Downloaded 18 times



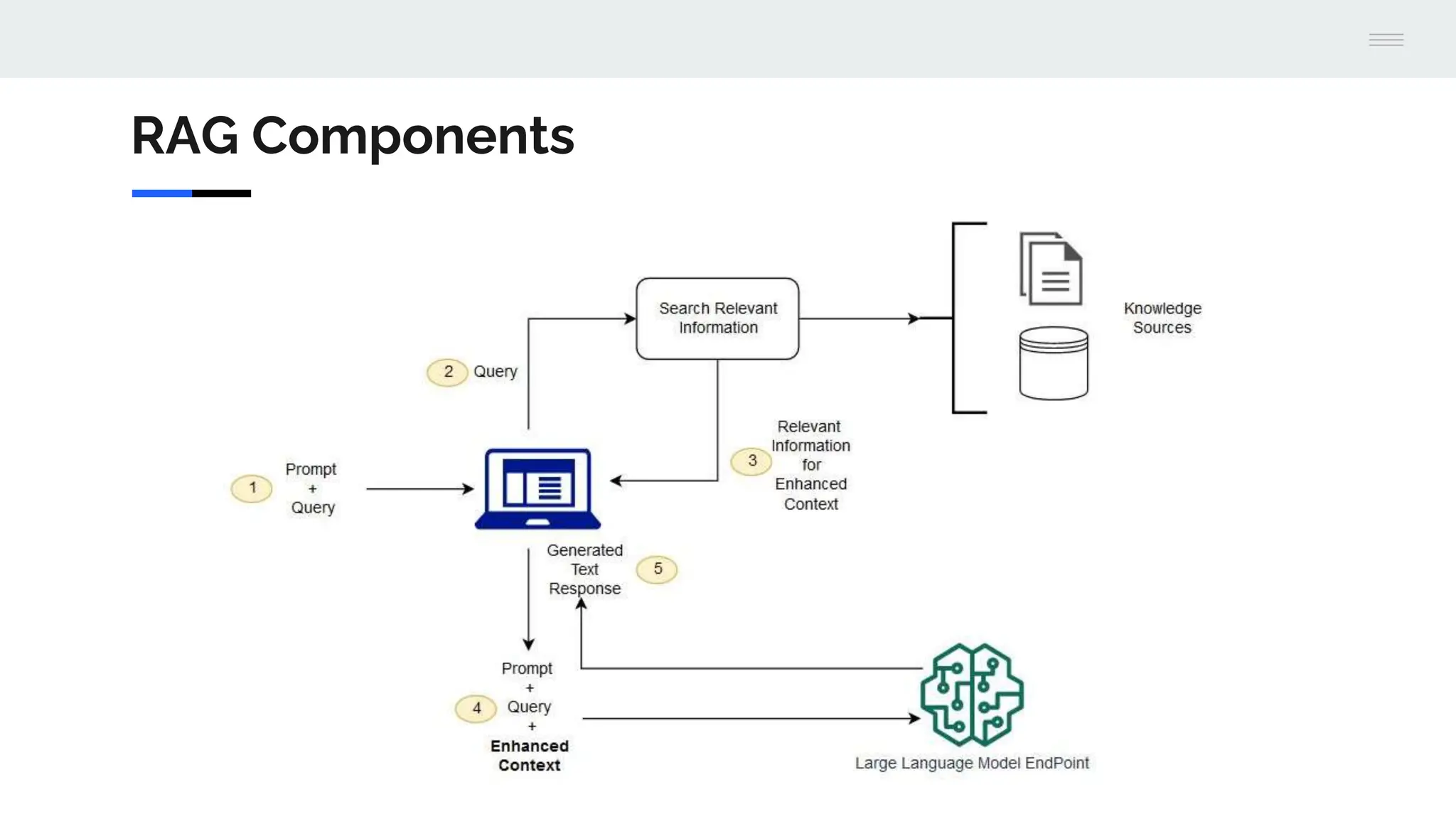



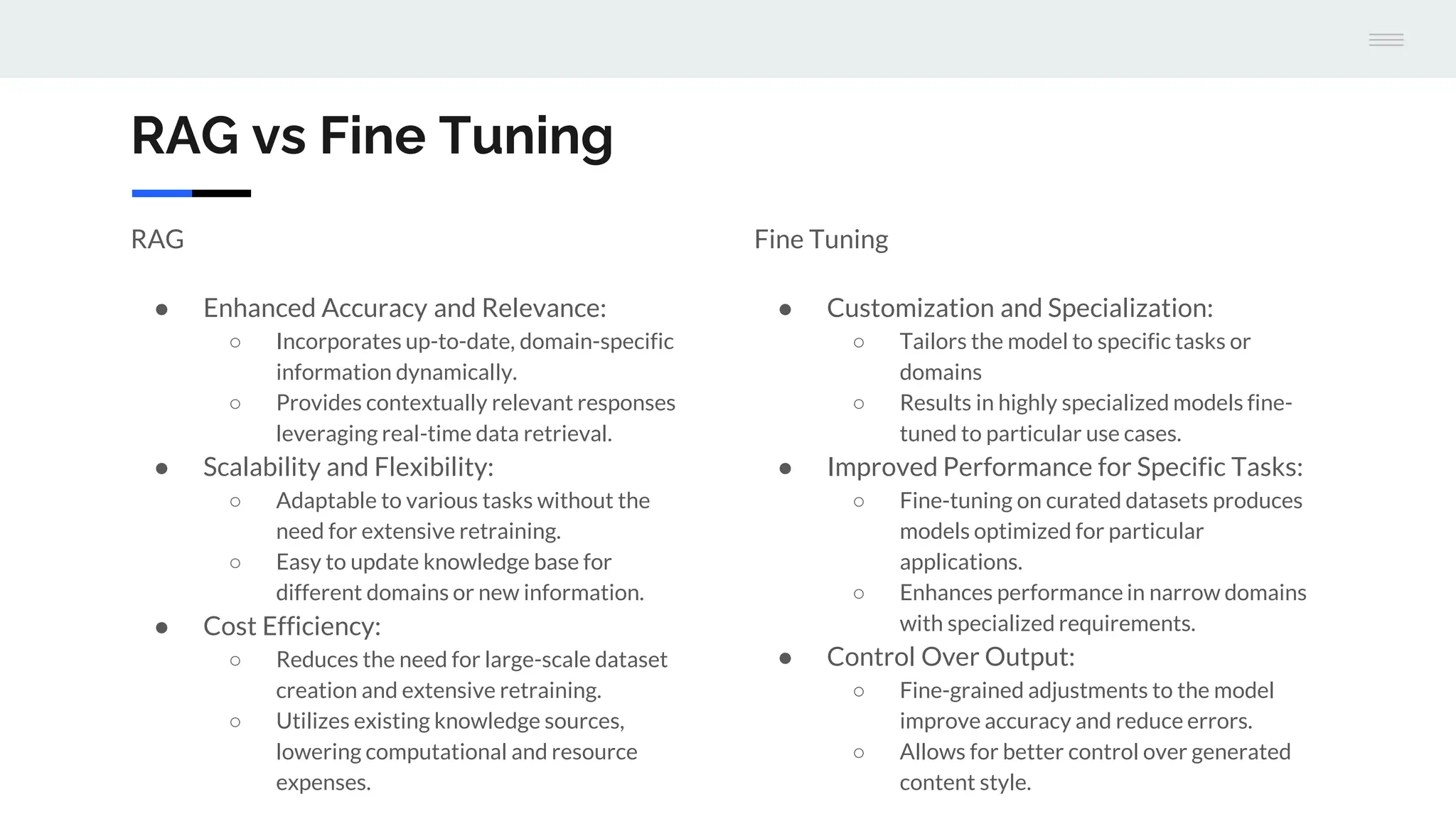




The document discusses a version 1.0 fine-tuning of the Llama 2 model using retrieval-augmented generation (RAG), emphasizing its hybrid approach that combines information retrieval with text generation to enhance accuracy and relevance. It outlines the mechanisms of how RAG works, the benefits it offers over traditional language models, and the importance of external knowledge sources for generating informed responses. The evaluation framework for performance assessment is aligned with established benchmarks for both traditional language models and RAG models.





![[DSC Europe 24] Sofia Konchakova - Effective Context Tuning Strategies for Re...](https://cdn.slidesharecdn.com/ss_thumbnails/sofiakonchakova-contentmanagementforragsystems-250213223330-c0838a06-thumbnail.jpg?width=640&height=640&fit=bounds)





























































