2014
Mnih, Volodymyr, etal. "Human-level control through deep reinforcement learning." Nature 518.7540 (2015): 529-533.
Silver, David, et al. "Mastering the game of Go with deep neural networks and tree search." Nature 529.7587 (2016): 484-489.
Vinyals, Oriol, et al. "StarCraft II: A New Challenge for Reinforcement Learning."
2016
2017
Communication
Mordatch, Igor, andPieter Abbeel. "Emergence of Grounded Compositional Language in Multi-Agent Populations." arXiv preprint arXiv:1703.04908 (2017)
https://blog.openai.com/learning-to-communicate/
다른 모든 Agent에게 메세지 전달
51.
Actor-Critic + CentralizedQ-value
다른 Agent의 내부 정보를 공유
Lowe, Ryan, et al. "Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments." arXiv preprint arXiv:1706.02275 (2017)
https://blog.openai.com/learning-to-cooperate-compete-and-communicate/
Centralized Q-value
Sparse Reward
Kulkarni, TejasD., et al. "Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation." Advances in Neural Information Processing Systems. 2016.
Vezhnevets, Alexander Sasha, et al. "Feudal networks for hierarchical reinforcement learning." arXiv preprint arXiv:1703.01161 (2017).
30번 정도의 올바른 행동 후에 0이 아닌 Reward을 얻음
Feedback
밧줄을 타고 내려가서 해골을 피하고 사다리를 타서 열쇠를 얻어야 100점 얻음
Kulkarni, Tejas D.,et al. "Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation." Advances in Neural Information Processing Systems. 2016
Vezhnevets, Alexander Sasha, et al. "Feudal networks for hierarchical reinforcement learning." arXiv preprint arXiv:1703.01161 (2017)
Bacon, Pierre-Luc, Jean Harb, and Doina Precup. "The Option-Critic Architecture." AAAI. 2017
A A
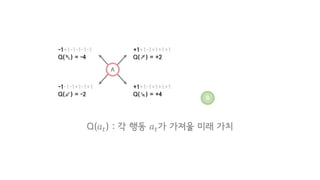
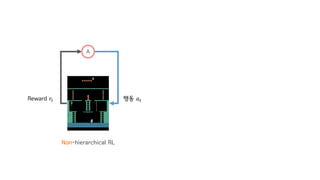
행동 𝑎"Reward 𝑟"
Non-hierarchical RL Hierarchical RL
61.
Kulkarni, Tejas D.,et al. "Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation." Advances in Neural Information Processing Systems. 2016
Vezhnevets, Alexander Sasha, et al. "Feudal networks for hierarchical reinforcement learning." arXiv preprint arXiv:1703.01161 (2017)
Bacon, Pierre-Luc, Jean Harb, and Doina Precup. "The Option-Critic Architecture." AAAI. 2017
A A
행동 𝑎"Reward 𝑟"
Non-hierarchical RL Hierarchical RL
목표1 목표2 목표3
62.
Kulkarni, Tejas D.,et al. "Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation." Advances in Neural Information Processing Systems. 2016
Vezhnevets, Alexander Sasha, et al. "Feudal networks for hierarchical reinforcement learning." arXiv preprint arXiv:1703.01161 (2017)
Bacon, Pierre-Luc, Jean Harb, and Doina Precup. "The Option-Critic Architecture." AAAI. 2017
A A
행동 𝑎"Reward 𝑟"
Non-hierarchical RL Hierarchical RL
밧줄 잡기
목표1 목표2 목표3
63.
Kulkarni, Tejas D.,et al. "Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation." Advances in Neural Information Processing Systems. 2016
Vezhnevets, Alexander Sasha, et al. "Feudal networks for hierarchical reinforcement learning." arXiv preprint arXiv:1703.01161 (2017)
Bacon, Pierre-Luc, Jean Harb, and Doina Precup. "The Option-Critic Architecture." AAAI. 2017
A A
행동 𝑎"Reward 𝑟"
Non-hierarchical RL Hierarchical RL
밧줄 잡기 사다리 내려가기
목표1 목표2 목표3
64.
Kulkarni, Tejas D.,et al. "Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation." Advances in Neural Information Processing Systems. 2016
Vezhnevets, Alexander Sasha, et al. "Feudal networks for hierarchical reinforcement learning." arXiv preprint arXiv:1703.01161 (2017)
Bacon, Pierre-Luc, Jean Harb, and Doina Precup. "The Option-Critic Architecture." AAAI. 2017
A A
행동 𝑎"Reward 𝑟"
Non-hierarchical RL Hierarchical RL
밧줄 잡기 사다리 내려가기 점프 하기
목표1 목표2 목표3
65.
Kulkarni, Tejas D.,et al. "Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation." Advances in Neural Information Processing Systems. 2016
Vezhnevets, Alexander Sasha, et al. "Feudal networks for hierarchical reinforcement learning." arXiv preprint arXiv:1703.01161 (2017)
Bacon, Pierre-Luc, Jean Harb, and Doina Precup. "The Option-Critic Architecture." AAAI. 2017
목표1 목표2 목표3
A A
행동 𝑎"Reward 𝑟"
𝑎*,"𝑎,,"
Non-hierarchical RL Hierarchical RL
𝑎-,"
밧줄 잡기 사다리 내려가기 점프 하기
66.
Kulkarni, Tejas D.,et al. "Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation." Advances in Neural Information Processing Systems. 2016
Vezhnevets, Alexander Sasha, et al. "Feudal networks for hierarchical reinforcement learning." arXiv preprint arXiv:1703.01161 (2017)
Bacon, Pierre-Luc, Jean Harb, and Doina Precup. "The Option-Critic Architecture." AAAI. 2017
목표1 목표2 목표3
- - ON
A A
목표 Ω
행동 𝑎"Reward 𝑟"
Non-hierarchical RL Hierarchical RL
𝑎*,"𝑎,," 𝑎-,"
67.
Kulkarni, Tejas D.,et al. "Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation." Advances in Neural Information Processing Systems. 2016
Vezhnevets, Alexander Sasha, et al. "Feudal networks for hierarchical reinforcement learning." arXiv preprint arXiv:1703.01161 (2017)
Bacon, Pierre-Luc, Jean Harb, and Doina Precup. "The Option-Critic Architecture." AAAI. 2017
목표1 목표2 목표3
- - ON
A A
목표 Ω
행동 𝑎-,"행동 𝑎"Reward 𝑟"
𝑎*,"𝑎,,"
Non-hierarchical RL Hierarchical RL
68.
Kulkarni, Tejas D.,et al. "Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation." Advances in Neural Information Processing Systems. 2016
Vezhnevets, Alexander Sasha, et al. "Feudal networks for hierarchical reinforcement learning." arXiv preprint arXiv:1703.01161 (2017)
Bacon, Pierre-Luc, Jean Harb, and Doina Precup. "The Option-Critic Architecture." AAAI. 2017
목표1 목표2 목표3
- - ON
A A
목표 Ω
행동 𝑎-,"행동 𝑎"Reward 𝑟" Reward 𝑟"
𝑎*,"𝑎,,"
Non-hierarchical RL Hierarchical RL
69.
Montezuma 잘 풀었다
Kulkarni,Tejas D., et al. "Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation." Advances in Neural Information Processing Systems. 2016
Vezhnevets, Alexander Sasha, et al. "Feudal networks for hierarchical reinforcement learning." arXiv preprint arXiv:1703.01161 (2017)
Bacon, Pierre-Luc, Jean Harb, and Doina Precup. "The Option-Critic Architecture." AAAI. 2017
암기로 풀 수없는 문제
Weber, Théophane, et al. "Imagination-Augmented Agents for Deep Reinforcement Learning." arXiv preprint arXiv:1707.06203 (2017).
https://deepmind.com/blog/agents-imagine-and-plan/
73.
Weber, Théophane, etal. "Imagination-Augmented Agents for Deep Reinforcement Learning." arXiv preprint arXiv:1707.06203 (2017).
https://deepmind.com/blog/agents-imagine-and-plan/
실제로 일어날 일을 시뮬레이션으로 (internal simulation) 상상해 보고 행동
74.
Model-free RL +Model-based RL
Deep Q-learning
Policy Gradient
…
75.
Model-free RL +Model-based RL
Imagination
Weber, Théophane, et al. "Imagination-Augmented Agents for Deep Reinforcement Learning." arXiv preprint arXiv:1707.06203 (2017).
https://deepmind.com/blog/agents-imagine-and-plan/
Duan, Yan, etal. "RL $^ 2$: Fast Reinforcement Learning via Slow Reinforcement Learning." arXiv preprint arXiv:1611.02779 (2016).
https://www.youtube.com/playlist?list=PLp24ODExrsVeA-ZnOQhdhX6X7ed5H_W4q
87.
Duan, Yan, etal. "RL $^ 2$: Fast Reinforcement Learning via Slow Reinforcement Learning." arXiv preprint arXiv:1611.02779 (2016).
한판 = 한 Episode
88.
Duan, Yan, etal. "RL $^ 2$: Fast Reinforcement Learning via Slow Reinforcement Learning." arXiv preprint arXiv:1611.02779 (2016).
Episode가 끝나도 정보를 리셋하지 않고 계속 사용
89.
Duan, Yan, etal. "RL $^ 2$: Fast Reinforcement Learning via Slow Reinforcement Learning." arXiv preprint arXiv:1611.02779 (2016).
N번의 Episode를 하나의 Trial로 정의
N번의 Episode를 통해서 최적의 플레이를 찾는 방법을 학습
90.
Duan, Yan, etal. "RL $^ 2$: Fast Reinforcement Learning via Slow Reinforcement Learning." arXiv preprint arXiv:1611.02779 (2016).
새로운 시도에는 새로운 게임(여기서는 새로운 맵)을 플레이
91.
Duan, Yan, etal. "RL $^ 2$: Fast Reinforcement Learning via Slow Reinforcement Learning." arXiv preprint arXiv:1611.02779 (2016).
새로운 시도에는 새로운 게임(여기서는 새로운 맵)을 플레이
RL2: Recurrent Network
Duan,Yan, et al. "RL $^ 2$: Fast Reinforcement Learning via Slow Reinforcement Learning." arXiv preprint arXiv:1611.02779 (2016).
https://www.youtube.com/playlist?list=PLp24ODExrsVeA-ZnOQhdhX6X7ed5H_W4q
Episode의 Return이 아닌 Trial의 Return을 optimize
100.
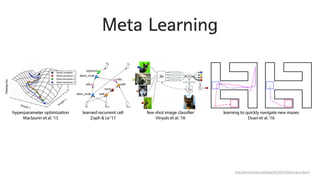
Model-Agnostic Meta-Learning
Finn, Chelsea,Pieter Abbeel, and Sergey Levine. "Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks." arXiv preprint arXiv:1703.03400 (2017).
여러 Task를 동시에 학습해 weight의 central point를 찾음
그리고 1번의 gradient update로 새 Task에 적응
Gated-Attention + A3C
Hermann,Karl Moritz, et al. "Grounded language learning in a simulated 3D world." arXiv preprint arXiv:1706.06551 (2017)
https://sites.google.com/view/gated-attention/home
134.
Self-Supervision + A3C
Chaplot,Devendra Singh, et al. "Gated-Attention Architectures for Task-Oriented Language Grounding." arXiv preprint arXiv:1706.07230 (2017)
https://www.youtube.com/watch?v=wJjdu1bPJ04
물체들의 관계까지 이해해야 하는 Agent
강화 학습 캉화학습 강화 학습 강화 학습
강화 학습 강화 학습 강화 학습 강화 학습
강화 학습 강화 학습 강화 학습 강화 학습
강화 학습 강화 학습 강화 학습 감화 학습
강화 학습 강화 학습 강화 학습 강화 학습
강회 학습 강화 학습 강화 학습 강화 학습
156.
Neural Turing Machine
DifferentiableNeural Computer
Neural Module Network
Neural Programmer-Interpreter
Programmable Agent
…
강화 학습 외에도 관심있는 분야
Graves, Alex, Greg Wayne, and Ivo Danihelka. "Neural turing machines." arXiv preprint arXiv:1410.5401 (2014).
Graves, Alex, et al. "Hybrid computing using a neural network with dynamic external memory." Nature 538.7626 (2016): 471-476.
Andreas, Jacob, et al. "Neural module networks." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016.
Reed, Scott, and Nando De Freitas. "Neural programmer-interpreters." arXiv preprint arXiv:1511.06279 (2015).
Denil, Misha, et al. "Programmable agents." arXiv preprint arXiv:1706.06383(2017).











































































































































































![[DL輪読会]Deep Learning 第7章 深層学習のための正則化](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning7-180601022541-thumbnail.jpg?width=640&height=640&fit=bounds)













![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial...](https://cdn.slidesharecdn.com/ss_thumbnails/readingpaper20170428-170428030525-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Reinforcement Learning with Deep Energy-Based Policies](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20170406-170407002545-thumbnail.jpg?width=640&height=640&fit=bounds)



![[데이터야놀자2107] 강남 출근길에 판교/정자역에 내릴 사람 예측하기](https://cdn.slidesharecdn.com/ss_thumbnails/predict-get-off-station-171012210042-thumbnail.jpg?width=640&height=640&fit=bounds)

![[NDC2017 : 박준철] Python 게임 서버 안녕하십니까 - 몬스터 슈퍼리그 게임 서버](https://cdn.slidesharecdn.com/ss_thumbnails/ndc17python-0425v08-170426123108-thumbnail.jpg?width=640&height=640&fit=bounds)


![[IGC 2016] 넷게임즈 김복식 - 중국 모바일 게임과 캐주얼 게임 디자인](https://cdn.slidesharecdn.com/ss_thumbnails/2-161009034159-thumbnail.jpg?width=640&height=640&fit=bounds)










![[해외세미나]서울-키에프시 교통정책 및 빅데이터솔루션 지식공유 워크샵 강연](https://cdn.slidesharecdn.com/ss_thumbnails/random-170809083329-thumbnail.jpg?width=640&height=640&fit=bounds)



![[RLkorea] 각잡고 로봇팔 발표](https://cdn.slidesharecdn.com/ss_thumbnails/rlkorea-robotarm-190303021332-thumbnail.jpg?width=640&height=640&fit=bounds)
























![Random Thoughts on Paper Implementations [KAIST 2018]](https://cdn.slidesharecdn.com/ss_thumbnails/kaist2018-180426031539-thumbnail.jpg?width=640&height=640&fit=bounds)
