Downloaded 626 times









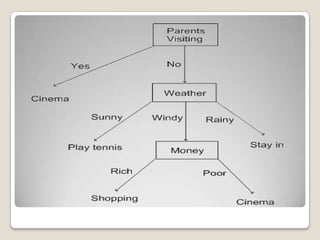


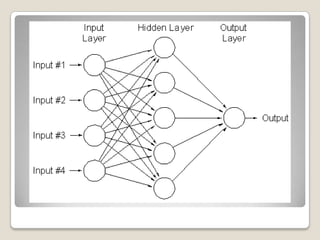




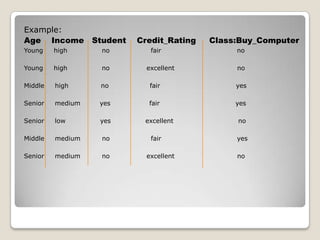

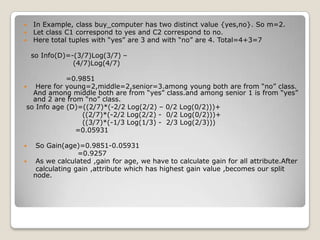
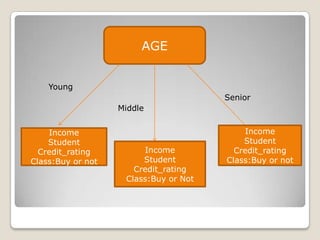






1. Machine learning is a branch of artificial intelligence concerned with algorithms that allow computers to learn from data without being explicitly programmed. 2. A major focus is automatically learning patterns from training data to make intelligent decisions on new data. This is challenging since the set of all possible behaviors given all inputs is too large to observe completely. 3. Machine learning is applied in areas like search engines, medical diagnosis, stock market analysis, and game playing by developing algorithms that improve automatically through experience. Decision trees, Bayesian networks, and neural networks are common algorithms.

































































