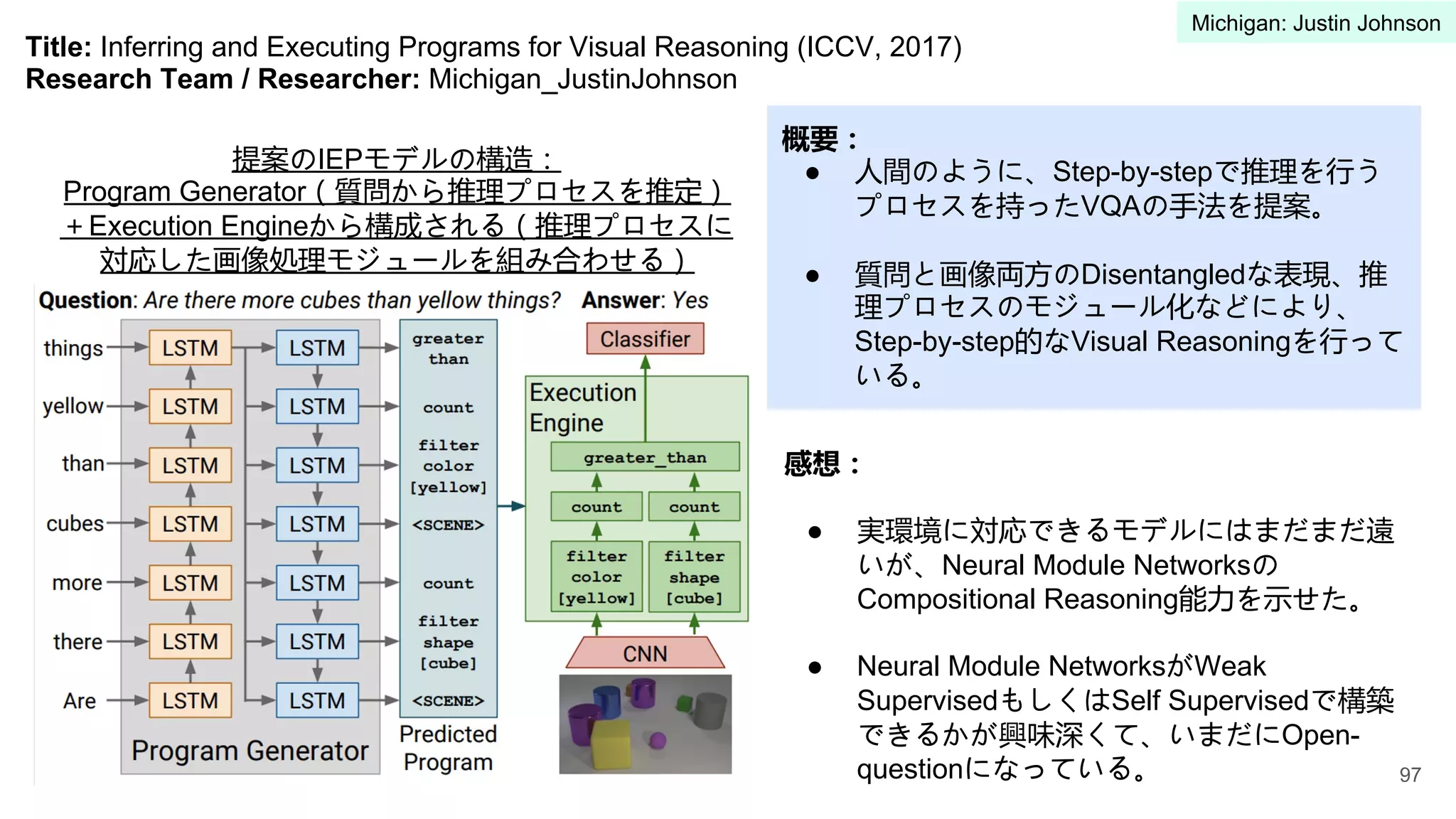
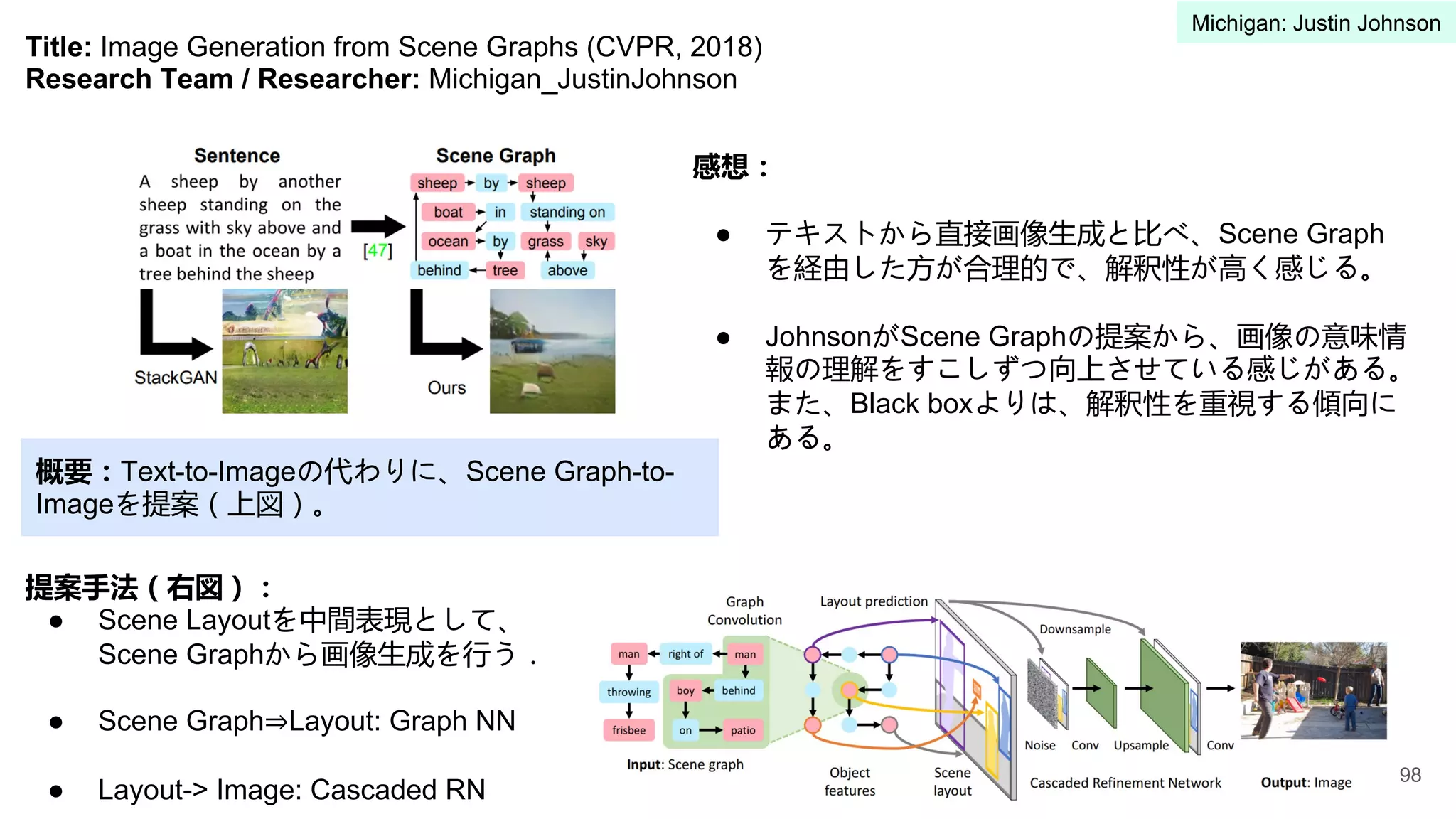
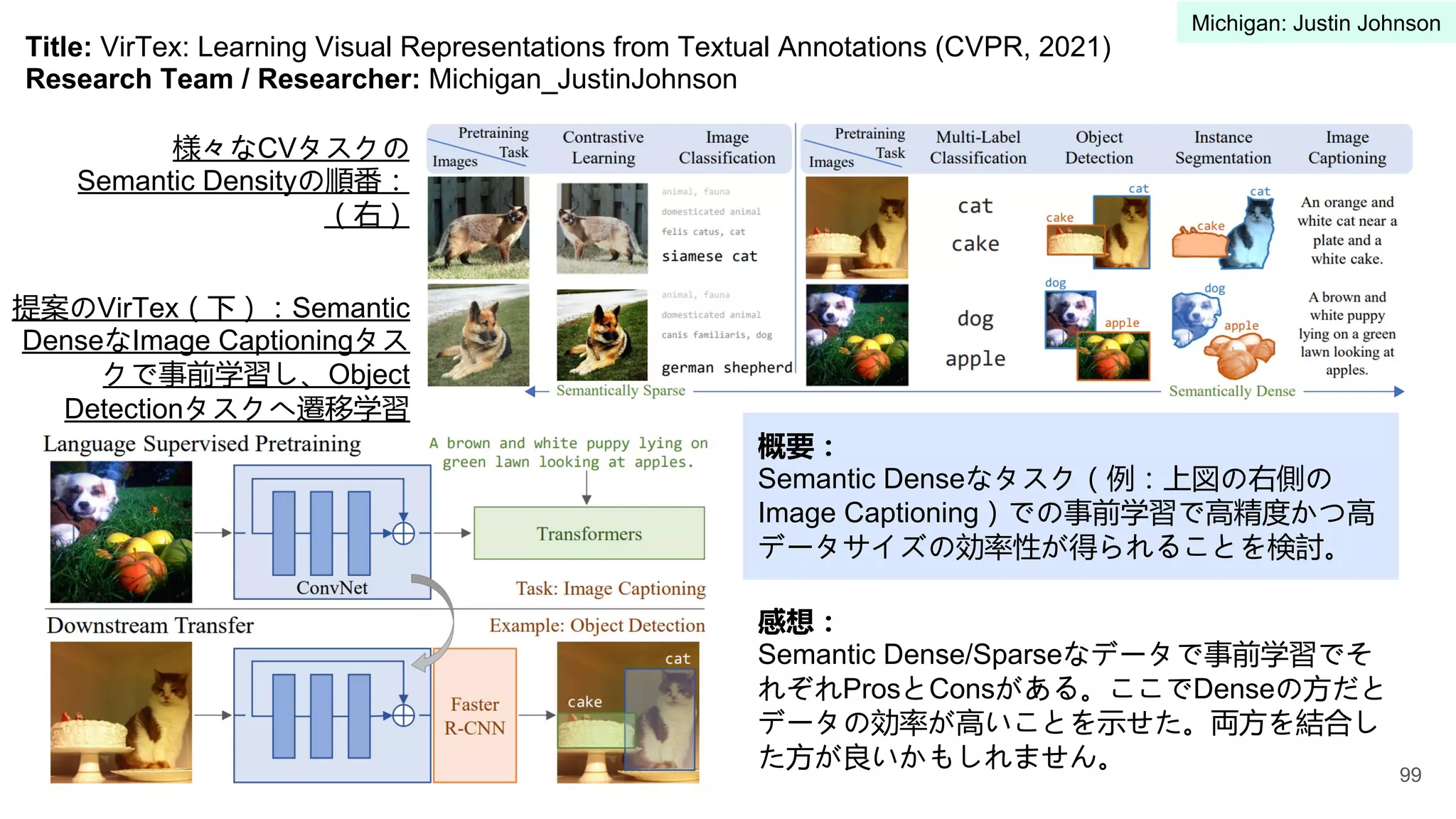
5 University of Michigan Justin Johnson 91-100
6 University of Michigan Honglak Lee 101-140
7 Google Peter Anderson 141-149
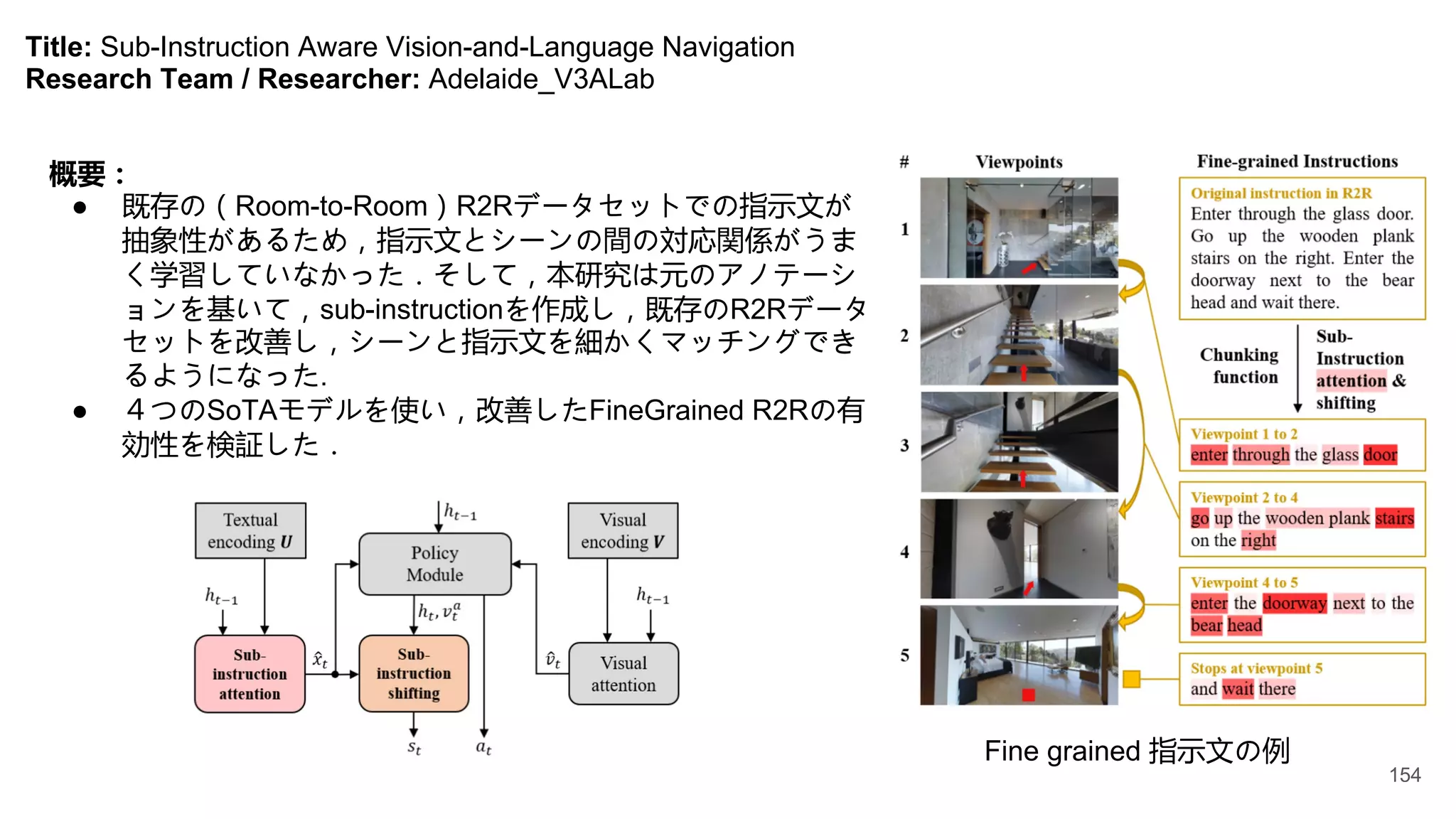
8 University of Adelaide V3Alab Qi Wu 150-154
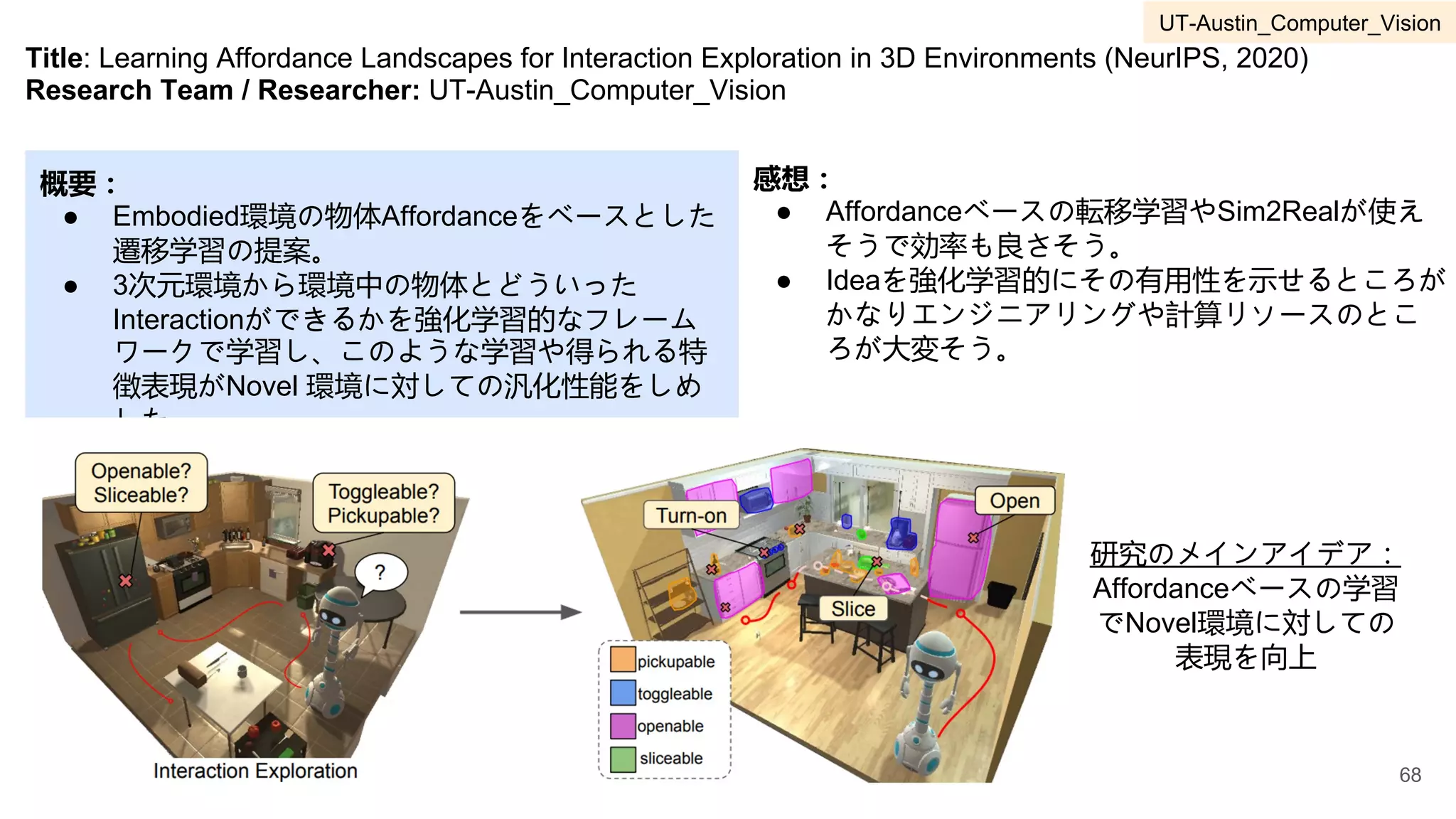
3
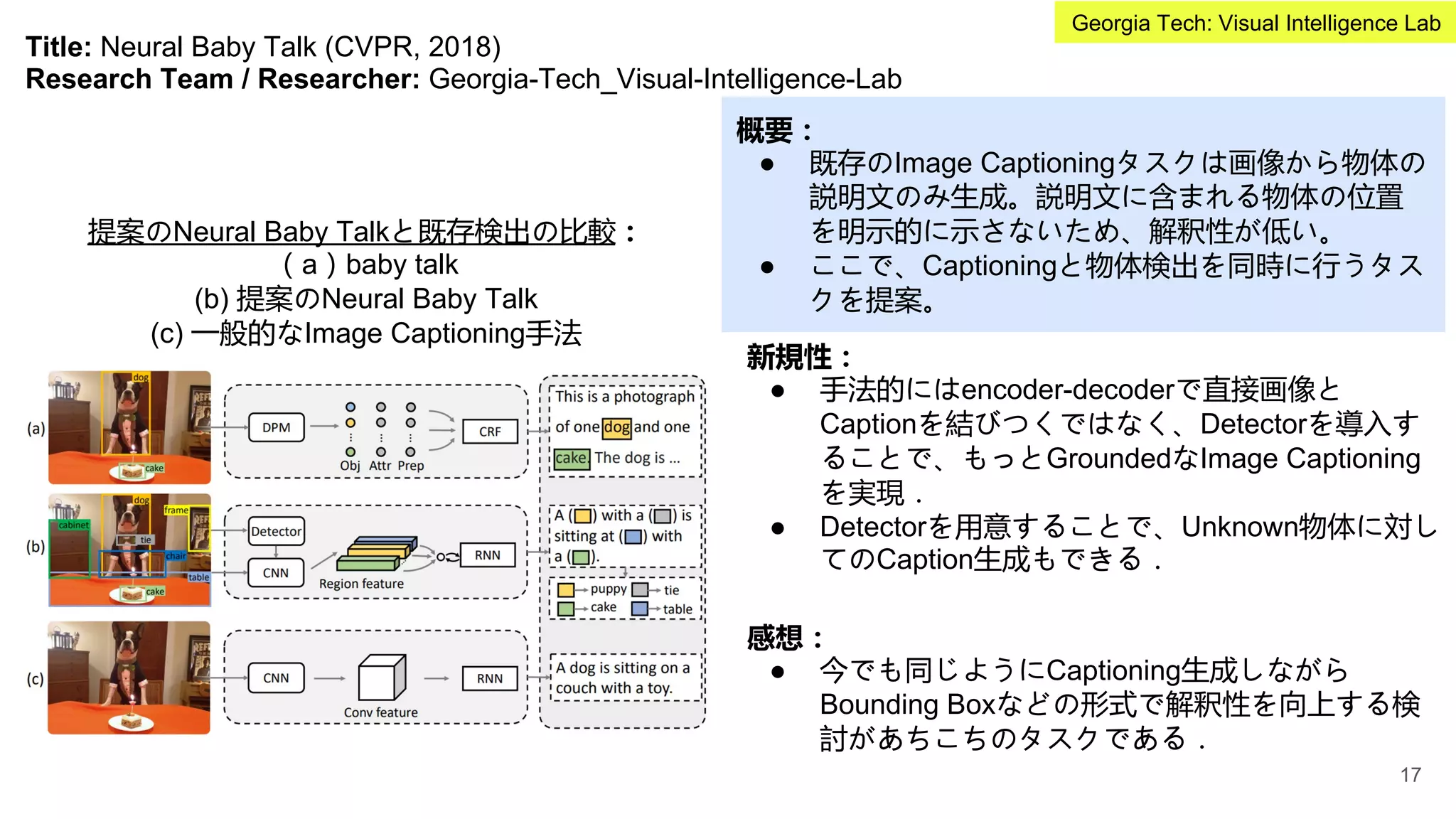
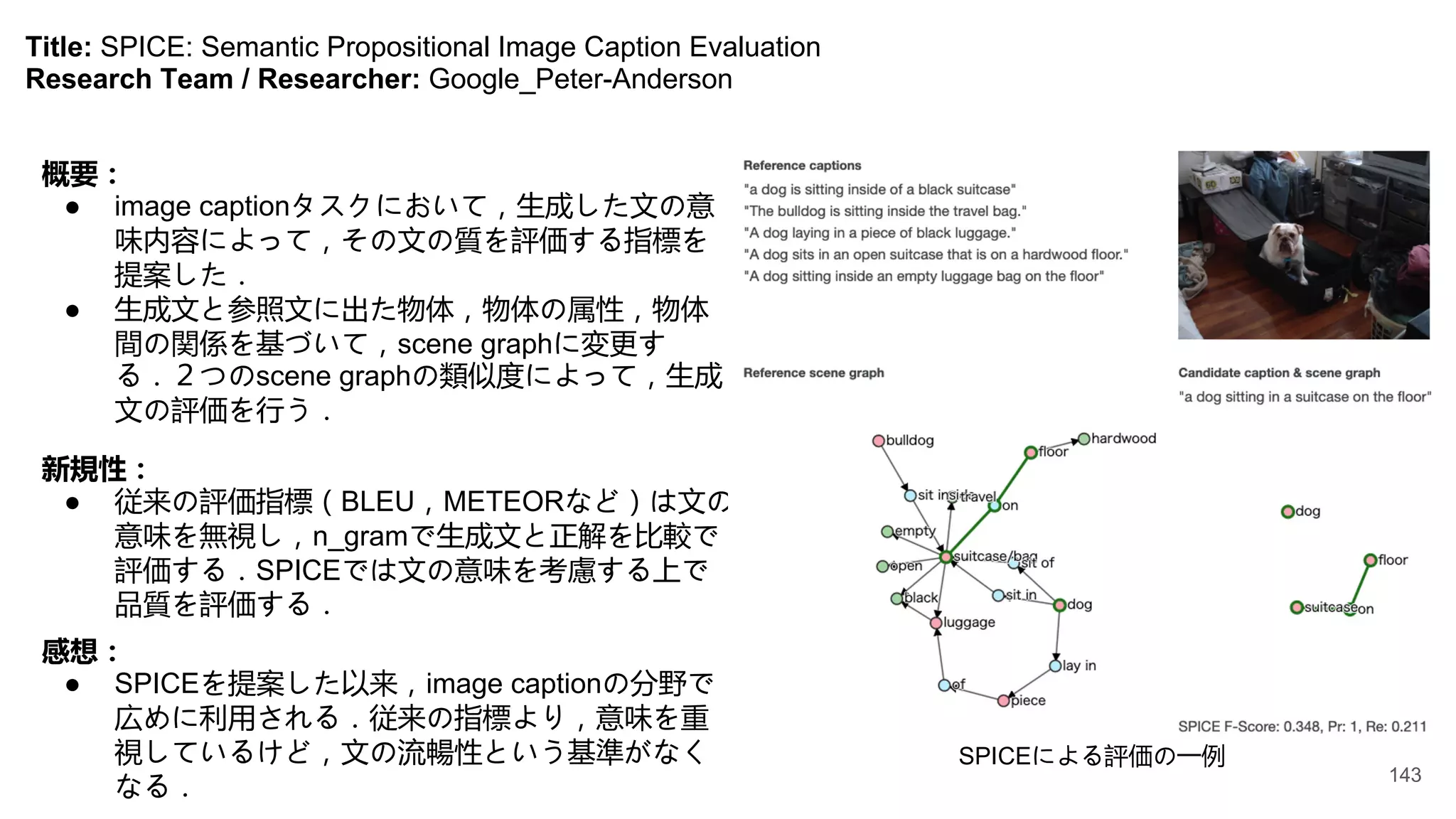
Title: ViLBERT: PretrainingTask-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks
(NeurIPS, 2019)
Research Team / Researcher: Georgia-Tech_Visual-Intelligence-Lab
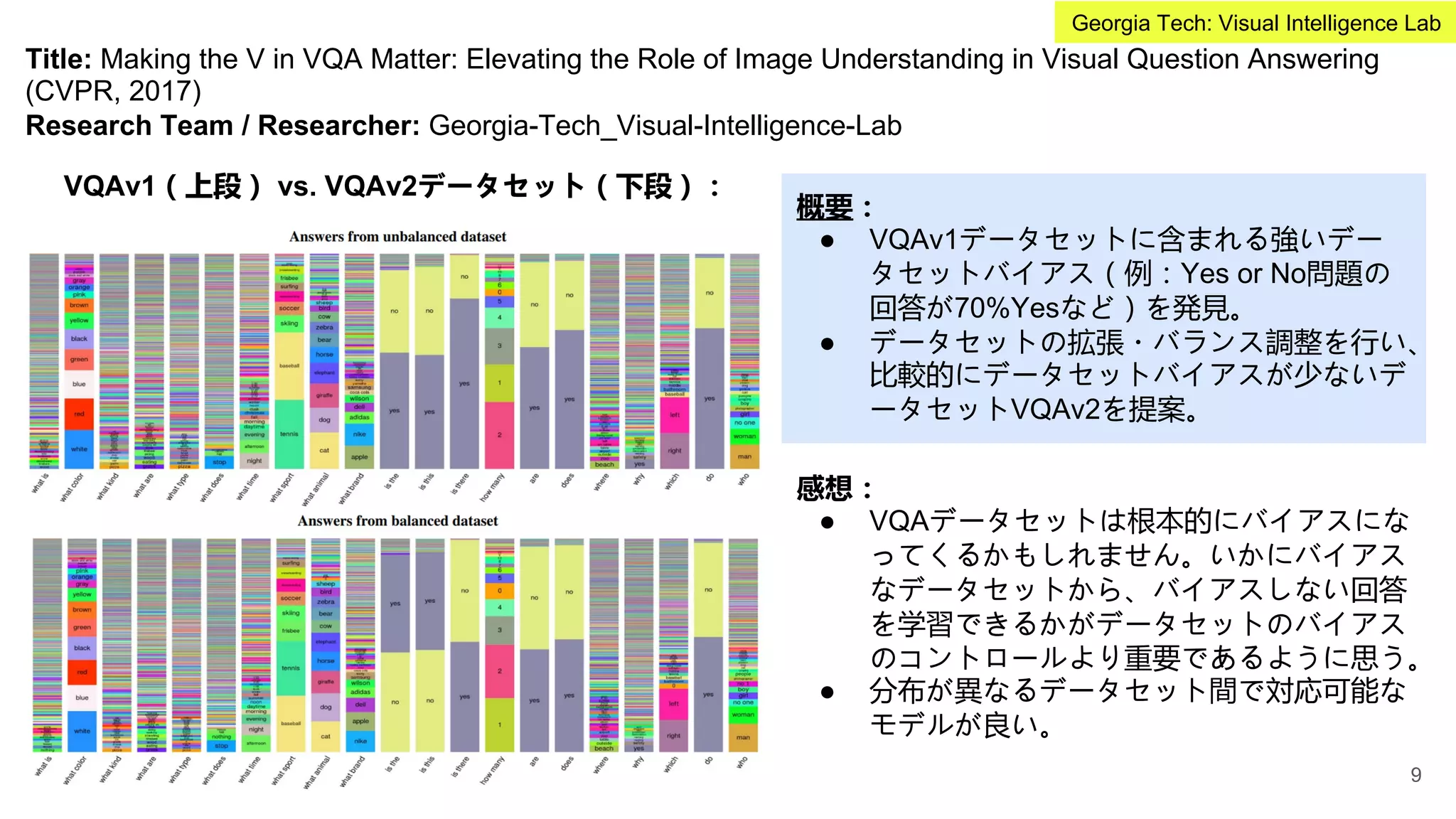
概要:
● Vision and Language系の研究で特にデータ
セットの作成のコストが高い問題がある。
● Vision and anguage タスクにおいて大規模
事前学習、タスク間の遷移学習を可能にす
るため、統一したモデルで複数のVision and
Languageタスクを学習可能なフレームワー
クを提案(ViLBERT)。
感想:
● BERTの成功をVandLに適応する試み。考えるだけ
ではなく、他の人より早い段階でRoadmapを構想
し、いち早く最新で使えそうな技術を導入すること
が重要。
● ViLBERTで提案する時点ですでにPaperid11の
12in1のマルチタスク同時学習を想定していたそう。
ViLBERTで行っている2種類のMulti-modal learning:左(ラベル推定まで);右(一致性の評価のみ)
20
Georgia Tech: Visual Intelligence Lab
21.
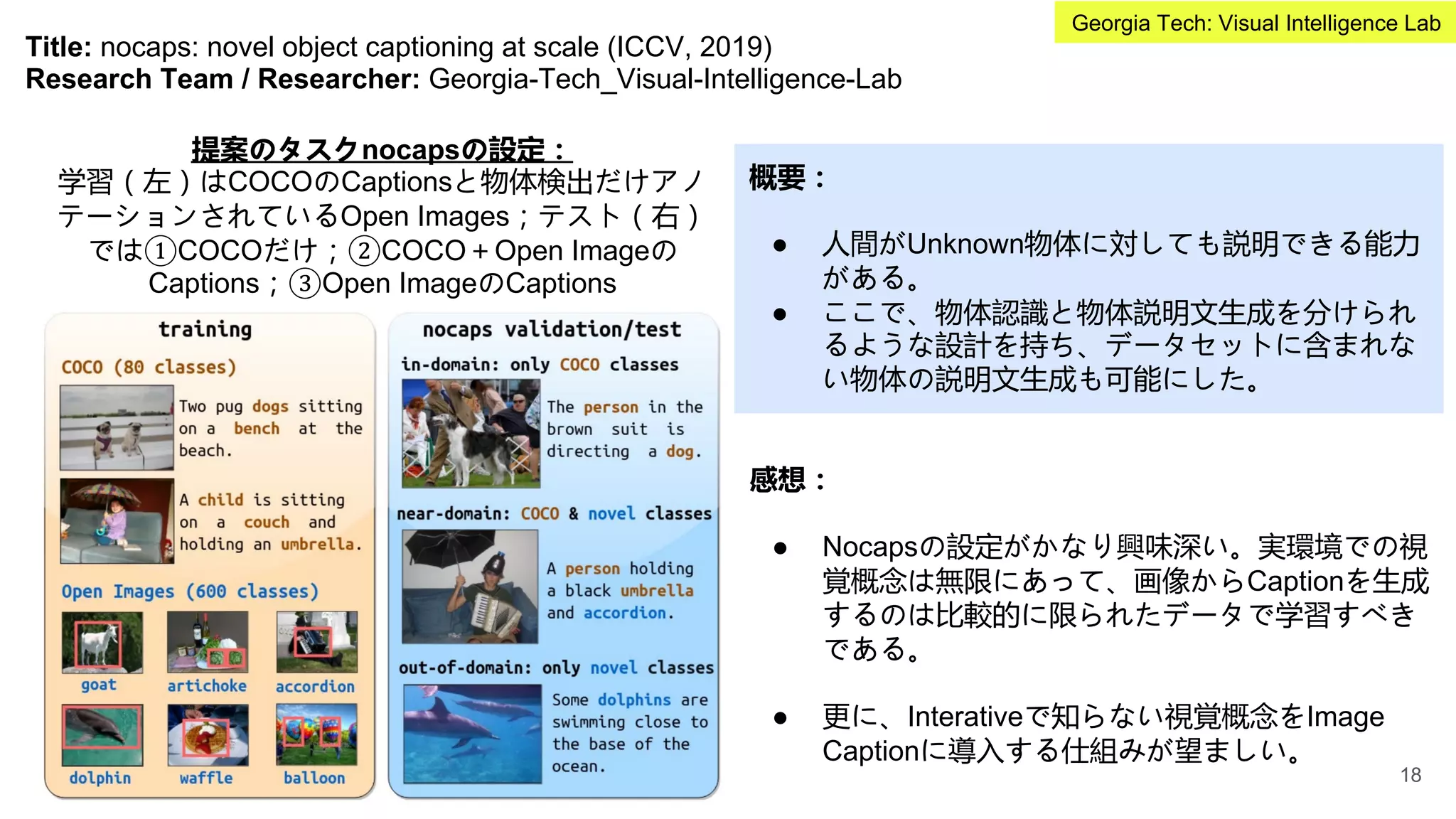
Title: 12-in-1: Multi-TaskVision and Language Representation Learning (NeurIPS, 2019)
Research Team / Researcher: Georgia-Tech_Visual-Intelligence-Lab
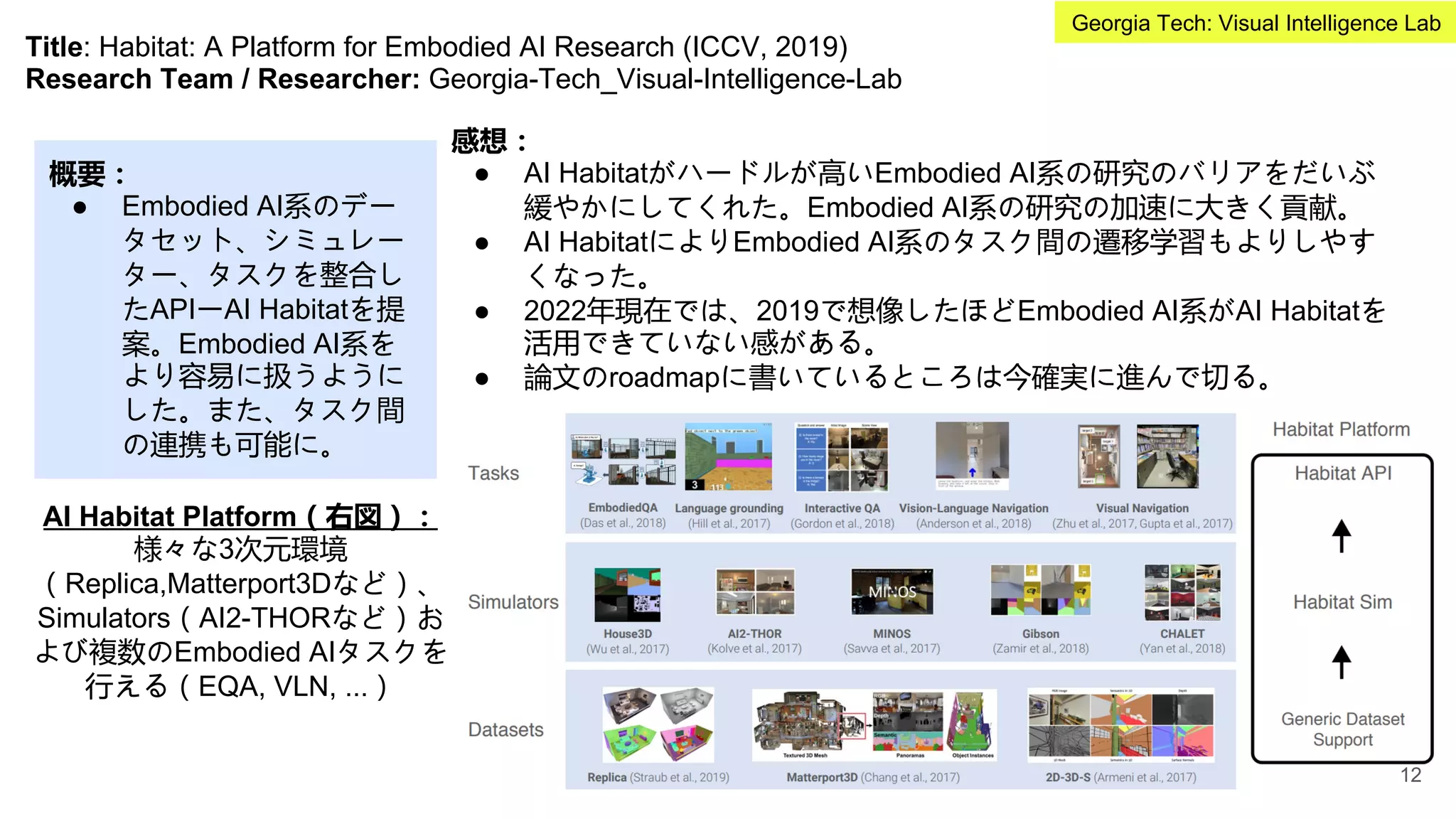
概要:
● ViLBERTをベースに、更に複数のVision and
Languageタスク間の遷移学習の効果を検証。
感想:
● ViLBERTをベースに、マルチタスク・データセ
ットにおいて分析を行た感じ。Communityに対
して貢献度が高いが、新規性がすこし薄れる部
分もある。
● VandL研究の理由:”promise of language as a
universal and natural interface for visual
reasoning”;なかなかうまくまとめている。
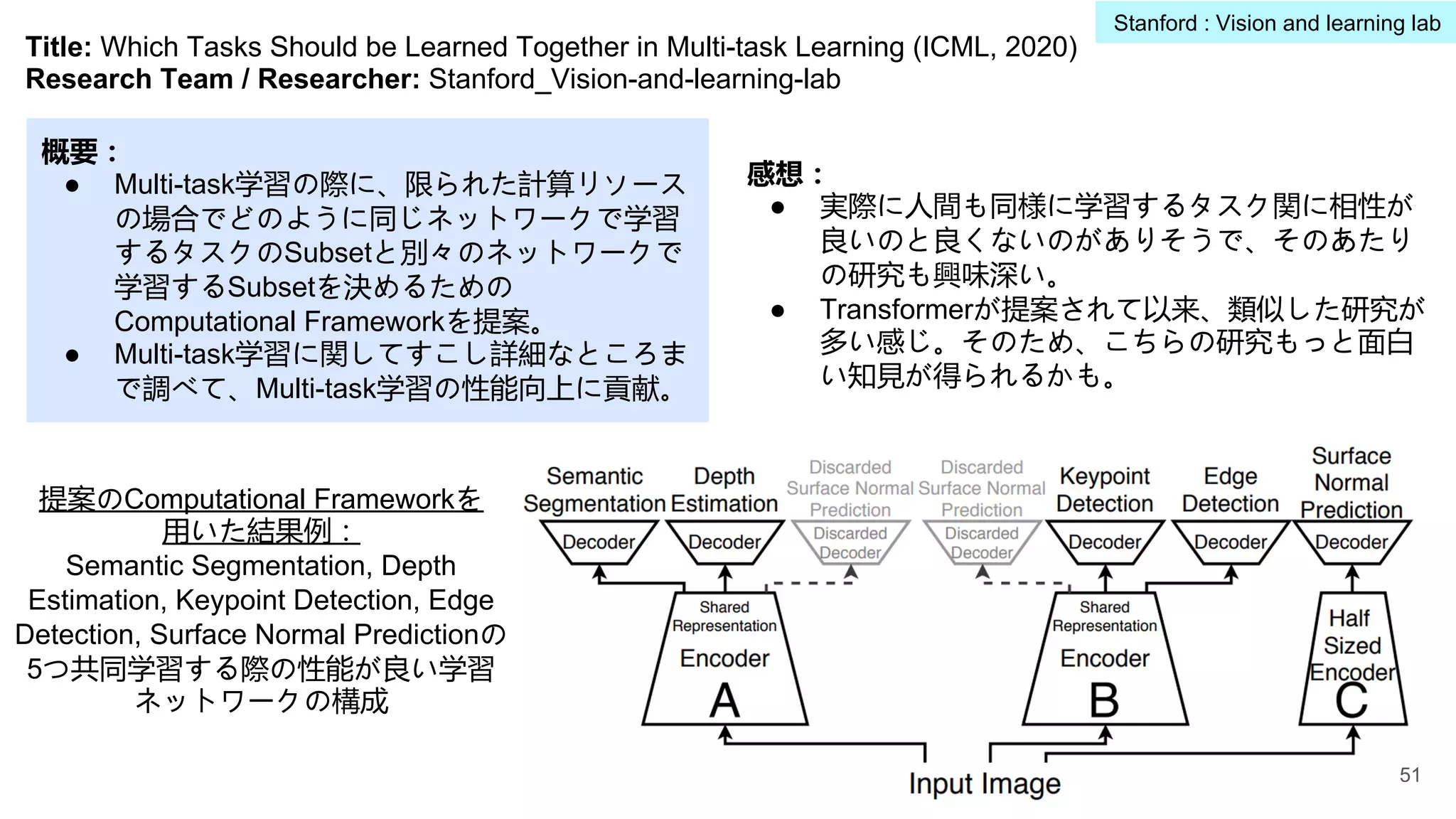
提案のマルチVandLタスク共同で学習する仕組み
21
Georgia Tech: Visual Intelligence Lab
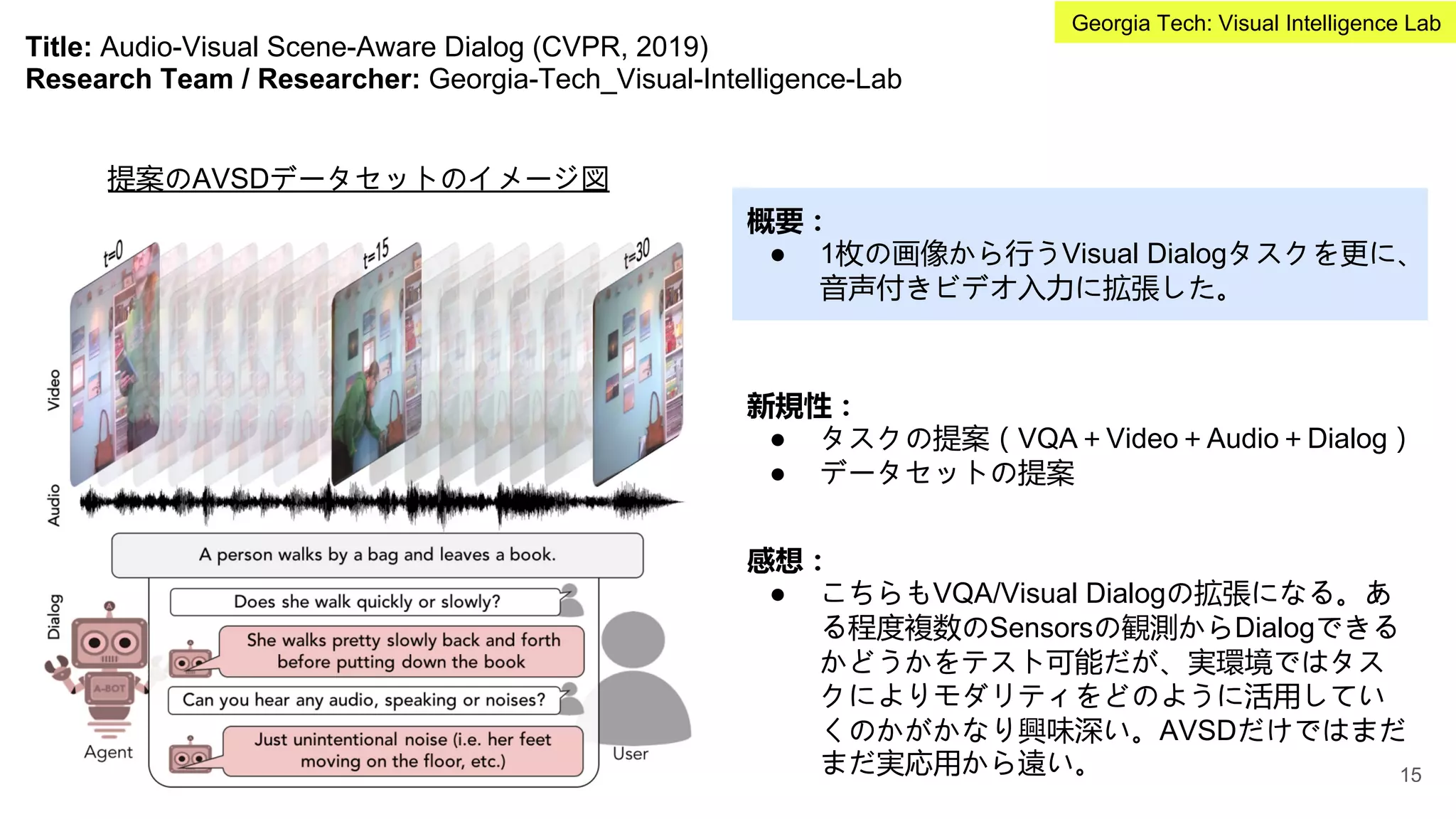
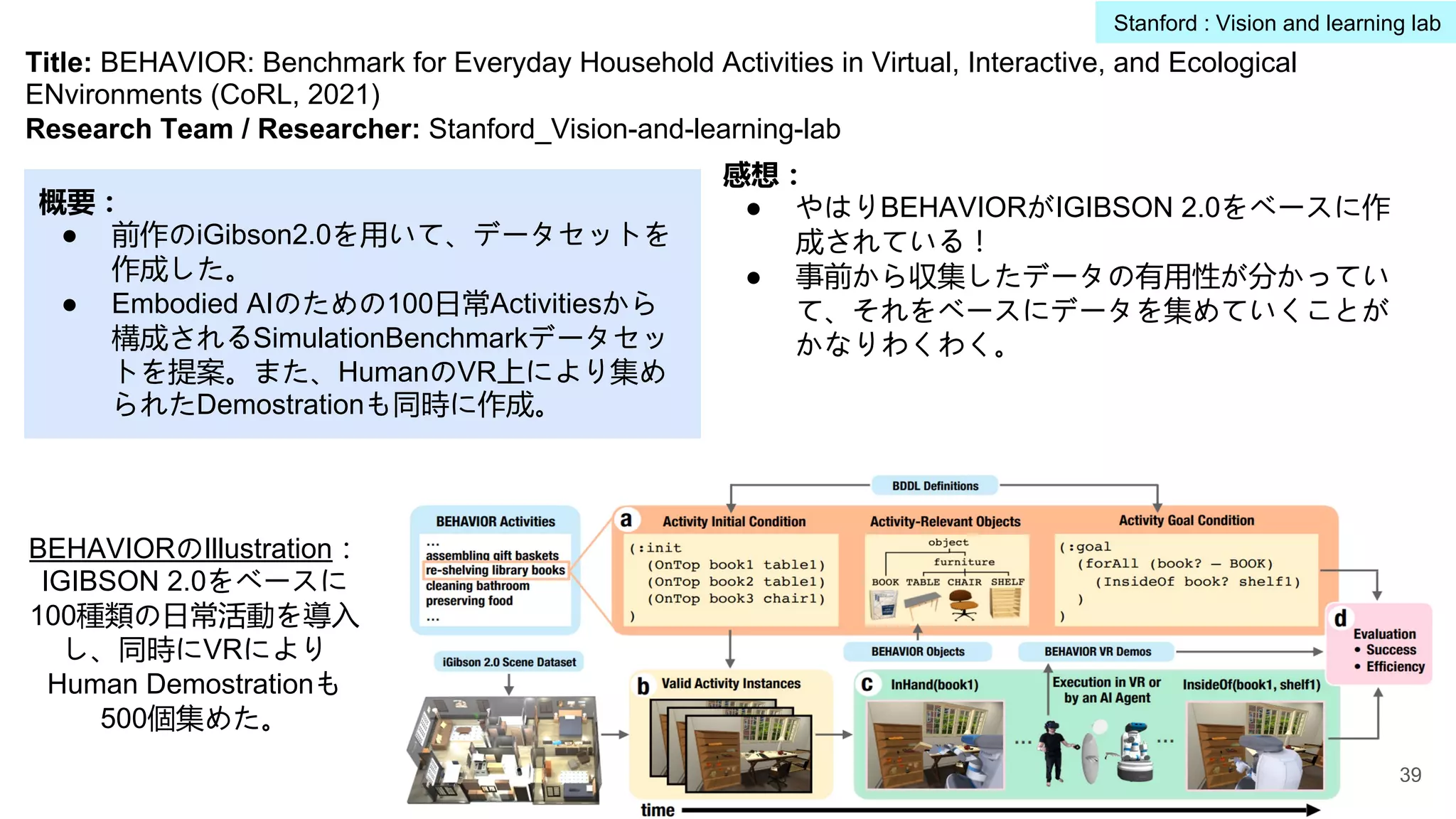
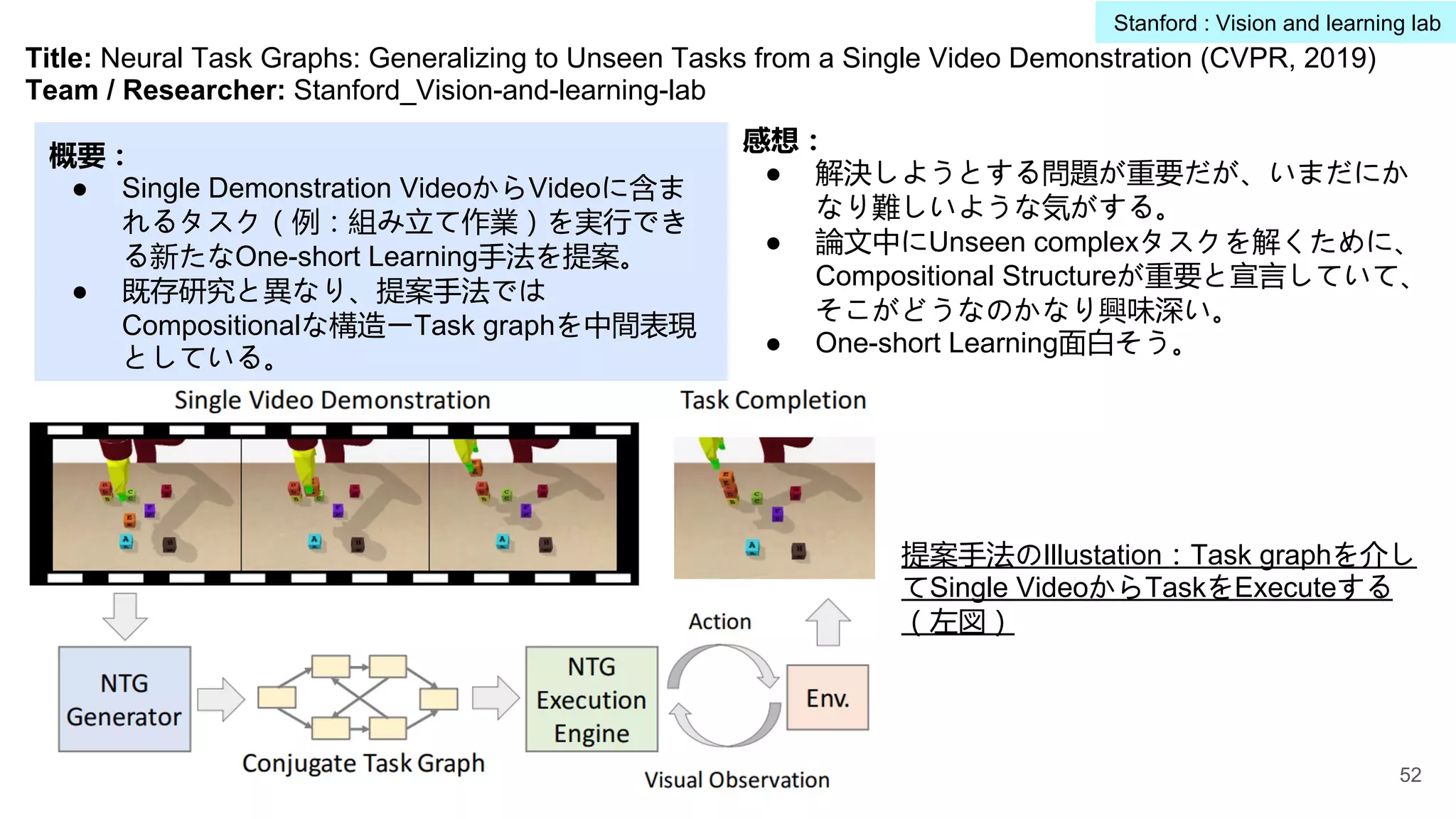
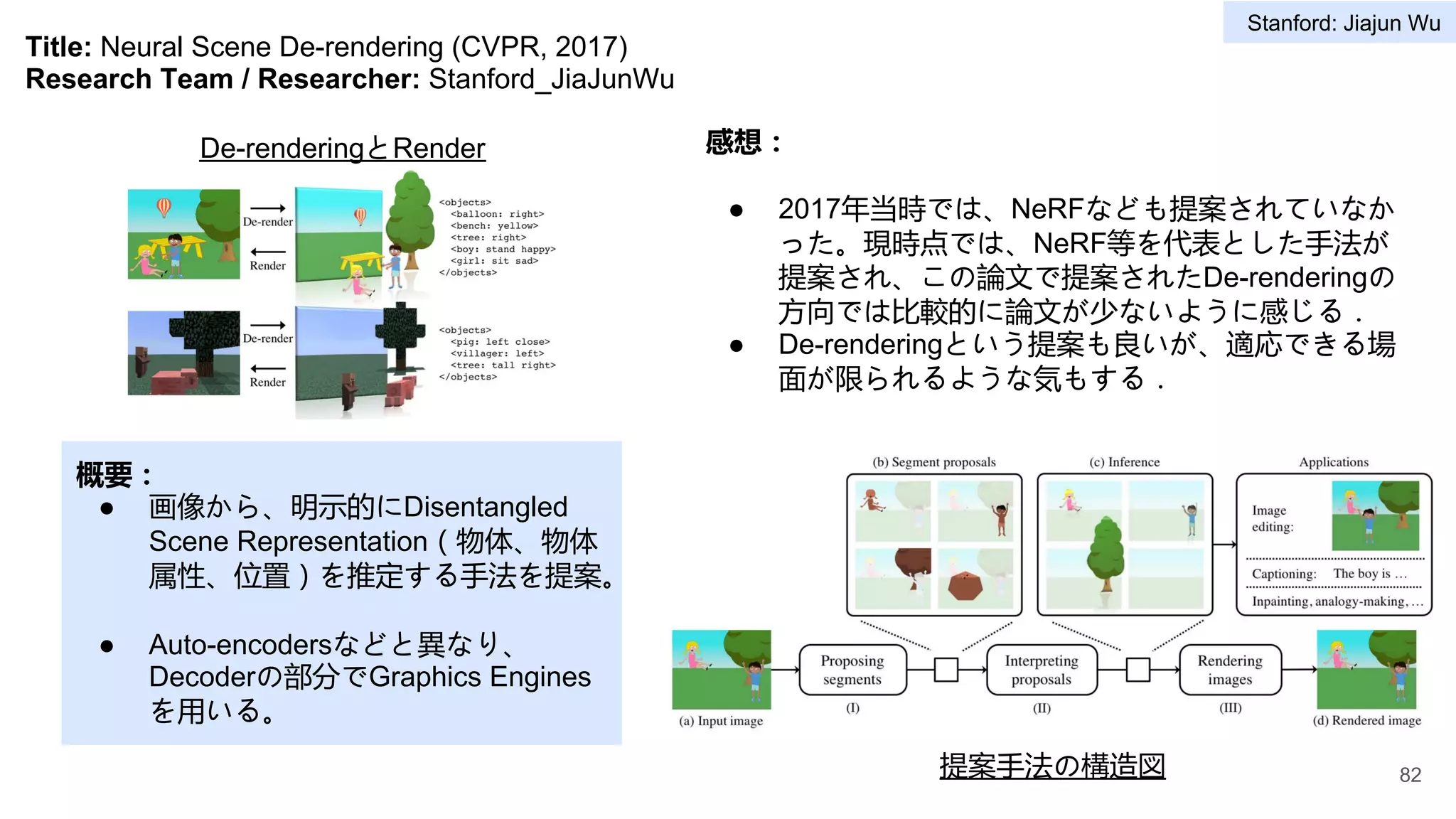
Title: Visual Genome:Connecting Language and Vision Using Crowdsourced Dense Image Annotations (IJCV,
2017)
Research Team / Researcher: Stanford_Vision-and-learning-lab
概要:
● ImageNetでは主に1画像1物体ラベルから構成。
ここで、1画像とその画像の意味的構造
(Scene Graph:物体、物体間の関係ラベ
ル)をアノテーション付けたデータセット
Visual Genomeを提案。
感想:
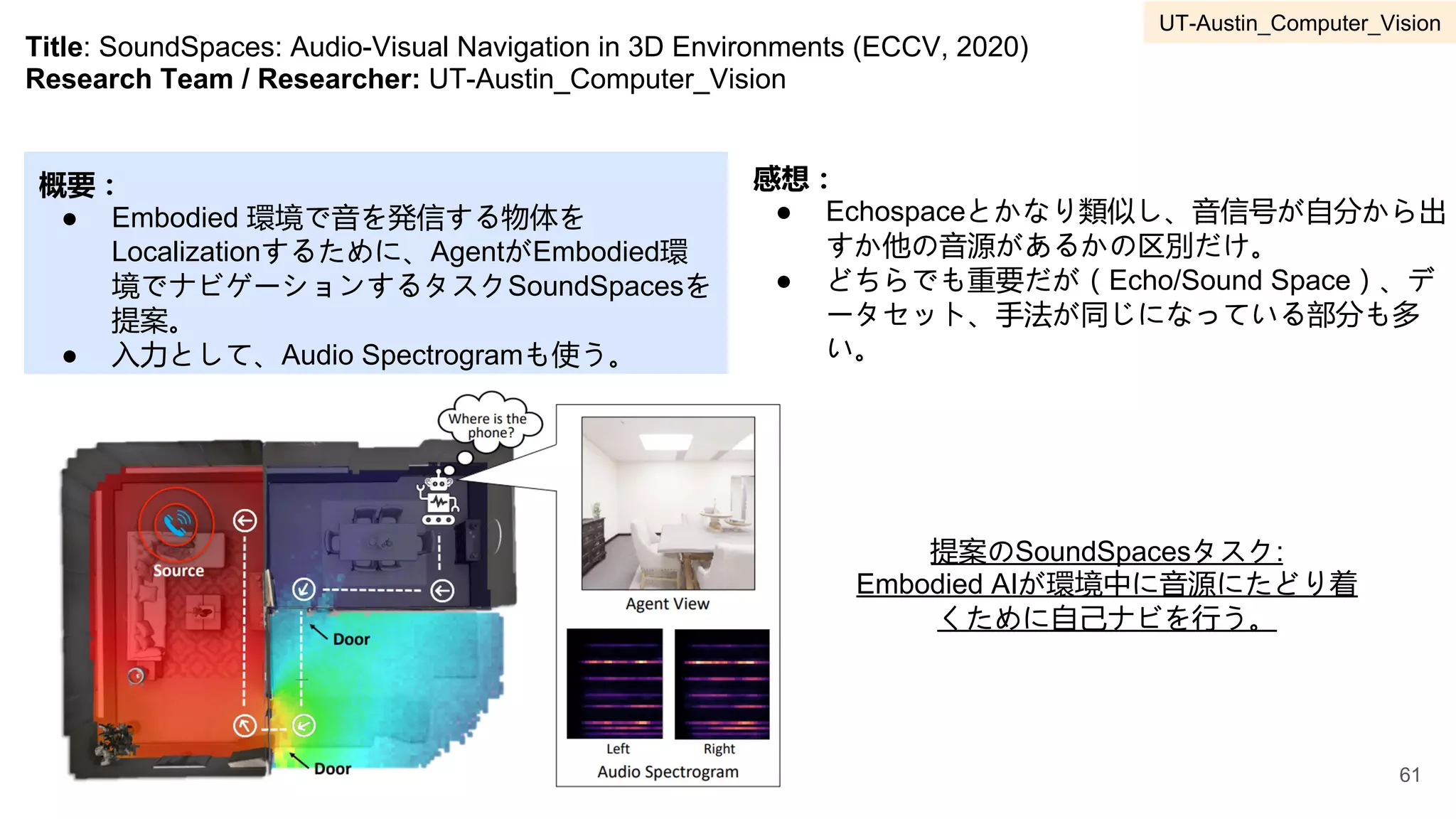
● Visual Genomeが大量な作成コストが必要となり、
分野の成長に大きく貢献できている。
● Visual Genomeデータセットがかなり大規模であ
り、現時点でもChallenge的で、様々なDown
streamタスクで活用できそう。
VisualGenome
データセット例
28
Stanford : Vision and learning lab
29.
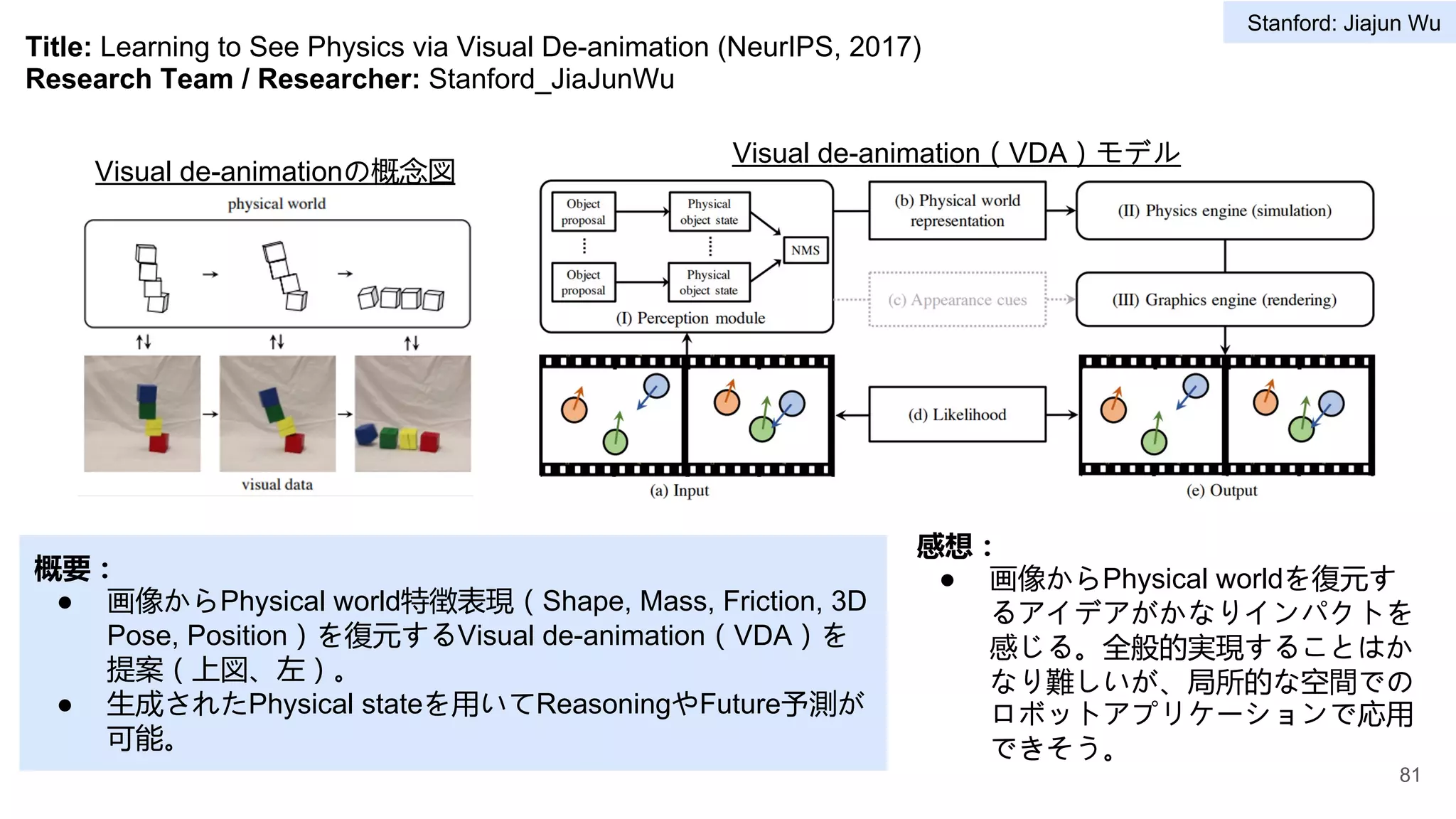
Title: Learning PhysicalGraph Representations from Visual Scenes (NeurIPS, 2020)
Research Team / Researcher: Stanford_Vision-and-learning-lab
概要:
● Sceneに含まれる物体の階層構造(物体と物
体のパーツなど)および物理属性(Surface
Shape, Texture)も考慮したPhysical Scene
Graph構造を提案。
感想:
● 室内環境データセットにまで適応できていると
ころがすごい。物理に従っても大規模データセ
ットに活用できるところなので、物理ベース手
法のPromisingなところを示せた。
提案のPhysical Scene Graph
(PSG) representation
(左図)
29
Stanford : Vision and learning lab
30.
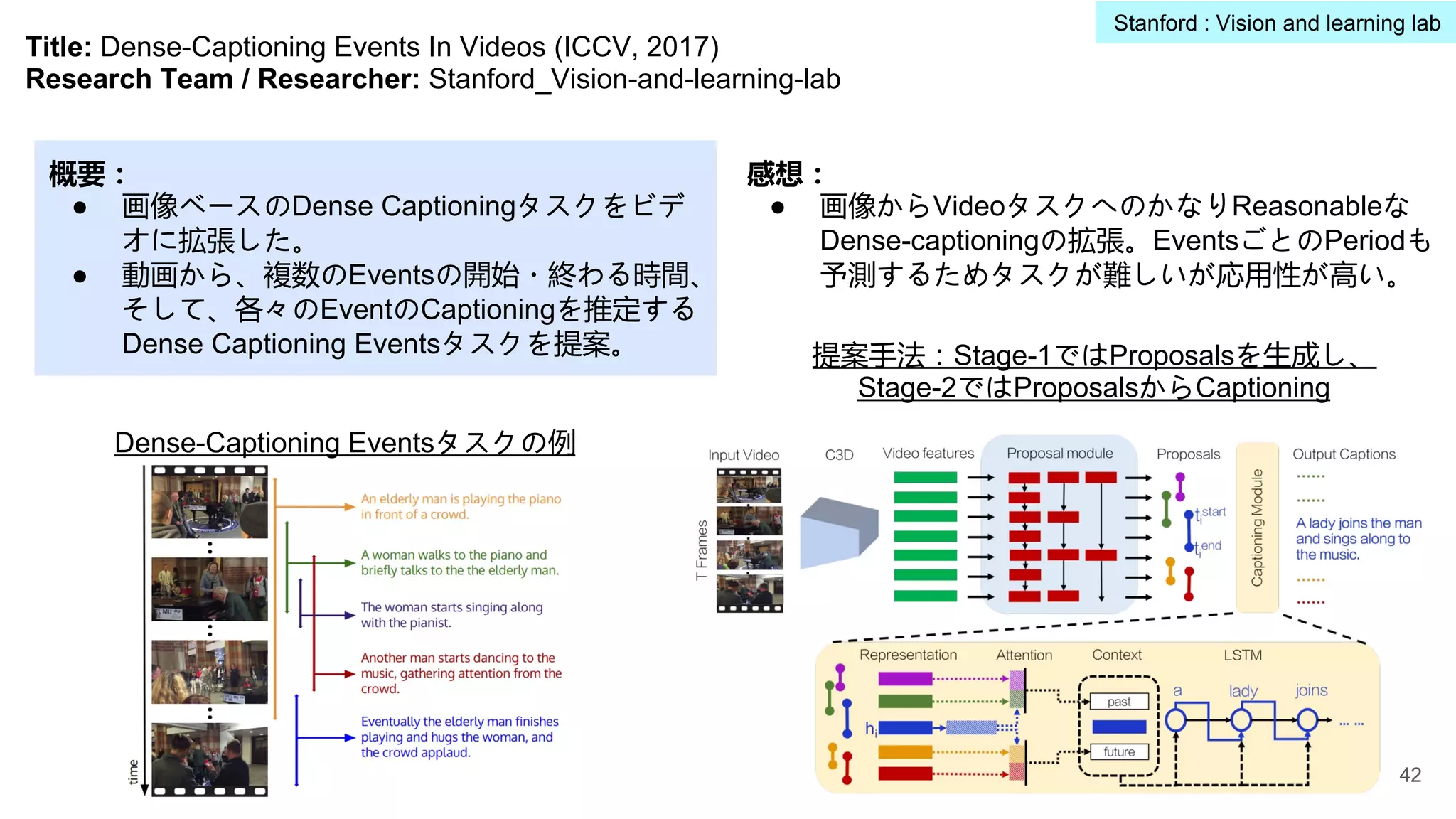
Title: ActivityNet: ALarge-scale Video Benchmark For Human Activity Understanding (CVPR, 2015)
Research Team / Researcher: Stanford_Vision-and-learning-lab
概要:
● これまでに動画像データセットでは1動画1
動画ラベルのような設定が多い。
● ここで、階層化された動作ラベルを付けた大
規模データセットActivityNetを提案。
感想:
● 論文で”Semantic Ontology”という言葉を使って
いる。Classic AIのOntologyとDeepLearningをい
かにうまく組み合わせられるかに関してかなり
工夫していそう。
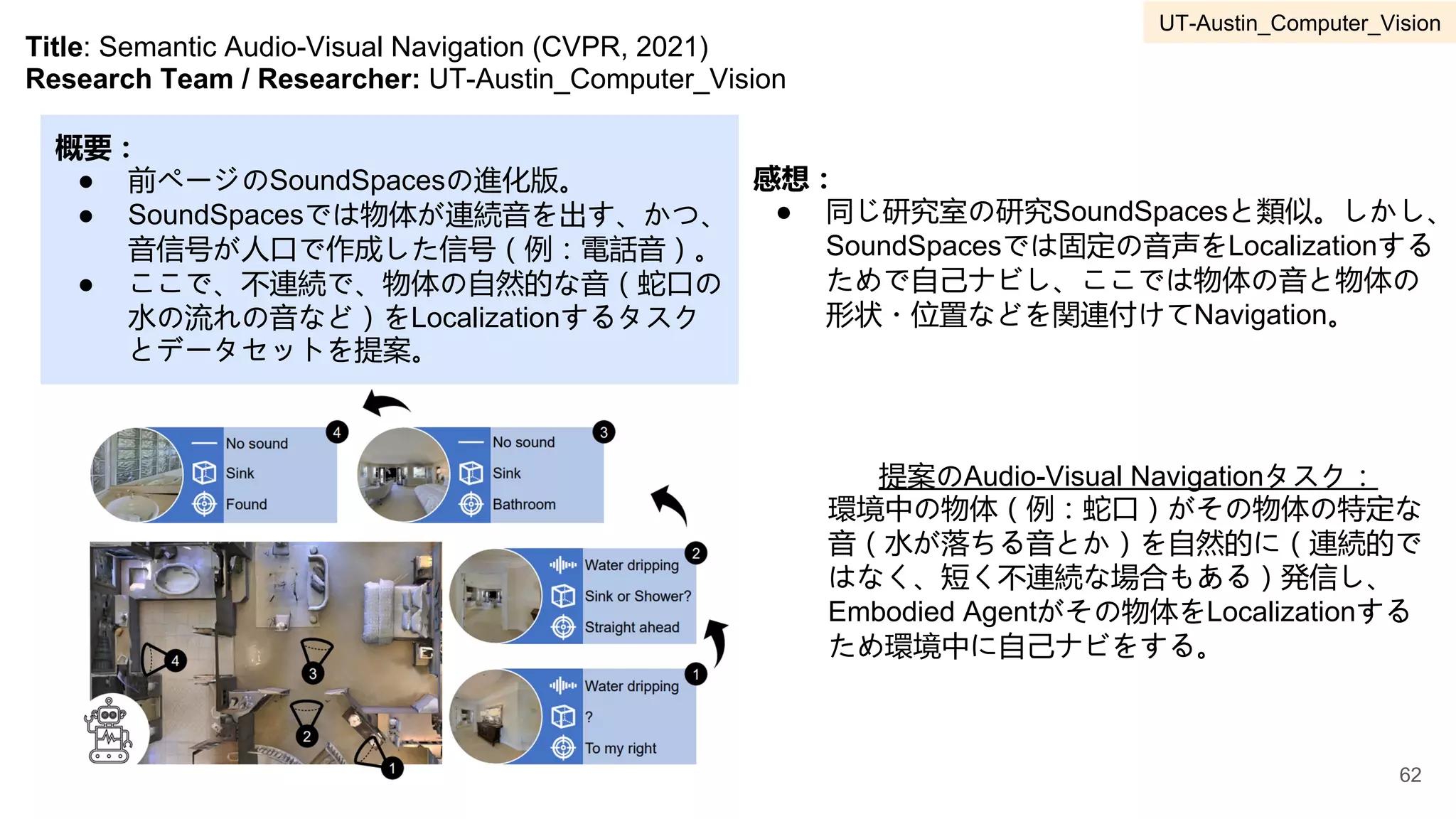
ActivityNetに含まれる2つ
の例(右図):
動作がTree状のSemantic
Levelsに従ってアノテーシ
ョンされている
30
Stanford : Vision and learning lab
31.
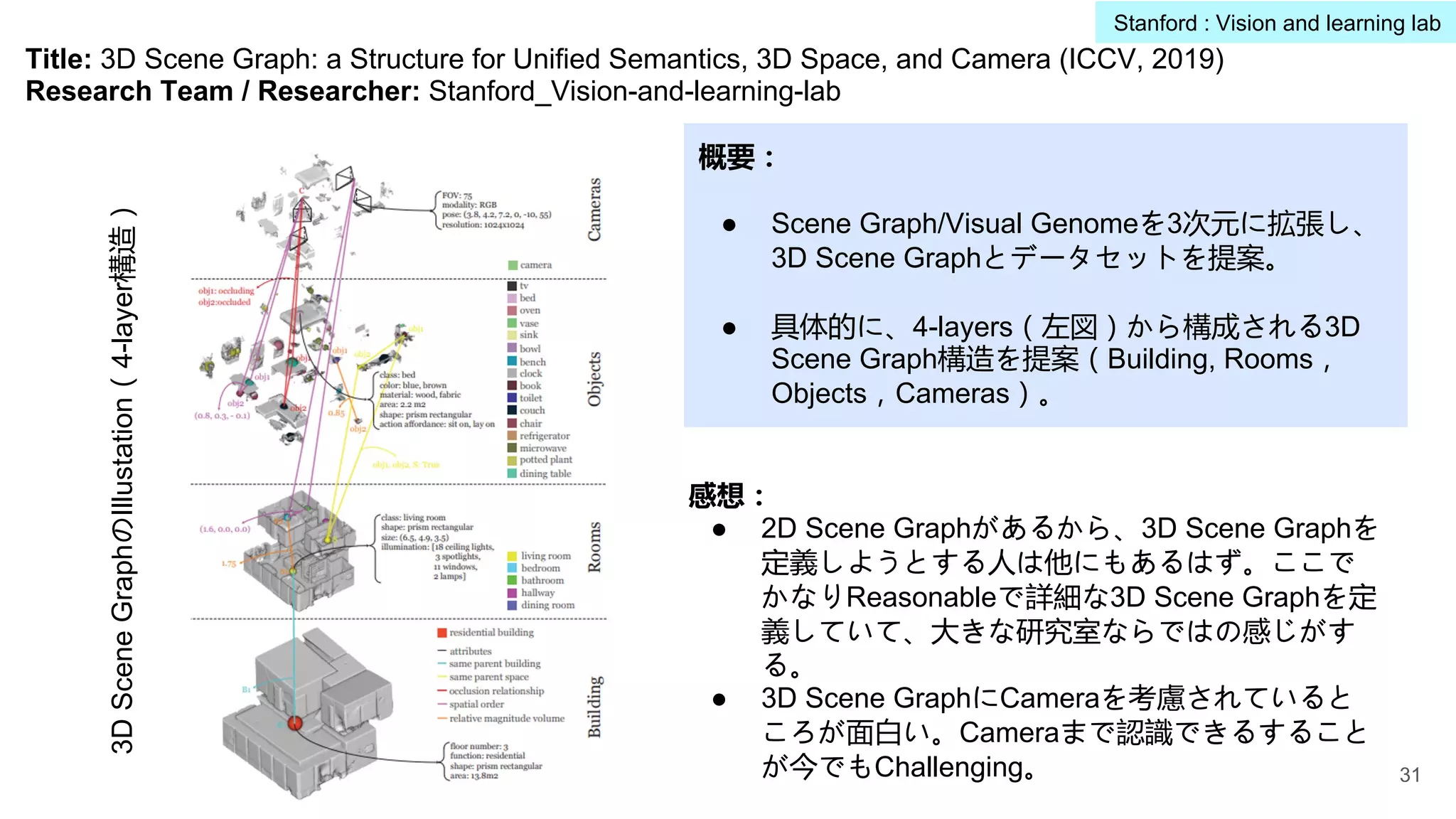
Title: 3D SceneGraph: a Structure for Unified Semantics, 3D Space, and Camera (ICCV, 2019)
Research Team / Researcher: Stanford_Vision-and-learning-lab
概要:
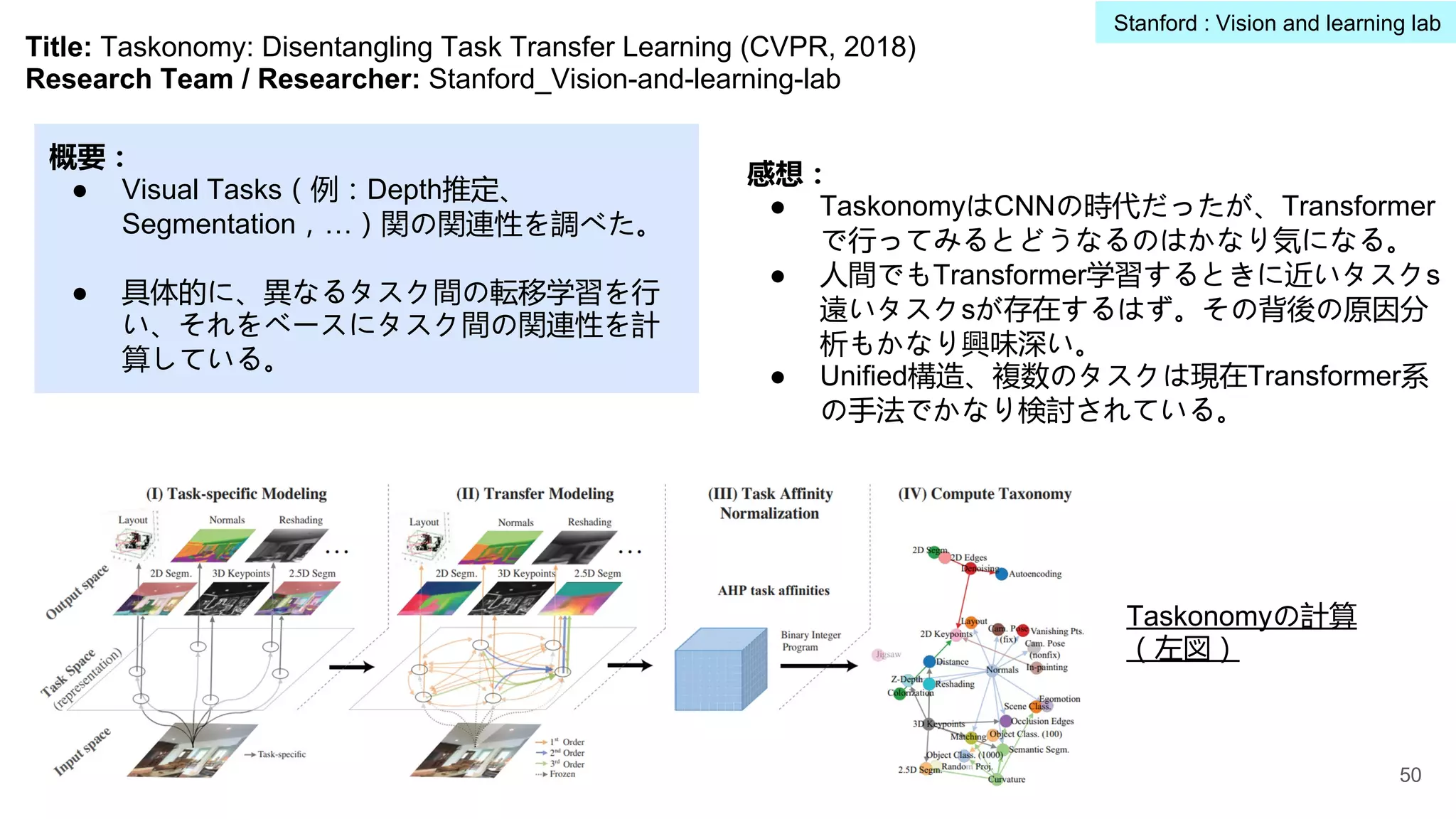
● Scene Graph/Visual Genomeを3次元に拡張し、
3D Scene Graphとデータセットを提案。
● 具体的に、4-layers(左図)から構成される3D
Scene Graph構造を提案(Building, Rooms,
Objects,Cameras)。
感想:
● 2D Scene Graphがあるから、3D Scene Graphを
定義しようとする人は他にもあるはず。ここで
かなりReasonableで詳細な3D Scene Graphを定
義していて、大きな研究室ならではの感じがす
る。
● 3D Scene GraphにCameraを考慮されていると
ころが面白い。Cameraまで認識できるすること
が今でもChallenging。
3D
Scene
GraphのIllustation(4-layer構造)
31
Stanford : Vision and learning lab
32.
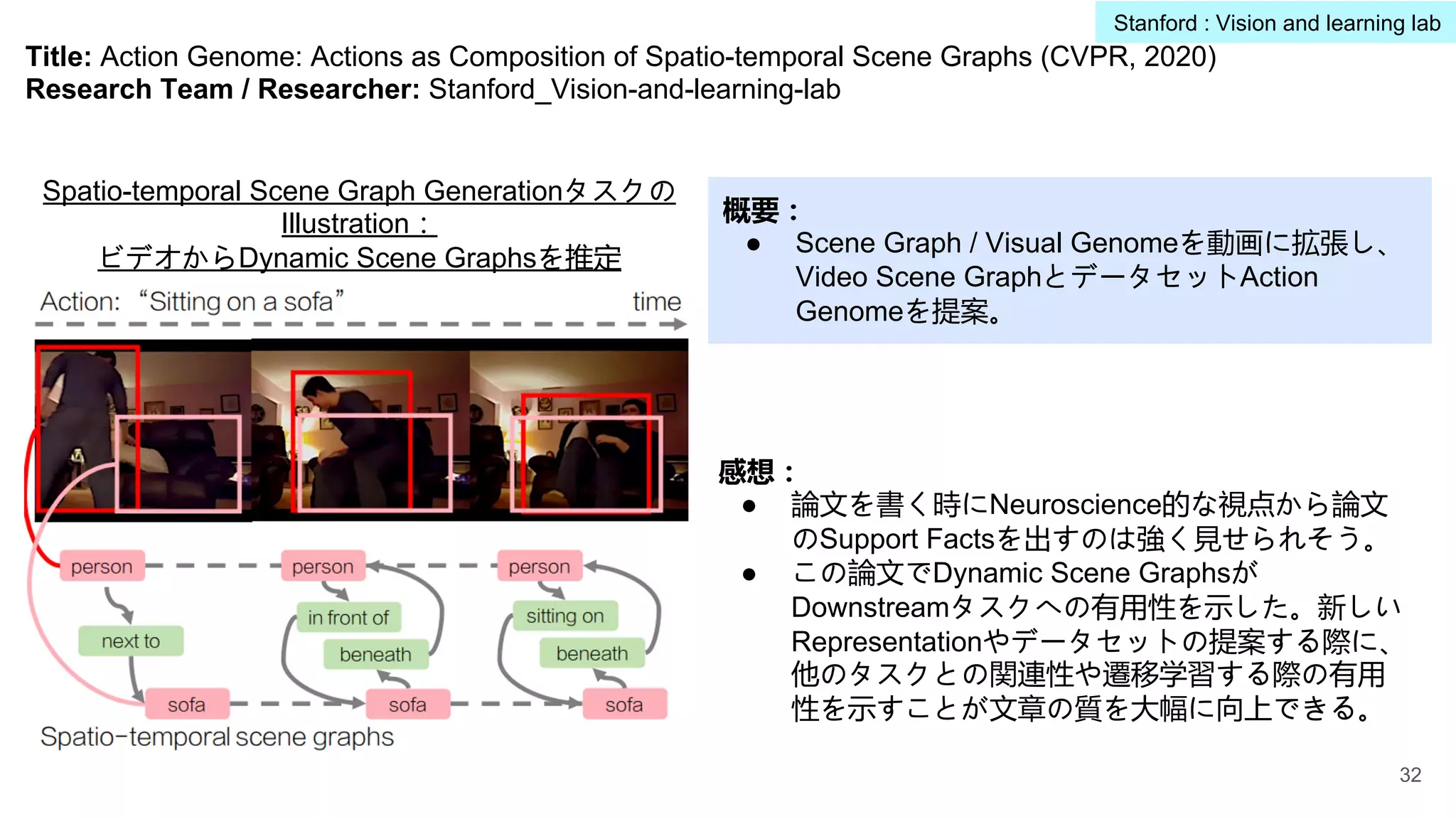
Title: Action Genome:Actions as Composition of Spatio-temporal Scene Graphs (CVPR, 2020)
Research Team / Researcher: Stanford_Vision-and-learning-lab
概要:
● Scene Graph / Visual Genomeを動画に拡張し、
Video Scene GraphとデータセットAction
Genomeを提案。
感想:
● 論文を書く時にNeuroscience的な視点から論文
のSupport Factsを出すのは強く見せられそう。
● この論文でDynamic Scene Graphsが
Downstreamタスクへの有用性を示した。新しい
Representationやデータセットの提案する際に、
他のタスクとの関連性や遷移学習する際の有用
性を示すことが文章の質を大幅に向上できる。
Spatio-temporal Scene Graph Generationタスクの
Illustration:
ビデオからDynamic Scene Graphsを推定
32
Stanford : Vision and learning lab
33.
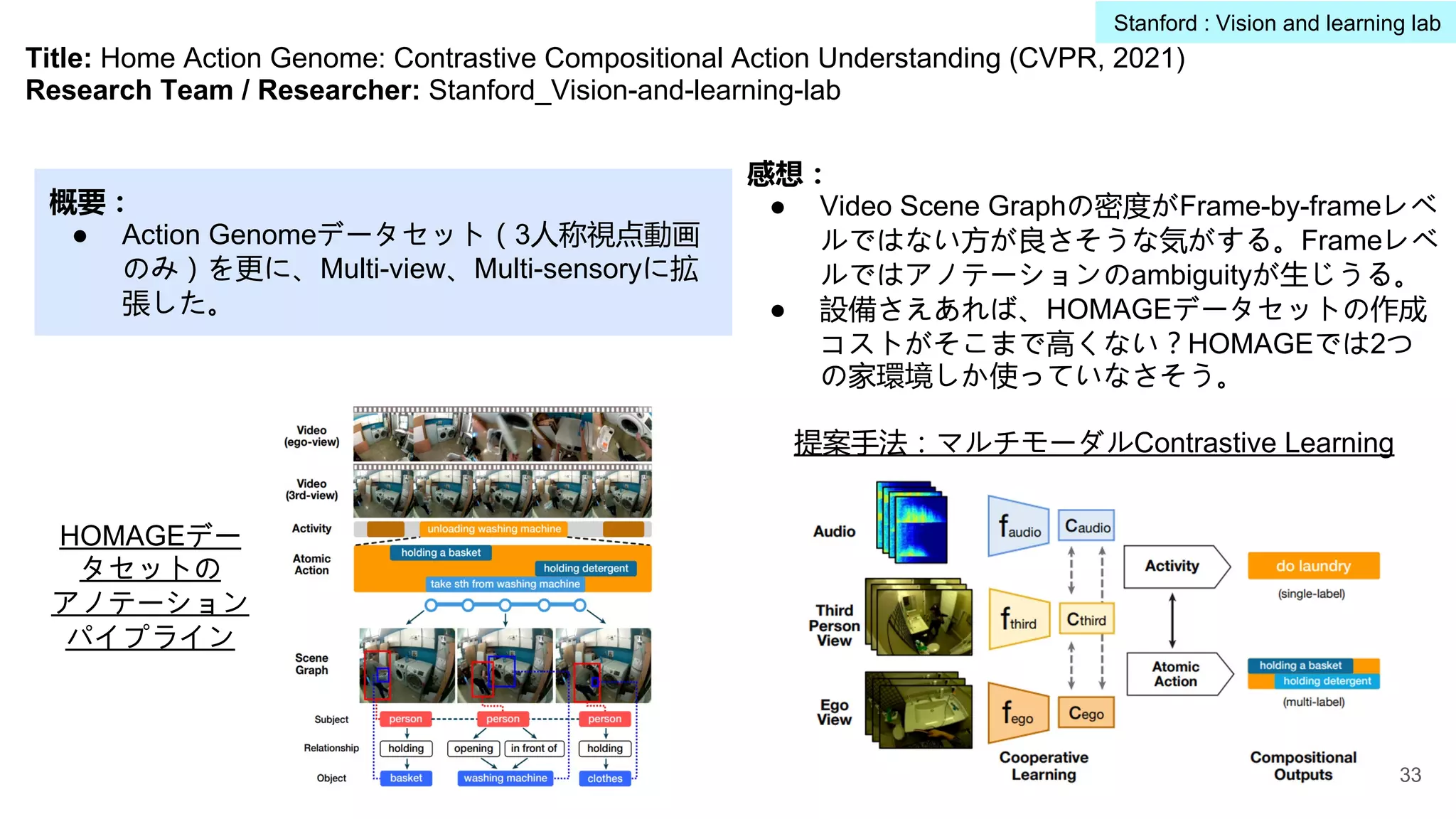
Title: Home ActionGenome: Contrastive Compositional Action Understanding (CVPR, 2021)
Research Team / Researcher: Stanford_Vision-and-learning-lab
概要:
● Action Genomeデータセット(3人称視点動画
のみ)を更に、Multi-view、Multi-sensoryに拡
張した。
感想:
● Video Scene Graphの密度がFrame-by-frameレベ
ルではない方が良さそうな気がする。Frameレベ
ルではアノテーションのambiguityが生じうる。
● 設備さえあれば、HOMAGEデータセットの作成
コストがそこまで高くない?HOMAGEでは2つ
の家環境しか使っていなさそう。
HOMAGEデー
タセットの
アノテーション
パイプライン
提案手法:マルチモーダルContrastive Learning
33
Stanford : Vision and learning lab
34.
Topic 2: SimulationEnvironments for
Embodied AI
34
Stanford : Vision and learning lab
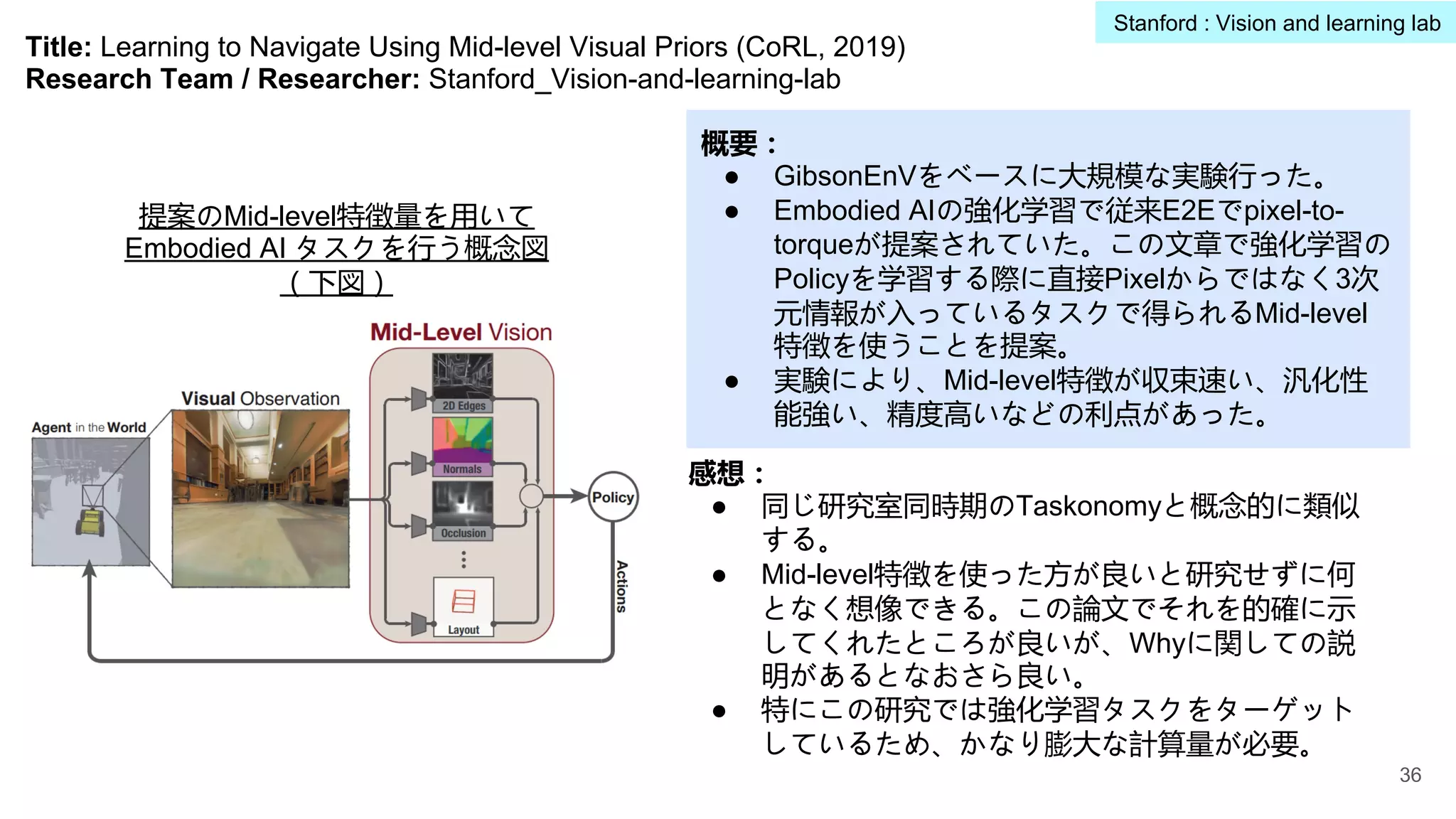
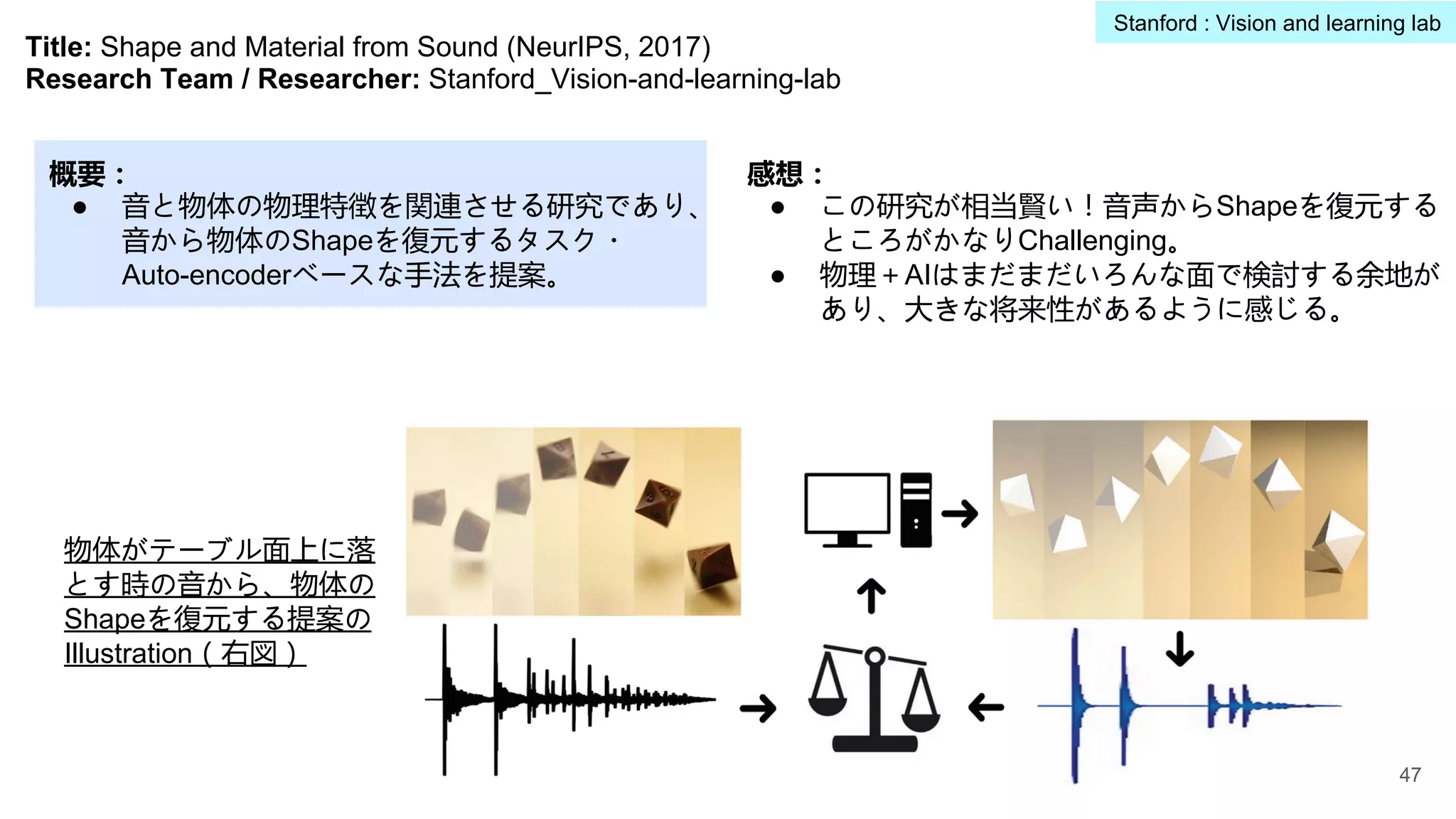
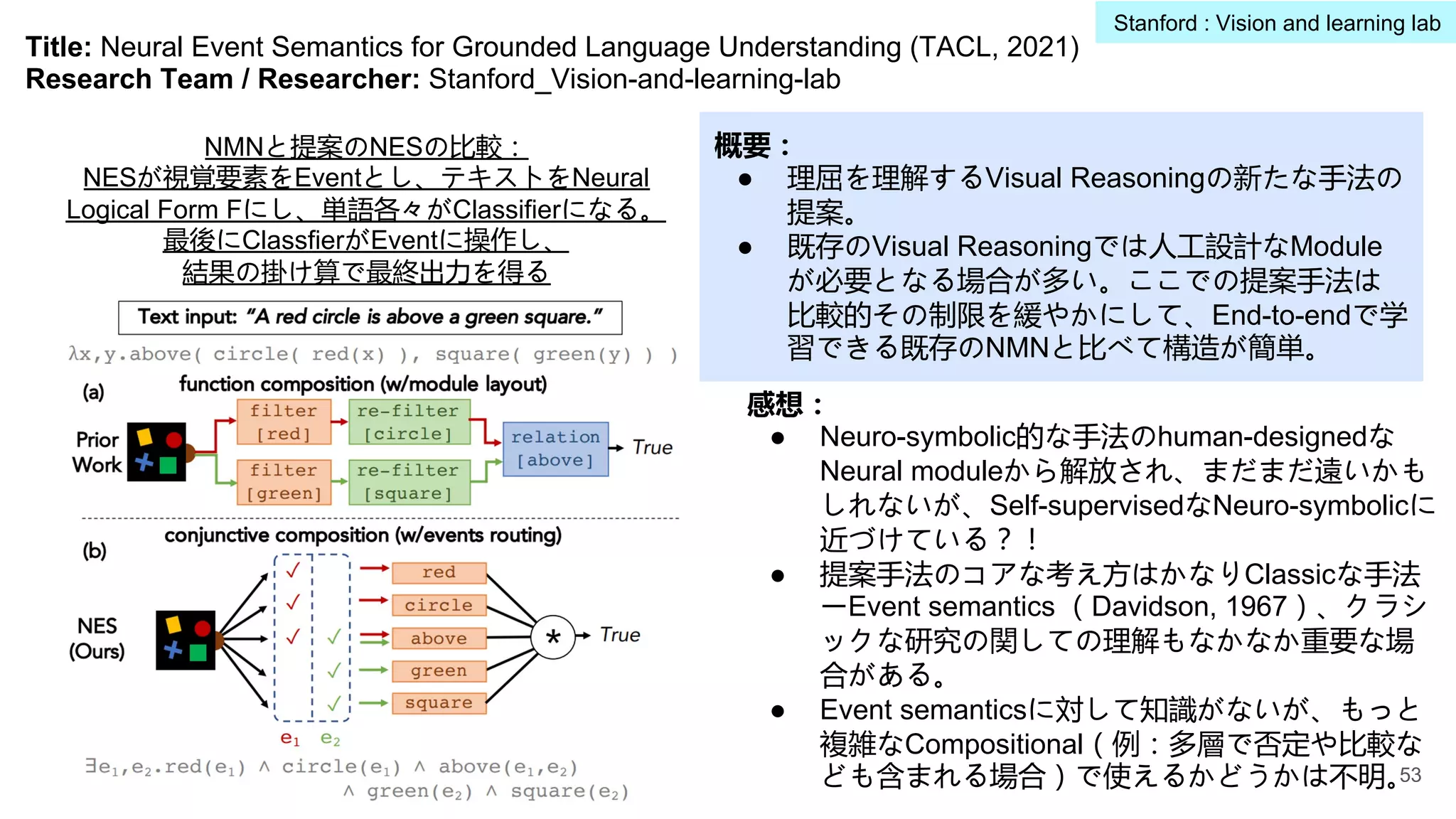
Title: Shape andMaterial from Sound (NeurIPS, 2017)
Research Team / Researcher: Stanford_Vision-and-learning-lab
概要:
● 音と物体の物理特徴を関連させる研究であり、
音から物体のShapeを復元するタスク・
Auto-encoderベースな手法を提案。
感想:
● この研究が相当賢い!音声からShapeを復元する
ところがかなりChallenging。
● 物理+AIはまだまだいろんな面で検討する余地が
あり、大きな将来性があるように感じる。
物体がテーブル面上に落
とす時の音から、物体の
Shapeを復元する提案の
Illustration(右図)
47
Stanford : Vision and learning lab
48.
Title: Deep AffordanceForesight: Planning Through What Can be Done in The Future (ICRA, 2021)
Research Team / Researcher: Stanford_Vision-and-learning-lab
概要:
● 物体のAffordanceをShort-termではなく(例:こ
の瞬間では持てる、押せるなど)、Long-termで
物体のAffordanceを扱う提案(例:物体の周囲の
物体を移動したら、この物体が押せるようにな
るなど)。
感想:
● 物体のAffordanceの定義がかなり難しく感じる。
通常の使い方や、非常的な使い方、タスクごと
の使いかたなど色々ある。
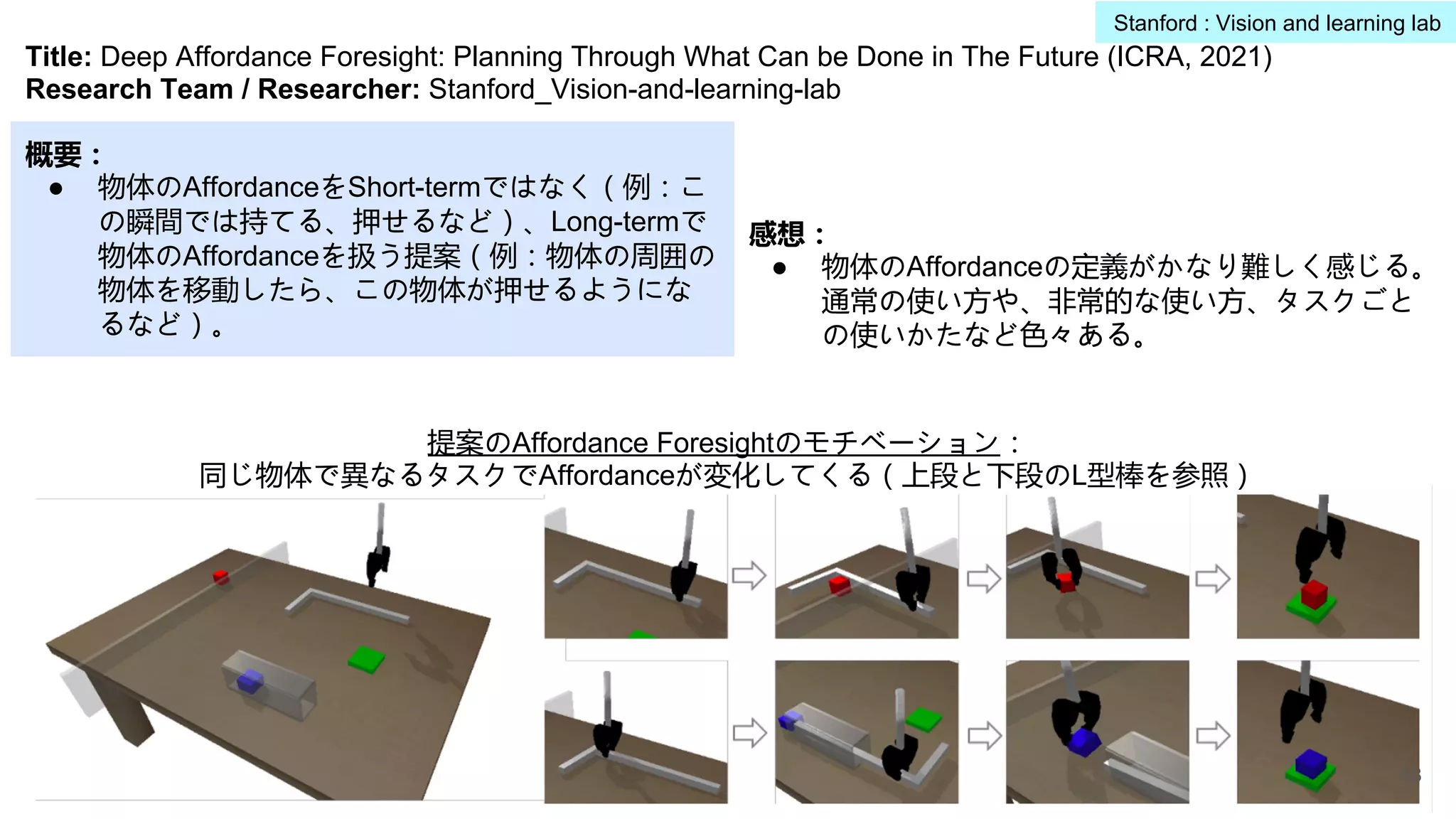
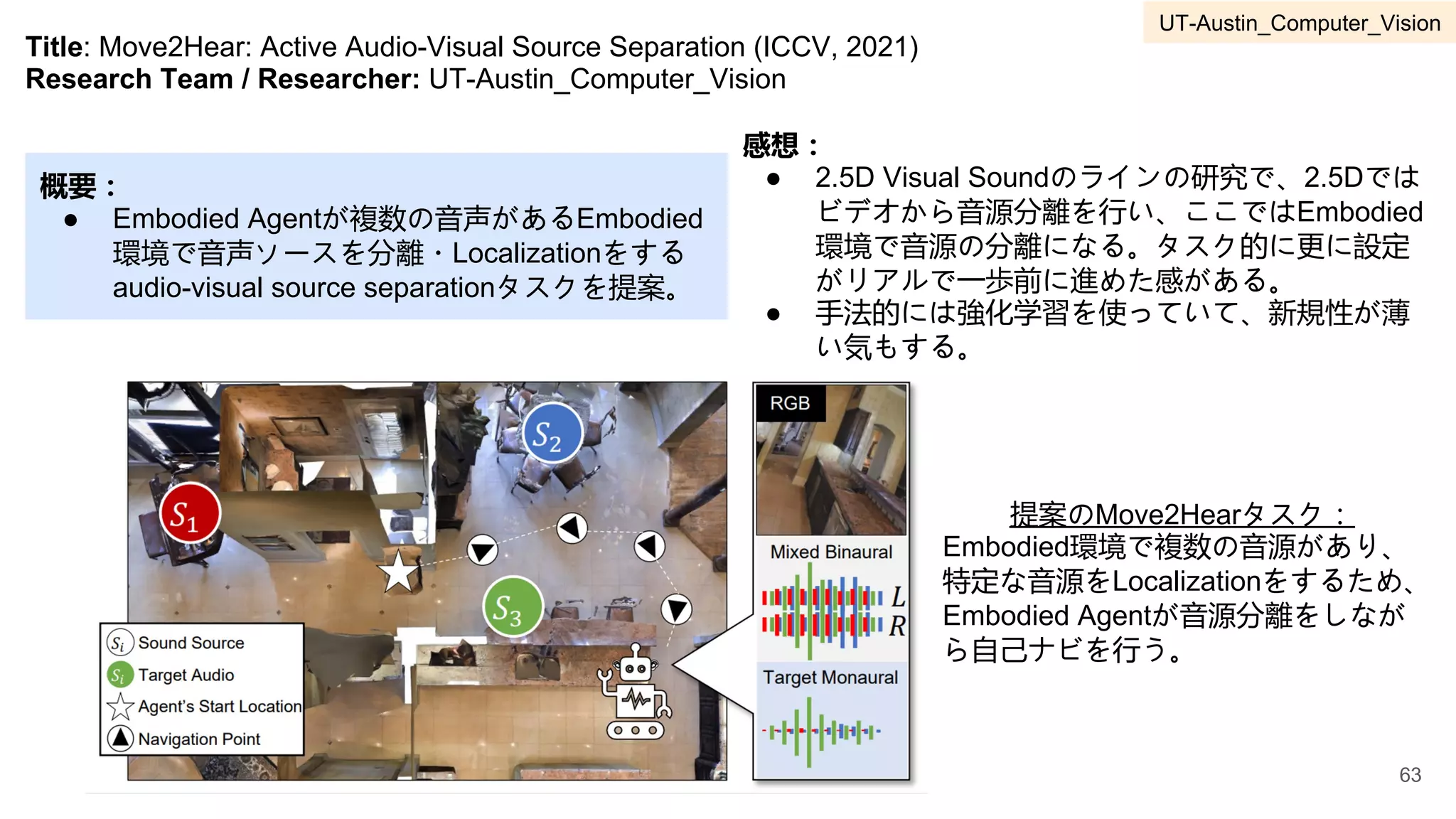
提案のAffordance Foresightのモチベーション:
同じ物体で異なるタスクでAffordanceが変化してくる(上段と下段のL型棒を参照)
48
Stanford : Vision and learning lab
49.
Title: OBJECTFOLDER: ADataset of Objects with Implicit Visual, Auditory, and Tacticle Representations
(CoRL, 2021)
Research Team / Researcher: Stanford_Vision-and-learning-lab
概要:
● 100 Simulation物体(視覚・音声・触感)を
含まれたデータセットOBJECTFOLDERを提
案。
● 3つのSubnetで(NeRFベース)で同時に上
記の3つをRenderingできる手法も提案。
感想:
● Touch(触感)がようやく入ってきました!(今
までは視覚・言語・音声だった)
● NeRFですべてを統一できる?
● Smellはまた入っていない。
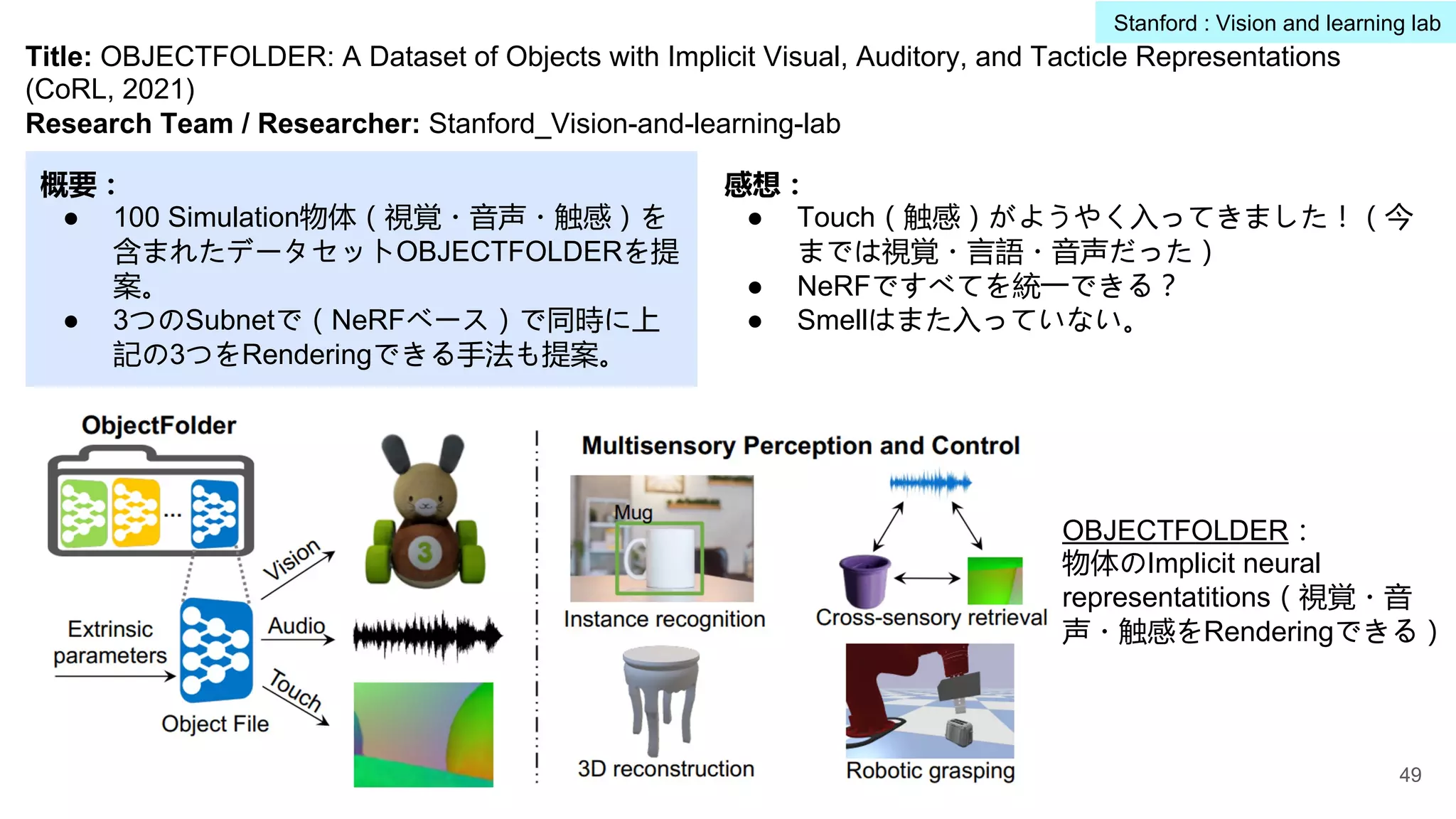
OBJECTFOLDER:
物体のImplicit neural
representatitions(視覚・音
声・触感をRenderingできる)
49
Stanford : Vision and learning lab
研究者 扱っている研究分野:
選定理由:
● VisualReasoning
● Vision and Language
● Image generation
● 3D Reasoning
● Vision and Languageを含めて、複数の分
野で重要な論文を残した
○ Vision and Language
■ CLEVR
■ Scene Graph
■ Dense Captioning
○ その他
■ Perceptual Loss
92
Justin Johnson先生
写真URL:https://web.eecs.umich.edu/~justincj/
Michigan: Justin Johnson
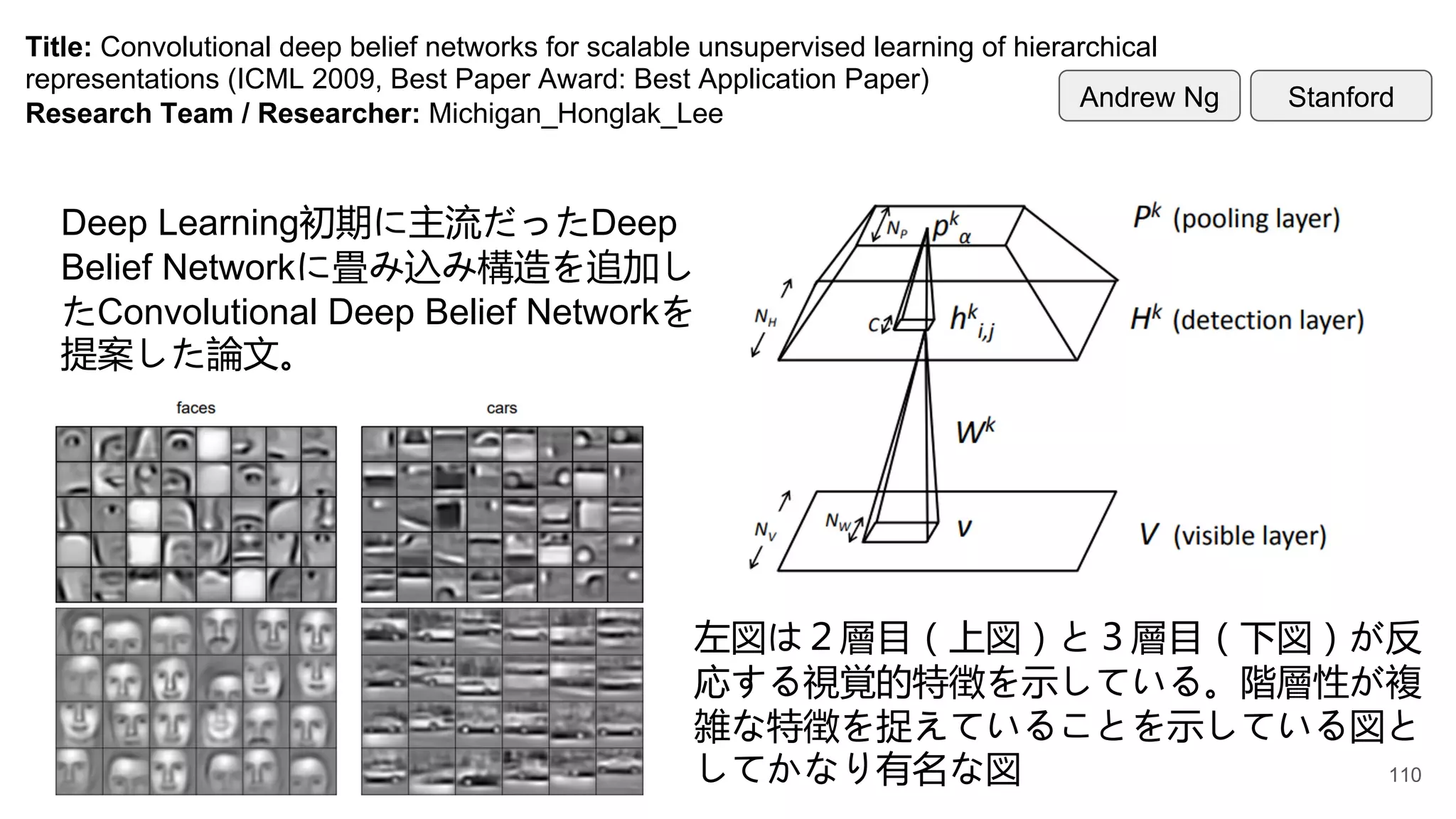
Title: Convolutional deepbelief networks for scalable unsupervised learning of hierarchical
representations (ICML 2009, Best Paper Award: Best Application Paper)
Research Team / Researcher: Michigan_Honglak_Lee
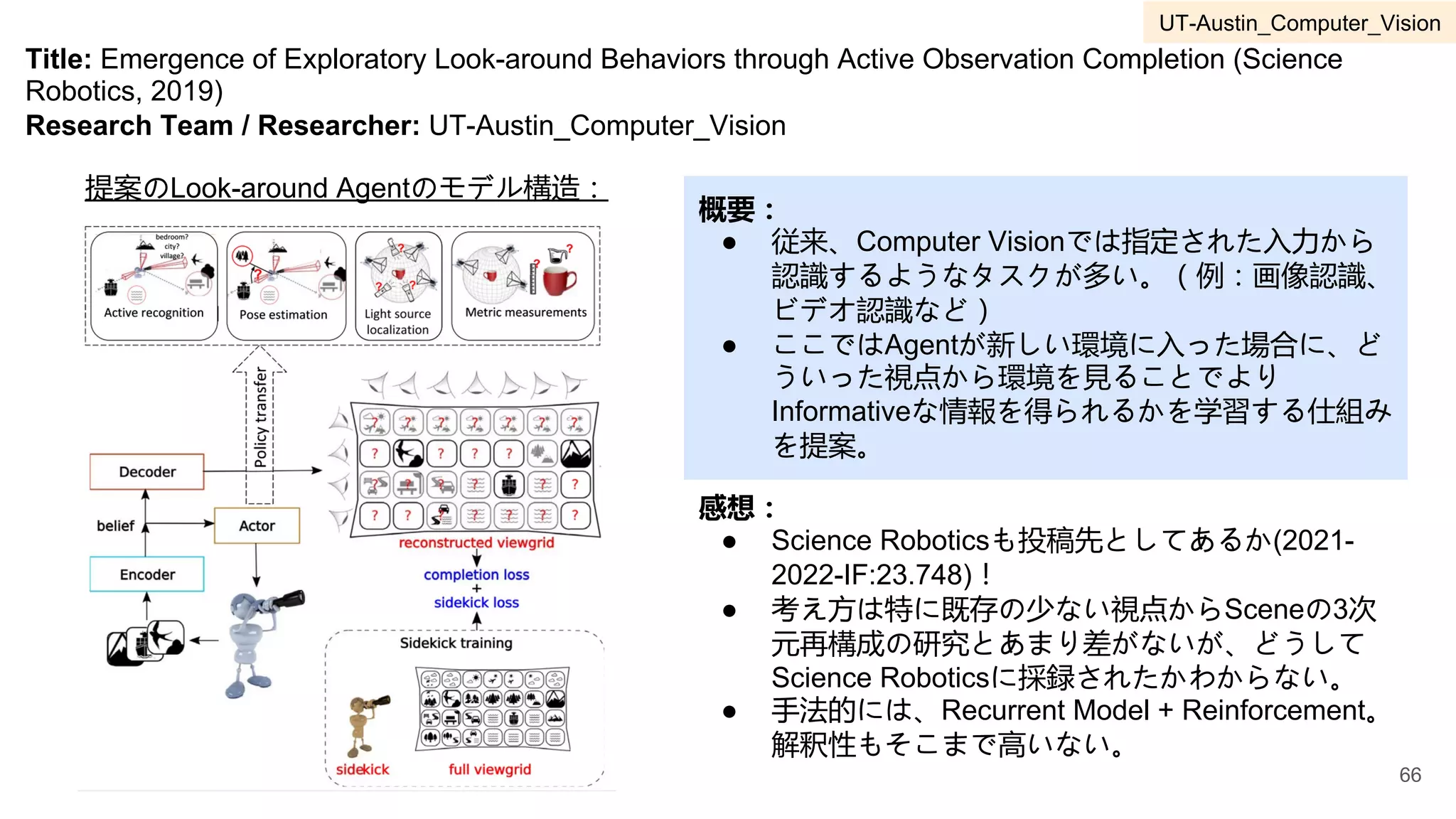
Deep Learning初期に主流だったDeep
Belief Networkに畳み込み構造を追加し
たConvolutional Deep Belief Networkを
提案した論文。
左図は2層目(上図)と3層目(下図)が反
応する視覚的特徴を示している。階層性が複
雑な特徴を捉えていることを示している図と
してかなり有名な図
Stanford
Andrew Ng
110
111.
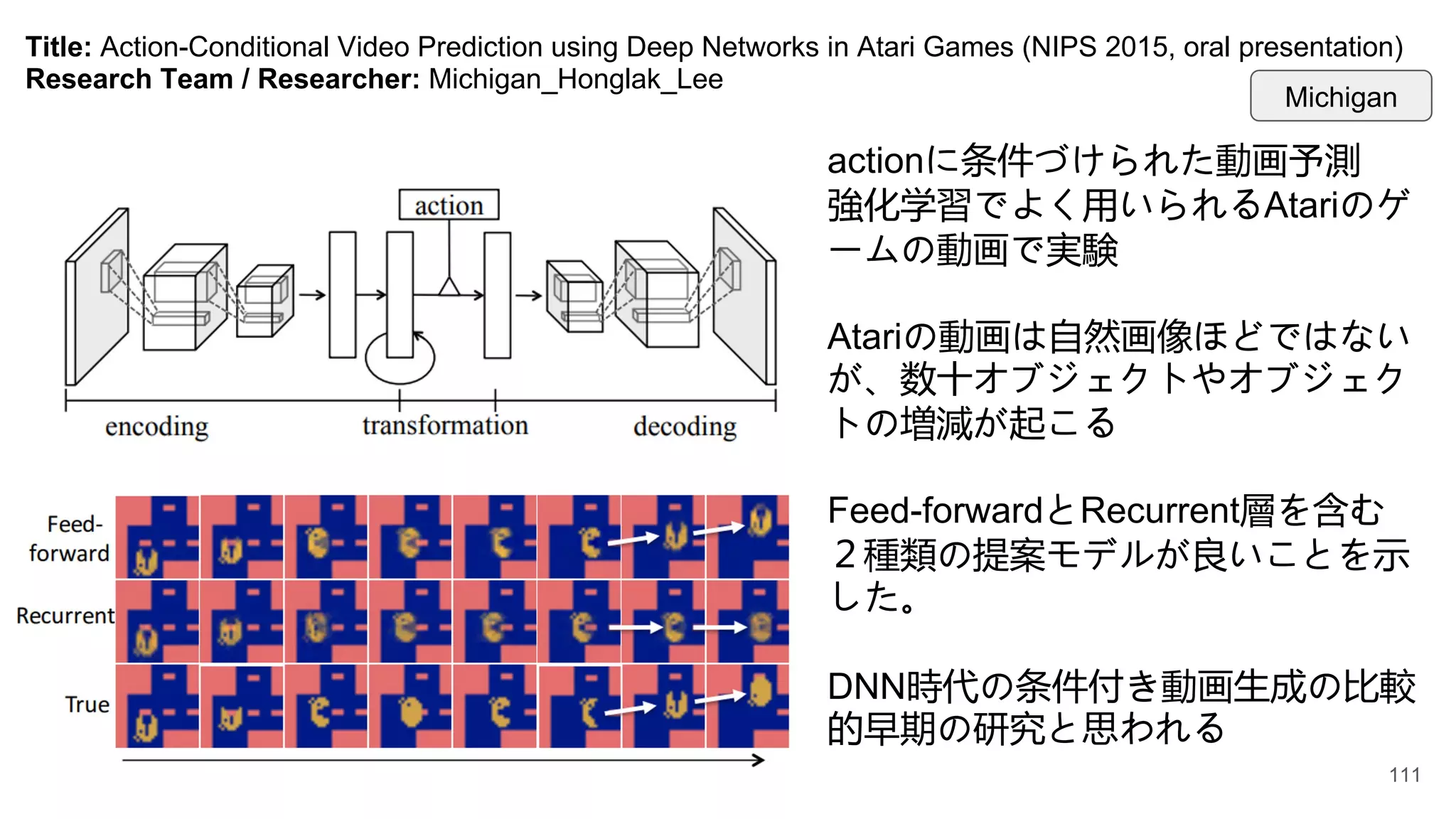
Title: Action-Conditional VideoPrediction using Deep Networks in Atari Games (NIPS 2015, oral presentation)
Research Team / Researcher: Michigan_Honglak_Lee
actionに条件づけられた動画予測
強化学習でよく用いられるAtariのゲ
ームの動画で実験
Atariの動画は自然画像ほどではない
が、数十オブジェクトやオブジェク
トの増減が起こる
Feed-forwardとRecurrent層を含む
2種類の提案モデルが良いことを示
した。
DNN時代の条件付き動画生成の比較
的早期の研究と思われる
Michigan
111
112.
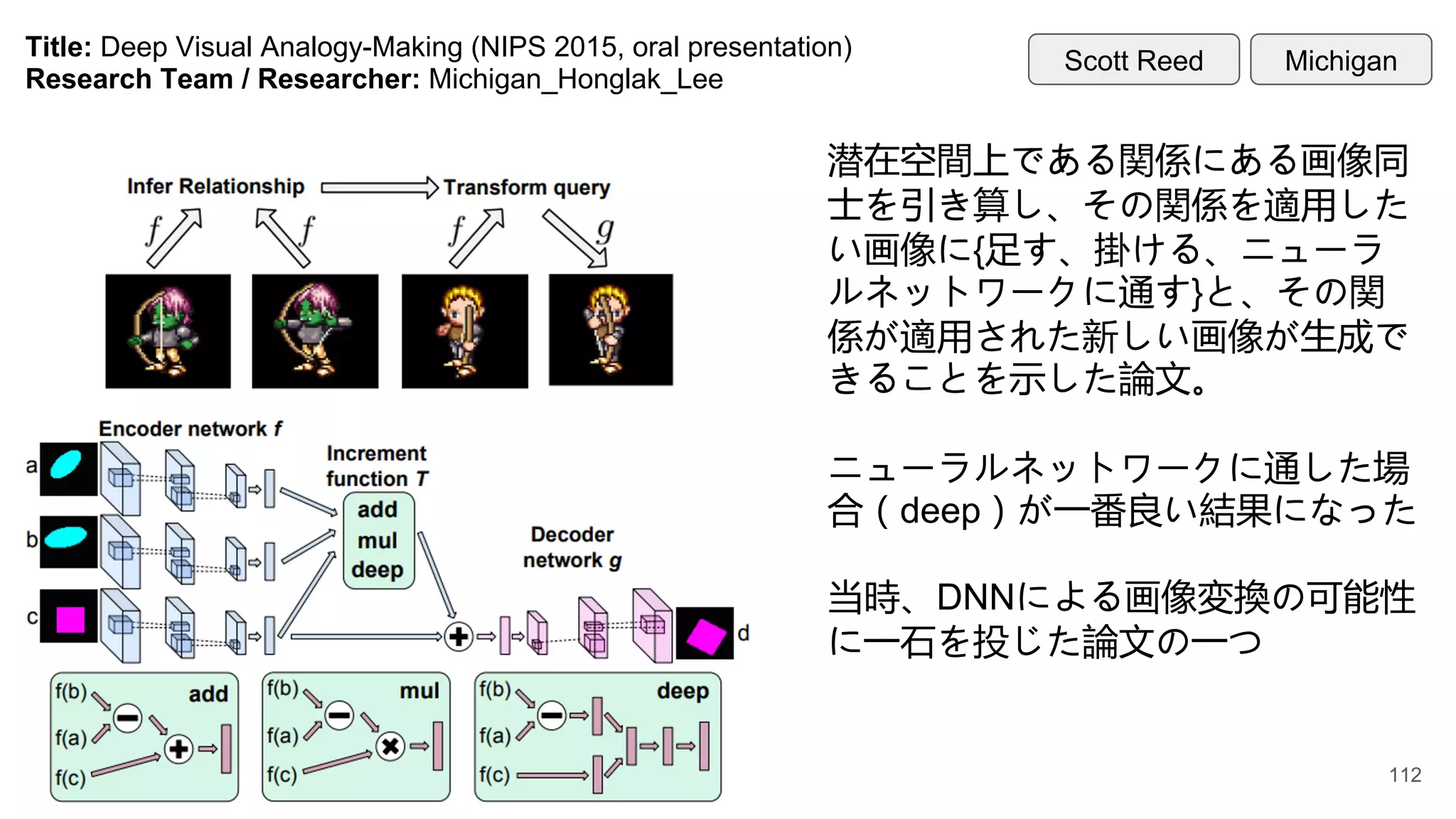
Title: Deep VisualAnalogy-Making (NIPS 2015, oral presentation)
Research Team / Researcher: Michigan_Honglak_Lee
潜在空間上である関係にある画像同
士を引き算し、その関係を適用した
い画像に{足す、掛ける、ニューラ
ルネットワークに通す}と、その関
係が適用された新しい画像が生成で
きることを示した論文。
ニューラルネットワークに通した場
合(deep)が一番良い結果になった
当時、DNNによる画像変換の可能性
に一石を投じた論文の一つ
Michigan
Scott Reed
112
113.
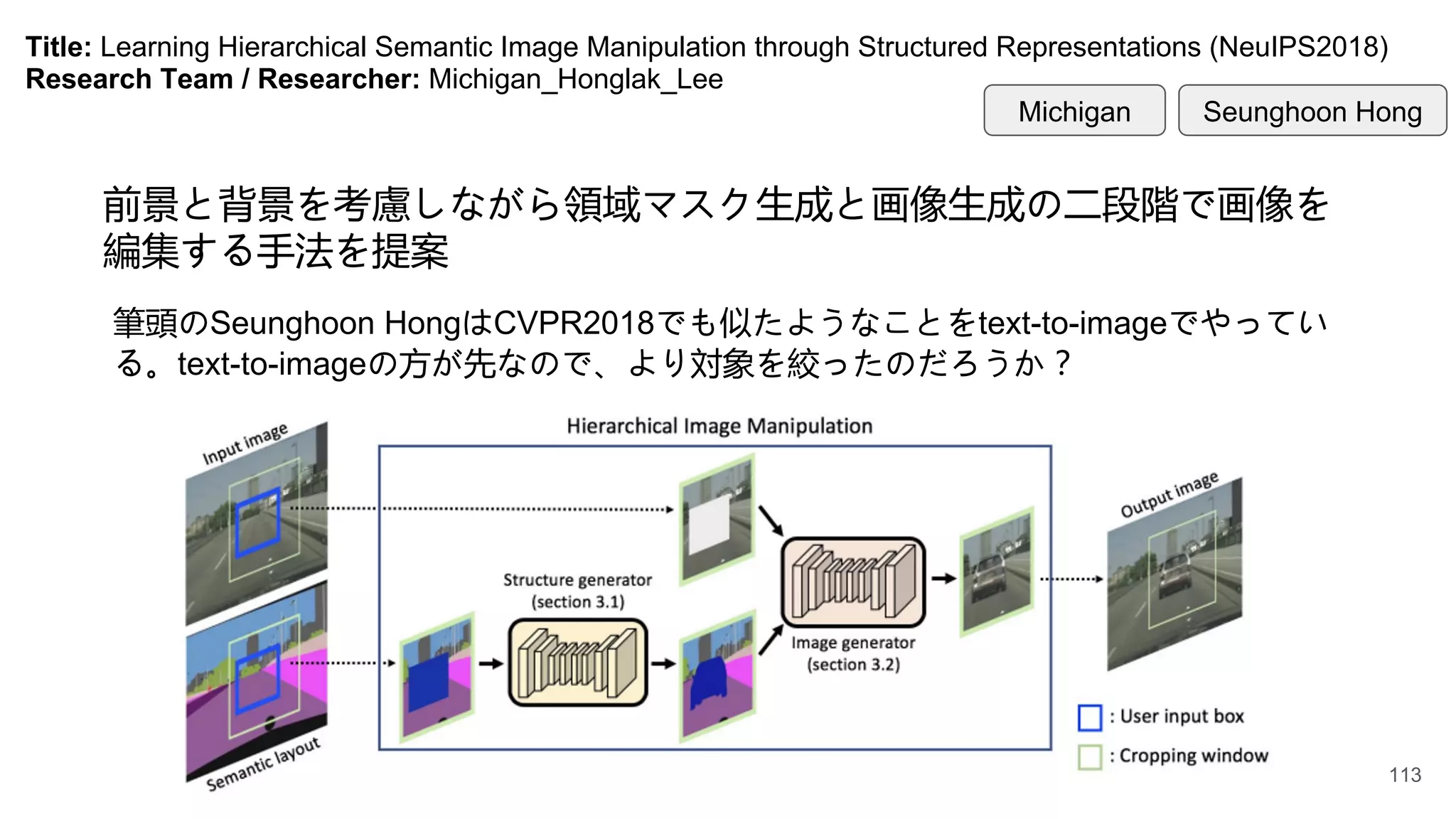
Title: Learning HierarchicalSemantic Image Manipulation through Structured Representations (NeuIPS2018)
Research Team / Researcher: Michigan_Honglak_Lee
前景と背景を考慮しながら領域マスク生成と画像生成の二段階で画像を
編集する手法を提案
筆頭のSeunghoon HongはCVPR2018でも似たようなことをtext-to-imageでやってい
る。text-to-imageの方が先なので、より対象を絞ったのだろうか?
Seunghoon Hong
Michigan
113
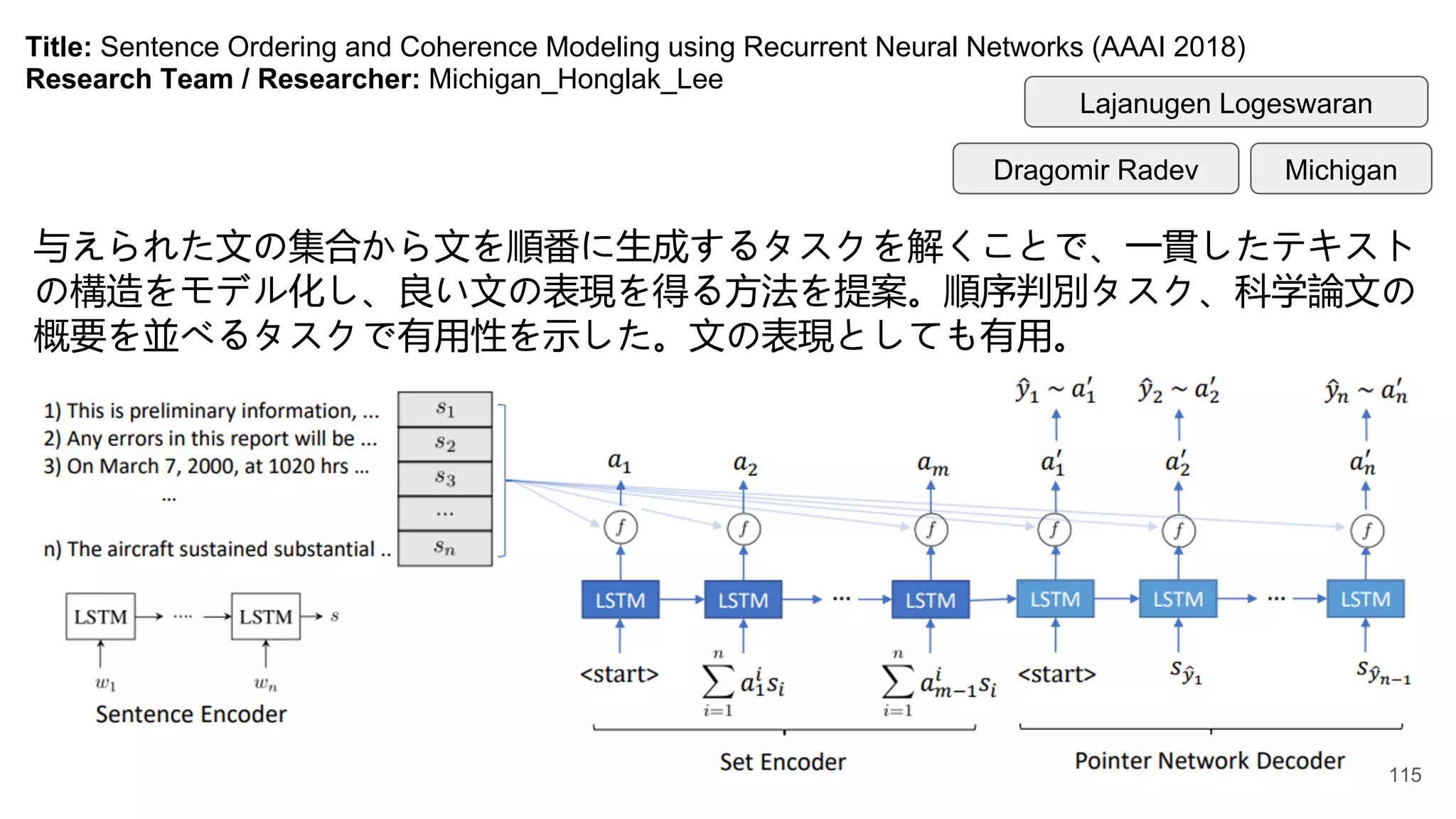
Title: Sentence Orderingand Coherence Modeling using Recurrent Neural Networks (AAAI 2018)
Research Team / Researcher: Michigan_Honglak_Lee
Lajanugen Logeswaran
Michigan
Dragomir Radev
与えられた文の集合から文を順番に生成するタスクを解くことで、一貫したテキスト
の構造をモデル化し、良い文の表現を得る方法を提案。順序判別タスク、科学論文の
概要を並べるタスクで有用性を示した。文の表現としても有用。
115
116.
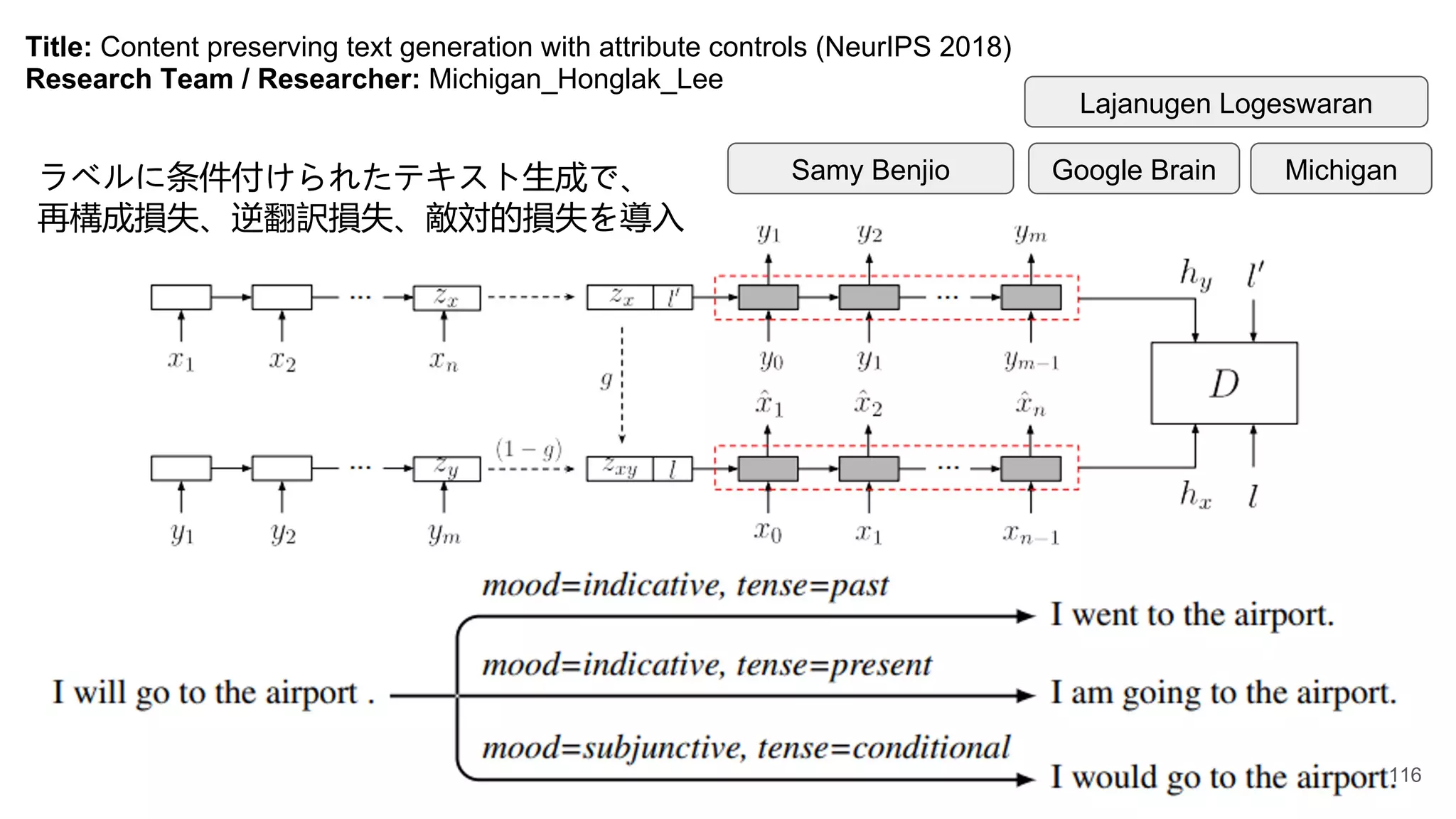
Title: Content preservingtext generation with attribute controls (NeurIPS 2018)
Research Team / Researcher: Michigan_Honglak_Lee
Lajanugen Logeswaran
Michigan
Google Brain
Samy Benjio
ラベルに条件付けられたテキスト生成で、
再構成損失、逆翻訳損失、敵対的損失を導入
116
117.
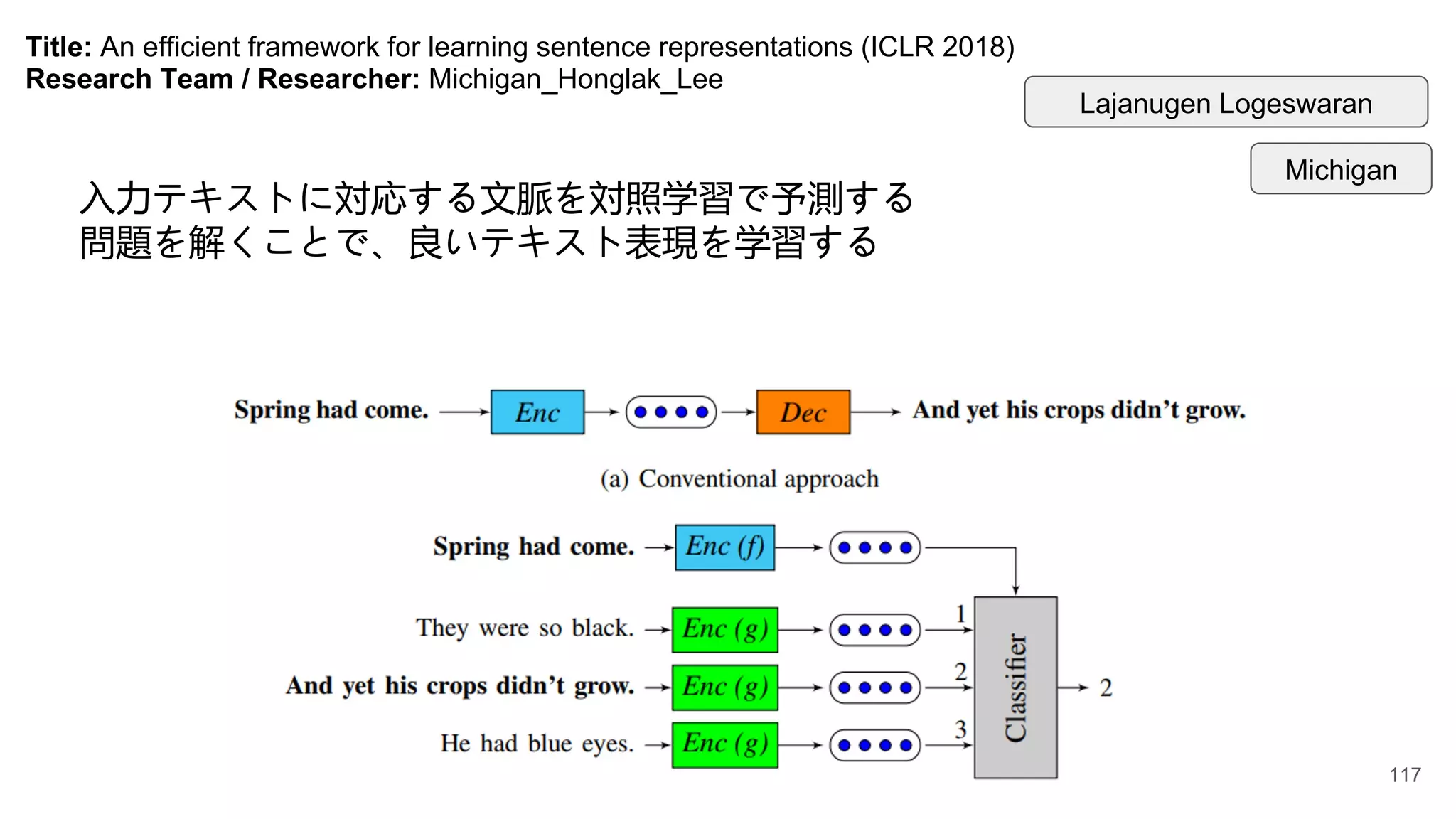
Title: An efficientframework for learning sentence representations (ICLR 2018)
Research Team / Researcher: Michigan_Honglak_Lee
Lajanugen Logeswaran
Michigan
入力テキストに対応する文脈を対照学習で予測する
問題を解くことで、良いテキスト表現を学習する
117
118.
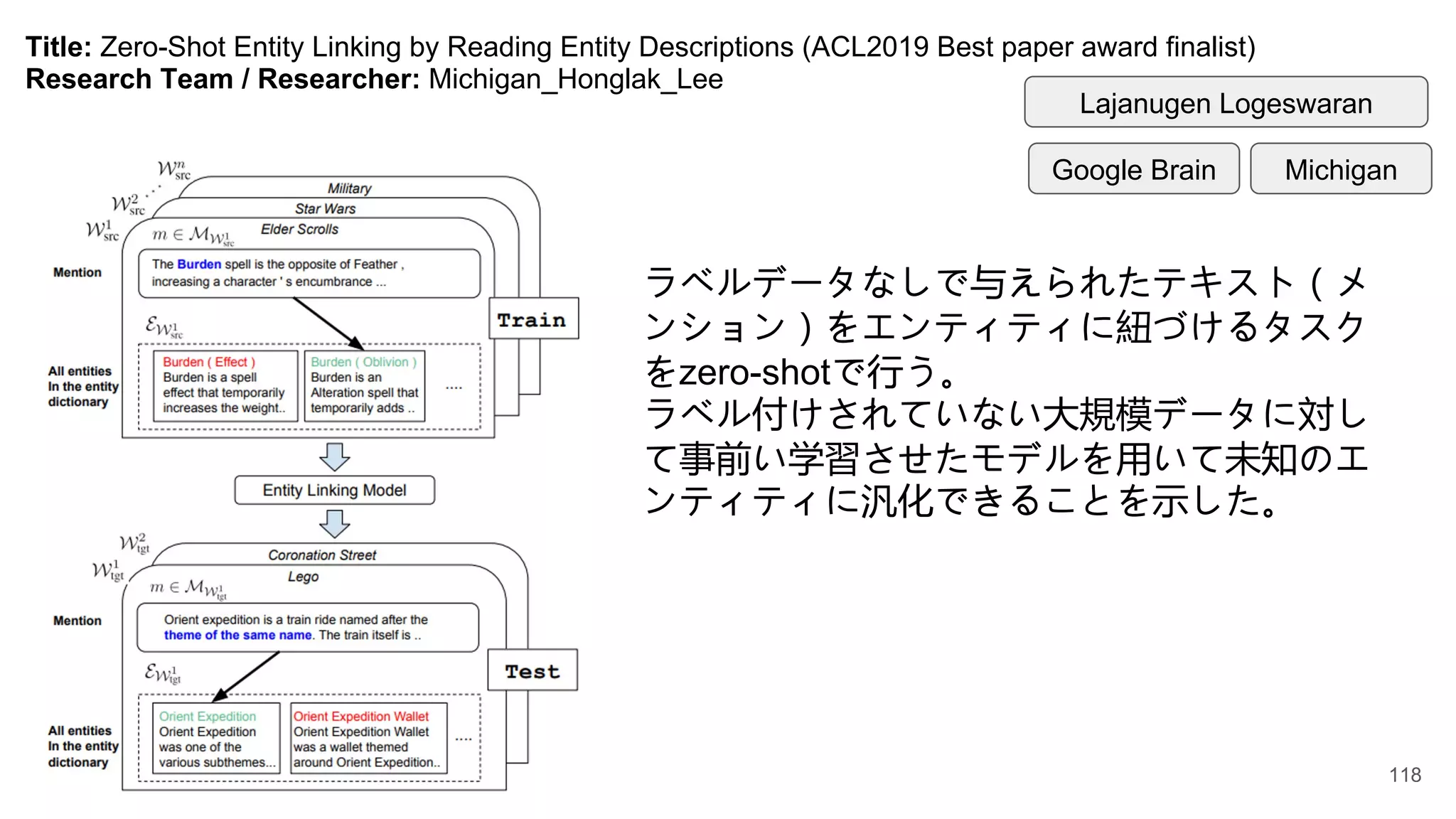
Title: Zero-Shot EntityLinking by Reading Entity Descriptions (ACL2019 Best paper award finalist)
Research Team / Researcher: Michigan_Honglak_Lee
ラベルデータなしで与えられたテキスト(メ
ンション)をエンティティに紐づけるタスク
をzero-shotで行う。
ラベル付けされていない大規模データに対し
て事前い学習させたモデルを用いて未知のエ
ンティティに汎化できることを示した。
Lajanugen Logeswaran
Michigan
Google Brain
118
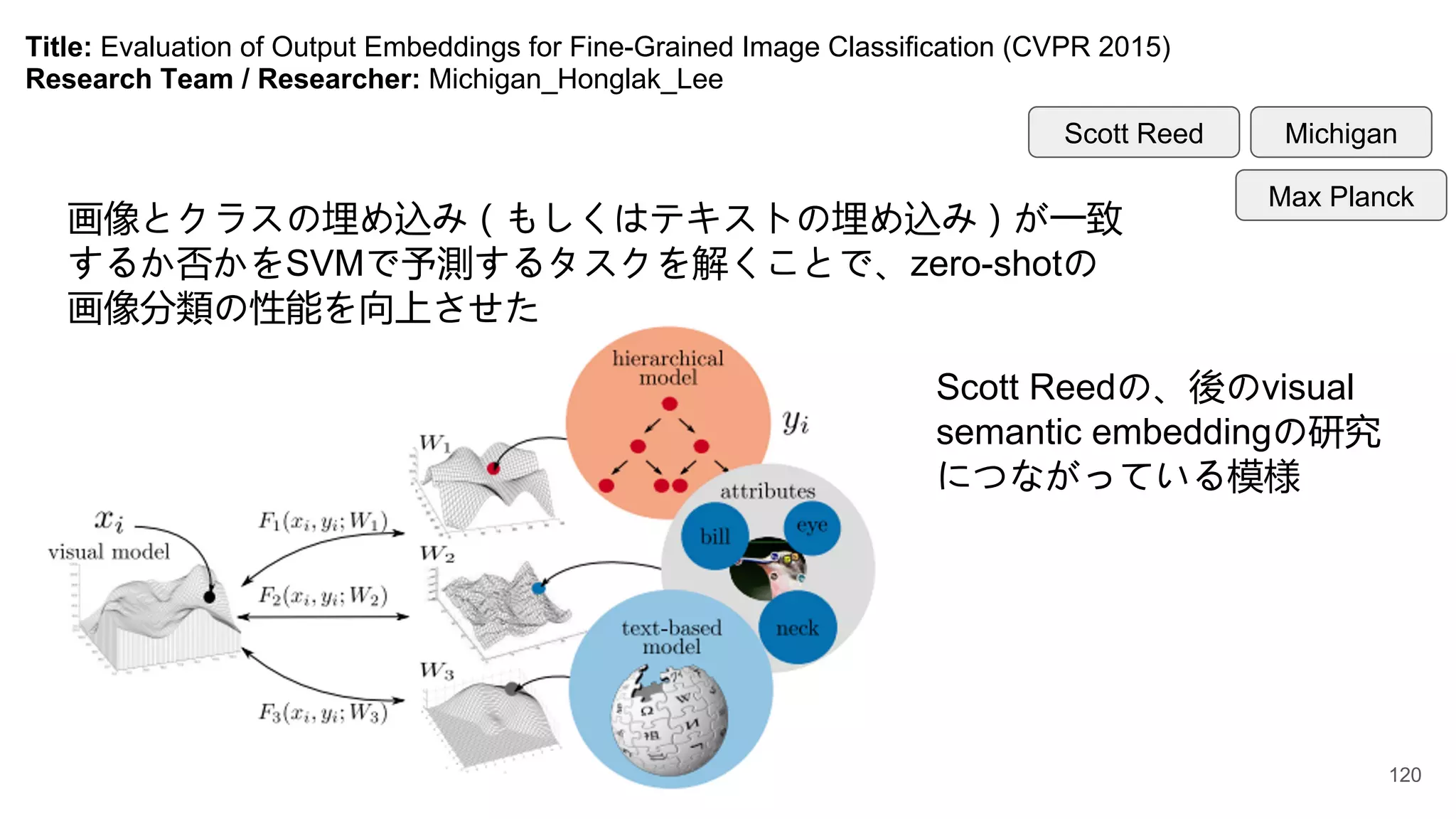
Title: Evaluation ofOutput Embeddings for Fine-Grained Image Classification (CVPR 2015)
Research Team / Researcher: Michigan_Honglak_Lee
Michigan
Scott Reed
Max Planck
画像とクラスの埋め込み(もしくはテキストの埋め込み)が一致
するか否かをSVMで予測するタスクを解くことで、zero-shotの
画像分類の性能を向上させた
Scott Reedの、後のvisual
semantic embeddingの研究
につながっている模様
120
121.
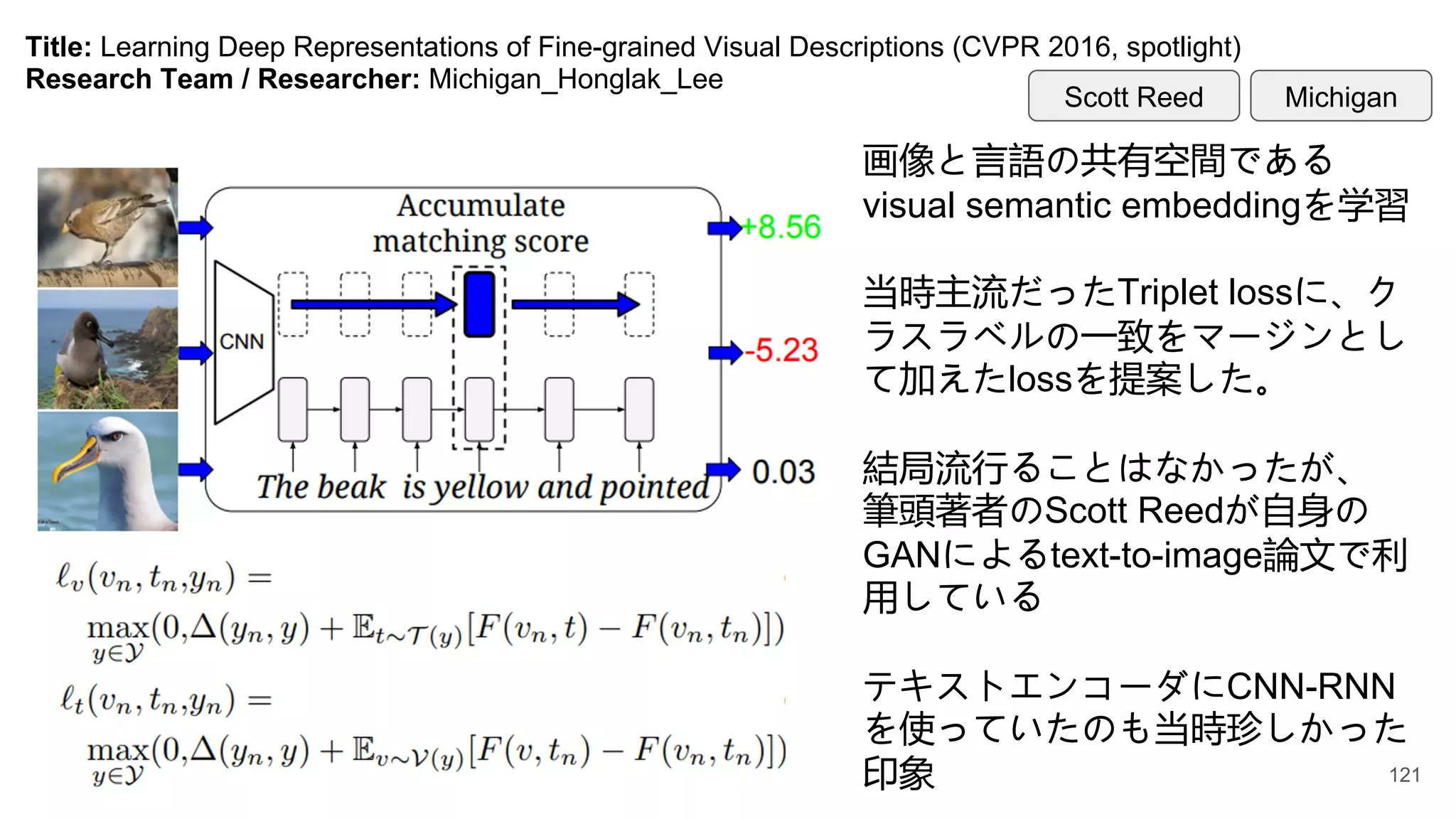
Title: Learning DeepRepresentations of Fine-grained Visual Descriptions (CVPR 2016, spotlight)
Research Team / Researcher: Michigan_Honglak_Lee
画像と言語の共有空間である
visual semantic embeddingを学習
当時主流だったTriplet lossに、ク
ラスラベルの一致をマージンとし
て加えたlossを提案した。
結局流行ることはなかったが、
筆頭著者のScott Reedが自身の
GANによるtext-to-image論文で利
用している
テキストエンコーダにCNN-RNN
を使っていたのも当時珍しかった
印象
Michigan
Scott Reed
121
122.
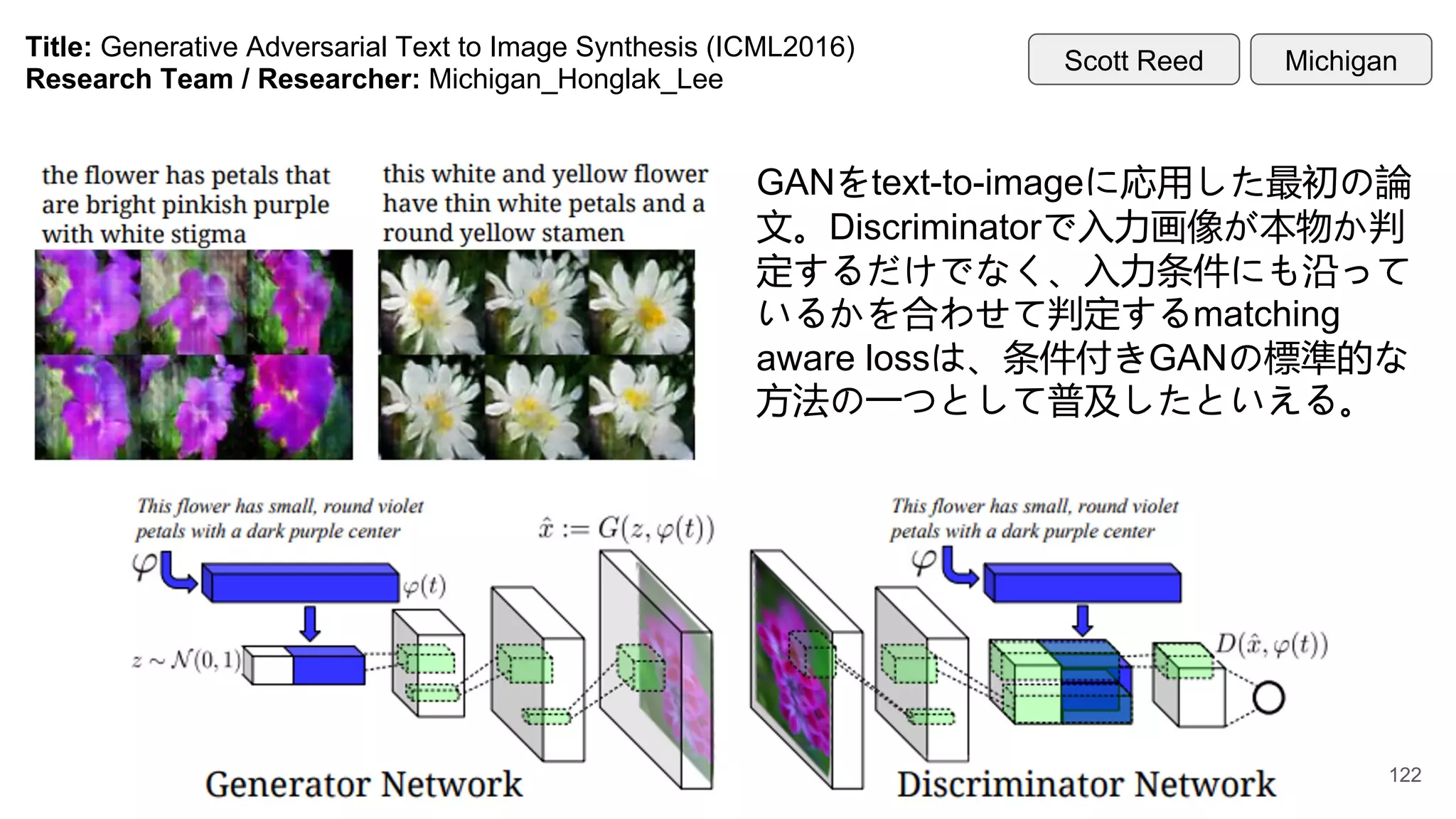
Title: Generative AdversarialText to Image Synthesis (ICML2016)
Research Team / Researcher: Michigan_Honglak_Lee
GANをtext-to-imageに応用した最初の論
文。Discriminatorで入力画像が本物か判
定するだけでなく、入力条件にも沿って
いるかを合わせて判定するmatching
aware lossは、条件付きGANの標準的な
方法の一つとして普及したといえる。
Michigan
Scott Reed
122
123.
Title: Learning Whatand Where to Draw (NIPS 2016, oral presentation)
Research Team / Researcher: Michigan_Honglak_Lee
概要:
text-to-imageの入力に自然言語だけで
なく矩形やkey-pointなど、空間的な情
報を含めて生成する手法を提案した。
テキスト+追加情報でtext-to-imageを
することの先駆けとなった論文
Honglak Leeのラボでは、この手のネ
タがしばらく継承されてきている
Michigan
Scott Reed
123
124.
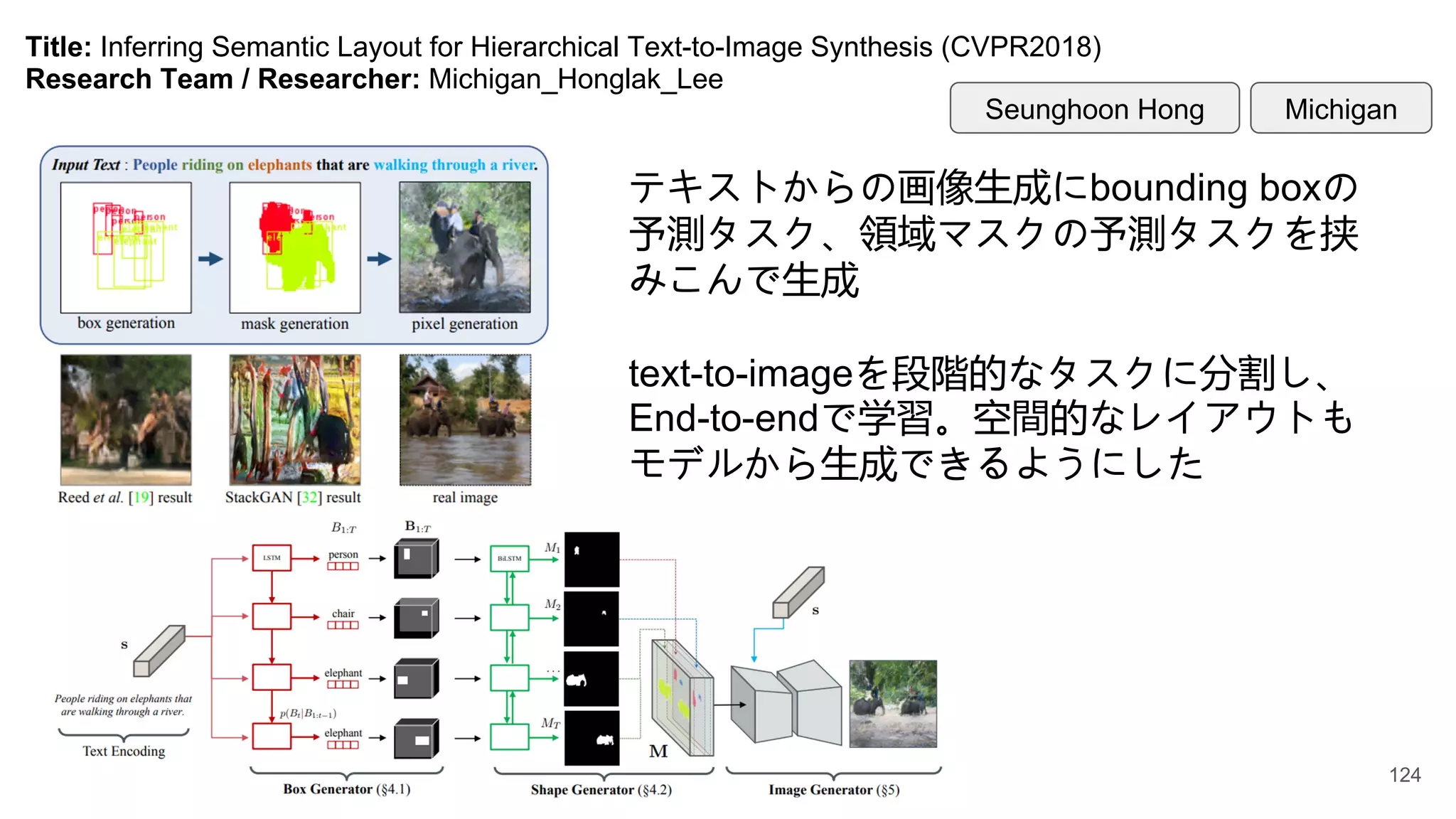
Title: Inferring SemanticLayout for Hierarchical Text-to-Image Synthesis (CVPR2018)
Research Team / Researcher: Michigan_Honglak_Lee
テキストからの画像生成にbounding boxの
予測タスク、領域マスクの予測タスクを挟
みこんで生成
text-to-imageを段階的なタスクに分割し、
End-to-endで学習。空間的なレイアウトも
モデルから生成できるようにした
Michigan
Seunghoon Hong
124
125.
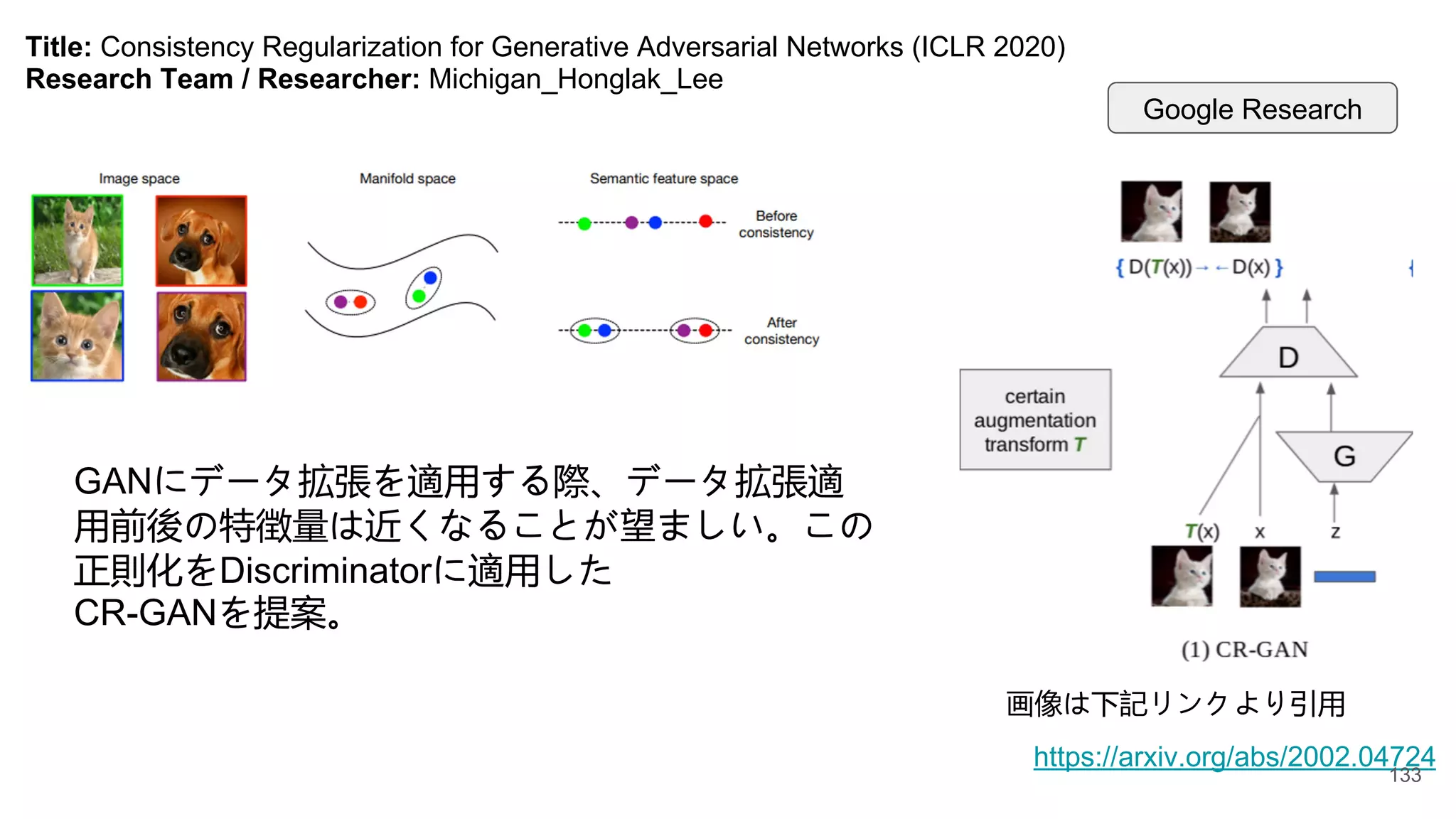
Title: Text-to-Image GenerationGrounded by Fine-Grained User Attention (WACV 2021)
Research Team / Researcher: Michigan_Honglak_Lee
実践的なテキストからの画像
生成の方法として、ユーザが
喋りながらマウスによる軌跡
入力を行えるという問題設定
の下で画像を生成
Google Research
125
126.
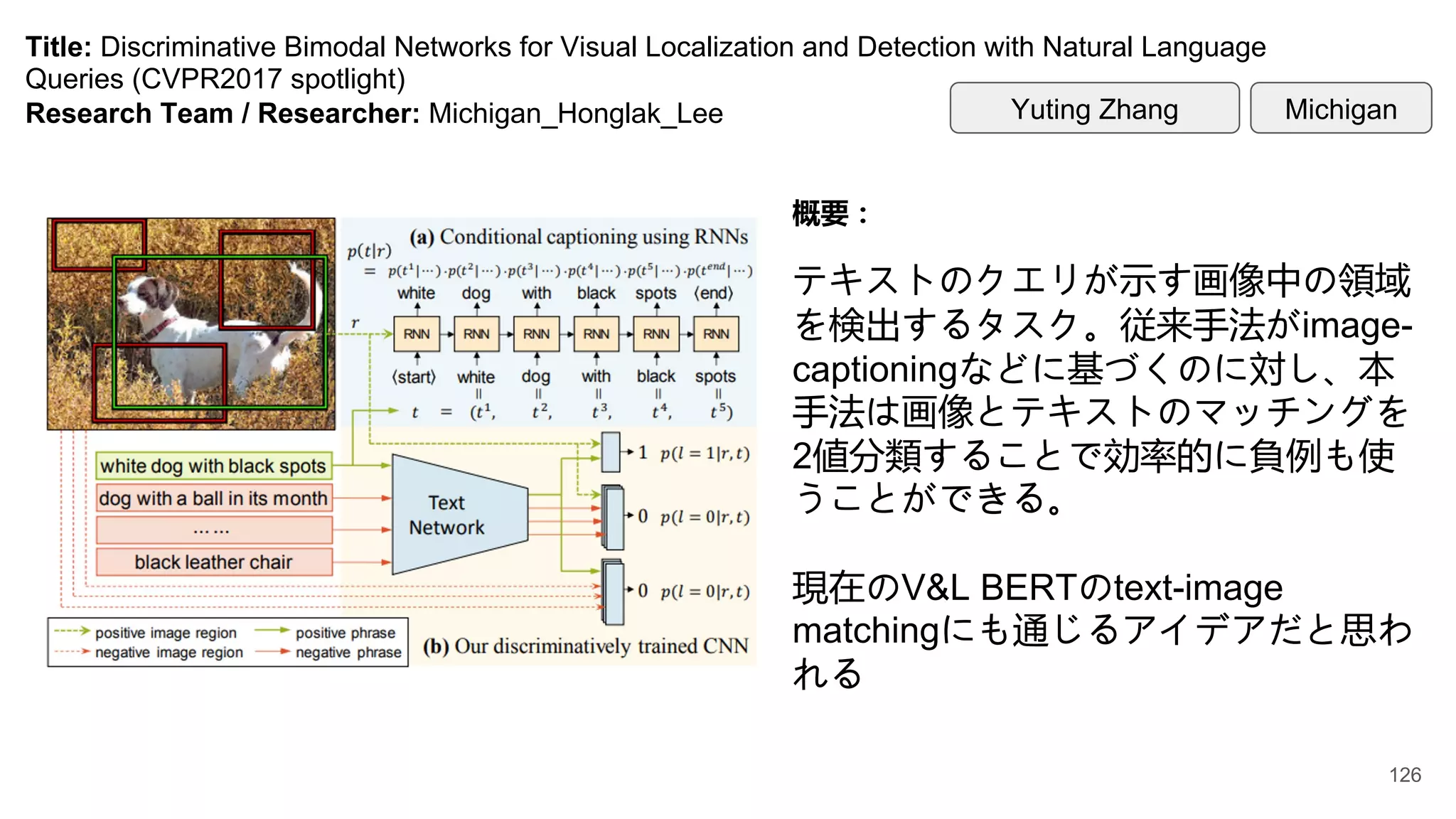
Title: Discriminative BimodalNetworks for Visual Localization and Detection with Natural Language
Queries (CVPR2017 spotlight)
Research Team / Researcher: Michigan_Honglak_Lee
概要:
テキストのクエリが示す画像中の領域
を検出するタスク。従来手法がimage-
captioningなどに基づくのに対し、本
手法は画像とテキストのマッチングを
2値分類することで効率的に負例も使
うことができる。
現在のV&L BERTのtext-image
matchingにも通じるアイデアだと思わ
れる
Michigan
Yuting Zhang
126
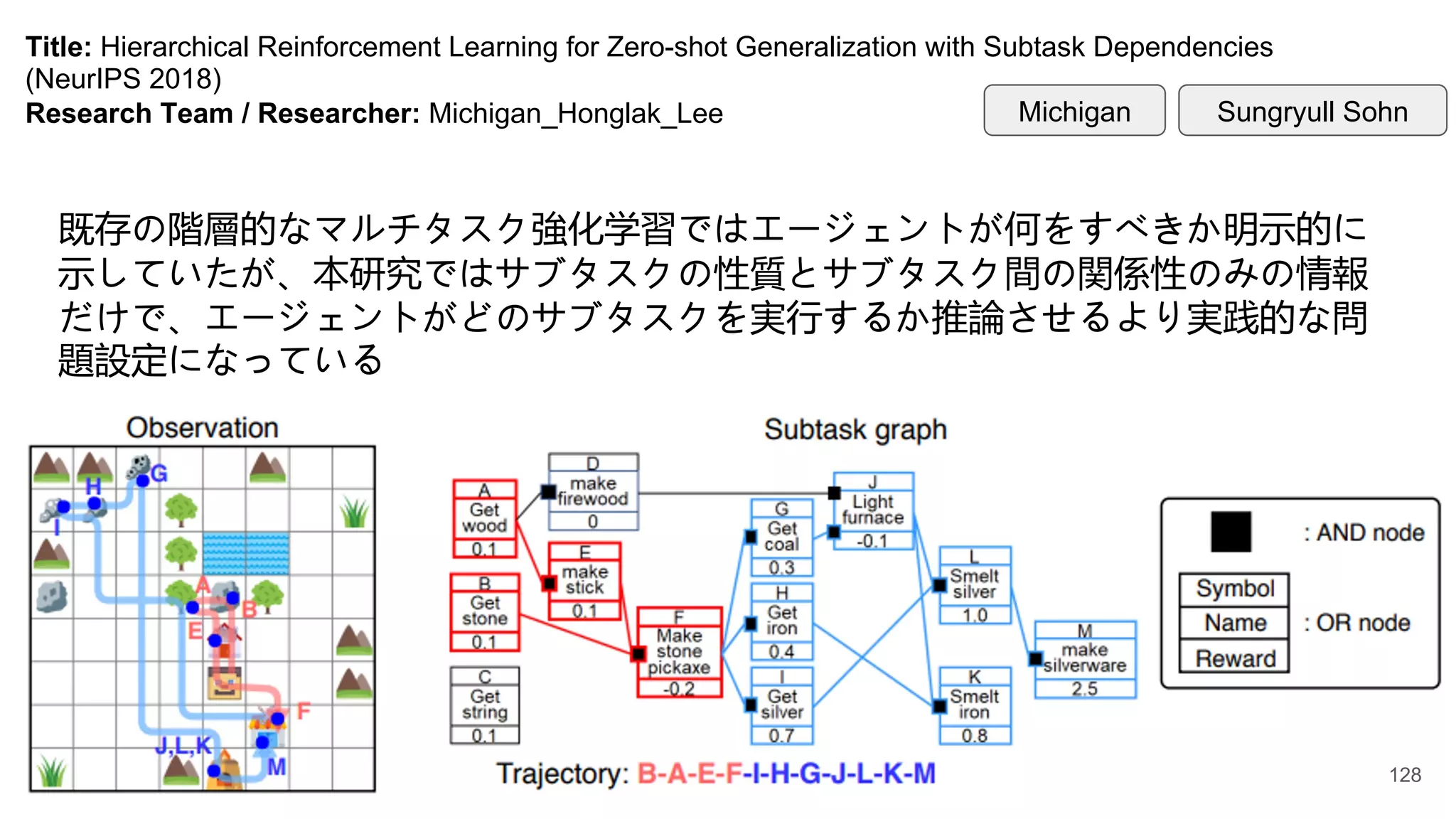
Title: Hierarchical ReinforcementLearning for Zero-shot Generalization with Subtask Dependencies
(NeurIPS 2018)
Research Team / Researcher: Michigan_Honglak_Lee Sungryull Sohn
Michigan
既存の階層的なマルチタスク強化学習ではエージェントが何をすべきか明示的に
示していたが、本研究ではサブタスクの性質とサブタスク間の関係性のみの情報
だけで、エージェントがどのサブタスクを実行するか推論させるより実践的な問
題設定になっている
128
129.
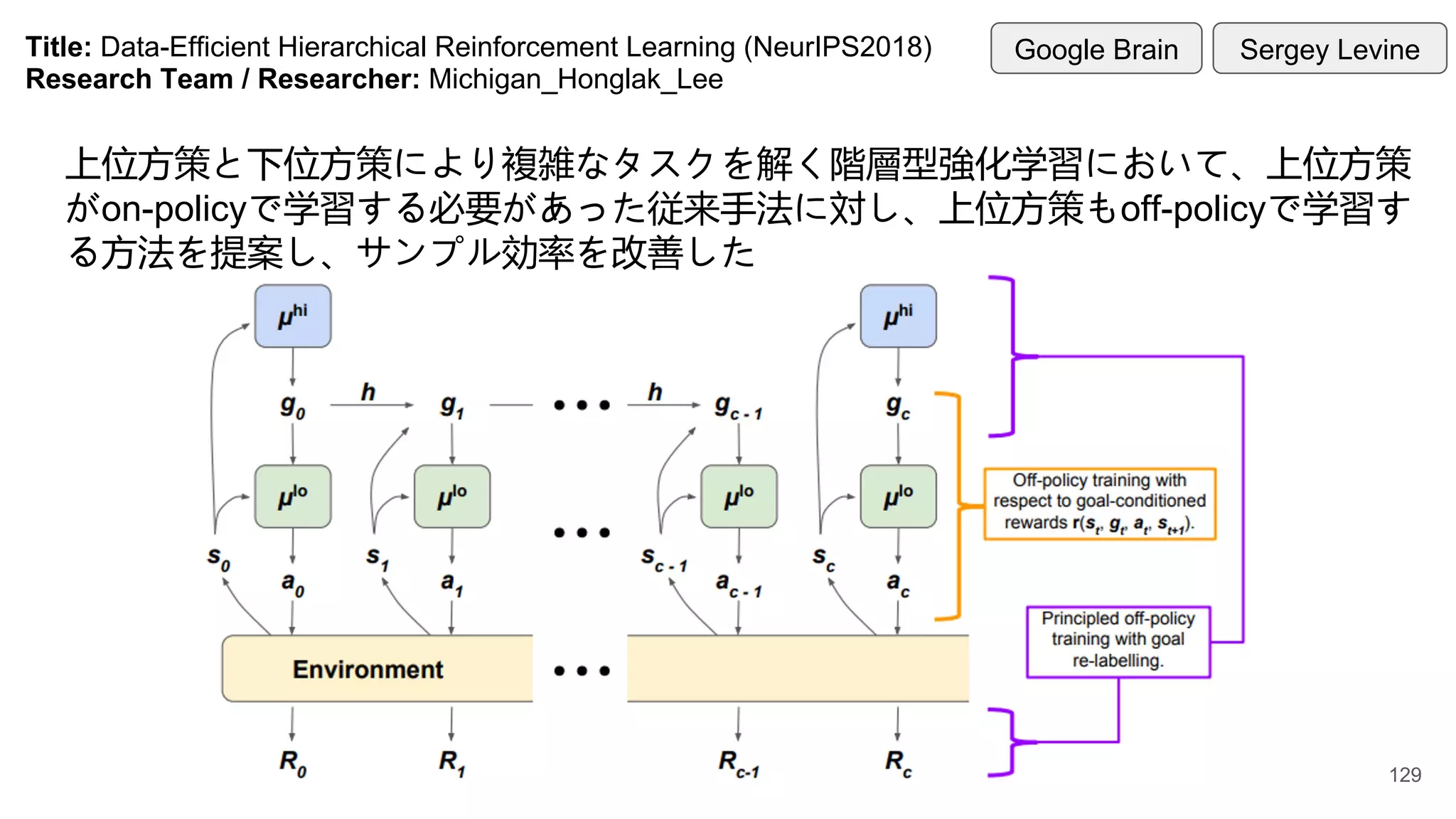
Title: Data-Efficient HierarchicalReinforcement Learning (NeurIPS2018)
Research Team / Researcher: Michigan_Honglak_Lee
上位方策と下位方策により複雑なタスクを解く階層型強化学習において、上位方策
がon-policyで学習する必要があった従来手法に対し、上位方策もoff-policyで学習す
る方法を提案し、サンプル効率を改善した
Google Brain Sergey Levine
129
130.
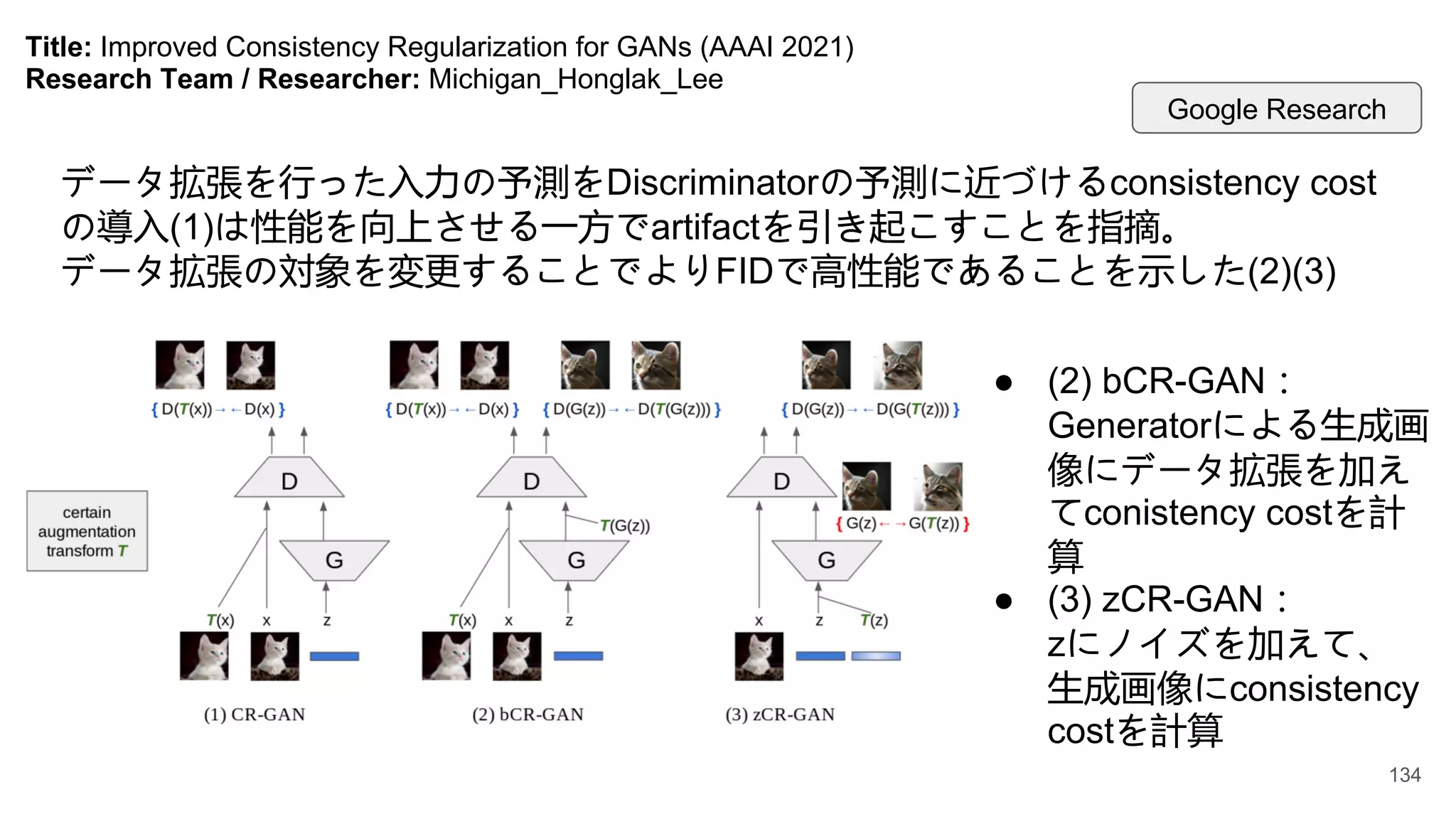
Title: Evolving ReinforcementLearning Algorithms (ICLR2021 oral)
Research Team / Researcher: Michigan_Honglak_Lee
概要:
モデルフリーの価値ベースRLエージェントを最適化するのに、損失関数を計
算する計算グラフ上をサーチするメタ学習強化学習を提案。
ドメインにによらず新しい環境への汎化が可能で、スクラッチ学習でも既存の
DQNなどと組み合わせることも可能。価値ベースの過大評価に対処するRLア
ルゴリズムと類似した傾向がある
Google Brain Sergey Levine
130
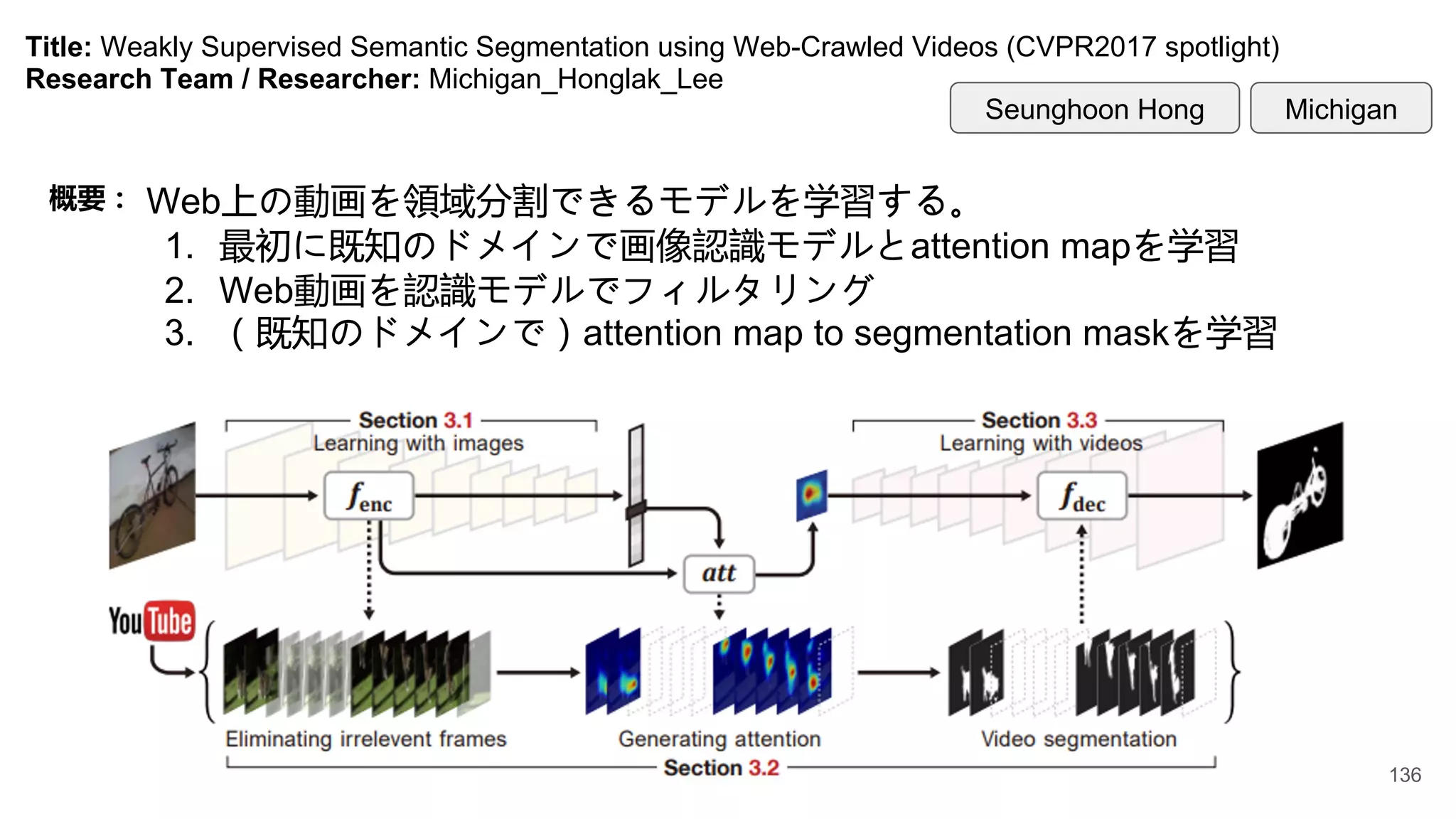
Title: Weakly SupervisedSemantic Segmentation using Web-Crawled Videos (CVPR2017 spotlight)
Research Team / Researcher: Michigan_Honglak_Lee
概要: Web上の動画を領域分割できるモデルを学習する。
1. 最初に既知のドメインで画像認識モデルとattention mapを学習
2. Web動画を認識モデルでフィルタリング
3. (既知のドメインで)attention map to segmentation maskを学習
Michigan
Seunghoon Hong
136
137.
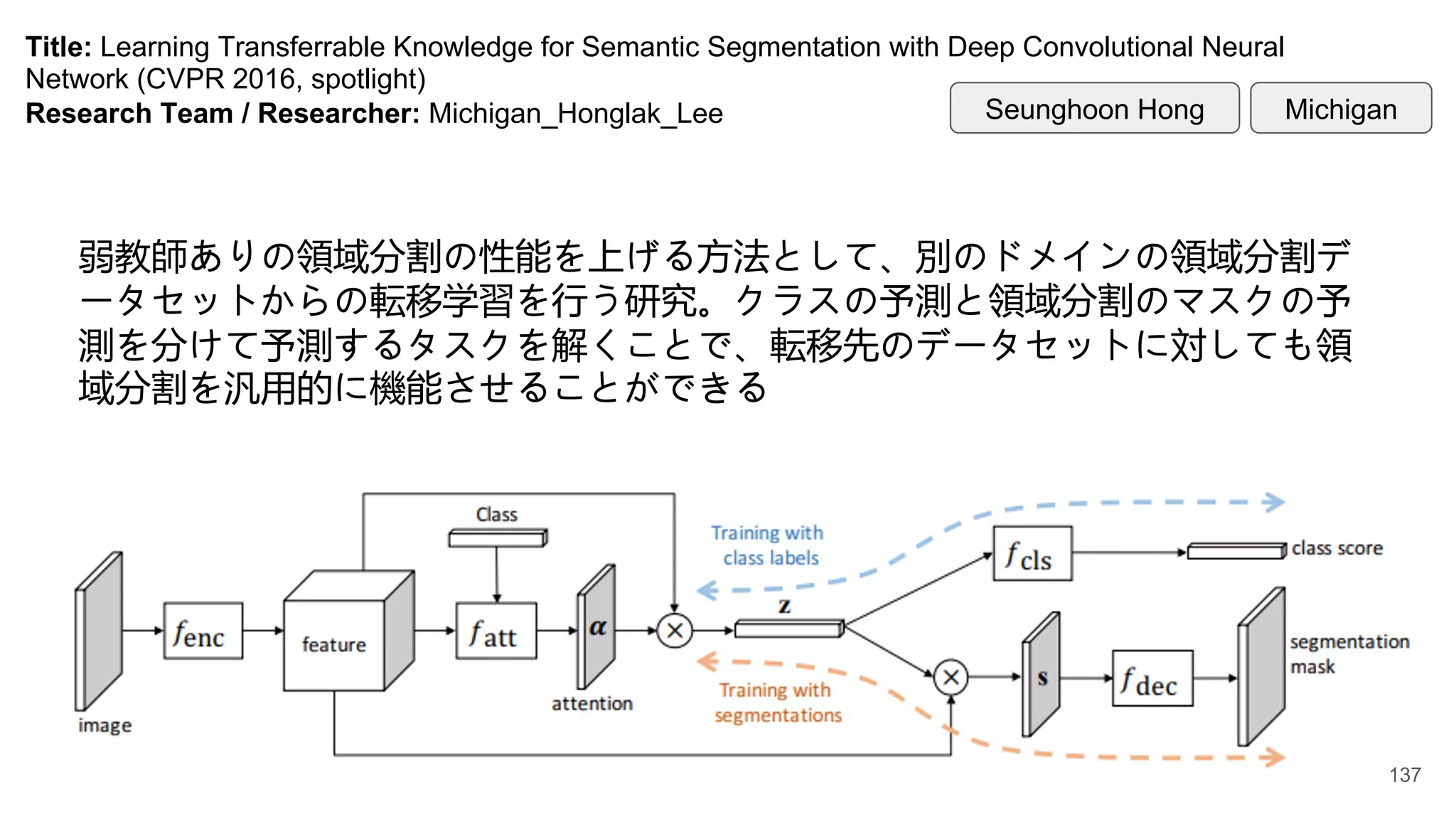
Title: Learning TransferrableKnowledge for Semantic Segmentation with Deep Convolutional Neural
Network (CVPR 2016, spotlight)
Research Team / Researcher: Michigan_Honglak_Lee
弱教師ありの領域分割の性能を上げる方法として、別のドメインの領域分割デ
ータセットからの転移学習を行う研究。クラスの予測と領域分割のマスクの予
測を分けて予測するタスクを解くことで、転移先のデータセットに対しても領
域分割を汎用的に機能させることができる
Michigan
Seunghoon Hong
137
138.
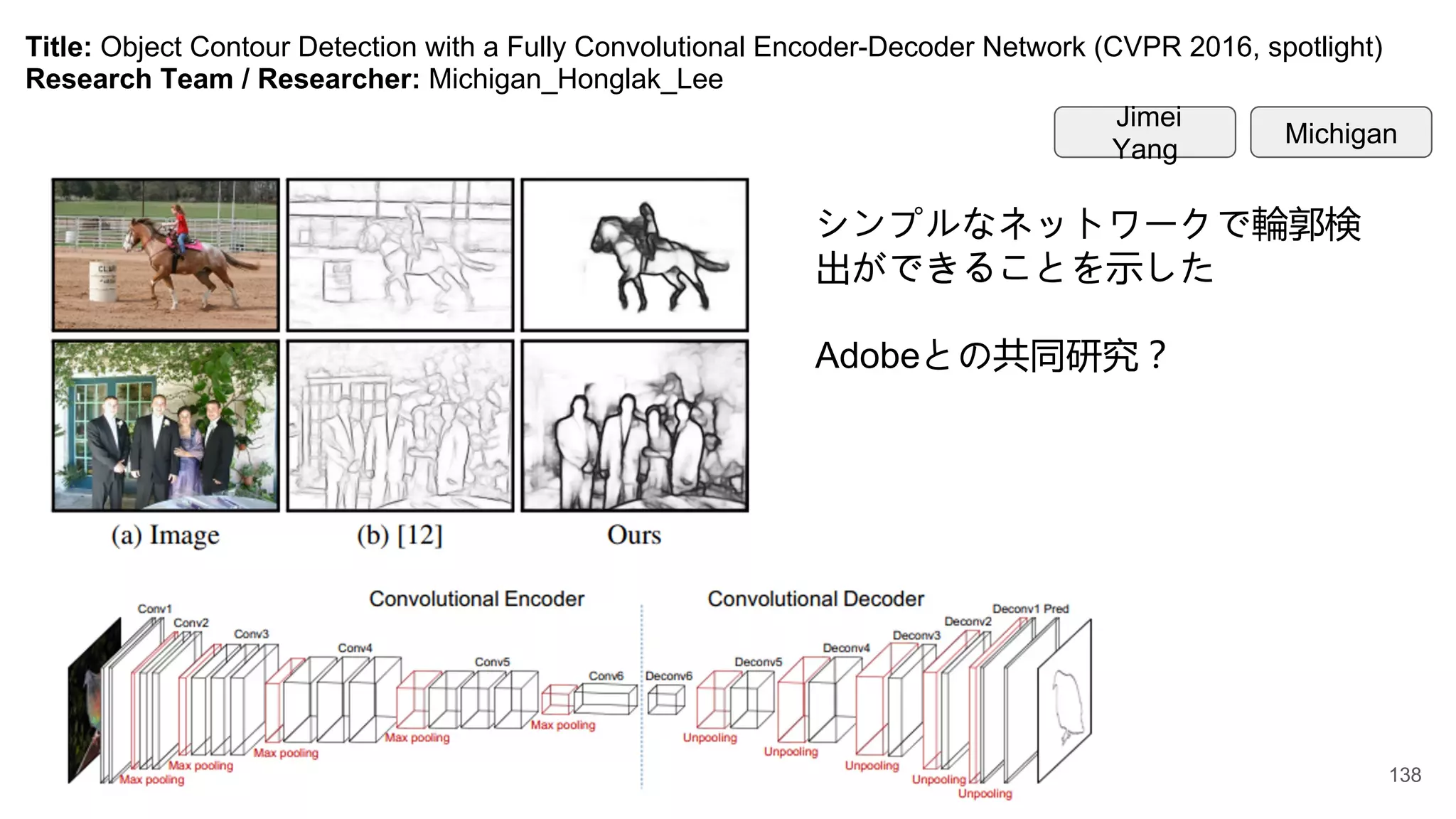
Title: Object ContourDetection with a Fully Convolutional Encoder-Decoder Network (CVPR 2016, spotlight)
Research Team / Researcher: Michigan_Honglak_Lee
シンプルなネットワークで輪郭検
出ができることを示した
Adobeとの共同研究?
Michigan
Jimei
Yang
138
139.
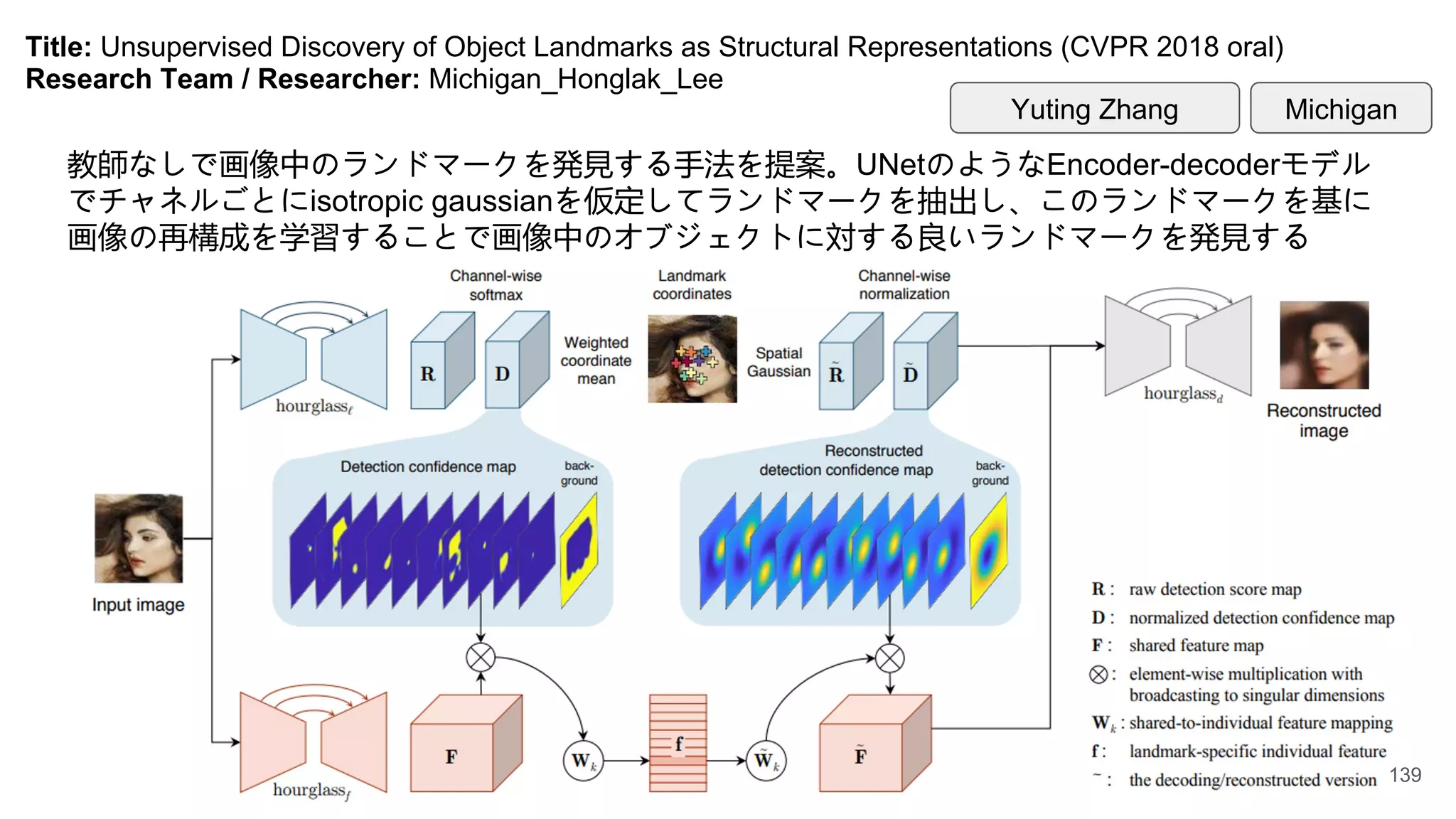
Title: Unsupervised Discoveryof Object Landmarks as Structural Representations (CVPR 2018 oral)
Research Team / Researcher: Michigan_Honglak_Lee
教師なしで画像中のランドマークを発見する手法を提案。UNetのようなEncoder-decoderモデル
でチャネルごとにisotropic gaussianを仮定してランドマークを抽出し、このランドマークを基に
画像の再構成を学習することで画像中のオブジェクトに対する良いランドマークを発見する
Michigan
Yuting Zhang
139
140.
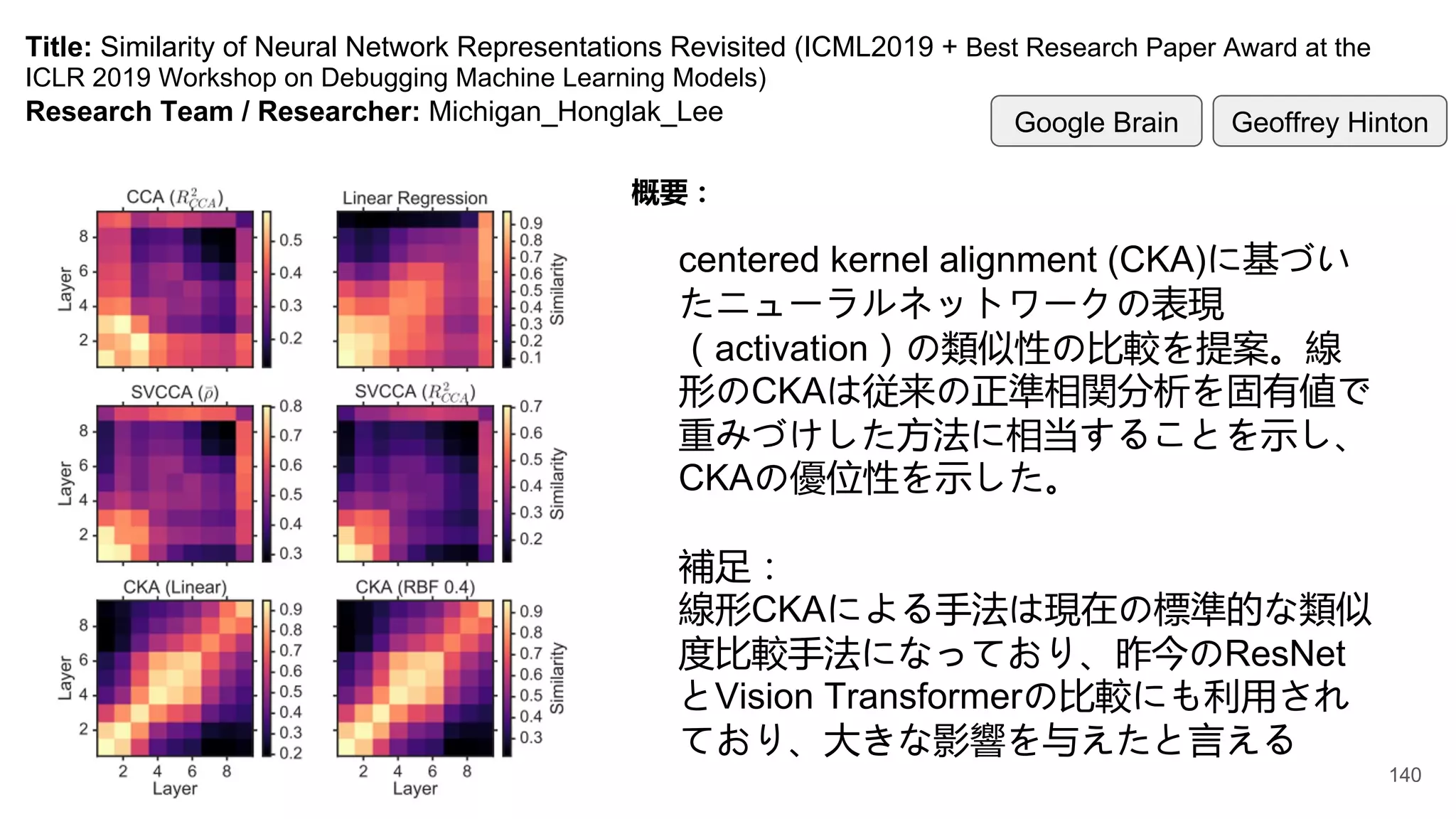
Title: Similarity ofNeural Network Representations Revisited (ICML2019 + Best Research Paper Award at the
ICLR 2019 Workshop on Debugging Machine Learning Models)
Research Team / Researcher: Michigan_Honglak_Lee
概要:
centered kernel alignment (CKA)に基づい
たニューラルネットワークの表現
(activation)の類似性の比較を提案。線
形のCKAは従来の正準相関分析を固有値で
重みづけした方法に相当することを示し、
CKAの優位性を示した。
補足:
線形CKAによる手法は現在の標準的な類似
度比較手法になっており、昨今のResNet
とVision Transformerの比較にも利用され
ており、大きな影響を与えたと言える
Google Brain Geoffrey Hinton
140
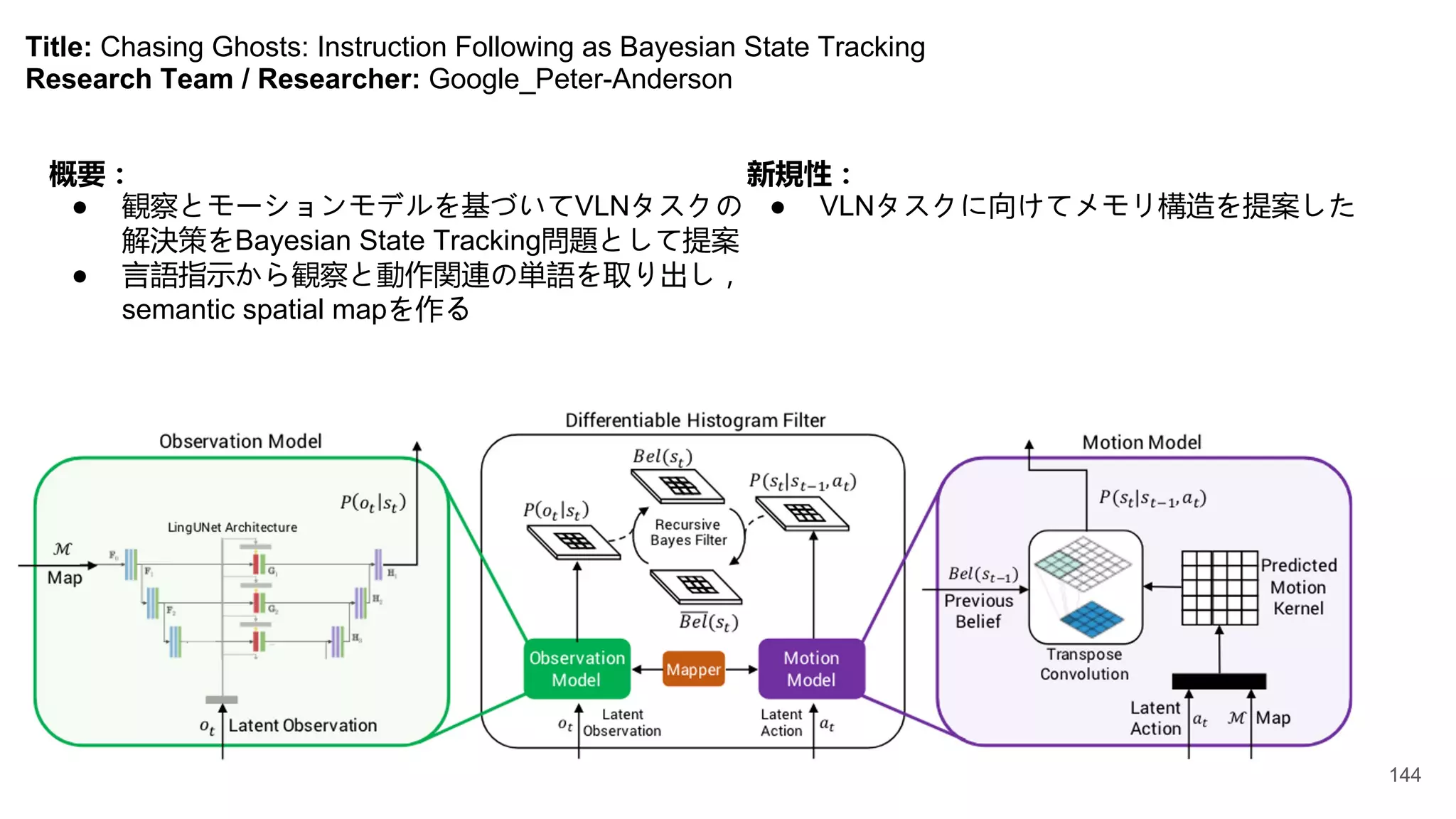
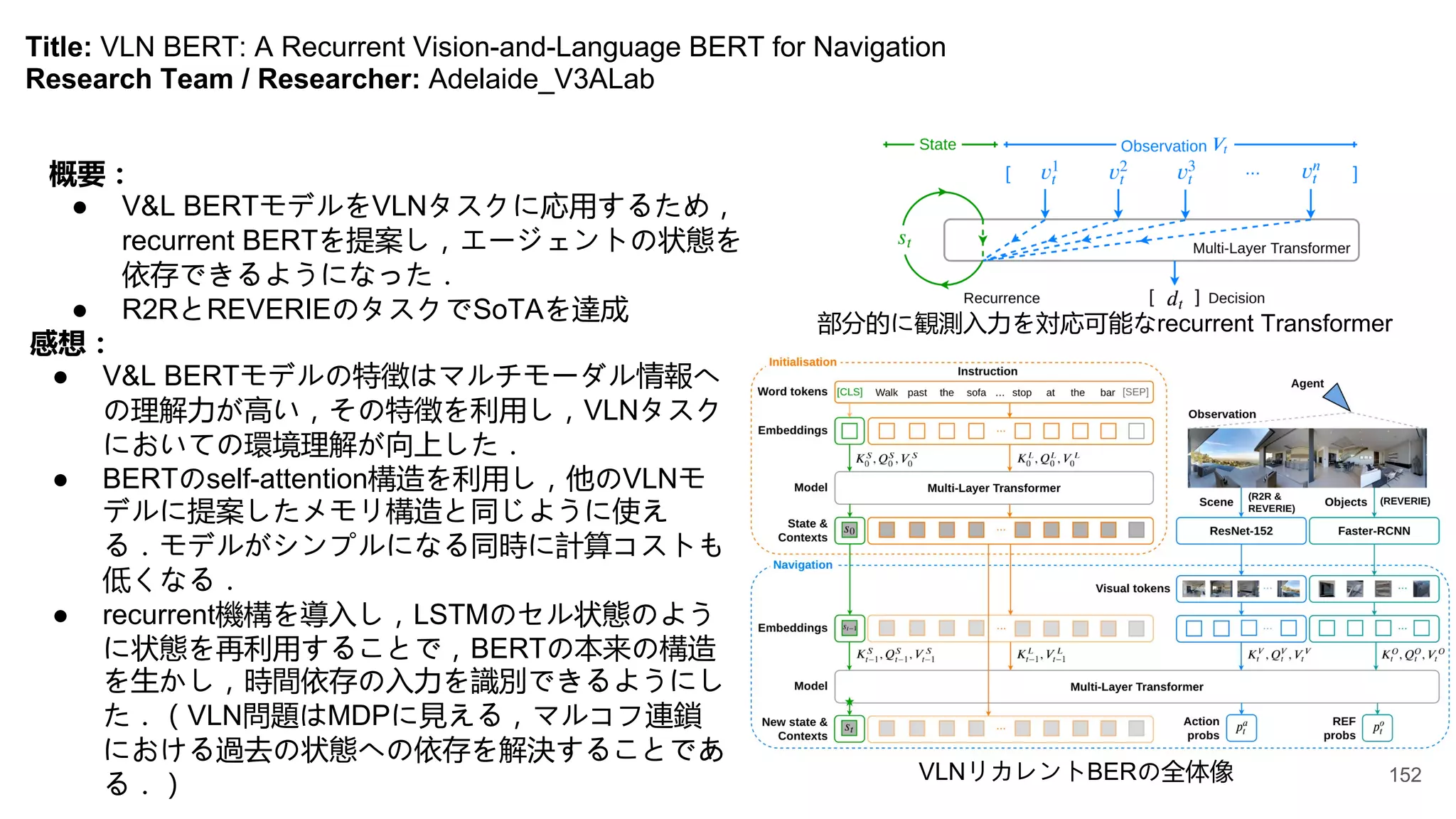
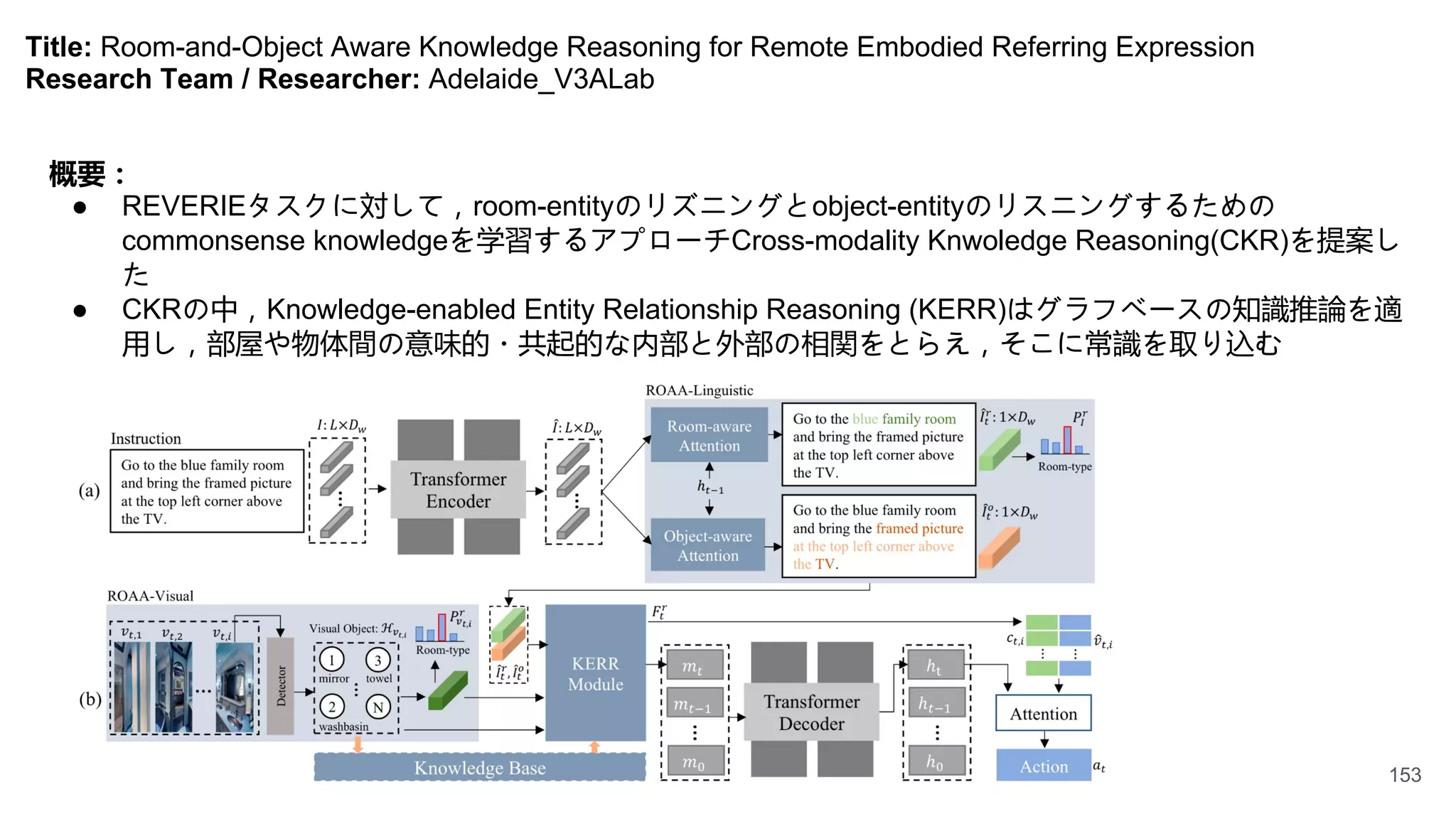
Title: Chasing Ghosts:Instruction Following as Bayesian State Tracking
Research Team / Researcher: Google_Peter-Anderson
概要:
● 観察とモーションモデルを基づいてVLNタスクの
解決策をBayesian State Tracking問題として提案
● 言語指示から観察と動作関連の単語を取り出し,
semantic spatial mapを作る
新規性:
● VLNタスクに向けてメモリ構造を提案した
144
145.
Title: Vision-and-Language Navigation:Interpreting visually-grounded navigation instructions in real environments
Research Team / Researcher: Google_Peter-Anderson
概要:
● vision langauge navigation(VLN):リアルな環境に
おけるエージェントは言語の指示に従って目的地
に辿り着くというタスクを提案した.
● ベンチマークRoom-to-Room(R2R)を構築した.
新規性:
● 新しくVision and Language系の研究のタスク
(VLN)を提案した.このタスクは,CV,NLP,
Robotics分野の結合で,非構造化かつ未知な実環
境でのreasoning能力を求める.
● 既存のVision and Language系の研究(VQA,
visual dialog etc)より,画像と自然言語両モダリ
ティ間の関係性をより深く理解する必要がある.
感想:
● 論文にはさまざまなベイスラインを提供され,
Seq2seqの手法でR2Rベンチマークを試した
結果,学習際に見なかったシーンに対する効
果が低下であることより,VLNタスクでは汎
用性のあるエージェントを学習させることが
重要である.
145
146.
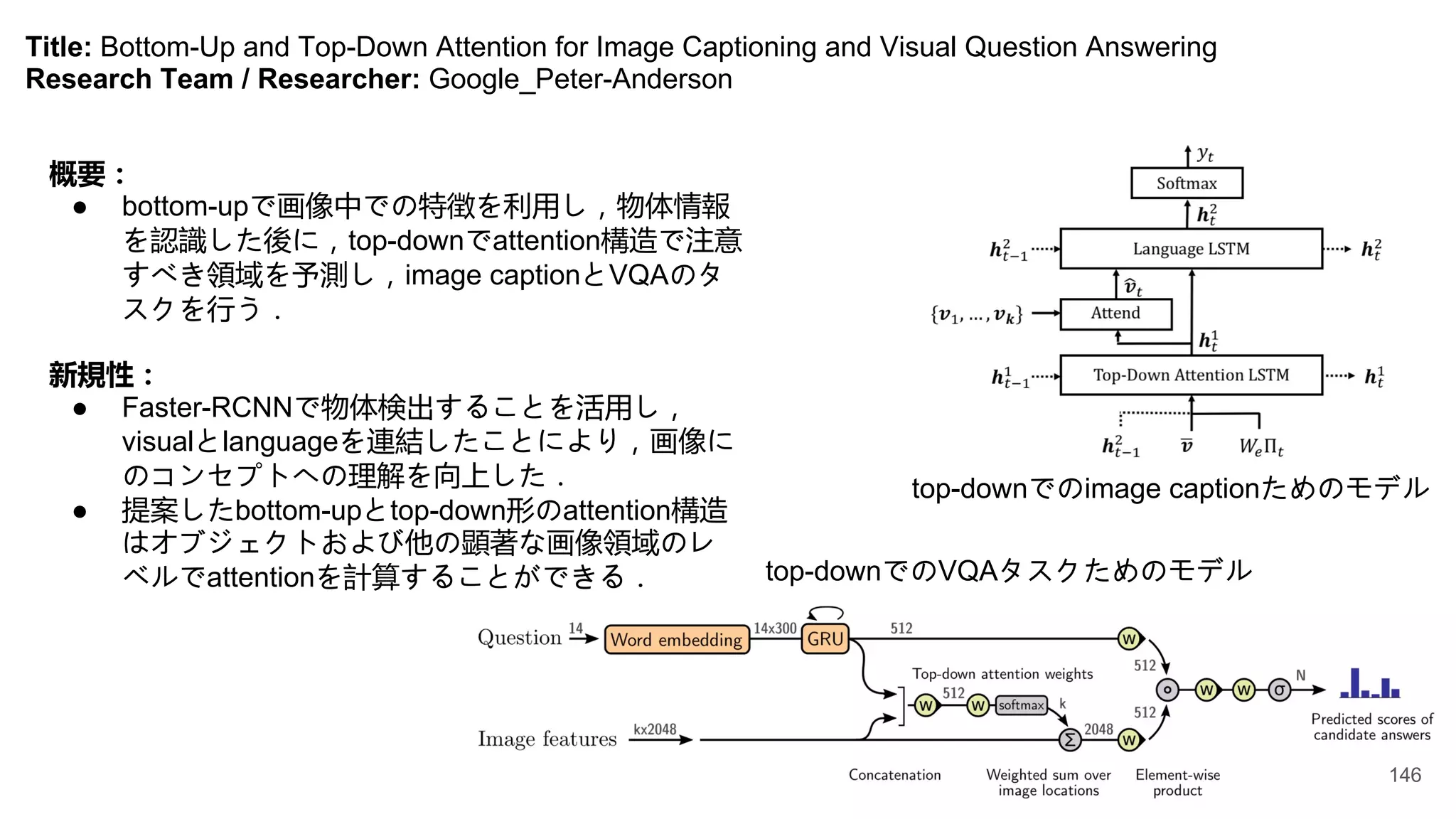
Title: Bottom-Up andTop-Down Attention for Image Captioning and Visual Question Answering
Research Team / Researcher: Google_Peter-Anderson
概要:
● bottom-upで画像中での特徴を利用し,物体情報
を認識した後に,top-downでattention構造で注意
すべき領域を予測し,image captionとVQAのタ
スクを行う.
新規性:
● Faster-RCNNで物体検出することを活用し,
visualとlanguageを連結したことにより,画像に
のコンセプトへの理解を向上した.
● 提案したbottom-upとtop-down形のattention構造
はオブジェクトおよび他の顕著な画像領域のレ
ベルでattentionを計算することができる. top-downでのVQAタスクためのモデル
top-downでのimage captionためのモデル
146
147.
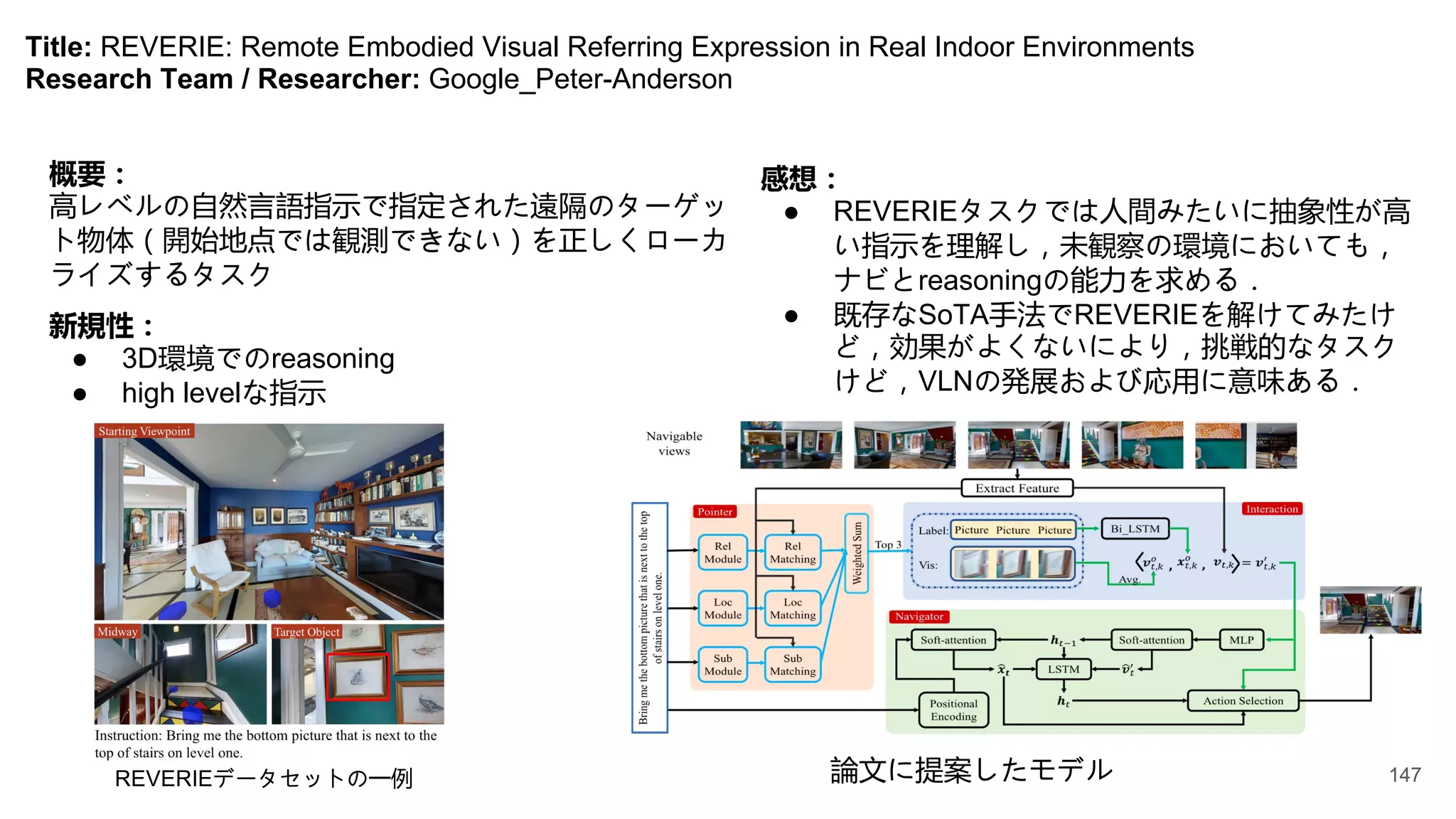
Title: REVERIE: RemoteEmbodied Visual Referring Expression in Real Indoor Environments
Research Team / Researcher: Google_Peter-Anderson
概要:
高レベルの自然言語指示で指定された遠隔のターゲッ
ト物体(開始地点では観測できない)を正しくローカ
ライズするタスク
新規性:
● 3D環境でのreasoning
● high levelな指示
論文に提案したモデル
REVERIEデータセットの一例
感想:
● REVERIEタスクでは人間みたいに抽象性が高
い指示を理解し,未観察の環境においても,
ナビとreasoningの能力を求める.
● 既存なSoTA手法でREVERIEを解けてみたけ
ど,効果がよくないにより,挑戦的なタスク
けど,VLNの発展および応用に意味ある.
147
148.
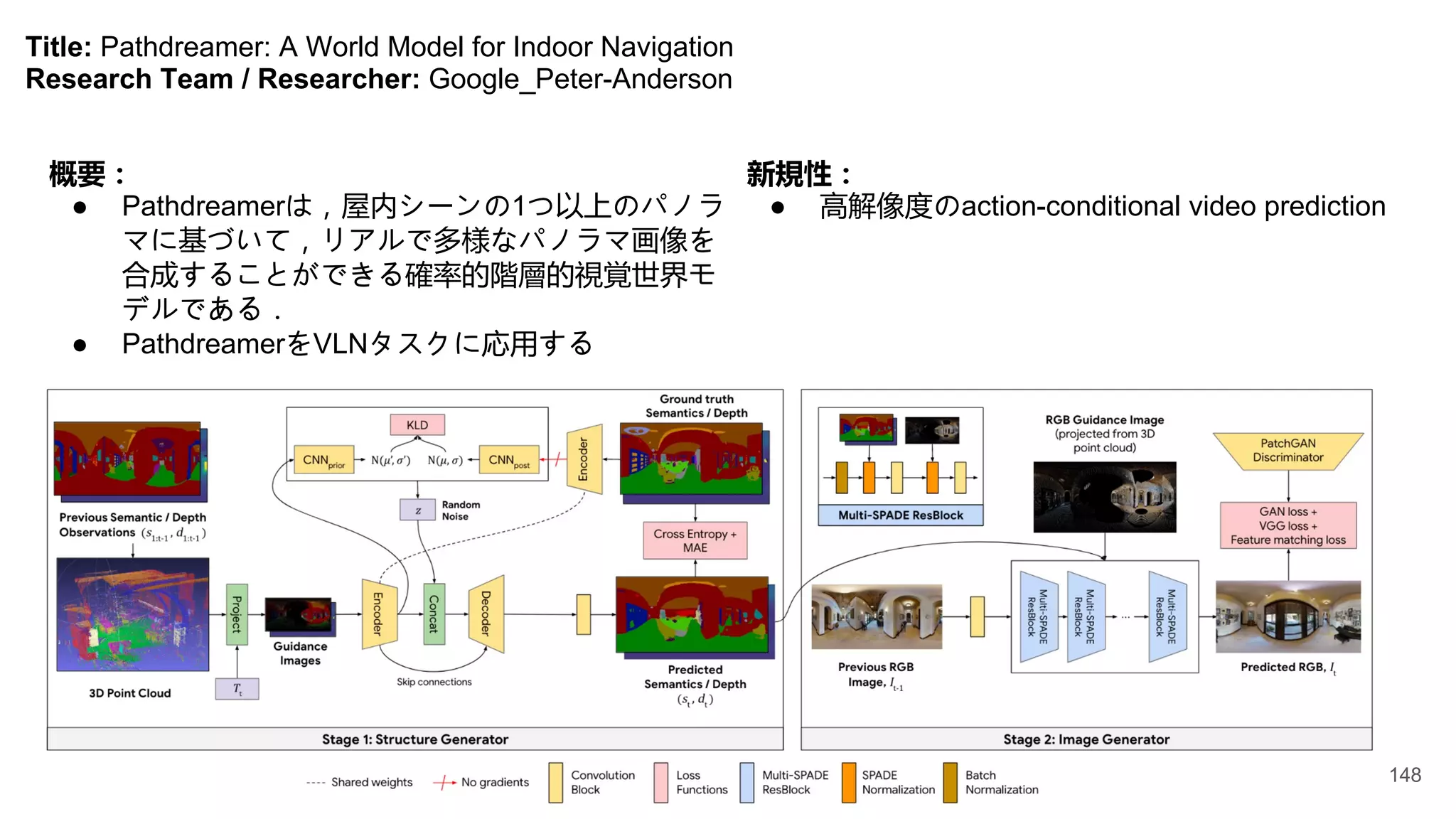
Title: Pathdreamer: AWorld Model for Indoor Navigation
Research Team / Researcher: Google_Peter-Anderson
概要:
● Pathdreamerは,屋内シーンの1つ以上のパノラ
マに基づいて,リアルで多様なパノラマ画像を
合成することができる確率的階層的視覚世界モ
デルである.
● PathdreamerをVLNタスクに応用する
新規性:
● 高解像度のaction-conditional video prediction
148



























































![Honglak Lee (ミシガン大学, LG AI Research)
兼務:2016 Google Brain→2020 LG AI Research
スタンフォード大学:(指導教員はAndrew Ng)
● Ph.D. (2010): Computer Science
● M.S. (2006): Computer Science, Applied Physics
ソウル国立大学:
● B.S. (2003): Physics, Computer Science
画像は[1]より引用
[1] https://web.eecs.umich.edu/~honglak/
主戦場の分野:強化学習、CV、V&L、NLP
貢献が多いトピック:
● 教師なし、弱教師ありの表現学習
● (主に弱教師あり)領域分割
● GANを用いた画像生成・画像変換
● GANの正則化手法
選定理由(品川):
研究室の規模は10名弱とそれほど
多くないものの、メンバー全体が
機械学習トップ会議の常連であり、
質の高い論文が多く、学べるもの
が多そうだと考えたため。 102](https://image.slidesharecdn.com/visionandlanguage-220830002316-2e078cd0/75/Vision-and-Language-102-2048.jpg)
![活躍している分野(採択先別、ジャーナル、workshop含む)
個人サイトにある掲載論文[1] 124件 (2005-2021)の論文を集計した
多い会議
● 表現学習や強化学
習(NeurIPS, ICML,
ICLR)
● CV系(CVPR,
ECCV, ICCV)
NeurIPS (5月投稿締
切)→ICLR (9月) or
CVPR (11月) → ICML
or IJCAI (1月)
という研究サイクル?
103](https://image.slidesharecdn.com/visionandlanguage-220830002316-2e078cd0/75/Vision-and-Language-103-2048.jpg)
![活躍している分野(研究テーマ別)
個人サイトにある掲載論文[1] 124件 (2005-2021)の論文を集計した
強化学習や表現学習が大
部分だが、関連技術とし
て画像(動画)生成・変
換系の話や、その道具と
して主流であるGANの工
夫の話も多い。
強化学習
表現学習
深層生成
モデル
104](https://image.slidesharecdn.com/visionandlanguage-220830002316-2e078cd0/75/Vision-and-Language-104-2048.jpg)































![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]MetaFormer is Actually What You Need for Vision](https://cdn.slidesharecdn.com/ss_thumbnails/20220121metaformer-220121085750-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://cdn.slidesharecdn.com/ss_thumbnails/swintransformer-210514020542-thumbnail.jpg?width=640&height=640&fit=bounds)



















![[DL輪読会]Experience Grounds Language](https://cdn.slidesharecdn.com/ss_thumbnails/20200515iwasawa-200515060537-thumbnail.jpg?width=640&height=640&fit=bounds)












