Downloaded 12 times





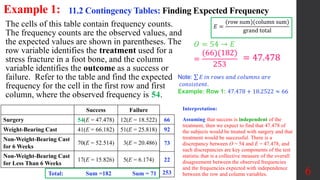













Chapter 11 covers chi-square tests for goodness-of-fit and contingency tables, focusing on testing the independence of variables and proportions for homogeneity. It explains the steps for conducting these tests, including formulating hypotheses, calculating test statistics, and analyzing results using observed and expected frequencies. Additionally, practical examples illustrate how to interpret the outcomes effectively.






















































































