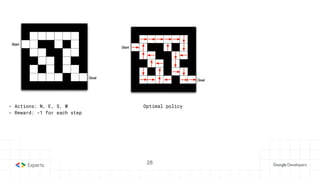
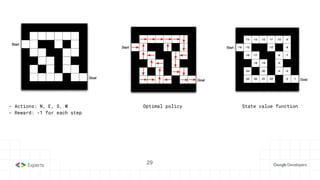
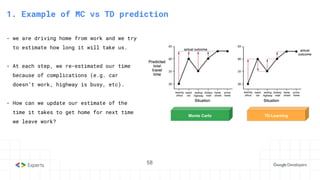
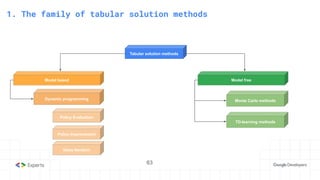
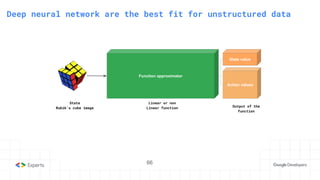
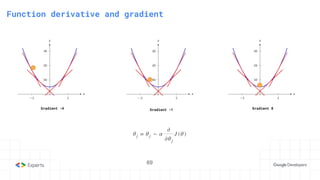
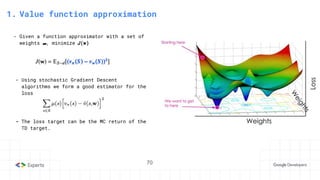
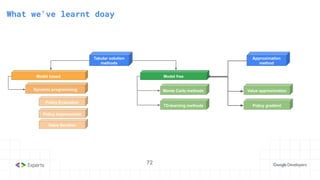
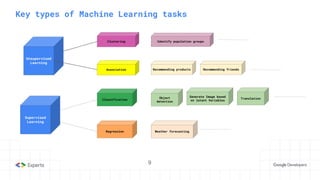
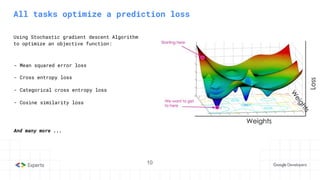
The document provides an overview of reinforcement learning (RL) concepts, including the frameworks, agent-environment interaction, and different methods such as Monte Carlo and Temporal Difference learning. Key topics include the Markov Decision Process, state-action value functions, and various algorithms for policy evaluation and improvement. The importance of using approximators for function estimation in complex environments, like those involving deep neural networks, is also emphasized.

















![22
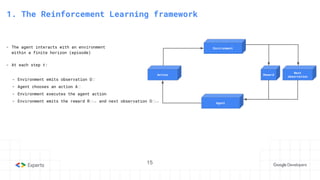
- A mathematical formulation of the agent interaction with the environment
- It requires that the environment is fully observable
6. Markov decision process
- An MDP is a tuple (S, A, p, γ) where:
- S is the set of all possible states
- A is the set of all possible actions
- p(r,s′ | s,a) is the transition function or joint probability of a reward r and next state s′,
given a state s and action a
- γ ∈ [0, 1] is a discount factor that trades off later rewards to earlier ones](https://image.slidesharecdn.com/headfirstreinforcementlearning1-221211212731-23ebcef4/85/Head-First-Reinforcement-Learning-22-320.jpg)