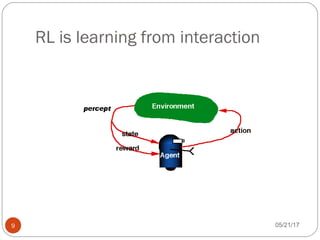
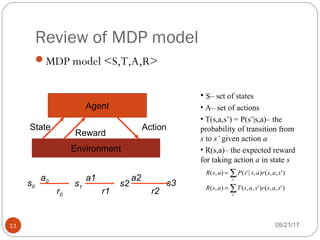
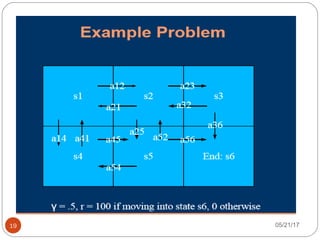
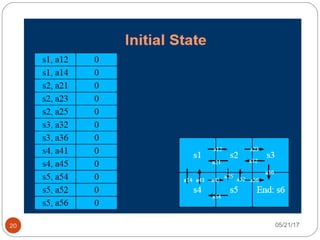
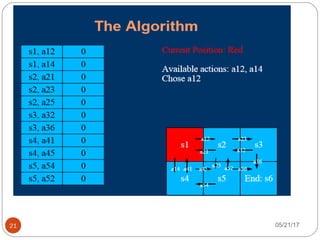
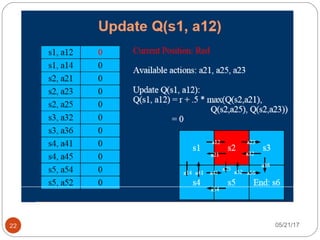
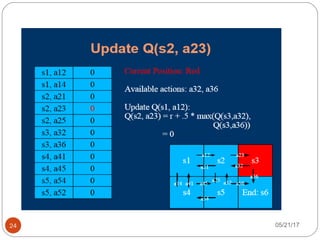
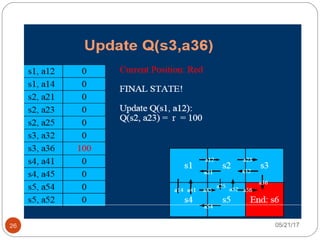
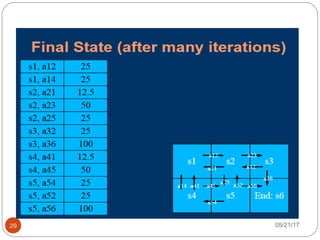
The document presents an overview of reinforcement learning, particularly focusing on the Q-learning algorithm and its application in sequential decision-making tasks. It describes how agents learn from interactions with their environment through rewards and penalties, aiming to find optimal policies to maximize long-term rewards. Key concepts such as the MDP model and exploration in partially observable states are also discussed.