Downloaded 20 times
























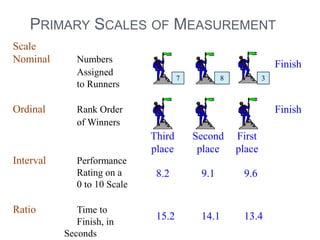




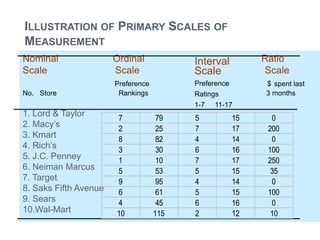
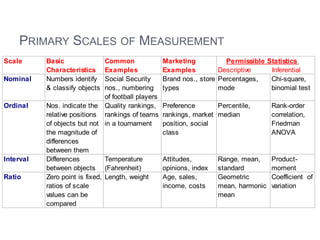
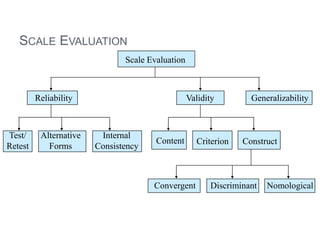







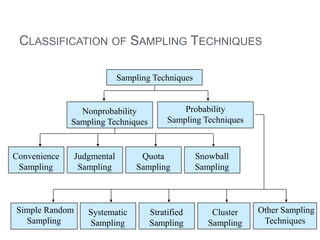














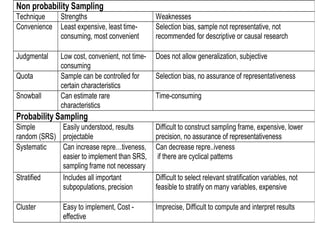


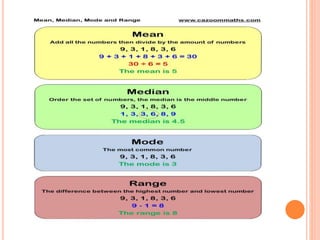



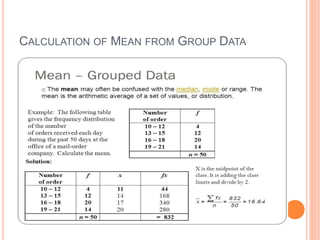















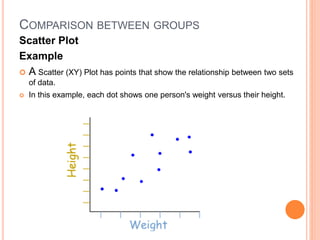
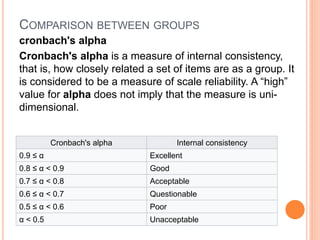
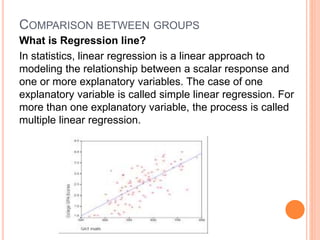



This document provides an overview of basic concepts in inferential statistics. It defines descriptive statistics as describing and summarizing data through measures like mean, median, variance and standard deviation. Inferential statistics is defined as using sample data and statistics to draw conclusions about populations through hypothesis testing and estimates. Key concepts explained include parameters, statistics, sampling distributions, null and alternative hypotheses, and the hypothesis testing process. Examples of descriptive and inferential analyses are also provided.




















































































