Download as PDF, PPTX

































![References
[1] Sutton, Richard S., and Andrew G. Barto. Reinforcement learning: An
introduction. MIT press, 1998.
[2] Mnih, Volodymyr, et al. "Human-level control through deep reinforcement
learning." Nature 518.7540 (2015): 529-533.
[3] Van Hasselt, Hado, Arthur Guez, and David Silver. "Deep Reinforcement
Learning with Double Q-Learning." AAAI. 2016.
[4] Wang, Ziyu, et al. "Dueling network architectures for deep reinforcement
learning." arXiv preprint arXiv:1511.06581 (2015).
[5] Schaul, Tom, et al. "Prioritized experience replay." arXiv preprint
arXiv:1511.05952 (2015).
59](https://image.slidesharecdn.com/reinforcementlearning-170904070210/85/Introduction-of-Deep-Reinforcement-Learning-59-320.jpg)


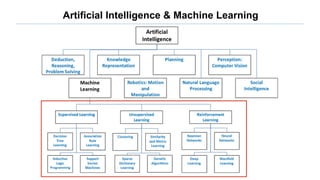
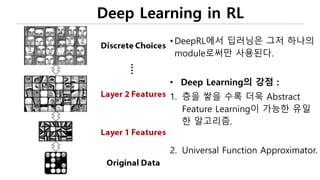
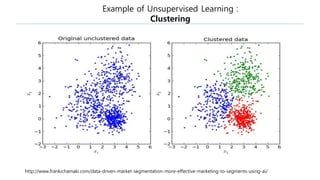
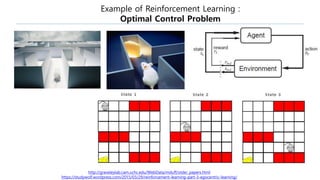
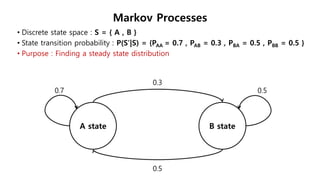
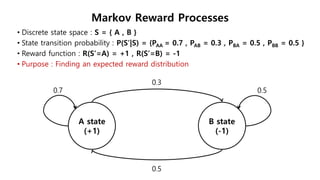
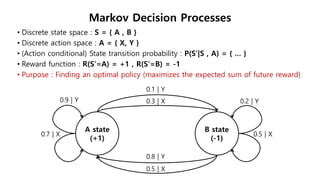
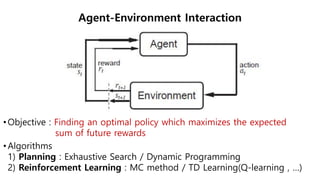
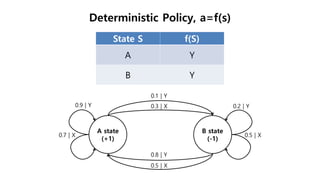
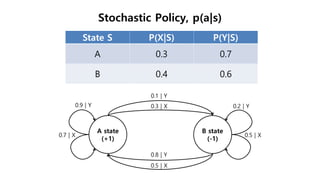
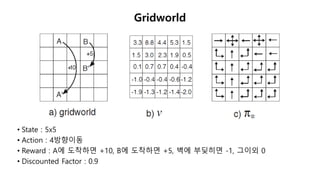
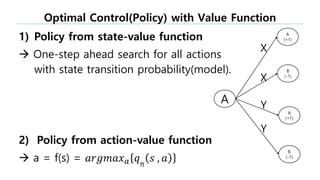
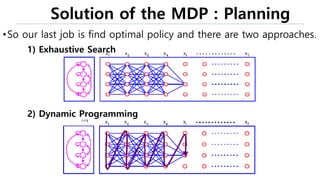
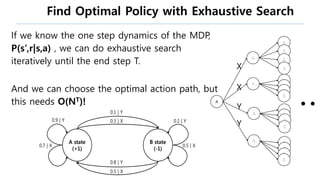
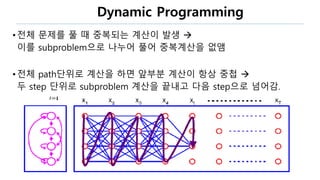
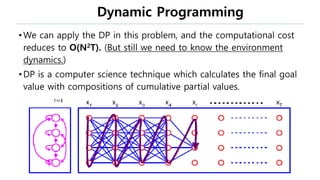
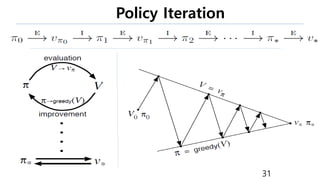
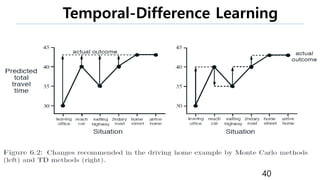
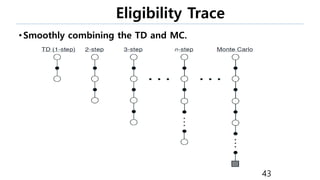
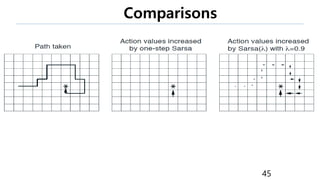
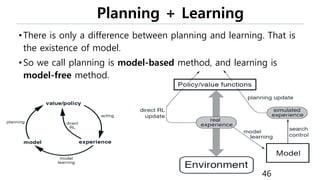
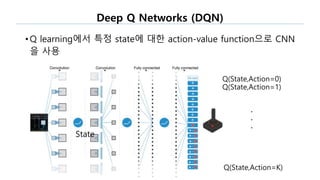
The document discusses the fundamentals of reinforcement learning (RL) as a branch of artificial intelligence, differentiating it from supervised and unsupervised learning. It delves into key concepts such as Markov decision processes, value functions, and the integration of deep learning techniques in RL, highlighting algorithms like Q-learning and deep Q-networks (DQN). Additionally, it covers advancements in DQN, including double DQN and prioritized experience replay for enhanced learning efficiency.


![[기초개념] Graph Convolutional Network (GCN)](https://cdn.slidesharecdn.com/ss_thumbnails/agistdkimgcn190507-190507153736-thumbnail.jpg?width=640&height=640&fit=bounds)


















![[DL輪読会]Hindsight Experience Replay](https://cdn.slidesharecdn.com/ss_thumbnails/her-180105002310-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Meta Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/metarl-190201005548-thumbnail.jpg?width=640&height=640&fit=bounds)










![[2017 PYCON 튜토리얼]OpenAI Gym을 이용한 강화학습 에이전트 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/random-170816031315-thumbnail.jpg?width=640&height=640&fit=bounds)



![[143]알파글래스의 개발과정으로 알아보는 ar 스마트글래스 광학 시스템](https://cdn.slidesharecdn.com/ss_thumbnails/43ar-171016045445-thumbnail.jpg?width=640&height=640&fit=bounds)
![[124]자율주행과 기계학습](https://cdn.slidesharecdn.com/ss_thumbnails/124-171016052833-thumbnail.jpg?width=640&height=640&fit=bounds)
![[132]웨일 브라우저 1년 그리고 미래](https://cdn.slidesharecdn.com/ss_thumbnails/321-171016021602-thumbnail.jpg?width=640&height=640&fit=bounds)

![[142] 생체 이해에 기반한 로봇 – 고성능 로봇에게 인간의 유연함과 안전성 부여하기](https://cdn.slidesharecdn.com/ss_thumbnails/142-171016082840-thumbnail.jpg?width=640&height=640&fit=bounds)
![[141] 오픈소스를 쓰려는 자, 리베이스의 무게를 견뎌라](https://cdn.slidesharecdn.com/ss_thumbnails/141deview2017-171016055311-thumbnail.jpg?width=640&height=640&fit=bounds)



























































