Downloaded 811 times


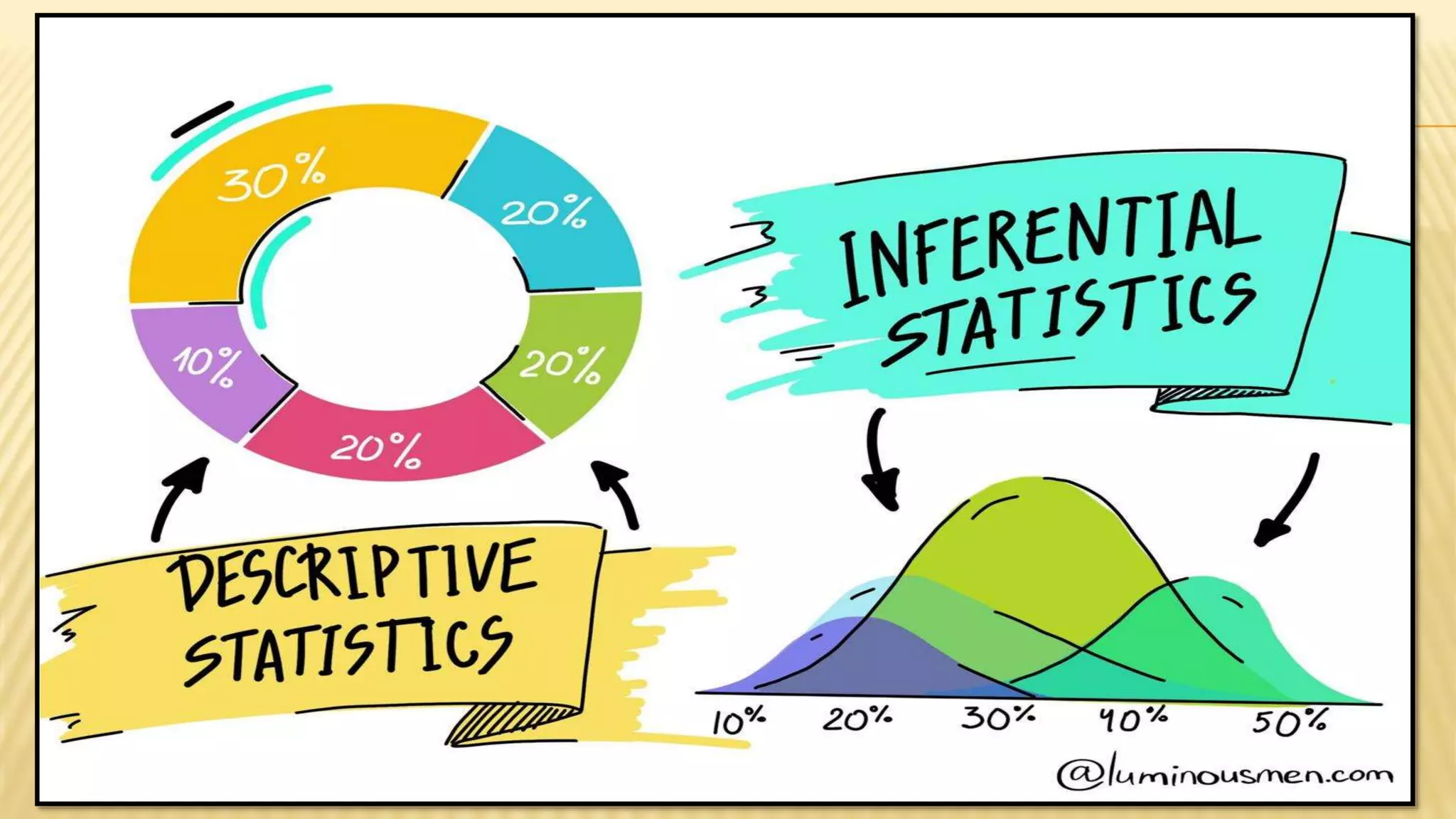

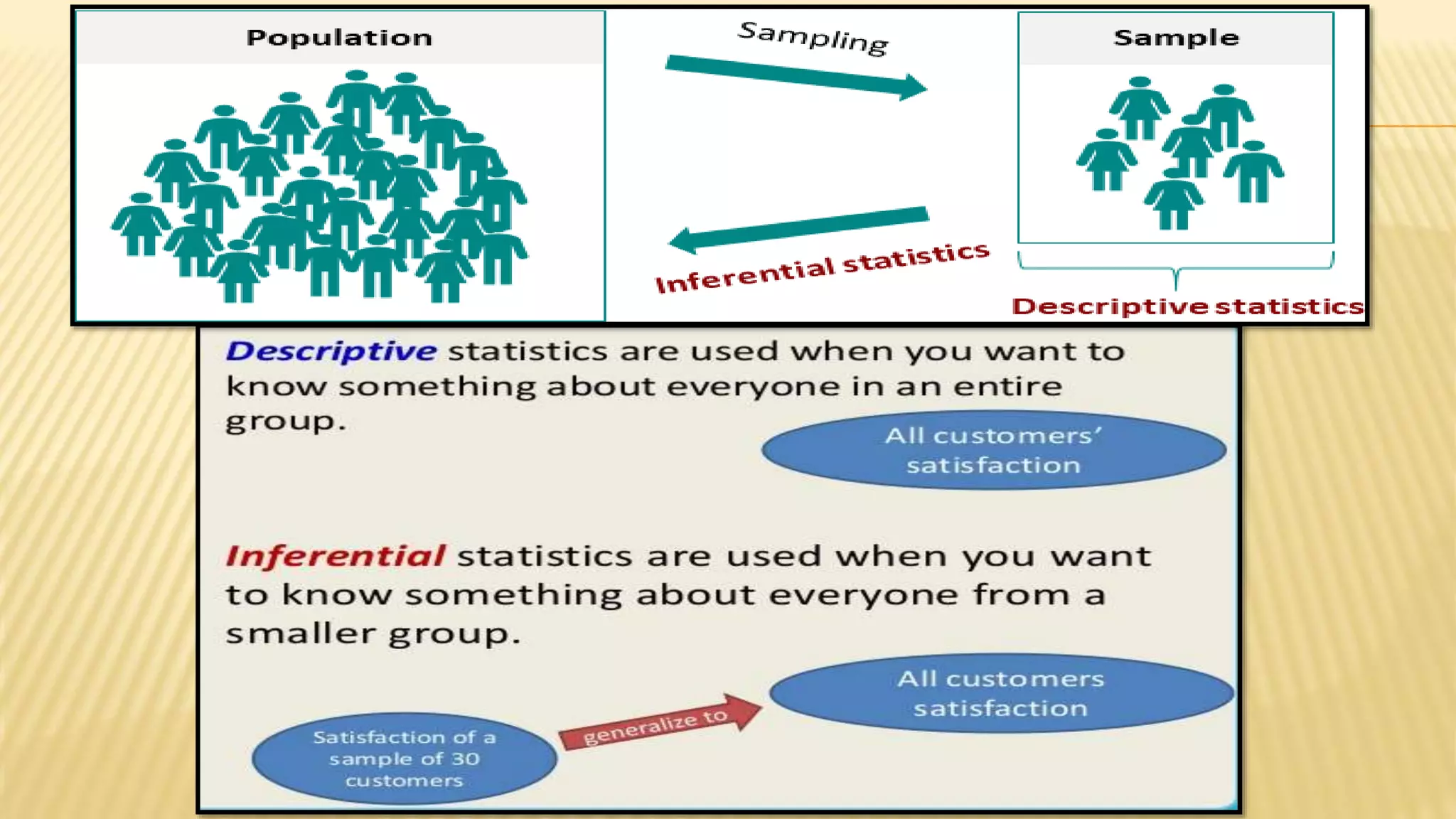
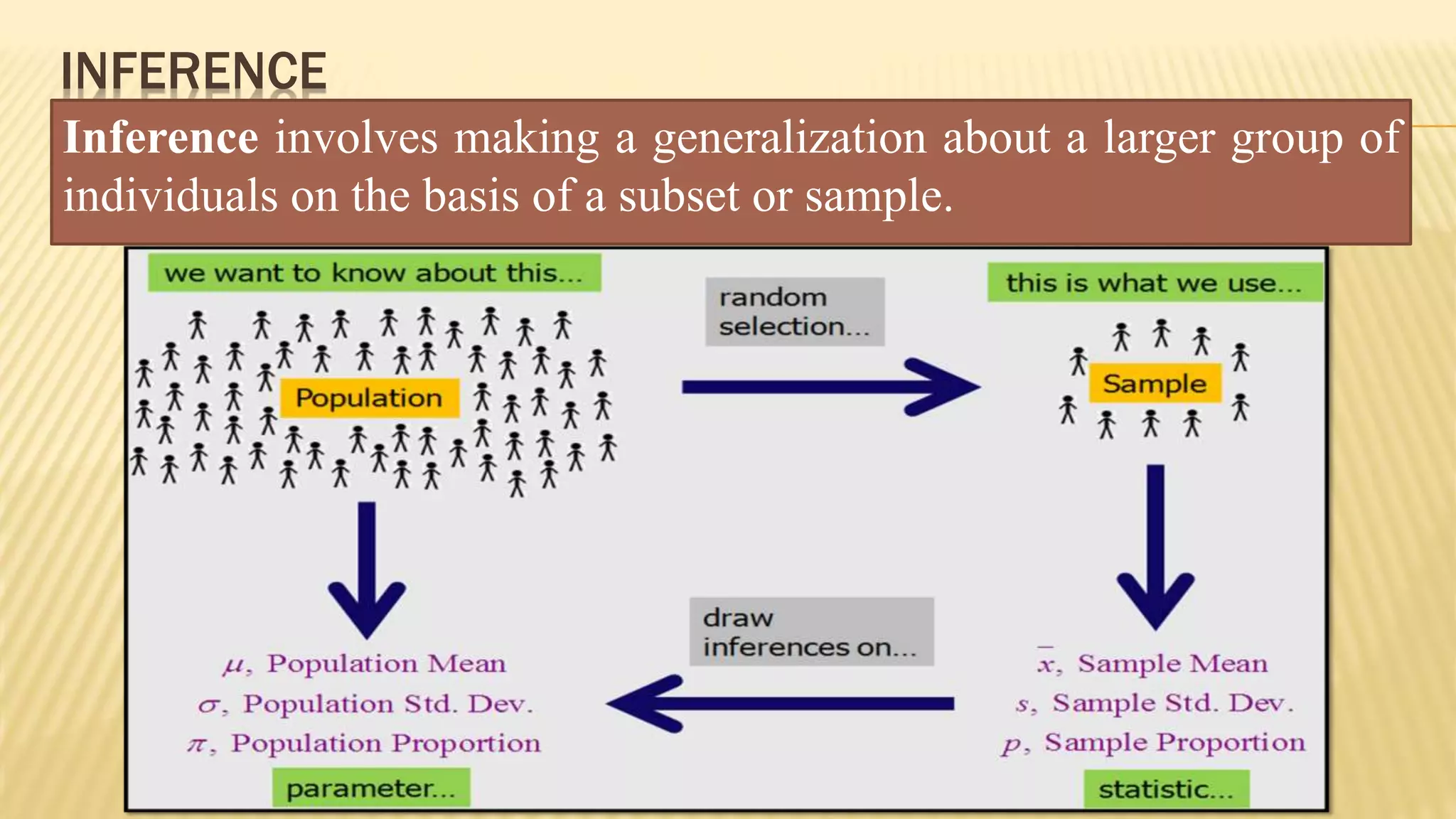
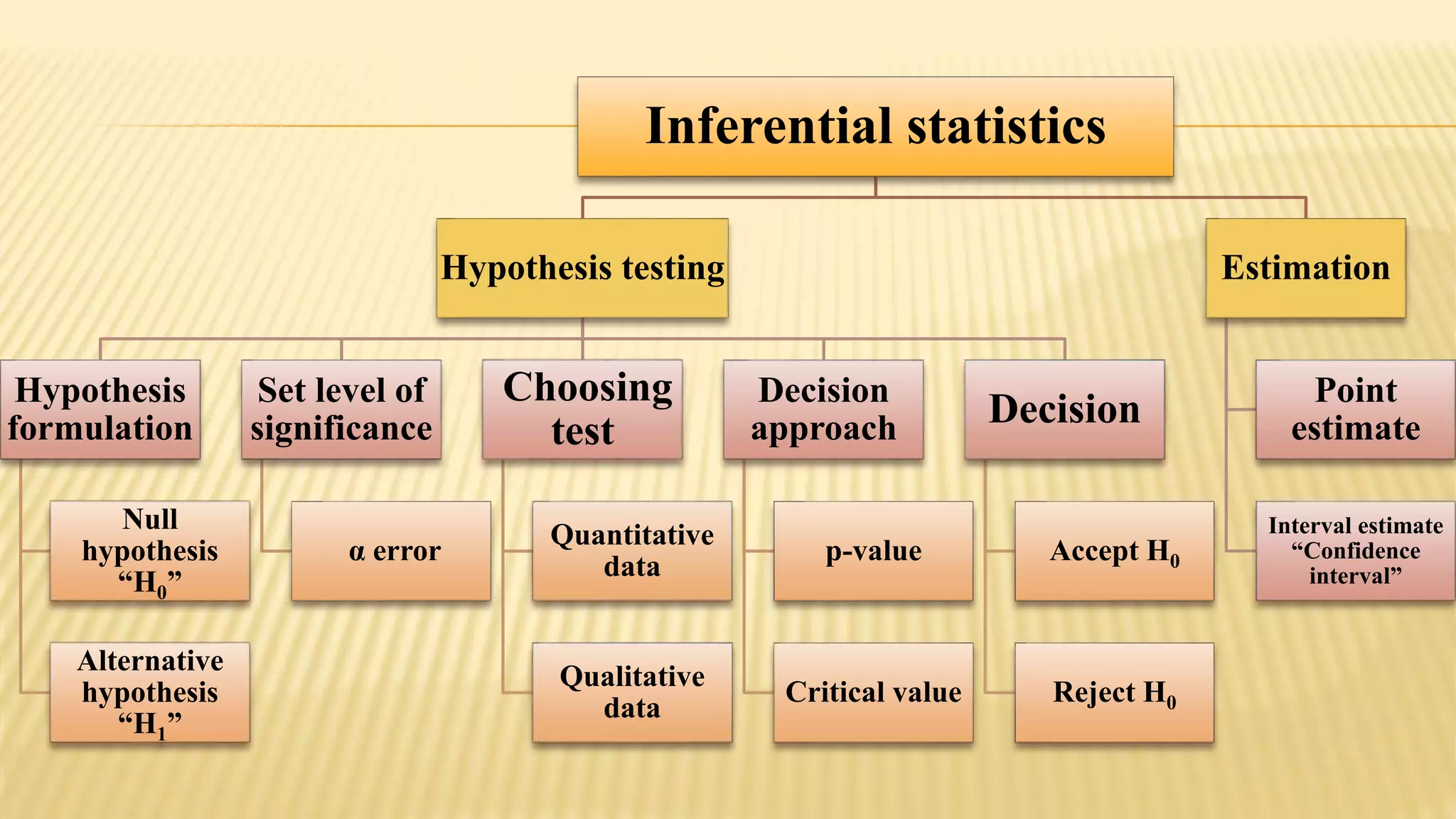
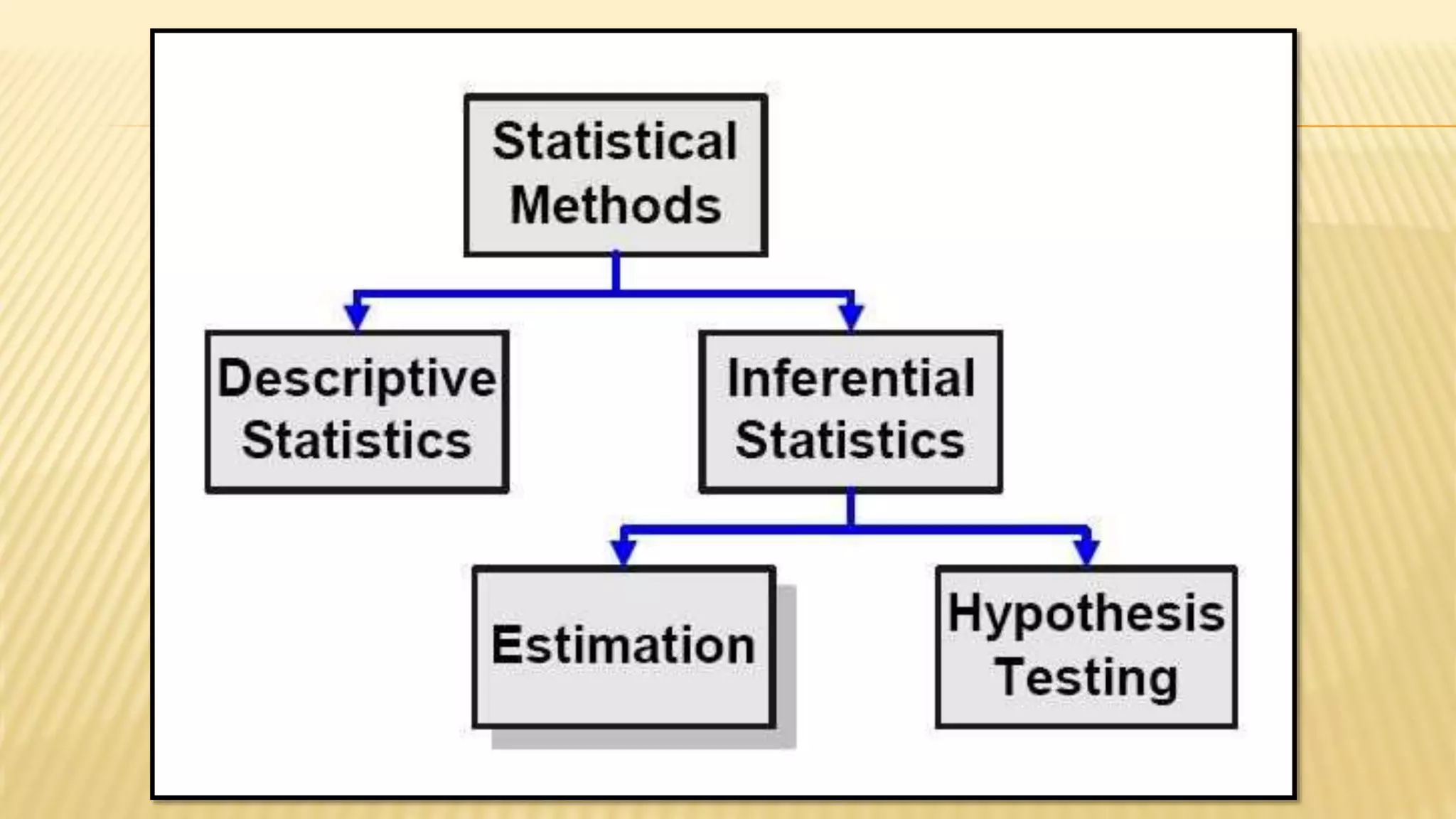
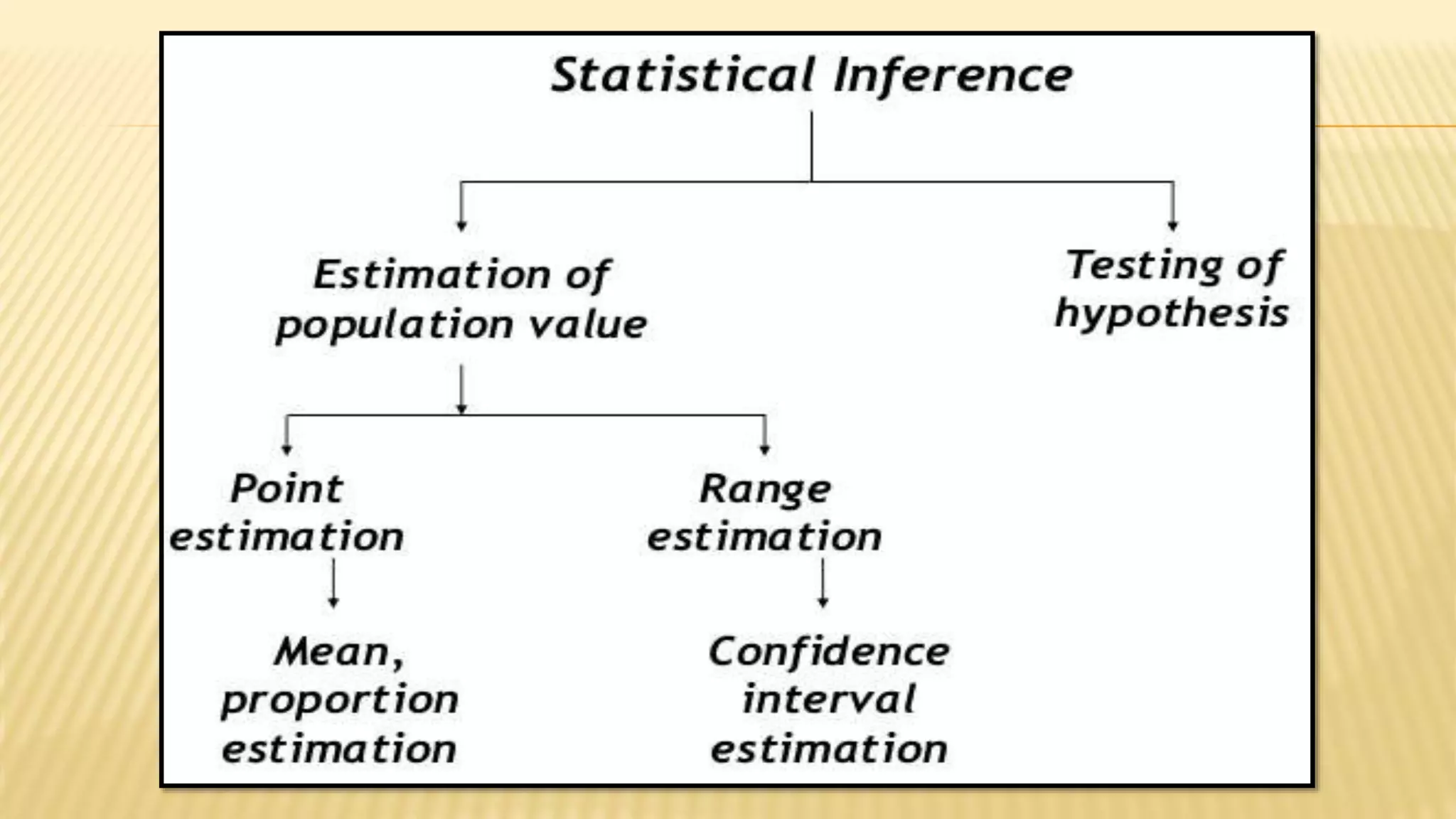
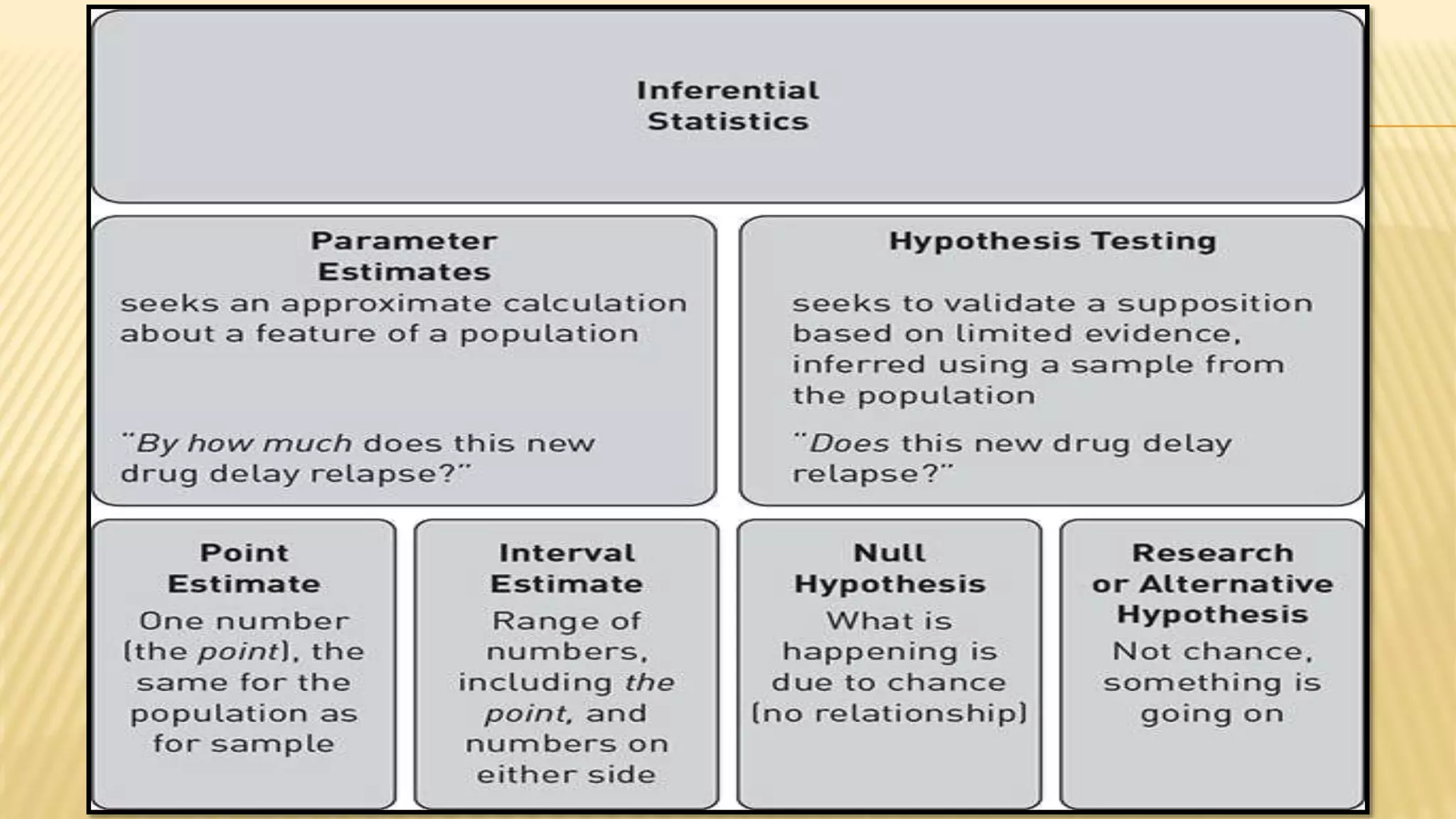


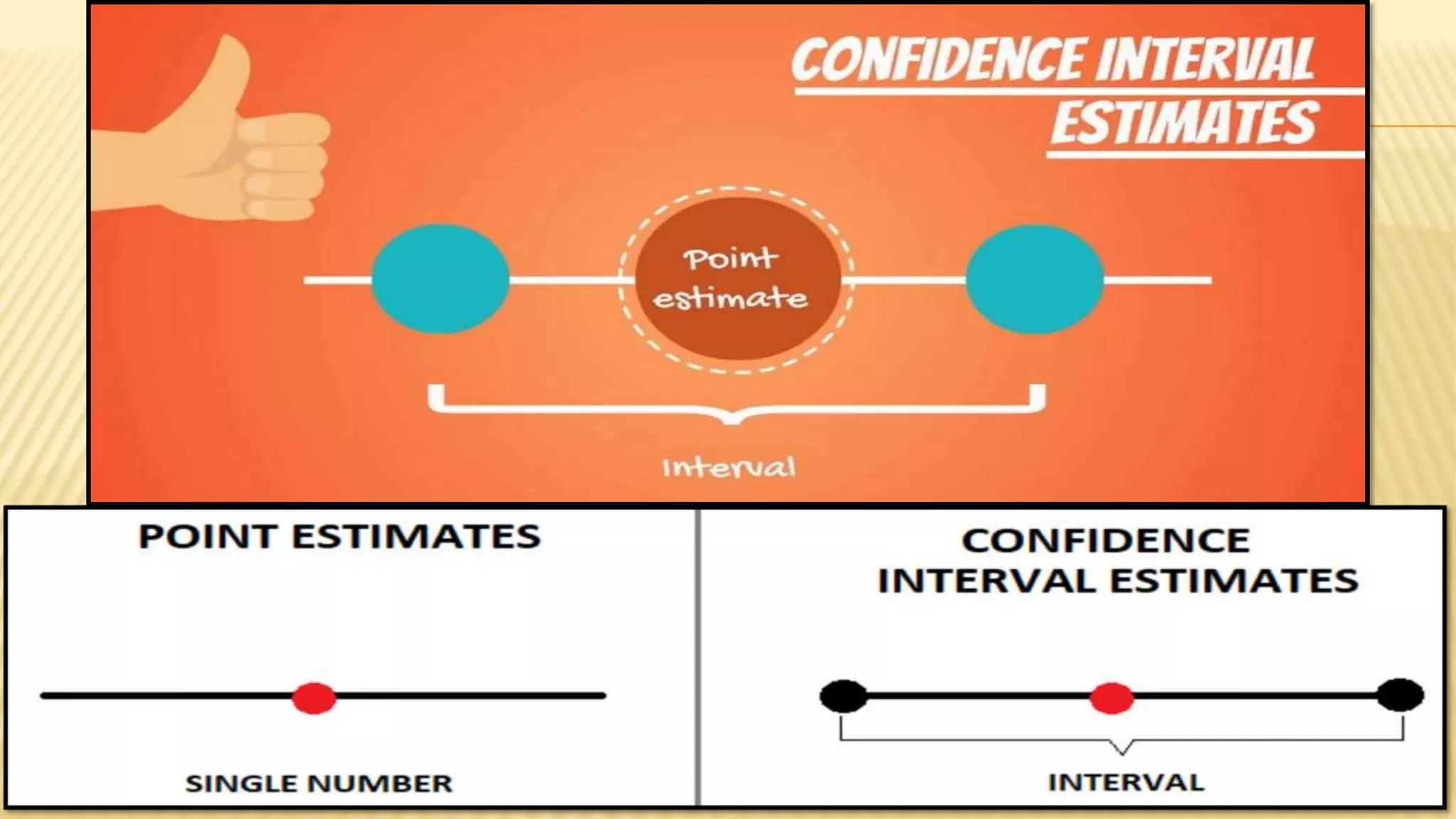

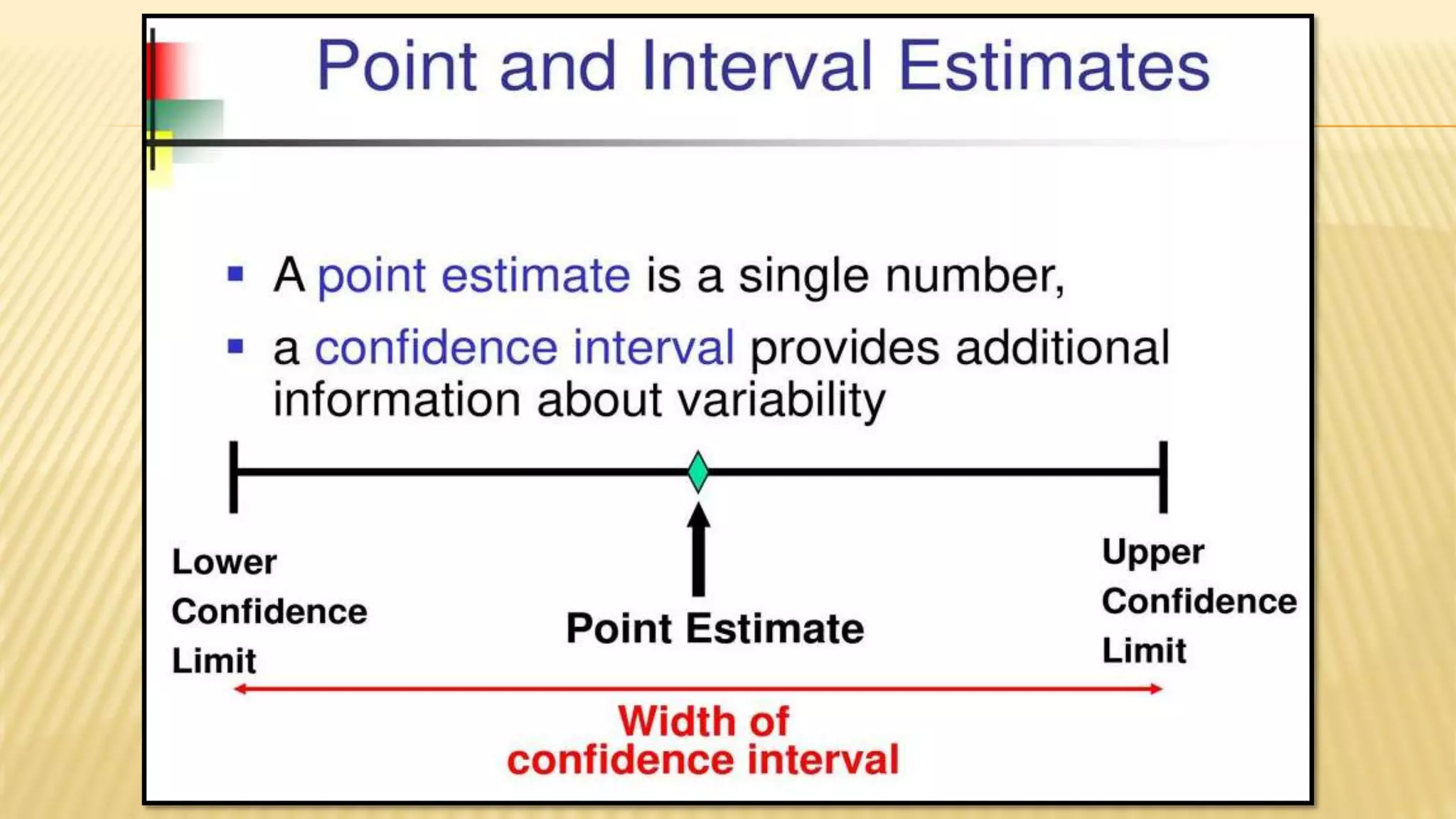

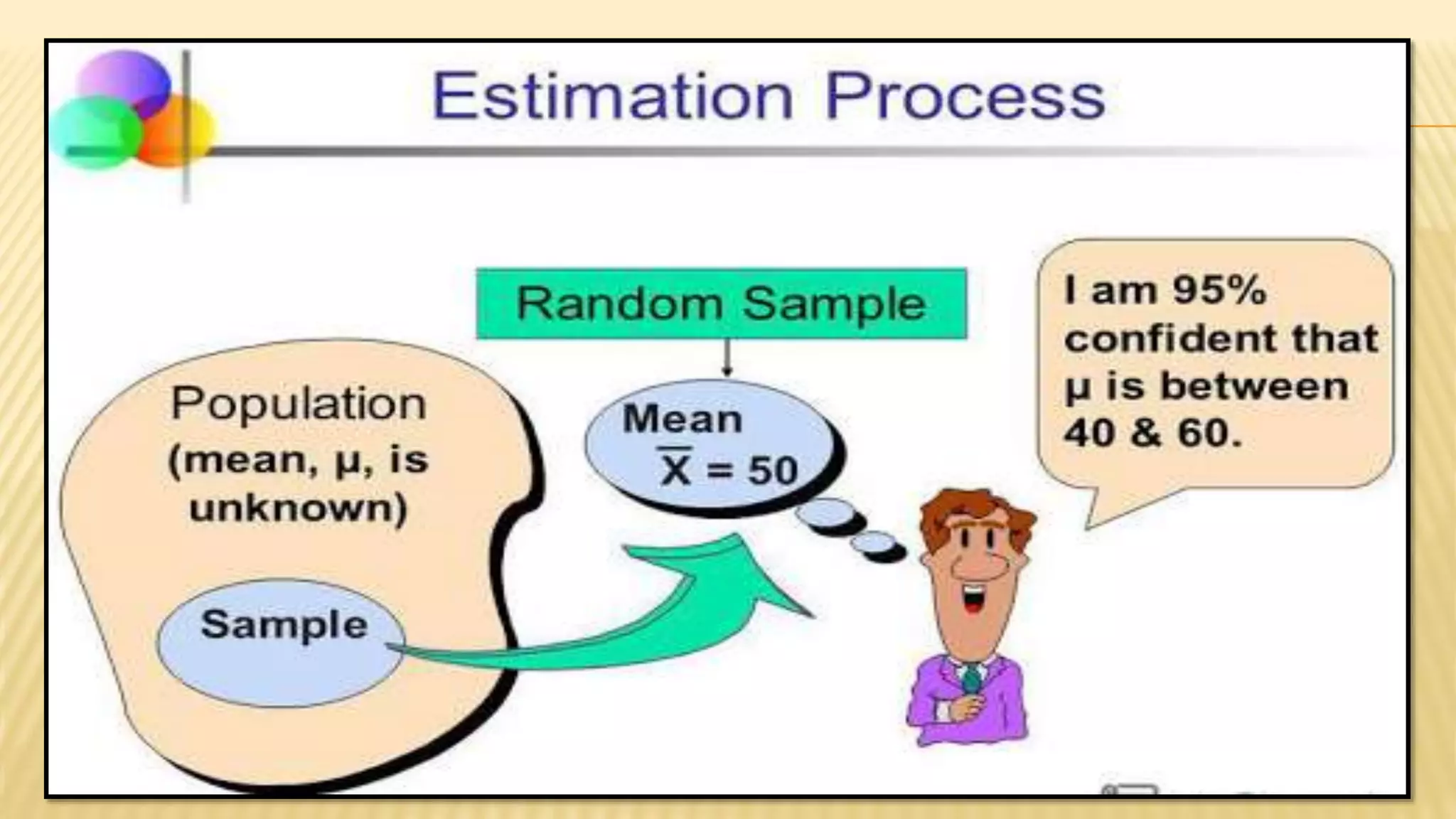


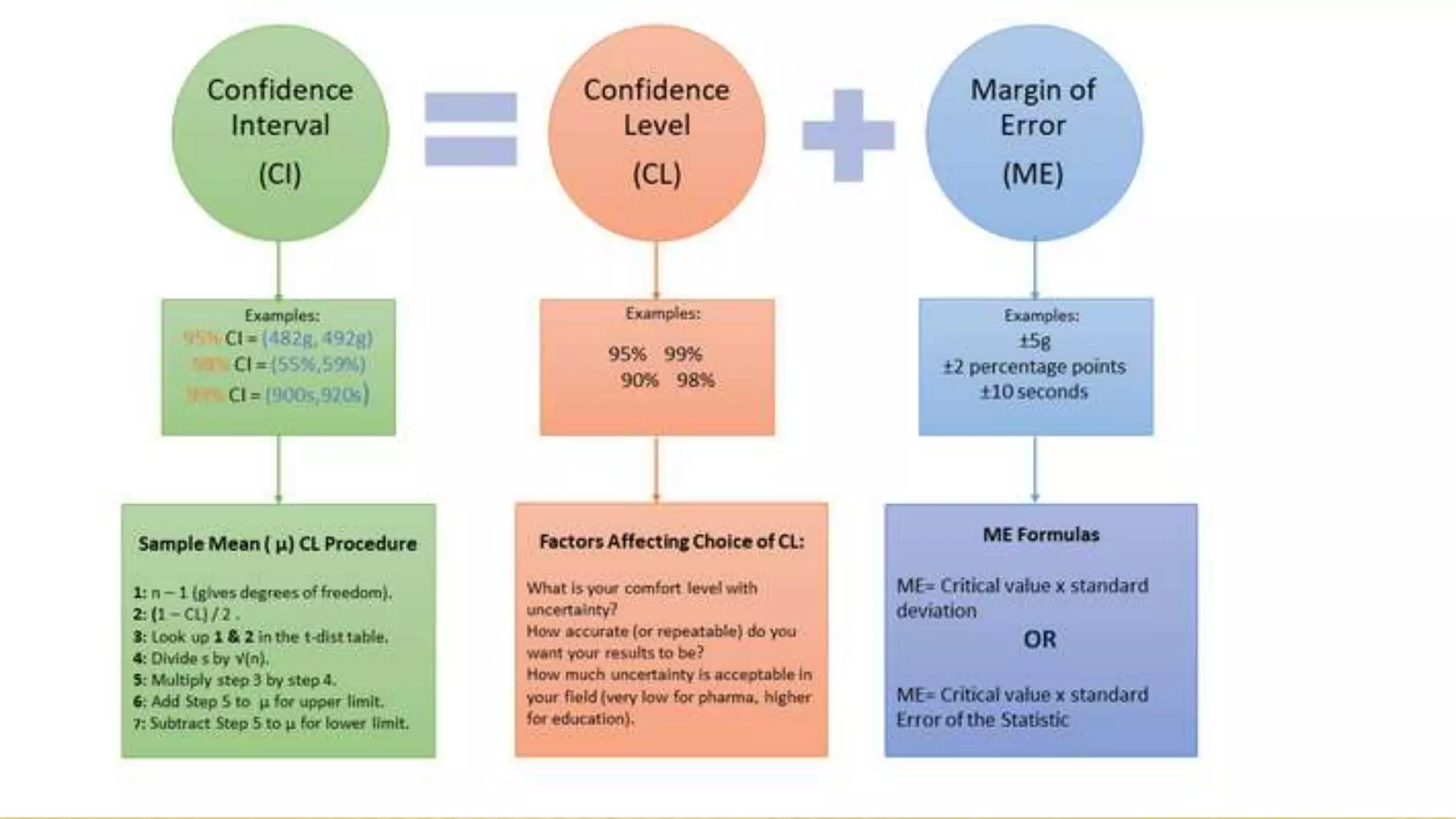




















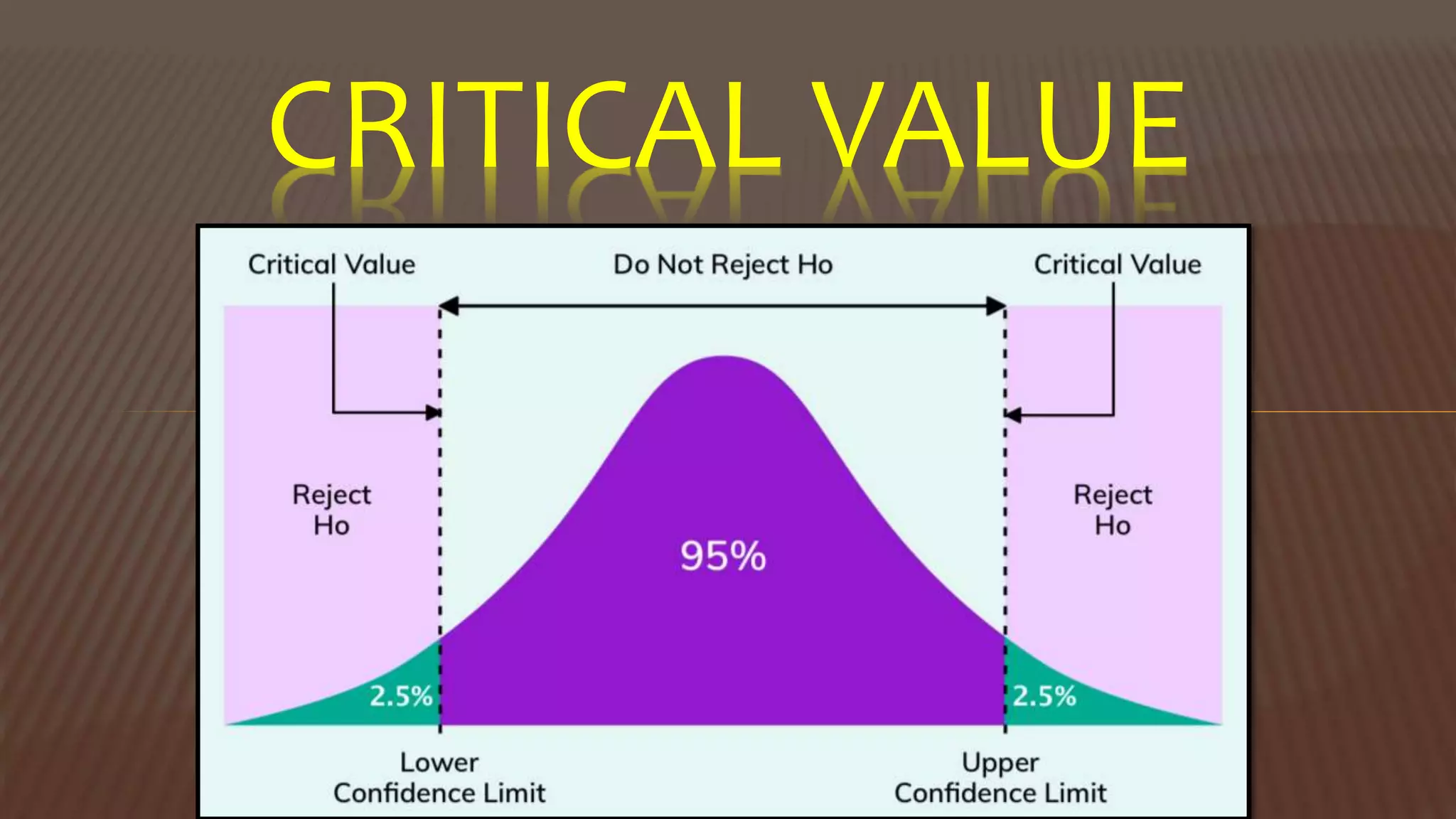


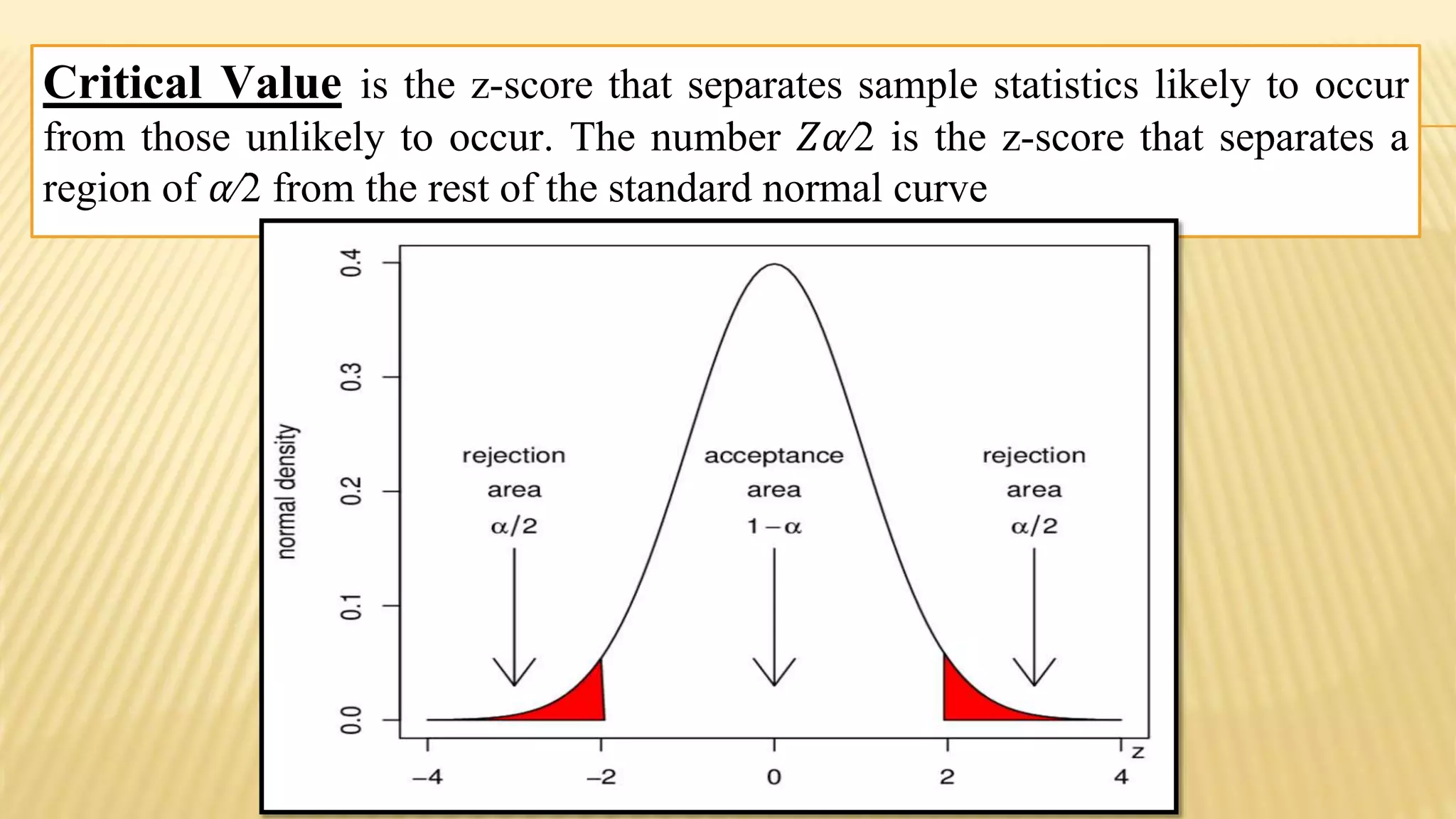
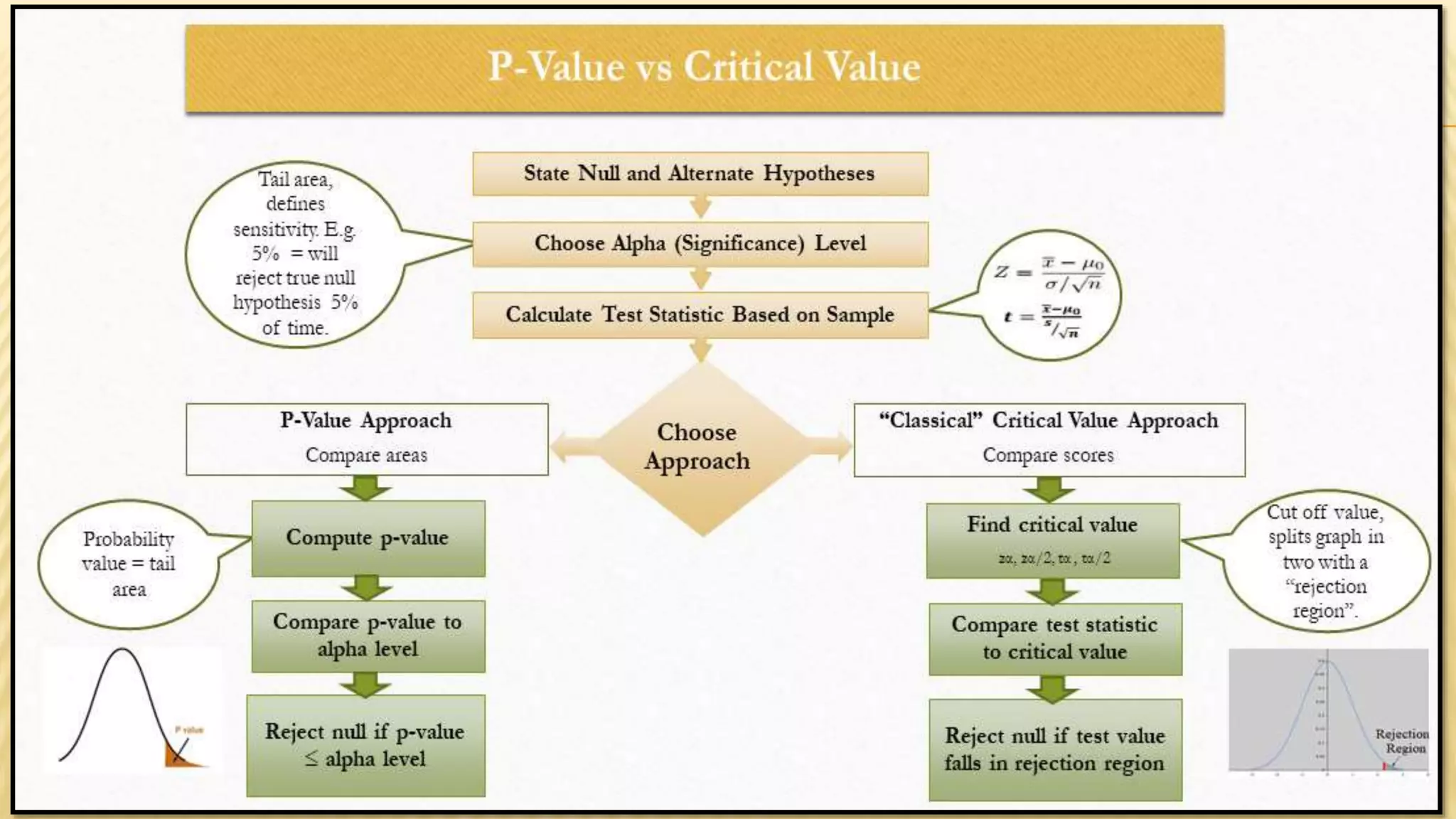






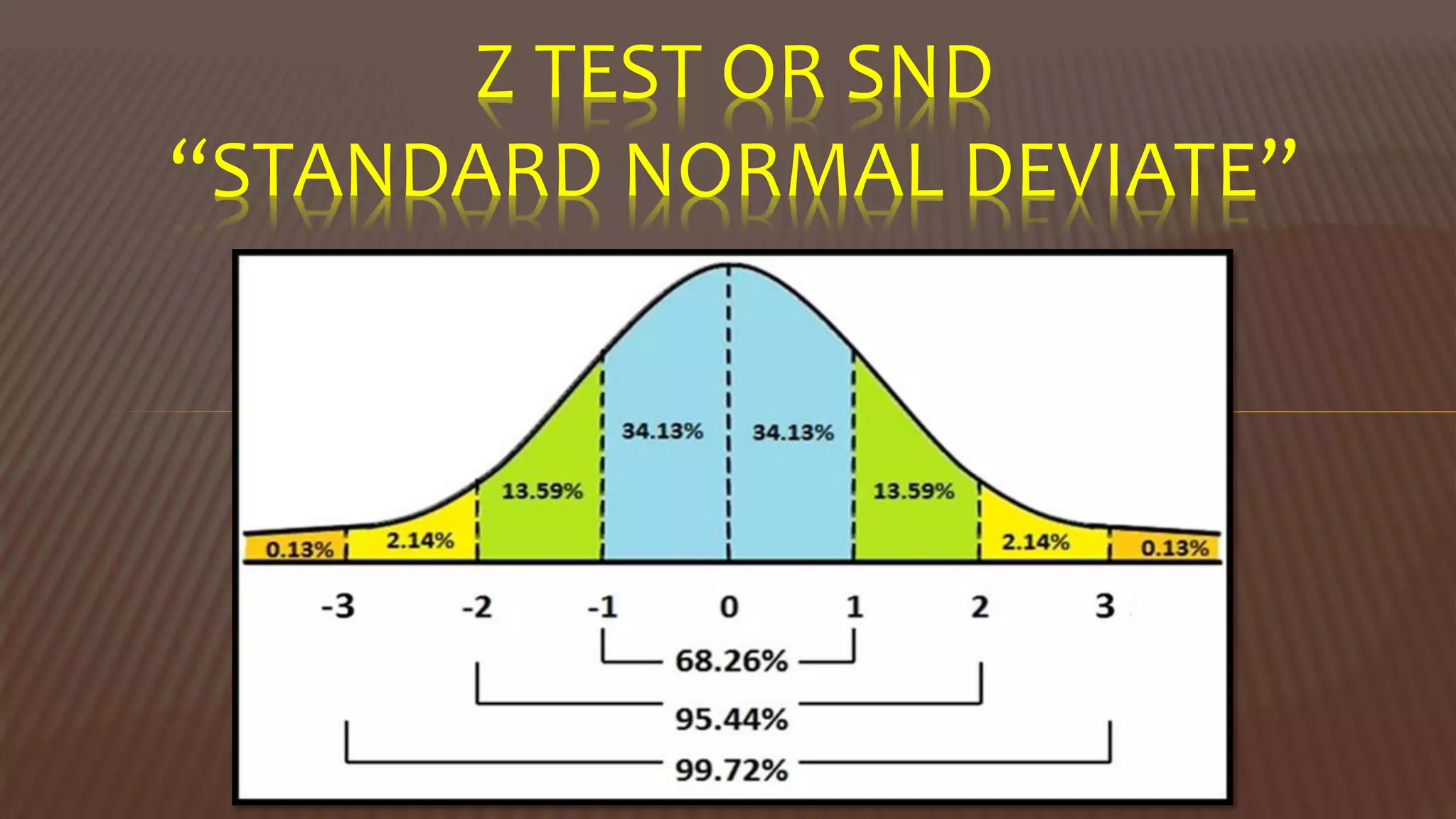
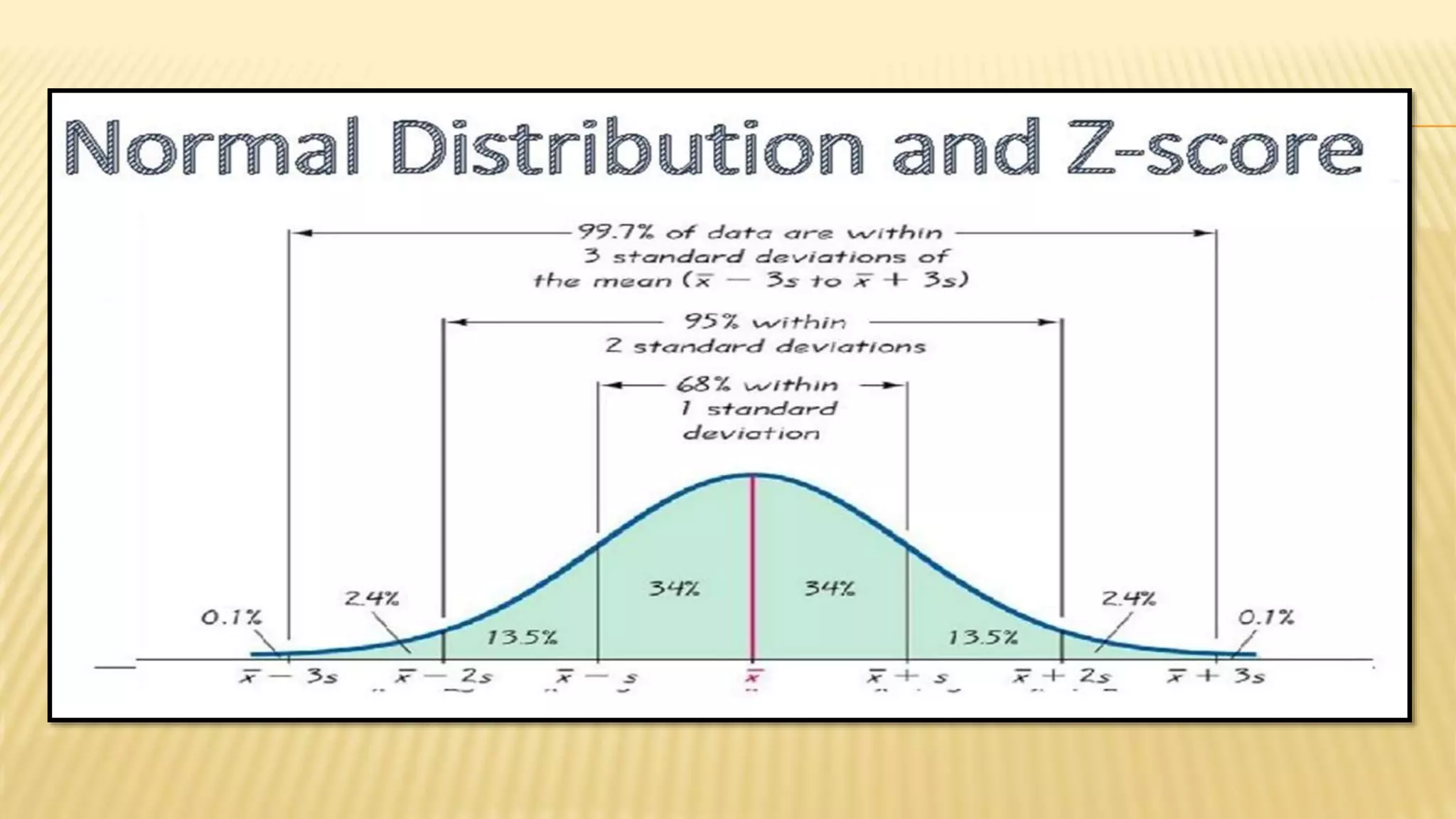
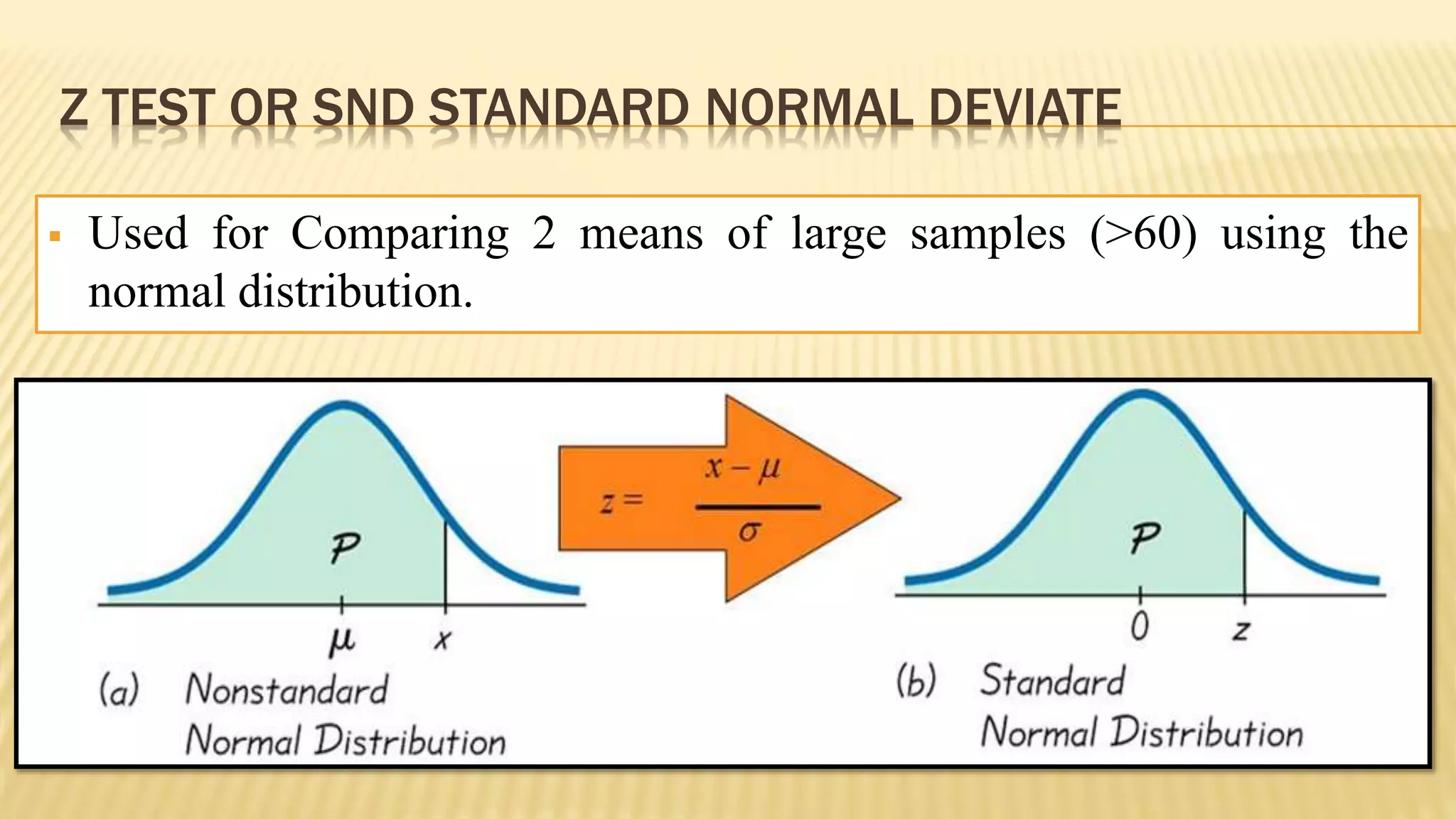


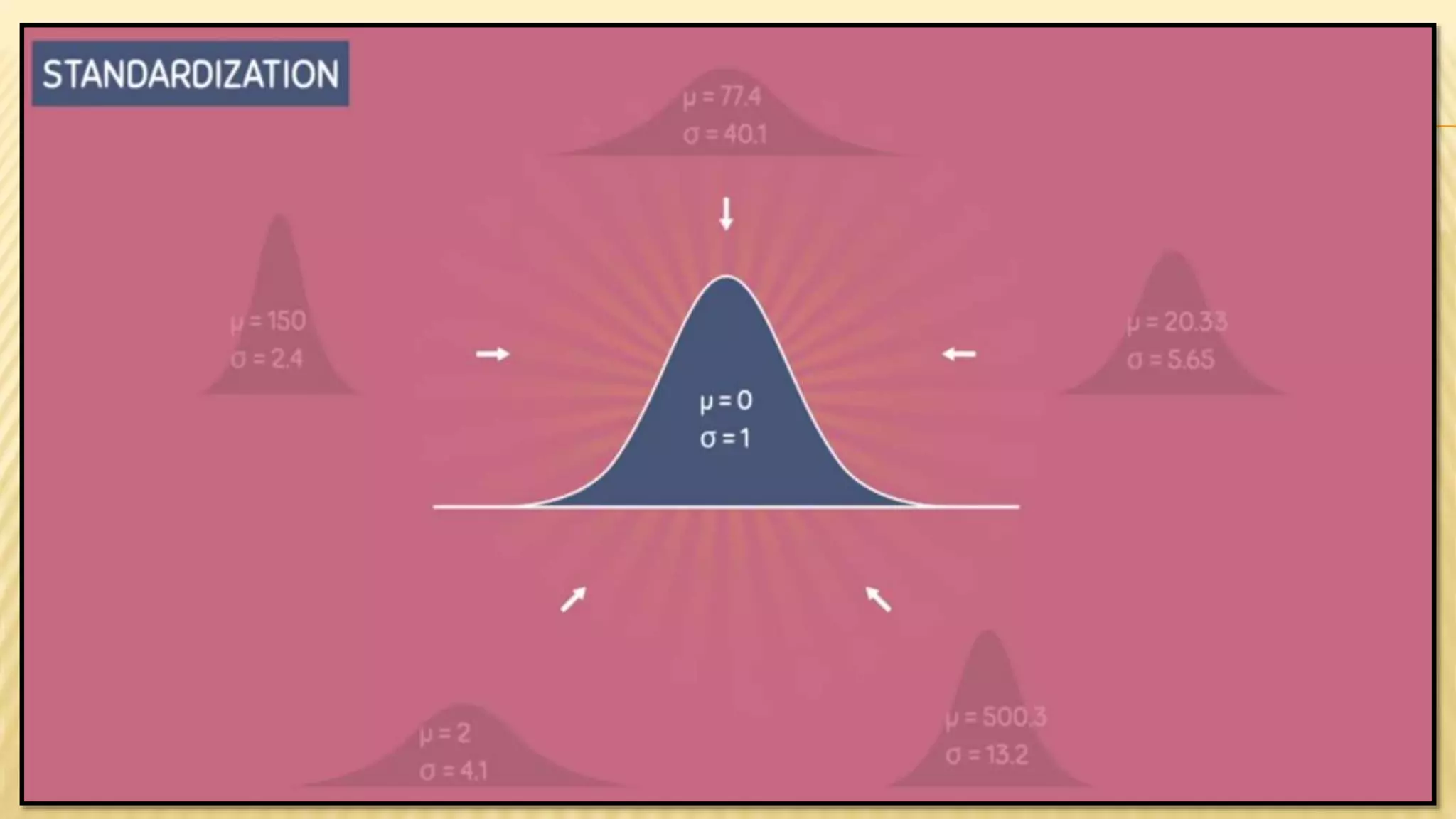
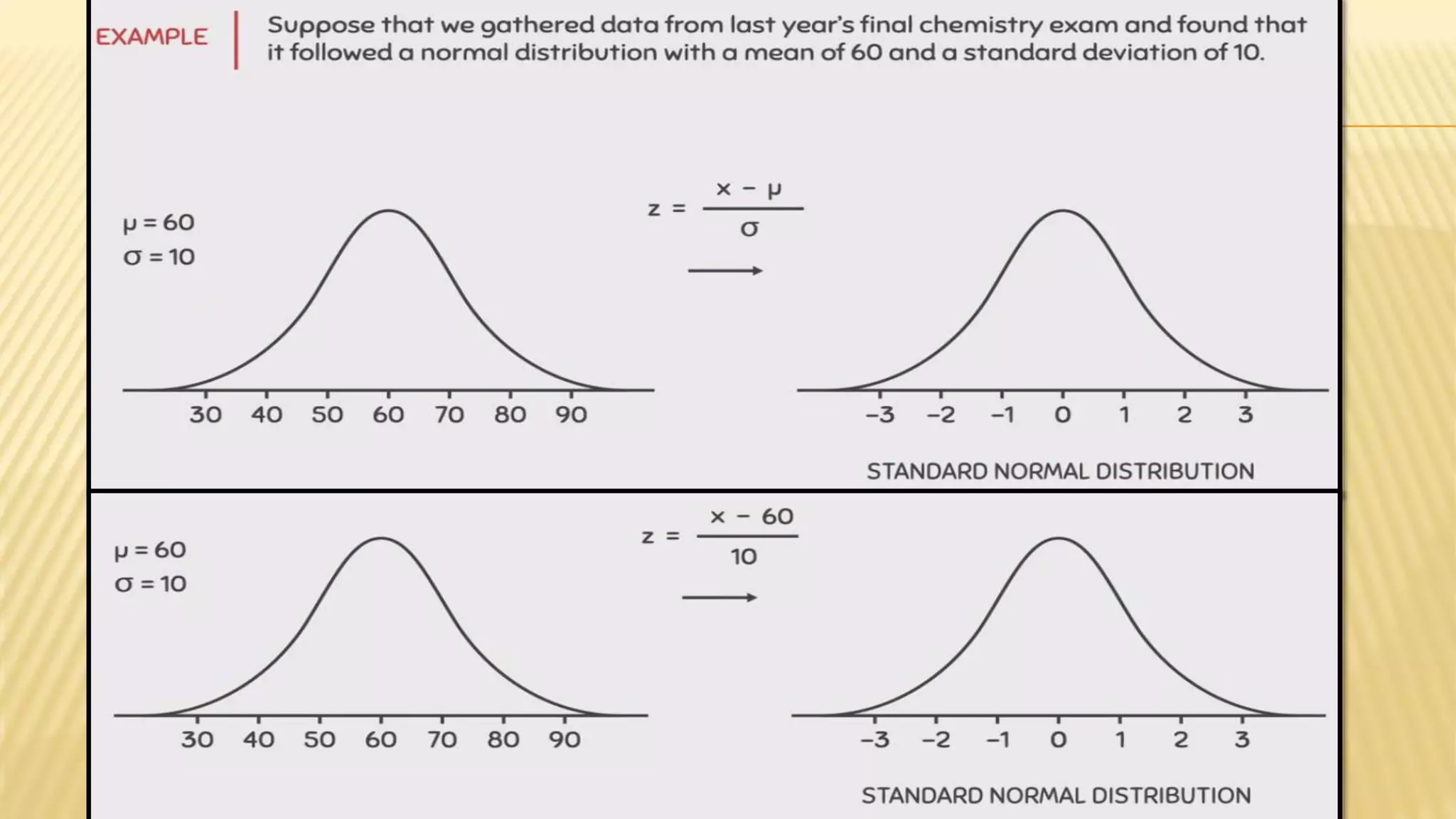

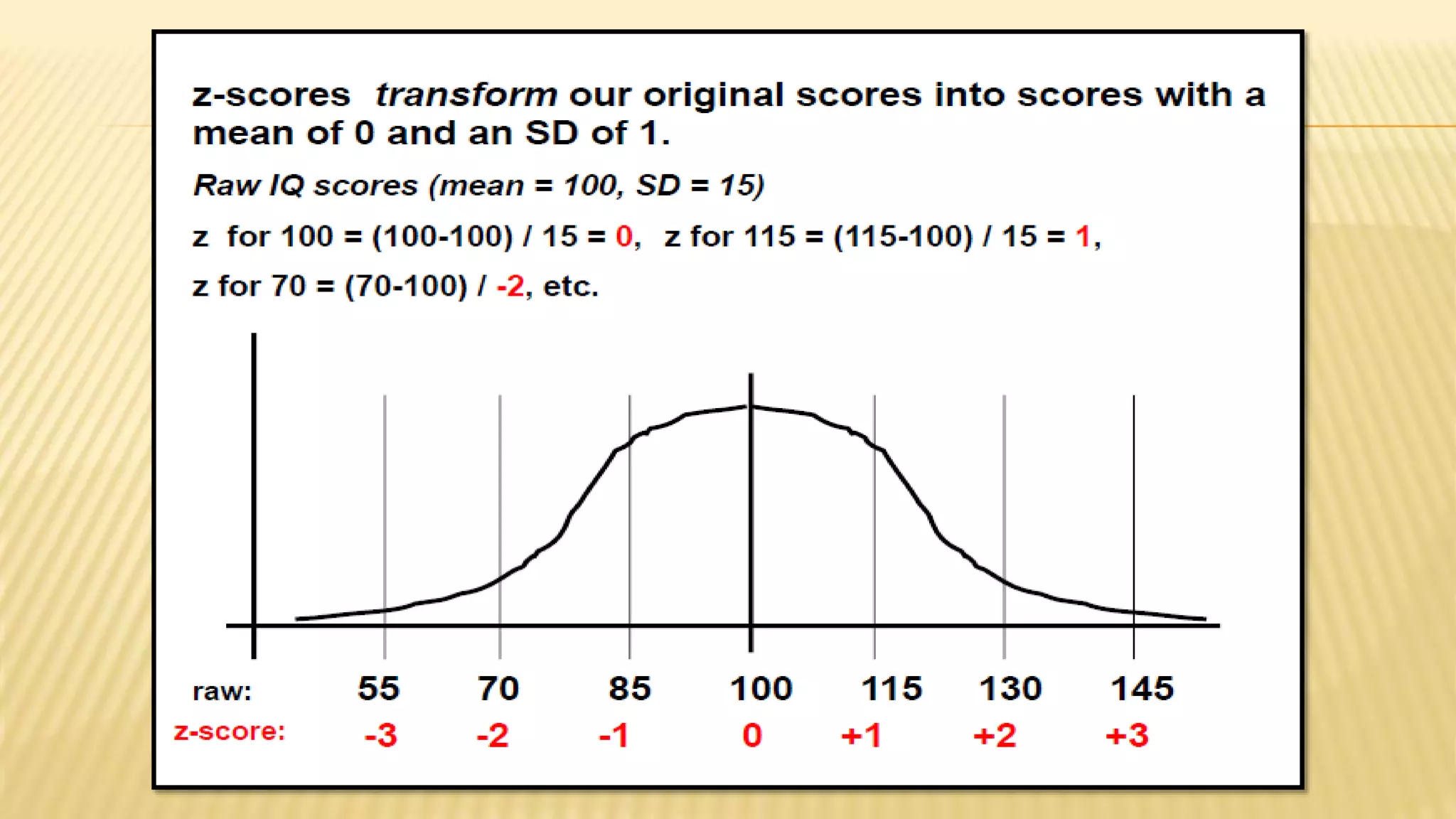





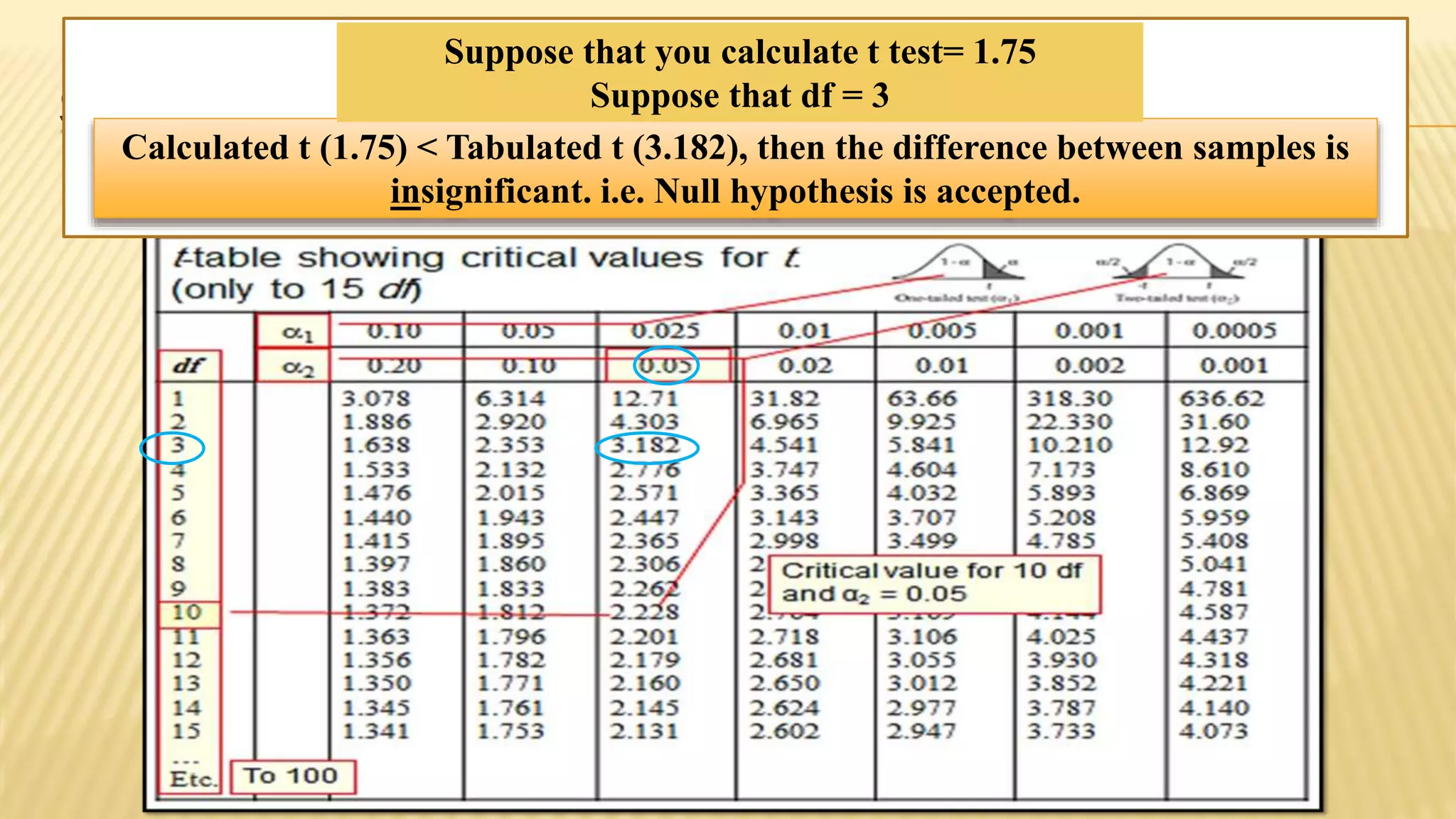
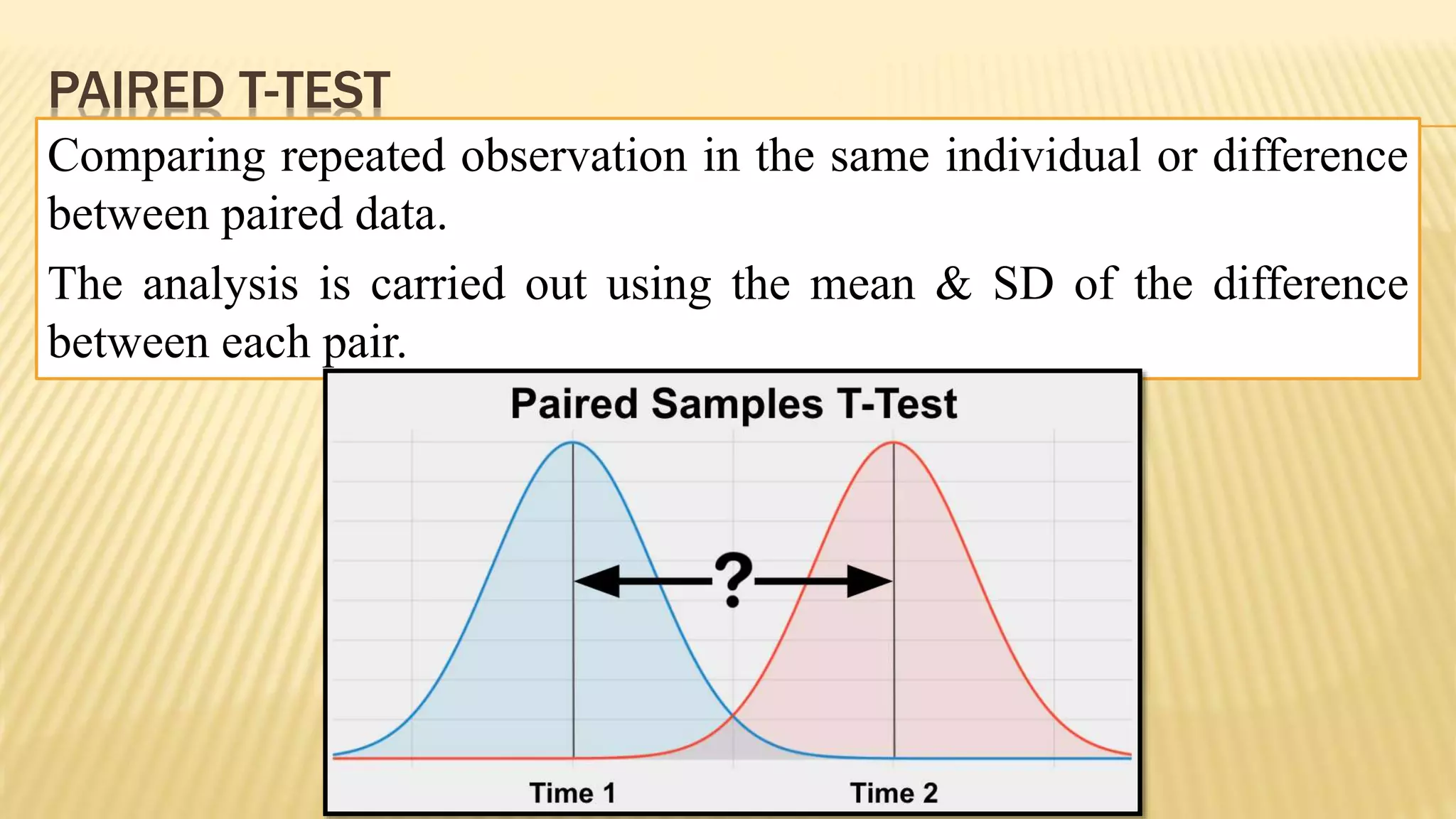
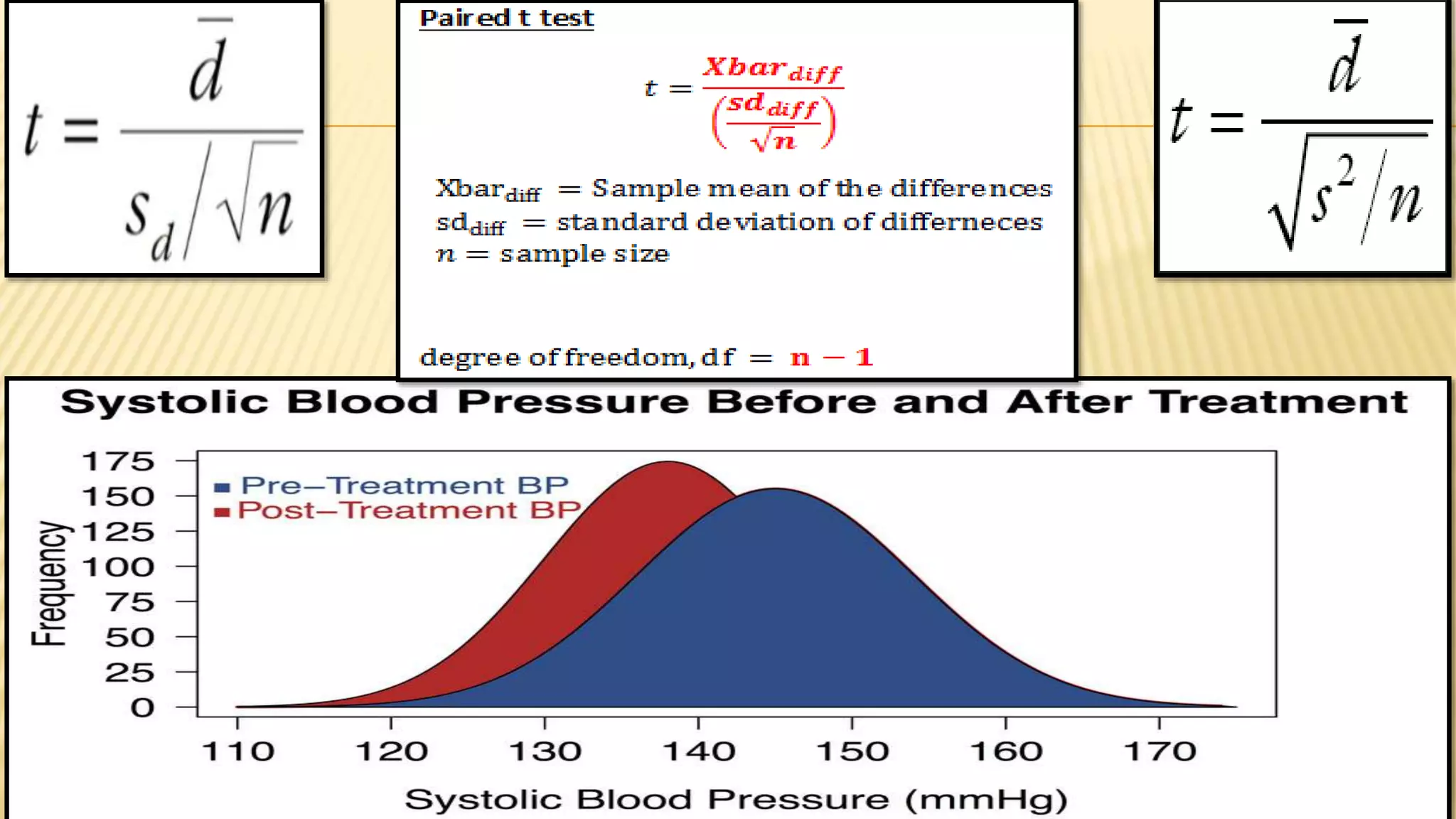

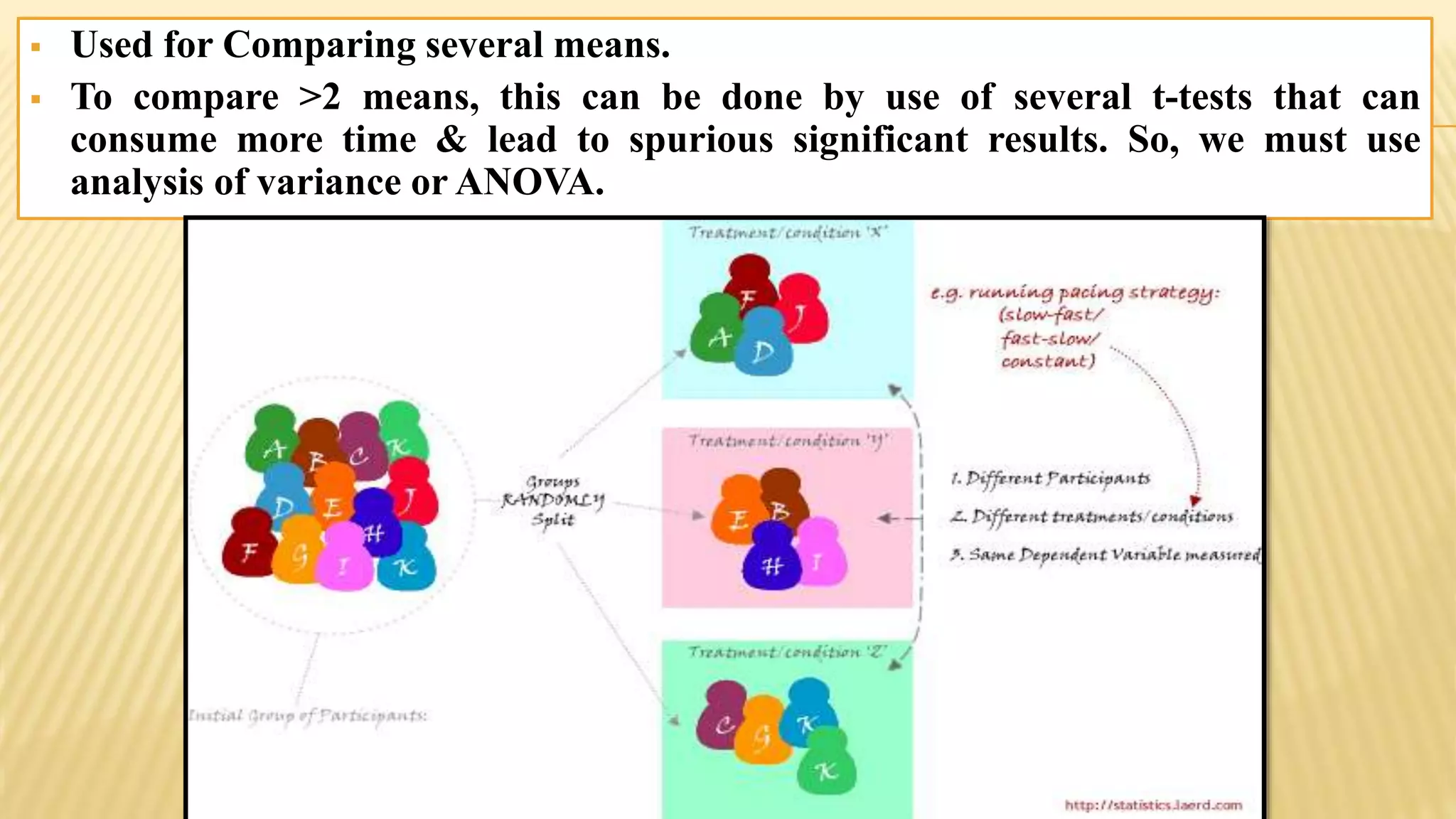

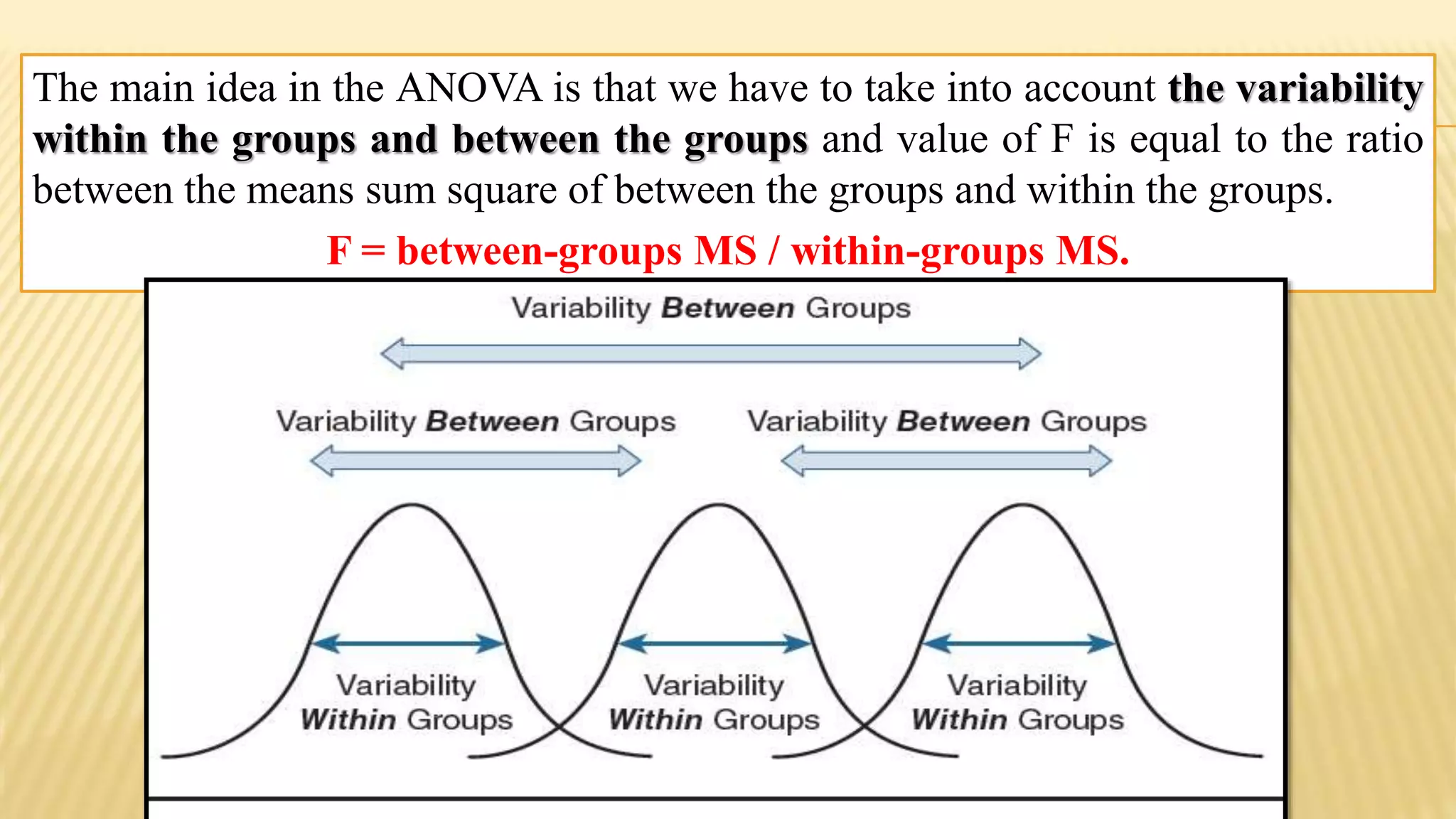






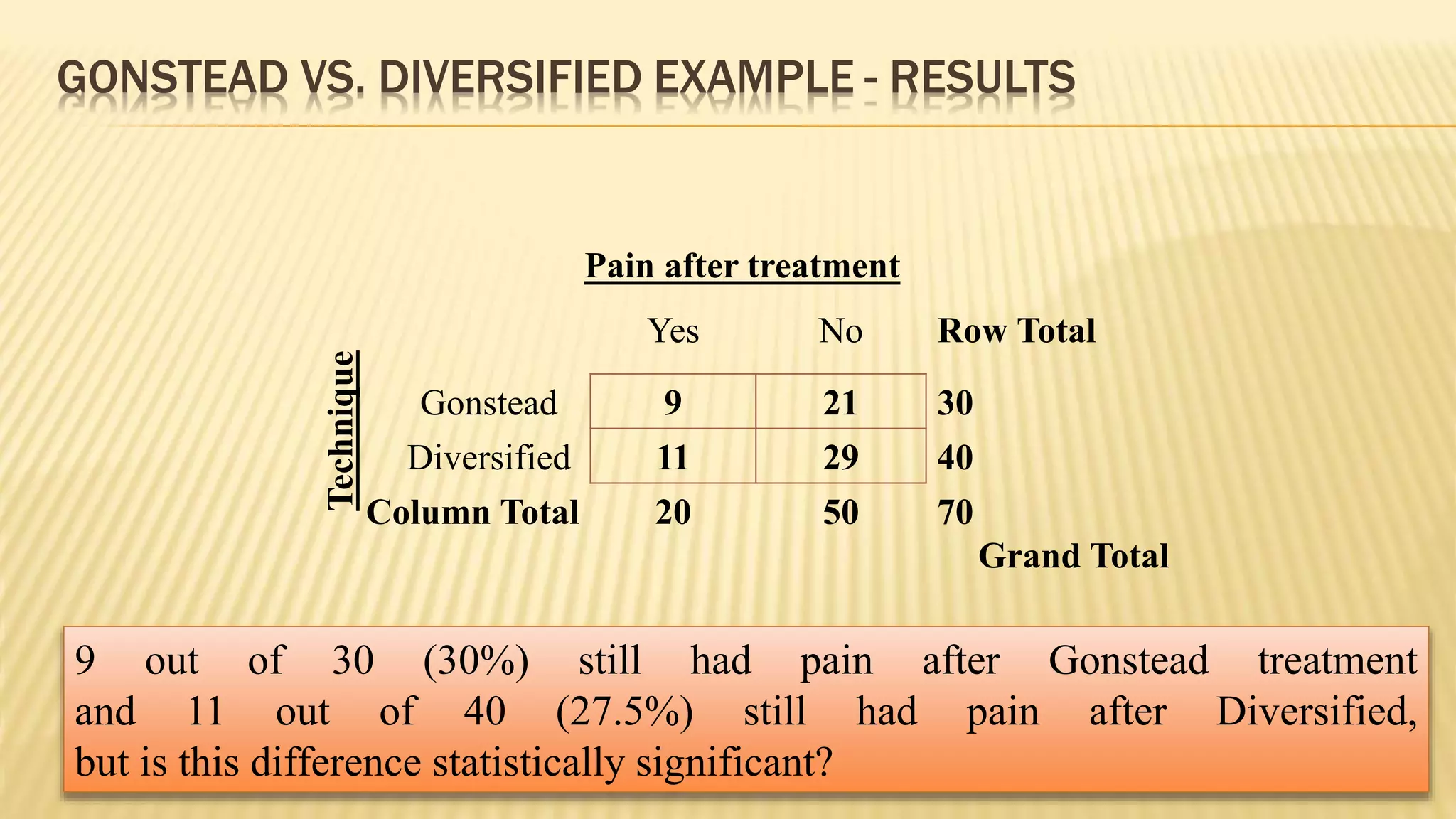
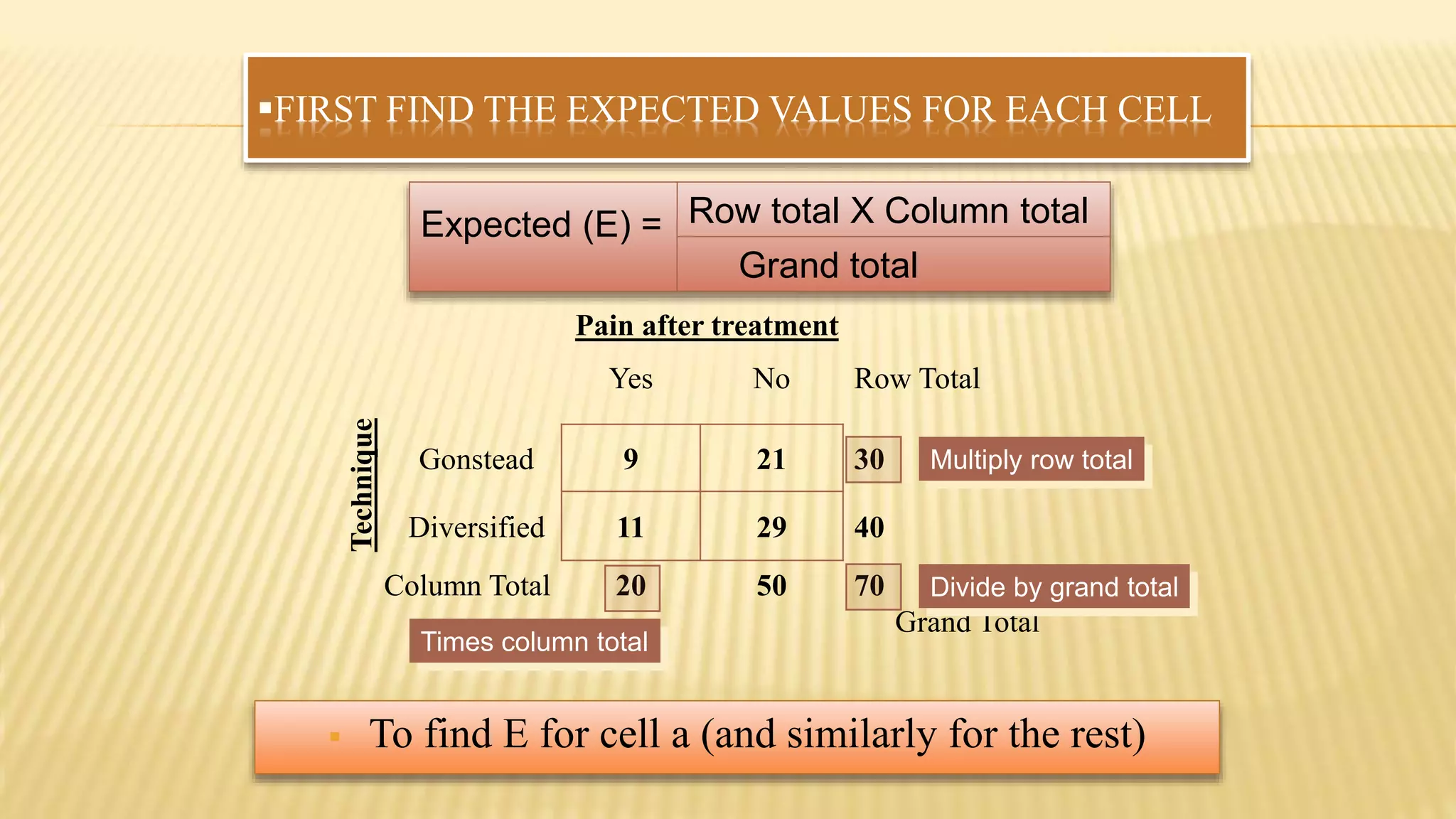


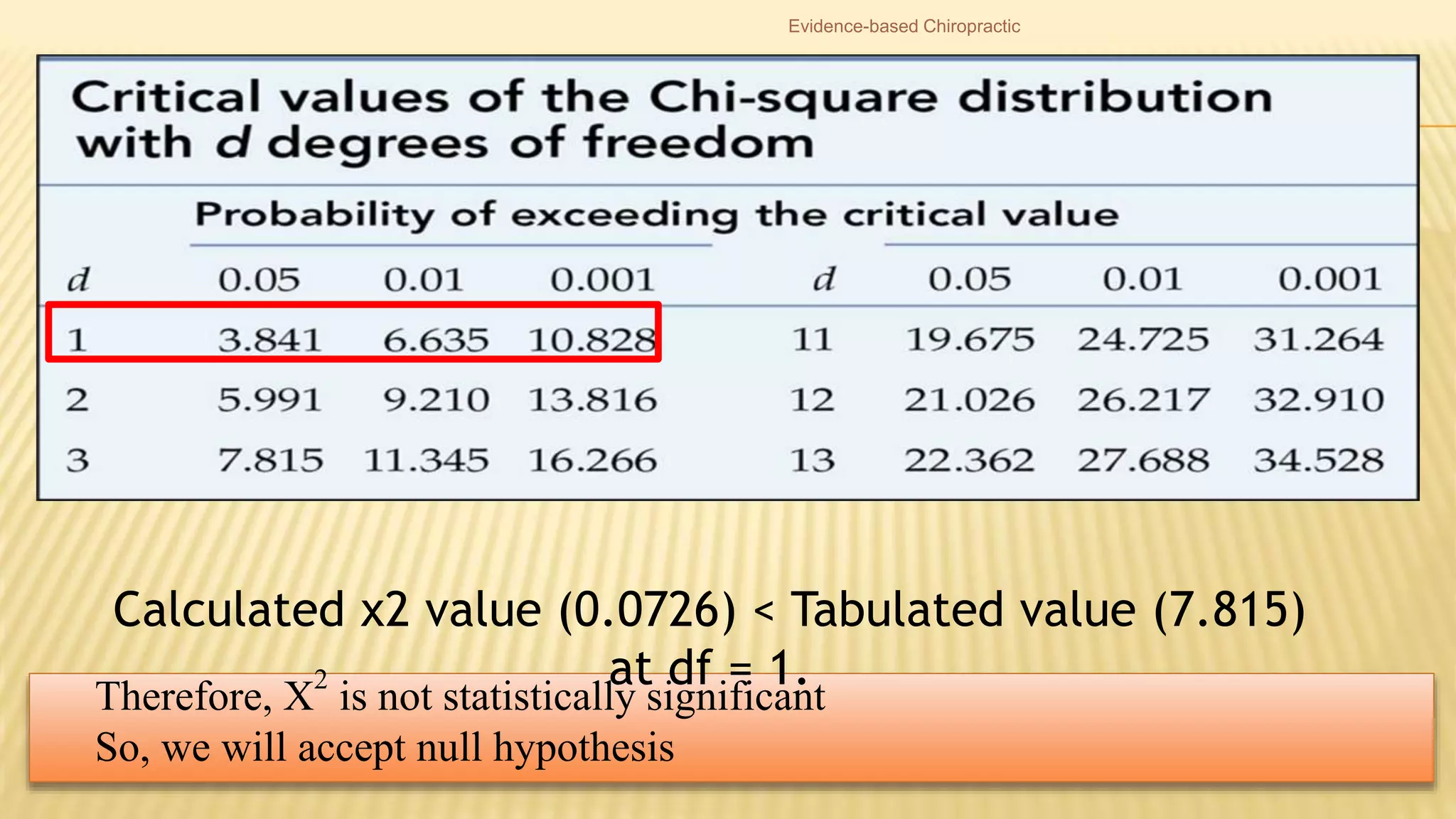












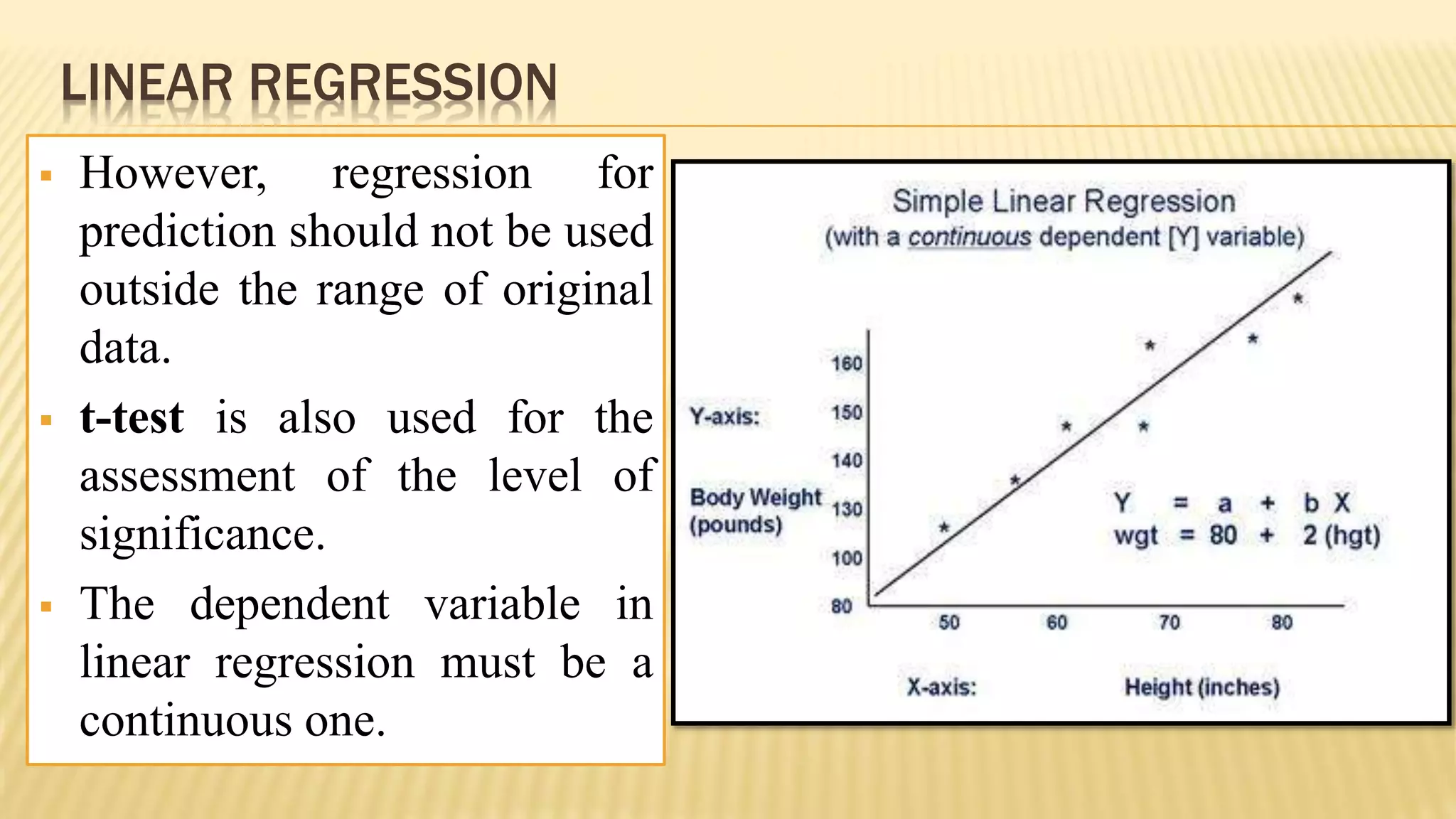
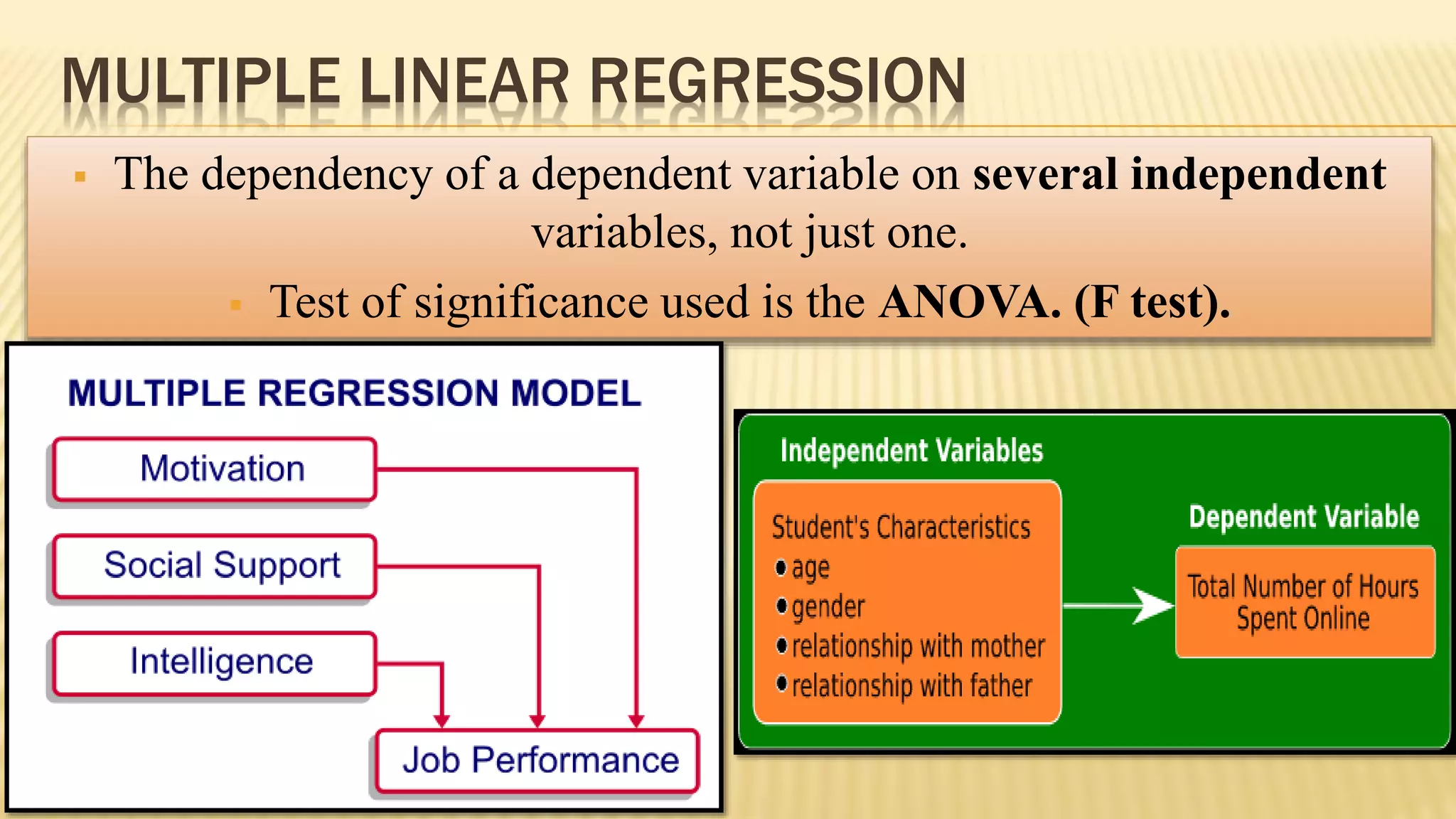

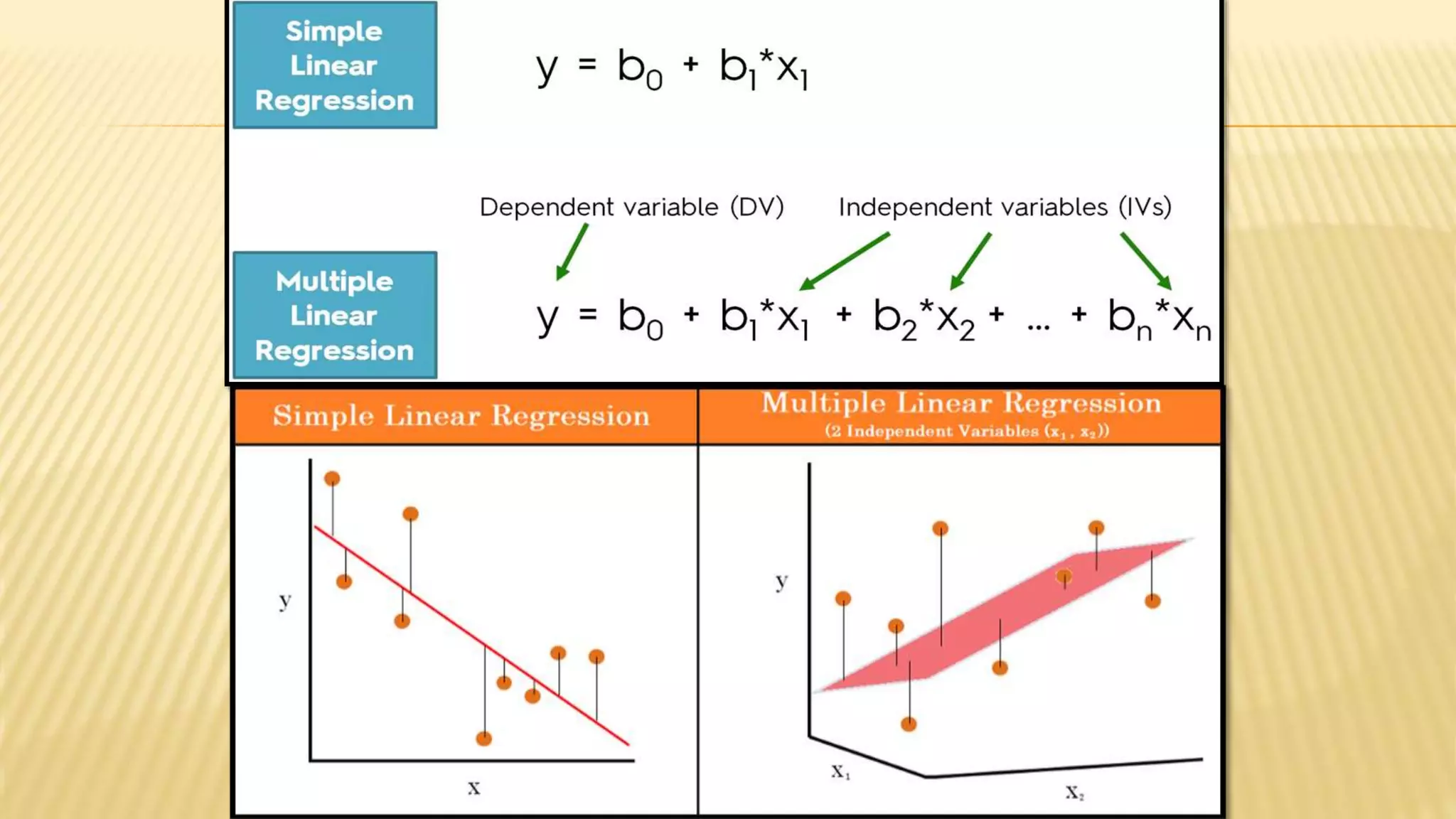


The document provides an overview of inferential statistics. It defines inferential statistics as making generalizations about a larger population based on a sample. Key topics covered include hypothesis testing, types of hypotheses, significance tests, critical values, p-values, confidence intervals, z-tests, t-tests, ANOVA, chi-square tests, correlation, and linear regression. The document aims to explain these statistical concepts and techniques at a high level.














































































![Apporach to lung biopsy [Auto-saved].pptx latest](https://cdn.slidesharecdn.com/ss_thumbnails/apporachtolungbiopsyauto-saved-251211225655-93258539-thumbnail.jpg?width=640&height=640&fit=bounds)








