This document serves as a tutorial on reinforcement learning, discussing its fundamentals, the definition of reinforcement learning problems using Markov decision processes, and methods for solving these problems like dynamic programming, Monte Carlo methods, and temporal-difference learning. It explores the concepts of policies, value functions, and reward systems, highlighting their roles in maximizing cumulative rewards through exploration and learning from interactions with the environment. Additionally, it addresses practical applications, various examples, and control strategies while also emphasizing the importance of state representation, function approximation, and reward design.



![Robot in a room
+1
-1
START
actions: UP, DOWN, LEFT, RIGHT
UP
80% move UP
10% move LEFT
10% move RIGHT
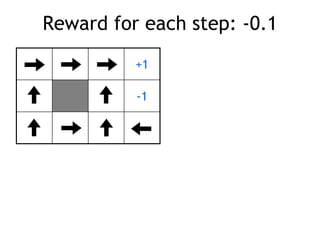
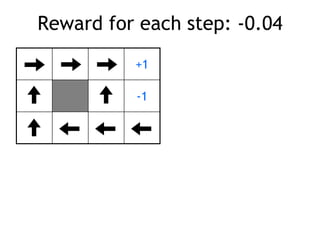
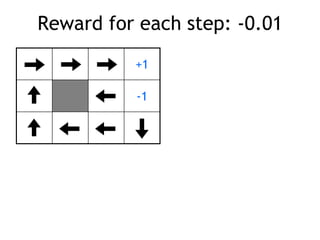
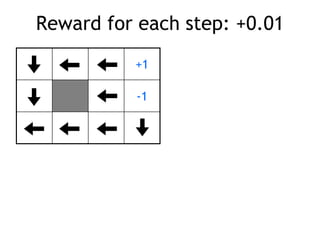
• reward +1 at [4,3], -1 at [4,2]
• reward -0.04 for each step
• what’s the strategy to achieve max reward?
• what if the actions were deterministic?](https://image.slidesharecdn.com/reinforcement-learning-240706133935-10b5c99b/85/reinforcement-learning-prsentation-for-c-4-320.jpg)
![Other examples
• pole-balancing
• TD-Gammon [Gerry Tesauro]
• helicopter [Andrew Ng]
• no teacher who would say “good” or “bad”
– is reward “10” good or bad?
– rewards could be delayed
• similar to control theory
– more general, fewer constraints
• explore the environment and learn from experience
– not just blind search, try to be smart about it](https://image.slidesharecdn.com/reinforcement-learning-240706133935-10b5c99b/85/reinforcement-learning-prsentation-for-c-5-320.jpg)
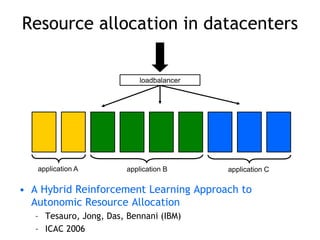

![Robot in a room
+1
-1
START
actions: UP, DOWN, LEFT, RIGHT
UP
80% move UP
10% move LEFT
10% move RIGHT
reward +1 at [4,3], -1 at [4,2]
reward -0.04 for each step
• states
• actions
• rewards
• what is the solution?](https://image.slidesharecdn.com/reinforcement-learning-240706133935-10b5c99b/85/reinforcement-learning-prsentation-for-c-8-320.jpg)
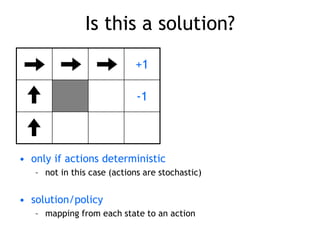
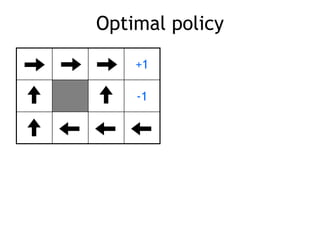
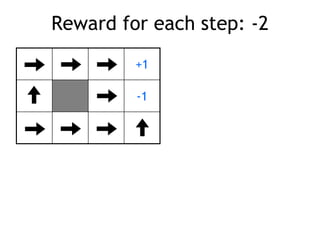
![Markov Decision Process (MDP)
• set of states S, set of actions A, initial state S0
• transition model P(s,a,s’)
– P( [1,1], up, [1,2] ) = 0.8
• reward function r(s)
– r( [4,3] ) = +1
• goal: maximize cumulative reward in the long run
• policy: mapping from S to A
– (s) or (s,a) (deterministic vs. stochastic)
• reinforcement learning
– transitions and rewards usually not available
– how to change the policy based on experience
– how to explore the environment
environment
agent
action
reward
new state](https://image.slidesharecdn.com/reinforcement-learning-240706133935-10b5c99b/85/reinforcement-learning-prsentation-for-c-16-320.jpg)










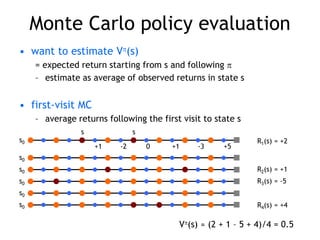


![Simulated experience
• 5-card draw poker
– s0: A, A, 6, A, 2
– a0: discard 6, 2
– s1: A, A, A, A, 9 + dealer takes 4 cards
– return: +1 (probably)
• DP
– list all states, actions, compute P(s,a,s’)
• P( [A,A,6,A,2], [6,2], [A,9,4] ) = 0.00192
• MC
– all you need are sample episodes
– let MC play against a random policy, or itself, or another
algorithm](https://image.slidesharecdn.com/reinforcement-learning-240706133935-10b5c99b/85/reinforcement-learning-prsentation-for-c-30-320.jpg)









![Features
• tile coding, coarse coding
– binary features
• radial basis functions
– typically a Gaussian
– between 0 and 1
[ Sutton & Barto, Reinforcement Learning ]](https://image.slidesharecdn.com/reinforcement-learning-240706133935-10b5c99b/85/reinforcement-learning-prsentation-for-c-42-320.jpg)














































![SecurityBoat_Service_Pitch_Deck[24158].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/securityboatservicepitchdeck24158-260121113056-452683e3-thumbnail.jpg?width=640&height=640&fit=bounds)



