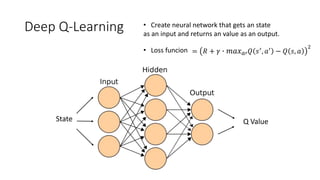
Deep Sarsa and Deep Q-learning use neural networks to estimate state-action values in reinforcement learning problems. Deep Q-learning uses experience replay and a target network to improve stability over the basic Deep Q-learning algorithm. Experience replay stores transitions in a replay buffer, and the target network is periodically updated to reduce bias from bootstrapping. Deepmind's DQN algorithm combined Deep Q-learning with experience replay and a target network to achieve good performance on complex tasks.

























































![[DL輪読会]深層強化学習はなぜ難しいのか?Why Deep RL fails? A brief survey of recent works.](https://cdn.slidesharecdn.com/ss_thumbnails/20210115dlohta-210115054939-thumbnail.jpg?width=640&height=640&fit=bounds)


























