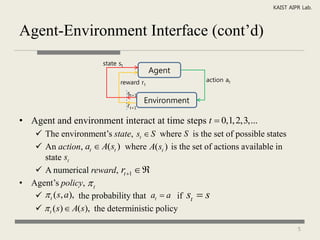
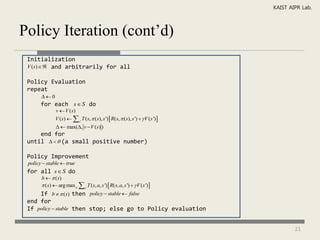
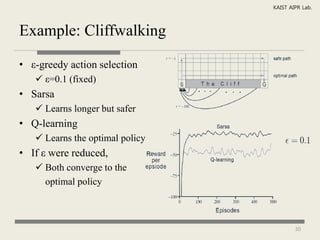
The document discusses reinforcement learning and Markov decision processes. It introduces reinforcement learning as an approach to machine learning where an agent learns to take actions in an environment to maximize rewards. Markov decision processes are described as a framework involving states, actions, transitions between states, and rewards. The goals of reinforcement learning are to learn a policy that maps states to optimal actions to maximize long-term rewards.





























![KAIST AIPR Lab.
References
[1] R. Sutton and A. Barto. Reinforcement Learning: An
Introduction. Pages 51-158, 1998.
[2] S. Russel and P. Norvig. Artificial Intelligence: A Modern
Approach. Pages 613-784, 2003.
32](https://image.slidesharecdn.com/jylee-reinforcementlearningdptdlearning-100603082412-phpapp01/85/Reinforcement-Learning-32-320.jpg)



































![[Dl輪読会]introduction of reinforcement learning](https://cdn.slidesharecdn.com/ss_thumbnails/dlintroductionofreinforcementlearning-161121061444-thumbnail.jpg?width=640&height=640&fit=bounds)



























![[DL輪読会]近年のオフライン強化学習のまとめ —Offline Reinforcement Learning: Tutorial, Review, an...](https://cdn.slidesharecdn.com/ss_thumbnails/20200626journalclubpub-200630064755-thumbnail.jpg?width=640&height=640&fit=bounds)



























