Download as PDF, PPTX


![ AlexNet [Krizhevsky+ 12] 以来,様々な分野で成果を発揮
4
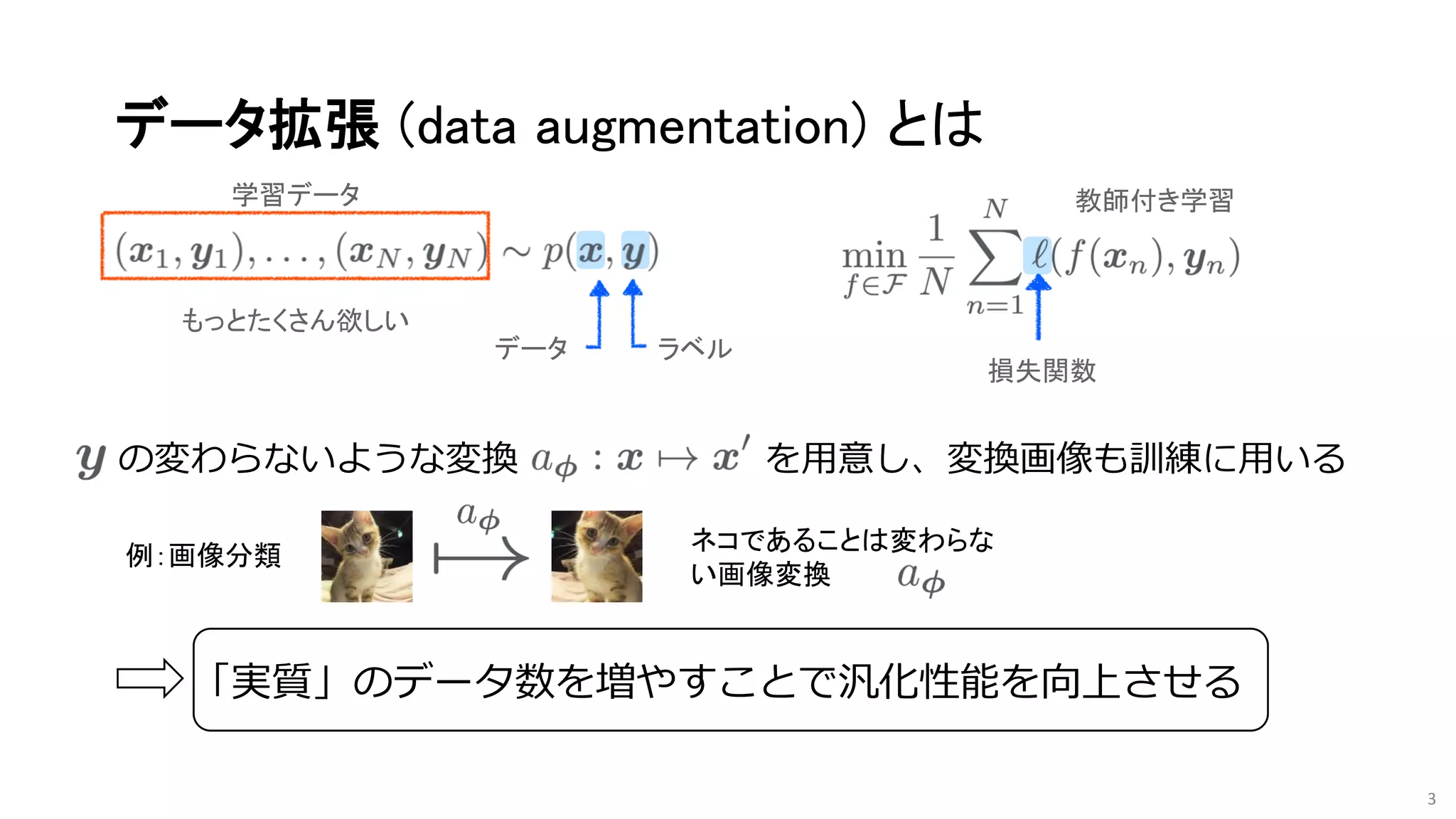
深層学習とデータ拡張
[Baird 93]
[Yeager+ 96]
[Simard+ 91]
90年代から文字認識のために利用されてきた
AlexNetは6,000万のパラメータがあり,120万枚の画像に過適合する
データ拡張+Dropoutによる正則化が重要](https://image.slidesharecdn.com/os2-03latest-210610045610/75/SSII2021-OS2-02-4-2048.jpg)
![表現学習への応用
5
FixMatch [Sohn+20]
各クラスに4枚しかラベル
付き画像がなくても90%
近い精度
近づける
SimCLR [Chen+20]
近づける 遠ざける
ラベルなしでも教師あり
学習に近い表現を獲得
意味に対して不変な変換後の画像の特徴表現が近くなるように
特徴抽出ネットワークを学習 [Bengio +13]
半教師あり学習: ラベルが一部しかない設定で学習
自己教師あり学習: ラベルがない設定で良い表現を学習](https://image.slidesharecdn.com/os2-03latest-210610045610/75/SSII2021-OS2-02-5-2048.jpg)
![他分野での例(自然言語処理)
Easy Data Augmentation [Wei&Zou 19]
特にデータ少ない場合に有効
構文木の利用 [Şahin&Steedman 18] 「切り抜き」:主要でない木の部位を削除
「回転」:順番を入れ替え
6](https://image.slidesharecdn.com/os2-03latest-210610045610/75/SSII2021-OS2-02-6-2048.jpg)

![画像データ拡張のアプローチ①:経験的な変換
8
基本的な画像処理
0.7 ネコ
0.3 + 0.7
0.3 イヌ
反転 クロップ 平行移動 回転 色調変化
mixup [Zhang+ 18] [Tokozume+, 18]
◦ 二枚の画像とラベルを線形に混合
Cutout [DeVries+ 17] [Zhong+, 17]
◦ ランダムに画像の一部を矩形でマスク](https://image.slidesharecdn.com/os2-03latest-210610045610/75/SSII2021-OS2-02-8-2048.jpg)
![画像データ拡張のアプローチ②:生成モデルの利用
9
画像生成モデルの発展 e.g., BigGAN [Brock+ 19]
実は生成画像
注:画像生成によるデータ拡張はまだ十分に確立されてはいない
◦ 特に、生成画像は高周波成分が実画像と異なる [Daznic+ 20]
→ そのままではデータ拡張には不向き? [Ravuri&Vinyals 19]](https://image.slidesharecdn.com/os2-03latest-210610045610/75/SSII2021-OS2-02-9-2048.jpg)
![画像データ拡張のアプローチ②:生成モデルの利用
1
0
視線推定タスクでの性能向上
シミュレータとの組合せ [Shrivastava+ 17]
◦ CG画像を実画像へ変換
条件付きGANの利用 [Han+ 19]
◦ 位置・大きさ等を指定した
腫瘍画像生成
いずれの場合も、元の画像データセット
以外の情報を入れていることが重要
1
0](https://image.slidesharecdn.com/os2-03latest-210610045610/75/SSII2021-OS2-02-10-2048.jpg)


![データ拡張戦略の自動設計
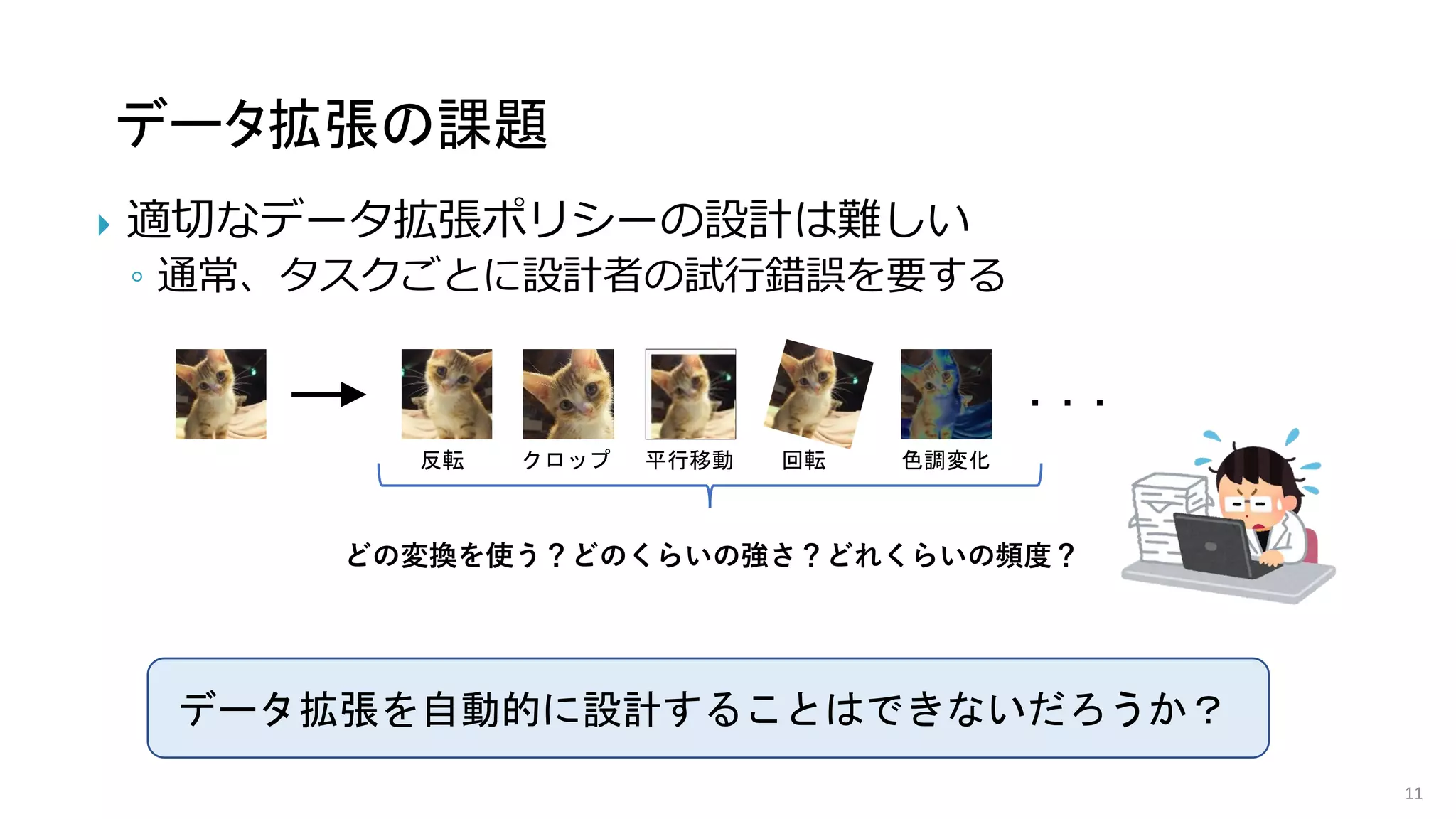
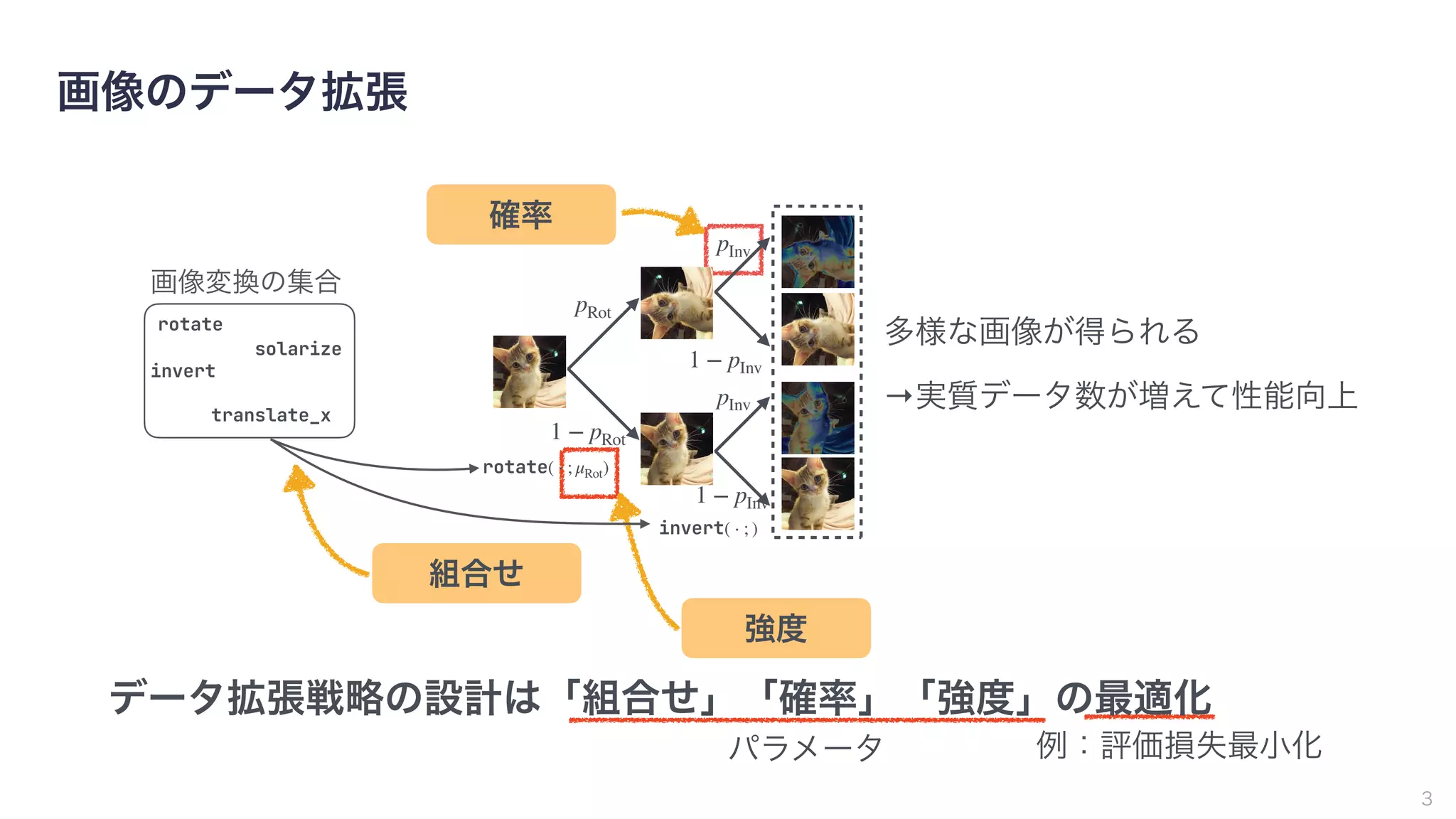
4
非常に広大な探索空間
∼ の可能な組合せ
→ 強化学習やベイズ最適化などの利用
1032
1064
CNNの学習に時間がかかる
→小さなCNNや学習データの一部のみの使用で代用
ただしAutoAugmentは探索が高コスト
CIFAR-10 Baseline AA
error rates 3.1 2.6
AutoAugment [Cubuk+19]
(CIFAR-10には5000GPU時間)
→ 高速化の研究が進められてきた](https://image.slidesharecdn.com/os2-03latest-210610045610/75/SSII2021-OS2-02-15-2048.jpg)
![データ拡張戦略の自動設計
5
非常に広大な探索空間
∼ の可能な組合せ
→ 強化学習やベイズ最適化などの利用
1032
1064
CNNの学習に時間がかかる
→小さなCNNや学習データの一部のみの使用で代用
ただしAutoAugmentは探索が高コスト
CIFAR-10 Baseline AA
error rates 3.1 2.6
AutoAugment [Cubuk+19]
(CIFAR-10には5000GPU時間)
→ 高速化の研究が進められてきた
→ 戦略を微分可能にすることで
勾配降下法による高速化
→CNNの学習の繰り返しを
避けることで高速化
Faster AutoAugmentは
精度劣化なしに15分程度で探索可能
Faster AutoAugment [Hataya+2020]](https://image.slidesharecdn.com/os2-03latest-210610045610/75/SSII2021-OS2-02-16-2048.jpg)
![6
戦略
元画像 変換後の画像
分布間距離
誤差逆伝播
+ 分類損失
元画像と変換後の画像を近づける 変換がクラスを変えないように制限
強度
確率
組合せ
pRot
1 − pRot
rotate( ⋅ ; μRot)
pInv
1 − pInv
invert( ⋅ ; )
pInv
1 − pInv
solarize
rotate
translate_x
invert
画像変換の集合
solarize
Faster AutoAugment [Hataya+2020]](https://image.slidesharecdn.com/os2-03latest-210610045610/75/SSII2021-OS2-02-17-2048.jpg)
![Faster AutoAugment [Hataya+2020]
• データ拡張の目的は分布の一致
7
元画像の分布 変換画像の分布
データ拡張では変換画像によって
元画像分布の欠損を補いたい
• GANの損失の応用
戦略
元画像 変換後の画像
元画像 or 変換画像?
誤差逆伝播](https://image.slidesharecdn.com/os2-03latest-210610045610/75/SSII2021-OS2-02-18-2048.jpg)
![実験結果
• 探索時間の比較 (GPU時間)
• 戦略の性能比較(テスト誤差率)*
8
Dataset AA Fast AA Faster AA
CIFAR-10 5,000 3.5 0.23
SVHN 1,000 1.5 0.061
ImageNet 15,000 450 2.3
Dataset Baseline AA Fast AA Faster AA
CIFAR-10 3.1 2.6 2.7 2.6
CIFAR-100 18.8 17.1 17.3 17.3
SVHN 1.3 1.1 1.1 1.2
ImageNet 23.7 22.4 22.4 22.7
Faster AutoAugmentは極めて高速に探索が可能
Faster AutoAugmentの戦略は先行研究とほぼ同等
* ImageNetではResNet-50 [He+16],そのほかのデータでは WRN28-10 [Zagoruyko&Komodakis 17] を使用
AA:AutoAugment [Cubuk+ 2019]
Fast AA:Fast AutoAugment [Lim+ 2019]](https://image.slidesharecdn.com/os2-03latest-210610045610/75/SSII2021-OS2-02-19-2048.jpg)
![実験結果
9
Dataset ランダム Faster AA
CIFAR-100 21.6 20.9
戦略の学習は必要?*
Dataset 分類損失なし Faster AA
CIFAR-100 21.5 20.9
分類損失は必要?*
* WRN40-2 [Zagoruyko&Komodakis 17] を使用
戦略
元画像 変換後の画像
分布間距離
誤差逆伝播
+ 分類損失
元画像と変換後の画像を近づける 変換がクラスを変えないように制限](https://image.slidesharecdn.com/os2-03latest-210610045610/75/SSII2021-OS2-02-20-2048.jpg)


SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向 6月10日 (木) 11:00 - 12:30 メイン会場(vimeo + sli.do) 登壇者1:中山 英樹 氏(東京大学) 登壇者2:幡谷 龍一郎 氏(東京大学) 概要:データ拡張は画像認識の精度向上テクニックとして古くから用いられてきたが、最新の深層学習においても最重要技術の一つとして年々注目を集めており、多様かつ複雑な進化を遂げている。その成功のカギは、タスクに関する先見知識を活用しながら、如何にして汎化性能を高めるように訓練画像を変換あるいは生成するかにある。本講演では、データ拡張の原理や最新動向について解説すると共に、自動的なデータ拡張に関する講演者の研究事例についても紹介する。

![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)











![[DL輪読会]AutoAugment: LearningAugmentation Strategies from Data & Learning Data...](https://cdn.slidesharecdn.com/ss_thumbnails/dlp0712f-190719034120-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)












![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [TS3] コンテンツ制作を支援する機械学習技術〜 イラストレーションやデザインの基礎から最新鋭の技術まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts32022ssiiess-220607054523-e80be8dc-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [TS2] 自律移動ロボットのためのロボットビジョン〜 オープンソースの自動運転ソフトAutowareを解説 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2ssii2022r4-220607054405-1c6b5fc2-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [OS3-04] Human-in-the-Loop 機械学習](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-04-220607021031-e69700d5-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [OS3-03] スケーラブルなロボット学習システムに向けて](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-03-220607020929-1e2b15e8-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [OS3-02] Federated Learningの基礎と応用](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-02-220607020834-2b5f93ff-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [OS3-01] 深層学習のための効率的なデータ収集と活用](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-01-220607020740-e80781dc-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [OS2-01] イメージング最前線](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os2-1-220607020403-b550c379-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [OS1-01] AI時代のチームビルディング](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os1-01-220607015404-49188612-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [SS2] Deepfake Generation and Detection – An Overview (ディープフェイクの生成と検出)](https://cdn.slidesharecdn.com/ss_thumbnails/ss2-01-210607043612-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...](https://cdn.slidesharecdn.com/ss_thumbnails/ss1-01-210607043349-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [TS3] 機械学習のアノテーションにおける データ収集 〜 精度向上のための仕組み・倫理や社会性バイアス 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts3-01-210607043121-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [TS1] Visual SLAM ~カメラ幾何の基礎から最近の技術動向まで~](https://cdn.slidesharecdn.com/ss_thumbnails/ts1-01-210607042113-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS3-03] 画像と点群を用いた、森林という広域空間のゾーニングと施業管理](https://cdn.slidesharecdn.com/ss_thumbnails/os3-04-210605062524-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS3-02] BIM/CIMにおいて安価に点群を取得する目的とその利活用](https://cdn.slidesharecdn.com/ss_thumbnails/os3-03-210605062350-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS3-01] 設備や環境の高品質計測点群取得と自動モデル化技術](https://cdn.slidesharecdn.com/ss_thumbnails/os3-02-210605062048-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS3] 広域環境の3D計測と認識 ~ 人が活動する場のセンシングとモデル化 ~(オーガナイザーによる冒頭の導入)](https://cdn.slidesharecdn.com/ss_thumbnails/os3-01-210605061816-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS2-03] 自己教師あり学習における対照学習の基礎と応用](https://cdn.slidesharecdn.com/ss_thumbnails/os2-04-210605061641-thumbnail.jpg?width=640&height=640&fit=bounds)