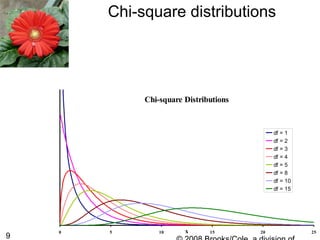
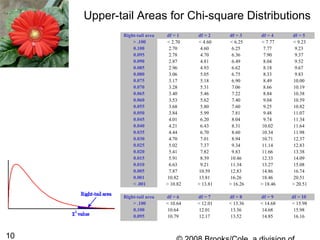
1. The document discusses categorical data analysis and goodness-of-fit tests. It introduces concepts such as univariate categorical data, expected counts, the chi-square test statistic, and assumptions of the chi-square test.
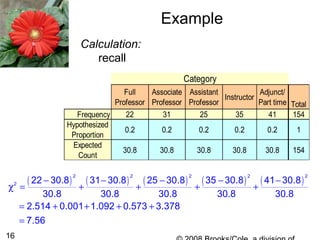
2. An example analyzes faculty status data from a university using a goodness-of-fit test to determine if the proportions are equal across categories. The test fails to reject the null hypothesis that the proportions are equal.
3. Tests for homogeneity and independence in two-way tables are described. Examples calculate expected counts and perform chi-square tests to compare populations' category proportions.