Download as PDF, PPTX

















































































![3D-aware な画像のシーン分解・生成
96
● [NoName] Y. Liao et al. Towards unsupervised learning of generative models for 3d controllable image synthesis. CVPR2020.
https://arxiv.org/abs/1912.05237
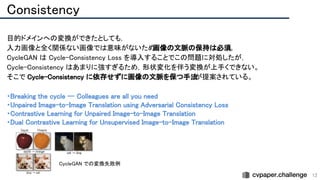
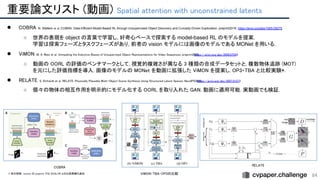
○ 画像のみを用いて 3D の操作が可能な画像を合成する 3D controllable image synthesis のタスクを定義.
物体・背景ごとに 3D の表現を生成し, 2D へレンダリング・2D で生成をすることで, 画像を合成する GAN.
● BlockGAN T. Nguyen-Phuoc et al. BlockGAN: Learning 3D Object-aware Scene Representations from Unlabelled Images. NeurIPS2020.
https://arxiv.org/abs/2002.08988
○ 前景の各物体・背景を分けて 3D 特徴空間でモデリングし, 射影することで画像を生成.
3D の表現は, 3D grid の特徴量と物体の姿勢を用いて行われる. 学習は 2D の画像のみから行う.
● GIRAFFE M. Niemeyer et al. GIRAFFE: Representing Scenes as Compositional Generative Neural Feature Fields. CVPR2021. https://arxiv.org/abs/2011.12100v1
○ 各物体の NeRF による3D 表現を GAN に組み込み, 制御可能で写実的な画像を合成.
カメラ姿勢もノイズからサンプリングし, 学習は 2D の画像のみから行う.
● ObSuRF K. Stelzner et al. Decomposing 3D Scenes into Objects via Unsupervised Volume Segmentation. preprint 2021. https://arxiv.org/abs/2104.01148
○ 画像を slot ベースの encoder で物体ごとの潜在変数を獲得し, この潜在変数で条件づけられた NeRF で画像をレンダリング.
NeRF の ray marching をポアソン過程とみなし, 深度を教師とすることで, 新しい loss を提案.
これにより, RGB-D 画像に対する NeRF の訓練を計算効率よく行う.
BlockGAN
GIRAFFE
ObSuRF
[NoName]](https://image.slidesharecdn.com/generationsgan-relation-210527023826/85/slide-96-320.jpg)












![Domain Adaptation
109
教師なし転移学習(厳密には,Transductive Transfer Learning) の一種
教師あり転移学習 (fine-tuning) と異なり,Domain Adaptationではターゲットドメインに教師
ラベルを仮定しない
タスクは,クラス分類,物体検出,セグメンテーションなど
[L. Zhang, arXiv’19.]](https://image.slidesharecdn.com/generationsgan-relation-210527023826/85/slide-109-320.jpg)


![特徴量ベース手法
112
1. 分布間距離の最小化
MMD等の分布間の統計量をもとに誤差を算出する
ドメイン間でCNNの深い層の特徴量平均を整合させ,
周辺分布のマッチングをする
2. 敵対的学習による整合
ドメイン識別器はどちらのドメインの特徴量か
見分け,特徴抽出器はドメイン不変の特徴を
生成するように学習する
3. 正規化層を利用
ドメイン毎でバッチ正規化することで,特徴量
を整合させる
[E. Tzeng+, arXiv’14]
分離した特徴抽出器から敵対的学習
[E. Tzeng+, CVPR’17]
共通の特徴抽出器から敵対的学習
[Y. Ganin+, ICML’15]
[Y. Li+, ICLRW’17]
ドメイン識別器 (赤点線)](https://image.slidesharecdn.com/generationsgan-relation-210527023826/85/slide-112-320.jpg)
![生成ベース手法
113
1. CycleGANを使用 [J. Hoffman+, ICLR’18]
2. Style Transferを使用 [M. Kim+, CVPR’20]
ターゲット→ソースへ画
像変換
ソース→ターゲットへ画
像変換
擬似ターゲットデータを
真のターゲット分布へ近づける
(ピクセルレベル)
擬似ターゲットデータを
真のターゲット分布へ近づける
(特徴量レベル)](https://image.slidesharecdn.com/generationsgan-relation-210527023826/85/slide-113-320.jpg)
![自己学習ベース手法
114
擬似ラベリング [D.H Lee, ICMLW’13]
クラス情報も含めて特徴空間を学習できる
2体の分類器による合議による擬似ラベルの決定 [K. Saito+, ICML’17]
その他: クラス毎の確信度に応じて擬似ラベルの学習を調整
[Y. Zou+, ECCV’18]
クラスタリングによる擬似ラベリングとそのカリキュラム学習
[C, Chen+, CVPR’19]
自己教師タスクも追加で学習 [Y. Sun+, arXiv’19]
その他: エントロピー最小化を導入する [Y. Zou+, NeurIPS’16,
T.H. Vu+, CVPR’19]
データ拡張をもとに拡張前後の一貫性を導入 [Y. Sun+, NeurIPS’20]
擬似ラベルをもとにクラス条件付き分布を計算し,MMDでマッチ
ング [M. Long+, ICCV’13]](https://image.slidesharecdn.com/generationsgan-relation-210527023826/85/slide-114-320.jpg)
![Domain Adaptationの限界
データ・アルゴリズム上の制約と実世界制約とのギャップ
1. べらぼうに大きなドメインシフト には対処できない
→ Negative Transfer (i.e., 適応の失敗) が生じ,その発生が事前に見積もれない
アルゴリズムの良し悪し,データの品質,ドメインシフトの大きさに依存 [Z. Wang+, CVPR’19, W. Zhang+, TKDE’20]
2. ラベル空間と分布に関する仮定は強くないか!?
(再掲: 共通のラベル空間かつラベリングは共通 :
→ ラベル分布の相違を考慮したDomain Adaptation
(e.g., Target shift [K. Zhang+, ICML’13, R. Takahashi+, ECCV’20])
→ ラベル空間の相違を考慮したDomain Adaptation
(e.g., Partial DA [Z. Cao+, CVPR’18, J. Zhan+, CVPR’18], Open-set DA [Busto+, ICCV‘17, K. Saito+, ECCV’18],
Universal DA [Y. You+, CVPR’19, Q. Yu+, CVPR’21])](https://image.slidesharecdn.com/generationsgan-relation-210527023826/85/slide-115-320.jpg)
![Domain Adaptationの派生形と周辺分野との融合
116
▪ ターゲットに少数の教師ラベルを仮定 (半教師あり [Saito+, ICCV’19], Few shot [S. Motiian+, NeurIPS’17])
▪ マルチドメインへ拡張 (Multi source [H. Zhao+, NeurIPS’18], Multi target [O. Rudovic+, TIP’20], Federated learning
[X. Peng+, ICLR’20])
▪ ドメインが動的に変化する (Incremental DA [Hoffman+, CVPR’14, M. Wulfmeier+, ICRA’18], Open compound
[Ziwei Liu+, CVPR’20])
▪ 映像間の適応へ拡張 [M.H Chen+, ICCV’19]
▪ ソースデータのプライバシーを考慮 (Source free [J. Liang+, ICML’20, J. N. Kundu+, CVPR’20, R. Li+, CVPR’20],
Test-time adaptation [D. Wang+, ICLR’21])
▪ Active Learningとの統合 [P. Rai+, NAACL-HLTW’10, J.C. Su+, CVPR’19]
▪ 応用タスクの拡張 (e.g., Person ReID, Sim2Real, Depth/Gaze estimation, Medical tasks)](https://image.slidesharecdn.com/generationsgan-relation-210527023826/85/slide-116-320.jpg)



The document presents an overview of the research group 'Generations' focused on image generation and generative models, detailing their contributions to fields like unpaired image-to-image translation and domain adaptation. It highlights various studies and techniques, including CycleGAN and neural radiance fields, aimed at enhancing image translation while preserving contextual integrity. The group is actively seeking new members for collaboration on these innovative themes.

![[DL輪読会]MetaFormer is Actually What You Need for Vision](https://cdn.slidesharecdn.com/ss_thumbnails/20220121metaformer-220121085750-thumbnail.jpg?width=640&height=640&fit=bounds)








![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)











![[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing](https://cdn.slidesharecdn.com/ss_thumbnails/glide2-220107030326-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DL輪読会]"CyCADA: Cycle-Consistent Adversarial Domain Adaptation"&"Learning Se...](https://cdn.slidesharecdn.com/ss_thumbnails/20180803dlakuzawa-180803003349-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Domain Adaptive Faster R-CNN for Object Detection in the Wild](https://cdn.slidesharecdn.com/ss_thumbnails/doikento20180615-180620021127-thumbnail.jpg?width=640&height=640&fit=bounds)























![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)




