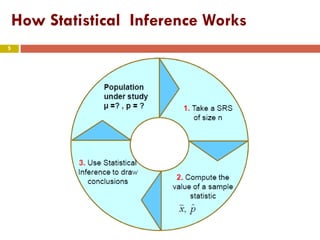
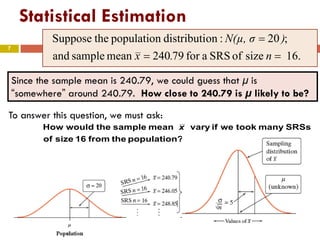
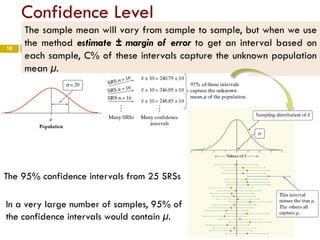
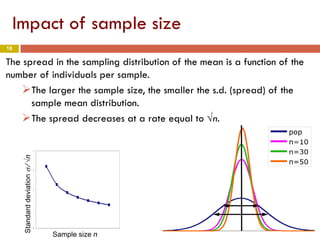
The document introduces statistical inference methods, including estimation with confidence and significance tests, for drawing conclusions about populations from sample data. It elaborates on constructing confidence intervals for population means, the impact of sample size on margin of error, and key concepts such as confidence levels and sampling distributions. The document also provides examples demonstrating how to calculate confidence intervals and determine required sample sizes based on desired margins of error.