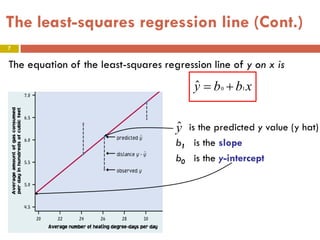
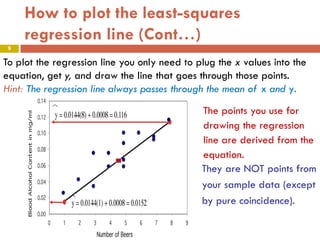
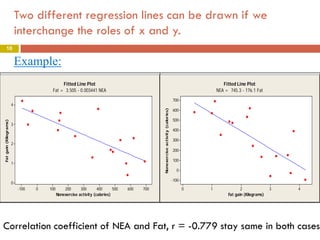
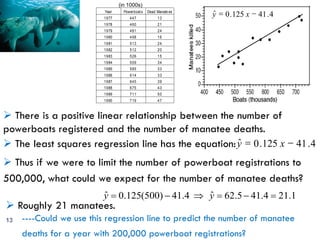
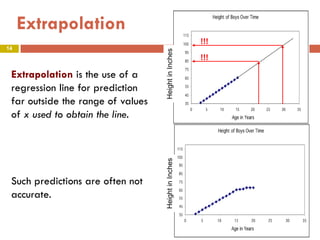
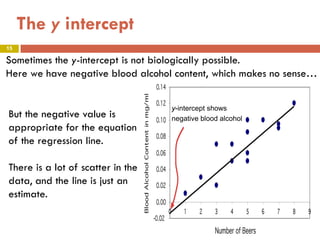
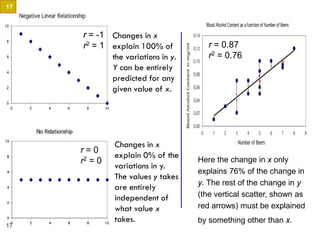
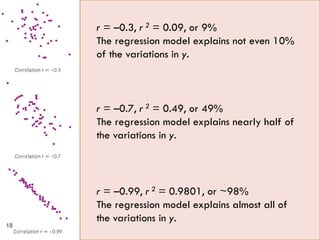
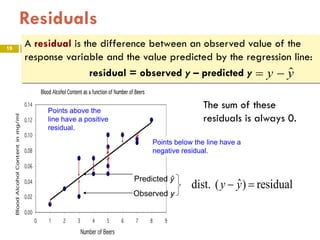
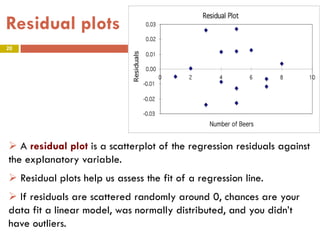
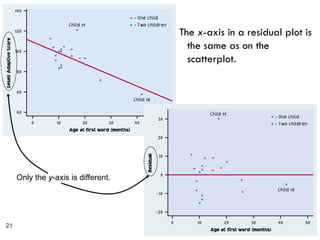
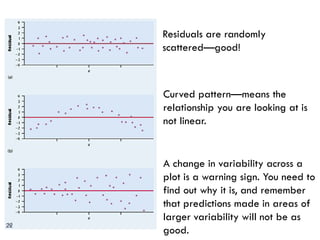
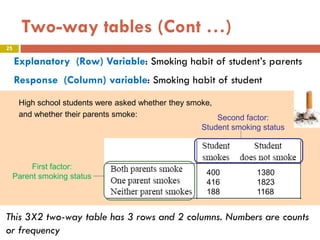
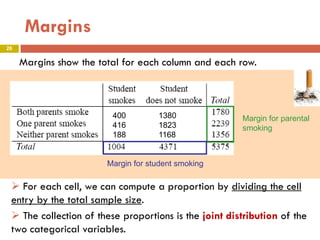
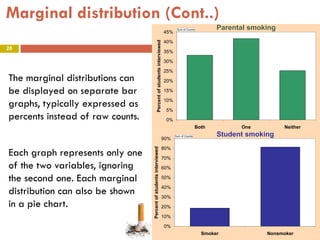
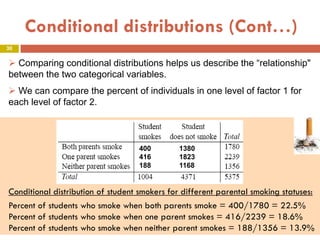
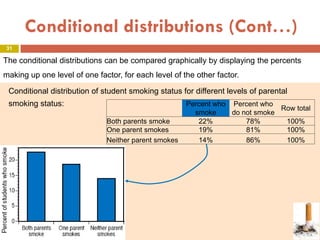
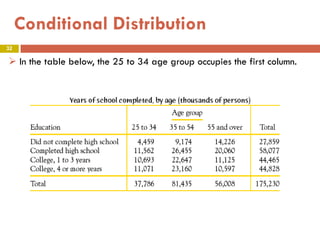
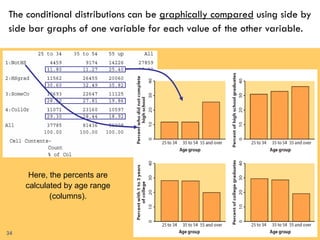
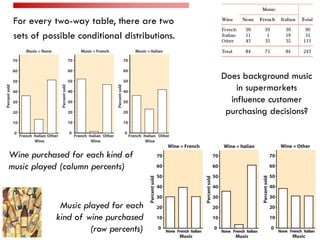
This document provides an overview of regression analysis and two-way tables. It defines key concepts such as regression lines, correlation, residuals, and marginal and conditional distributions. Regression finds the linear relationship between two variables to make predictions. The least squares regression line minimizes the vertical distance between the data points and the line. Correlation and the coefficient of determination r2 measure how well the regression line fits the data. Two-way tables summarize the relationship between two categorical variables through marginal and conditional distributions.