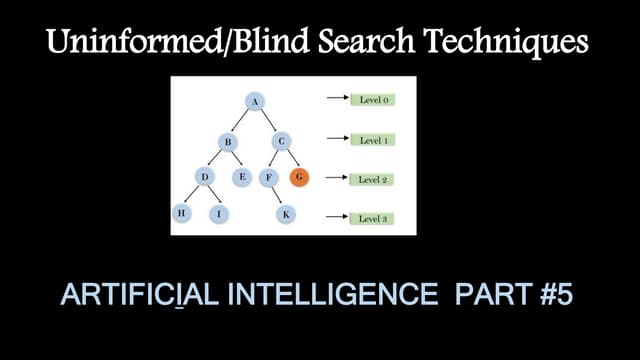
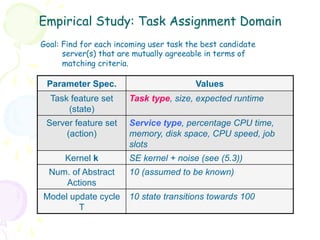
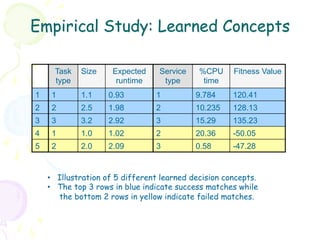
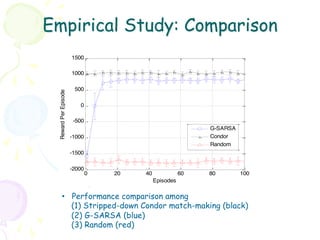
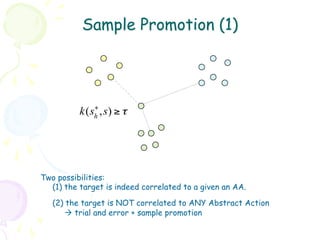
Downloaded 58 times







![Reinforcement Learning Algorithms …
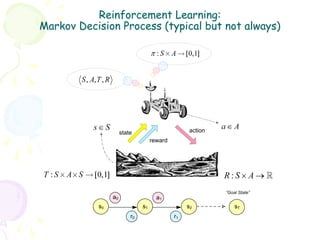
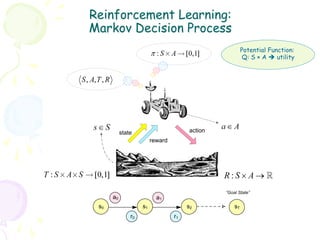
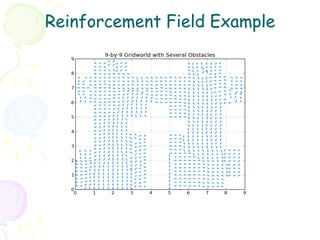
• In most complex domains, T, R need to be estimated à RL
framework
– Temporal Difference (TD) Learning st St+1
• Q-learning, SARSA, TD(λ) MDP
rt
– Example of TD learning: SARSA
at
st
– SARSA Update Rule:
Q(s, a) ← Q(s, a) + α [r + γ Q(sʹ′, aʹ′) − Q(s, a)]
– Q-learning Update Rule:
Q( s, a) ← Q(s, a) + α ⎡r + γ max Q(sʹ′, aʹ′) − Q(s, a) ⎤
⎣ aʹ′ ⎦
– Function approximation, SMC, Policy Gradient, etc.
“But the problems are …”](https://image.slidesharecdn.com/grl2-130331113429-phpapp01/85/Generalized-Reinforcement-Learning-9-320.jpg)





![Using GPR: A Thought Process (1)
• Need to gauge the similarity/correlation between any two decisions
à kernel functions k (x, xʹ′)
• Need to estimate the (potential) value of an arbitrary combination of
state and actions without needing to explore all the state space à
the value predictor is a “function” of kernels
• The class of functions that exhibit the above properties à
functions drawn from Reproduced Kernel Hilbert Space (RKHS)
n n
Q + (⋅) = ∑αi k(xi ,⋅) Q + (x * ) = ∑α k(x ,x )
i i *
i=1 i=1
• GP regression (GPR) method induces such functions [GPML, Rasmussen]
– Representer Theorem [B. Schölkopf et al. 2000]
( )
cost (x1, y1, f (x1 )),...,(xm , ym , f (xm )) + regularizer f ( )](https://image.slidesharecdn.com/grl2-130331113429-phpapp01/85/Generalized-Reinforcement-Learning-15-320.jpg)

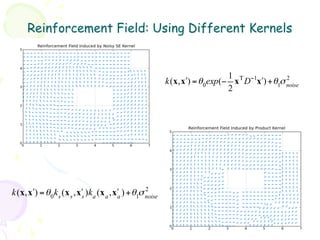
![*GPR I: Gaussian Process
• GP: a probability distribution over a set of random
variables (or function values), any finite set of
which has a (joint) Gaussian distribution
y | x, M i N f ,σ noise I ⇒ f | M i GP m(x),k(x, x!)
( ) ( )
– Given a prior assumption over functions (See previous page)
– Make observations (e.g. policy learning) and gather evidences
– Posterior p.d. over functions that eliminate those not consistent
with the evidence Prior and Posterior
2 2
1 1
output, f(x)
output, f(x)
0 0
−1 −1
−2 −2
−5 0 5 −5 0 5
input, x input, x
Predictive distribution:
2
p(y⇤ |x⇤ x y) ⇠ N k(x⇤ x)> [K + noise I] y
-1](https://image.slidesharecdn.com/grl2-130331113429-phpapp01/85/Generalized-Reinforcement-Learning-17-320.jpg)

![*GPR III: Value Prediction
• Predictive Distribution with a test point
n
+ Τ −1
q* = Q (x* ) = k(x* ) K ( X , X ) q = ∑α k(x ,x )
i i *
i=1
−1
cov(q* ) = k(x* ,x* ) − k T
* (K +σ )
2
n
I k*
– Prediction of a new test is achieved by comparing
with all the samples retained in the memory
– Predictive value largely depends on correlated
samples
– The (sample) correlation hypothesis (i.e. kernel)
applies to in all state space
– Reproducing property from RKHS [B. Schölkopf and A.
Smola,2002]
(x∗ , Q+ (x∗ )) : k (⋅, x∗ ) → Q+ (⋅), k (⋅, x∗ ) = Q+ (x∗ )](https://image.slidesharecdn.com/grl2-130331113429-phpapp01/85/Generalized-Reinforcement-Learning-19-320.jpg)


![i, j 1
m
( ) ) Q ( ) å
QQ (s s), xaQ =are + x =s , containing a sequence of predictive values with respect
+
corresponding targetsxQ denotedx1 ,..., ixn1α1 k ( xxx i )
(x q
s a ,a
= , x i ,..., m (6.2)
roduct definition in (5.59), one can thus evaluate the inner product between Q
2
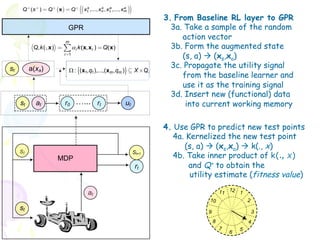
3. From Baseline RL layer to GPR
ent traverses the state X. With the assumption ofaasequence ofktraining samples will be
to the input in space with m steps, noisy kernel ( x i , x j ) ij as the covariance
pattern k ( , x ) in terms of GPR (next)
function, the predictive distribution),...,( x ,s targets isa thus, given by q X f, X ~ N q, [ X ] ,
(s ) Q x ( xQq1 over newn ,m 1 ,..., xm Q where | and (6.2)
d retained inQ memory: : 1,
s a
x1 ,..., x q x) X Q,
2. Use the generalization capacity
m
k (× xs , xa )) =m (× )
,( k ,x
Q, k ( , x ) k ( x, x i ) Q( x ) (5.63)
and their corresponding observedfrom GP to predict values
where i
denote the set of augmented states + fitness
i 1 m () k ( ,a )
agent traverses the state space with Q steps,× sequence of training samples will be
×, x
1
lpful for the moment to consider these training samplesqin
q K X , X K X, X
as a functionalExpand
- datathe action into its
(5.51)
st
and retained a(xa) Ω :({(,x1 ),...,( x m , qm )m , qX 1)} ,
: x1 q1, q1 ),...,(x
in memory:
X K X ,X * * *
m Q
where X and Q,
nced by the experience particles distributed K X , X K state space. The mechanism
over the X , X K X , X *
parametric representation
(5.52)
denote the set of that theto Section 6.5. Each corresponding observed fitness
deferred
- Kernel assumption accounts for
, their values are note augmented statesarrive attheir experience particle the weight-space
and (5.51) and (5.52) is similar to effectively
Here we derivation to
random effect in the action
rol policy that generalizes into the neighboring (augmented)for morespace through one
state details. With only
helpful formodel; however, to consider these training samples in
the moment the interested readers may refer to [14, 107]
…... rt as a functional data
st at r0 111 ut 1b. Estimate utility for each
the kernel to be(5.51) is reducedshortly. The similarity of any two particles (or
test point, discussed to
“regular”
renced by the experience particles distributed over the state space. The mechanism state-action pair
wo referenced augmented states) takes into account both the state vector x s and
1a. Baseline
ng their values are deferred to Section 6.5. Each experience particle effectively RL: e.g. SARSA
x a . This formulation is made possible by allowing the action to take on continuous
ontrol policy that generalizes into the neighboring (augmented) state space- MDP based RL treats actions
108
through
g with the use of a kernel function as a correlation hypothesis associating as decision choices
one
st St+1
of the kernel to be discussed shortly. The similarity of any two particles (or
ate to another through their inner products in the kernel-induced feature - Estimate utility without looking
MDP space
rt
,above constructs defined, the nexttakes into account both the the reinforcement action parameters
at
two referenced augmented states) step toward establishing state vector x s and
esent the fitness function made possible by integrates with parametric actions and,
r x . This formulation is in a manner that allowing the action to take on continuous
a
11 12 1
me, serves as a “critic” for the policy at
embedded in experience particles. In this 10 2
ong with the use of a kernel function as a correlation hypothesis associating one
represent the fitness value function through a progressively-updated Gaussian
s 9 3
t
state to another through their inner products in the kernel-induced feature space
8 4
7 5
he above constructs defined, the next step toward establishing the reinforcement 6](https://image.slidesharecdn.com/grl2-130331113429-phpapp01/85/Generalized-Reinforcement-Learning-22-320.jpg)
![Policy Estimation Using Q+
• Policy Evaluation using Q+(xs,xa) ~ GP
– Q+ can be estimated through GPR
– Define policy through Q+ : e.g. softmax (Gibbs
distr.)
exp !Q + s,a (i) / τ $
# ( ) &
" %
(
π s,a (i)
) =
∑ j exp !Q + (s,a ( j) ) / τ $
" %
exp !Q + (x s ,x (i) ) / τ $
# ( a ) &
" %
=
∑ j exp !Q + (x s ,x (a j) ) / τ $
#
" ( ) &
%
• π [Q+ ] is an increasing functional over Q+](https://image.slidesharecdn.com/grl2-130331113429-phpapp01/85/Generalized-Reinforcement-Learning-24-320.jpg)

![Particle Reinforcement (2)
• Maintain a set of state partitions
• Keep track of both positive particles
and negative particles
• positive particles refer to the desired
control policy while negative particles
+ point out what to avoid
-
• “Interpolate” control policy. Recall:
+
-
+ (
π [Q + ] = π s,a (i) )
-
exp !Q + (x s ,x (i) ) / τ $
# ( a ) &
" %
=
∑ j exp !Q + (x s ,x (a j) ) / τ $
#
" ( ) &
%
“Problem: How to replace older samples?”](https://image.slidesharecdn.com/grl2-130331113429-phpapp01/85/Generalized-Reinforcement-Learning-26-320.jpg)

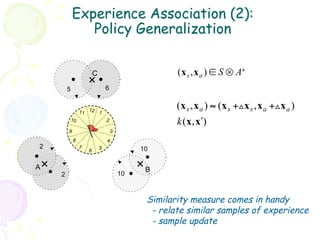

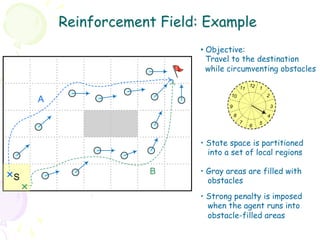
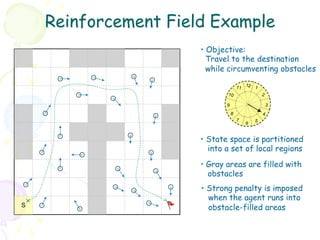
![Action Operator: Step-by-Step (1)
• At a given state s ∈ S, the agent
chooses a (parametric) action
according to the current policy π [Q+ ]
• The action operator resolves the
random effect in action parameters
through a sampling process such that 11 12 1
the (stochastic) action is reduced to 10 2
a fixed action vector x a .
9 3
• The action vector resolved from
8 4
above is subsequently paired with the 7 5
current state vector x s to form an 6
augmented state x = (xs , xa ).](https://image.slidesharecdn.com/grl2-130331113429-phpapp01/85/Generalized-Reinforcement-Learning-34-320.jpg)



















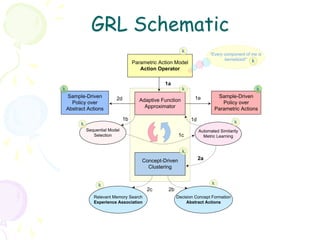
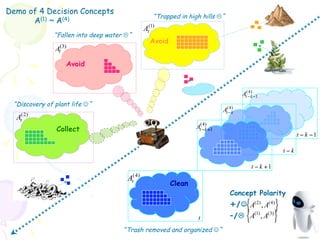


1. The document discusses challenges with standard reinforcement learning formulations due to large state and action spaces. It proposes representing actions as operators that induce state transitions rather than discrete choices. 2. It introduces a generalized reinforcement learning framework using kernel methods to compare "decision contexts" or state-action pairs. Value functions are represented as vectors in a Reproducing Kernel Hilbert Space rather than concrete mappings. 3. Gaussian process regression is used to predict values for unseen state-action pairs by comparing them to stored samples, enabling generalization beyond explored contexts. Hyperparameters are tuned to best explain sample data using marginal likelihood optimization.