Download as PDF, PPTX




![Atari[Nature,2015]
4](https://image.slidesharecdn.com/rlbasic-170706155846/85/Deep-Reinforcement-Learning-4-320.jpg)
![AlphaGo[Nature,2016]
5](https://image.slidesharecdn.com/rlbasic-170706155846/85/Deep-Reinforcement-Learning-5-320.jpg)

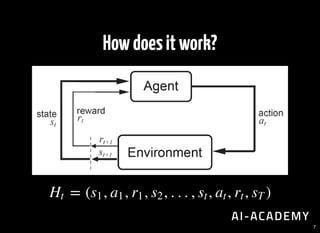







![Expectedfuturerewards
Any goal can be represented as a sum of intermediate rewards.
[ ∣ ] = [ + γ + + … ∣ ]∑
∞
t=0
γ
t
Rt St R0 R1 γ
2
R2 St
15](https://image.slidesharecdn.com/rlbasic-170706155846/85/Deep-Reinforcement-Learning-16-320.jpg)











![Updaterule
In rabbits, humans and machines we get the same algorithm:
while True:
Q[t] = Q[t-1] + alpha * (Q_target - Q[t-1])
27](https://image.slidesharecdn.com/rlbasic-170706155846/85/Deep-Reinforcement-Learning-28-320.jpg)
![Q-Learning[Watkins,1989]
The agent does not have a model of the environment.
Perform actions following a standard policy.
Predict using the target policy.
Which makes it an "o -policy", model-free method.
28](https://image.slidesharecdn.com/rlbasic-170706155846/85/Deep-Reinforcement-Learning-29-320.jpg)






![Network
Input: an image of shape [None, 42, 42, 4]
4 Conv2D 32 lters, 4x4 kernel
1 Hidden layer of size 256
1 Fully connected layer of size action_size
35](https://image.slidesharecdn.com/rlbasic-170706155846/85/Deep-Reinforcement-Learning-36-320.jpg)







The document provides an overview of deep reinforcement learning (DRL), outlining its fundamental concepts such as Q-learning, policy, value functions, and the role of agents in decision-making. It discusses various aspects including the significance of delayed feedback, the use of neural networks, and methods for improving stability in learning processes. Additionally, it highlights tools, challenges, and resources available for further exploration in the field of DRL.
























































![[Sponsored] C3.ai description](https://cdn.slidesharecdn.com/ss_thumbnails/c3deckmeetupnovember252019v2-191128092146-thumbnail.jpg?width=640&height=640&fit=bounds)







![[Giovanni Galloro] How to use machine learning on Google Cloud Platform](https://cdn.slidesharecdn.com/ss_thumbnails/mlcapabilitiesongcp-190115085455-thumbnail.jpg?width=640&height=640&fit=bounds)





![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)
















