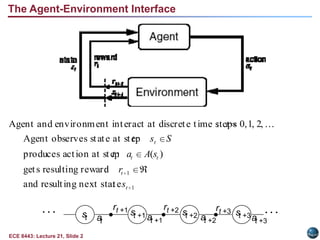
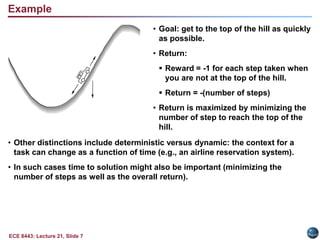
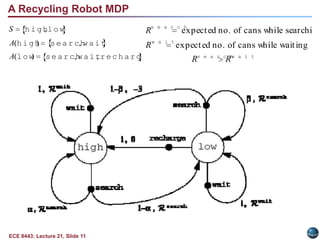
The document summarizes key concepts in reinforcement learning:
- Agent-environment interaction is modeled as states, actions, and rewards
- A policy is a rule for selecting actions in each state
- The return is the total discounted future reward an agent aims to maximize
- Tasks can be episodic or continuing
- The Markov property means the future depends only on the present state
- The agent-environment framework can be modeled as a Markov decision process