Downloaded 15 times



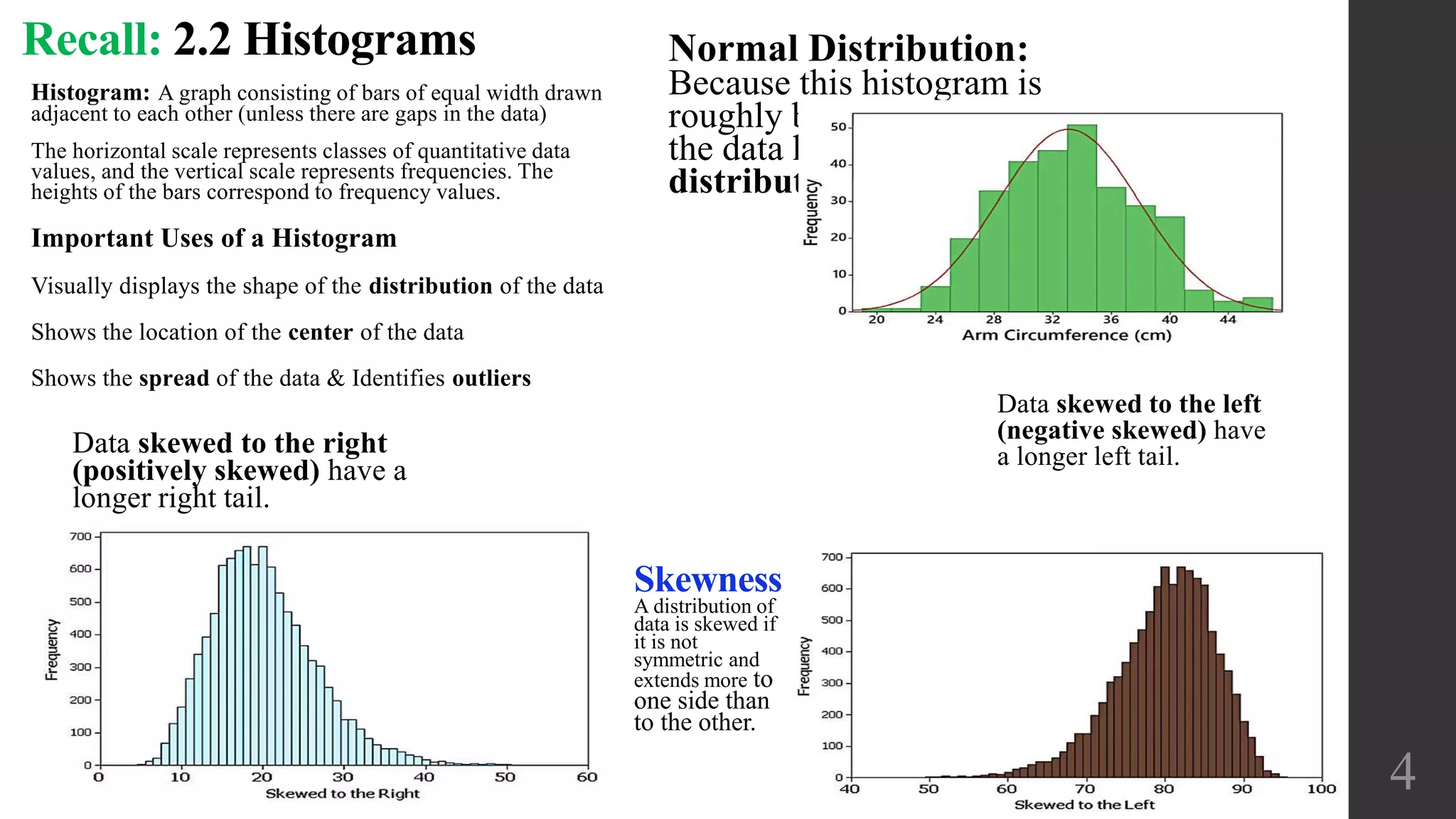


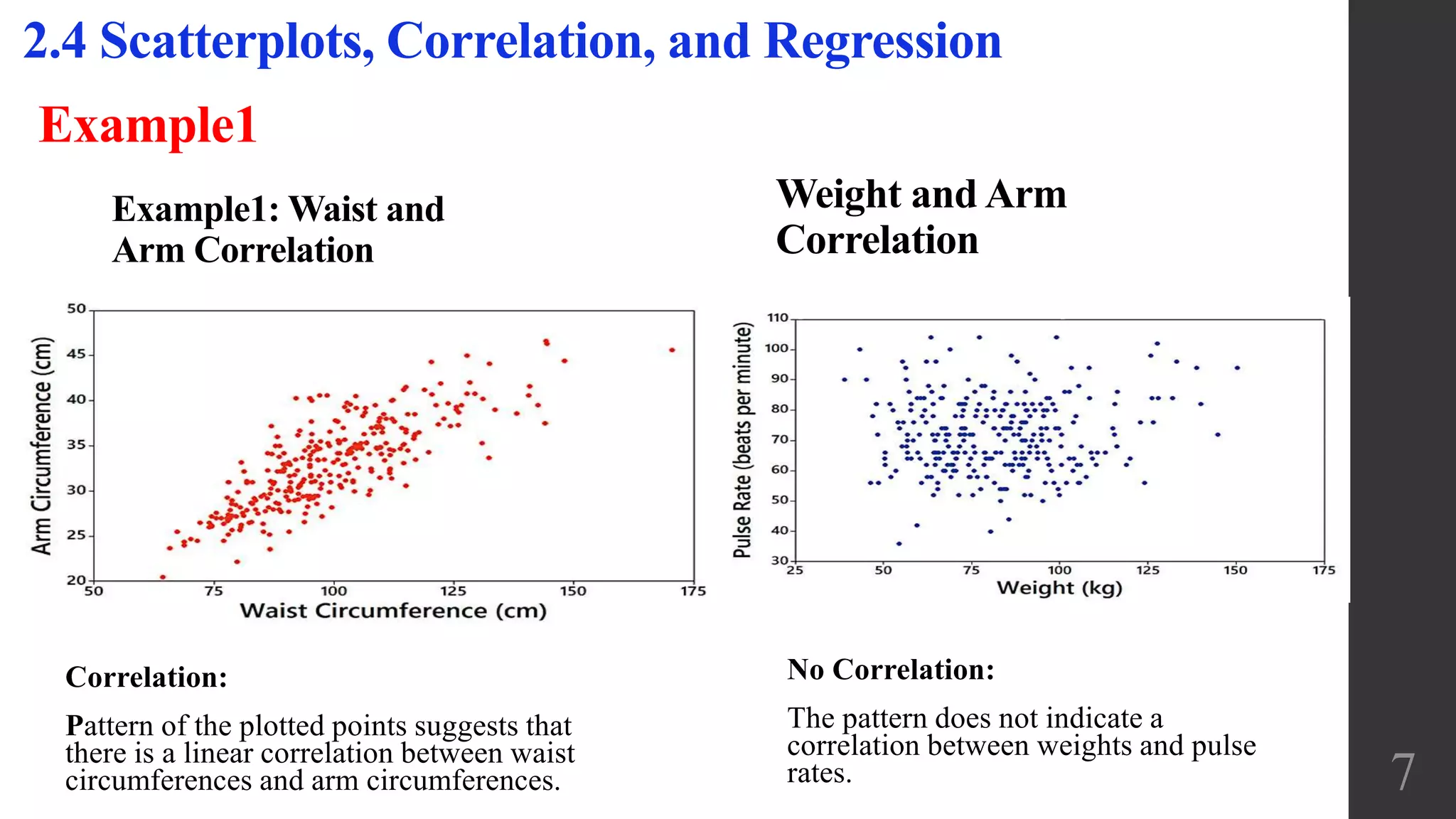
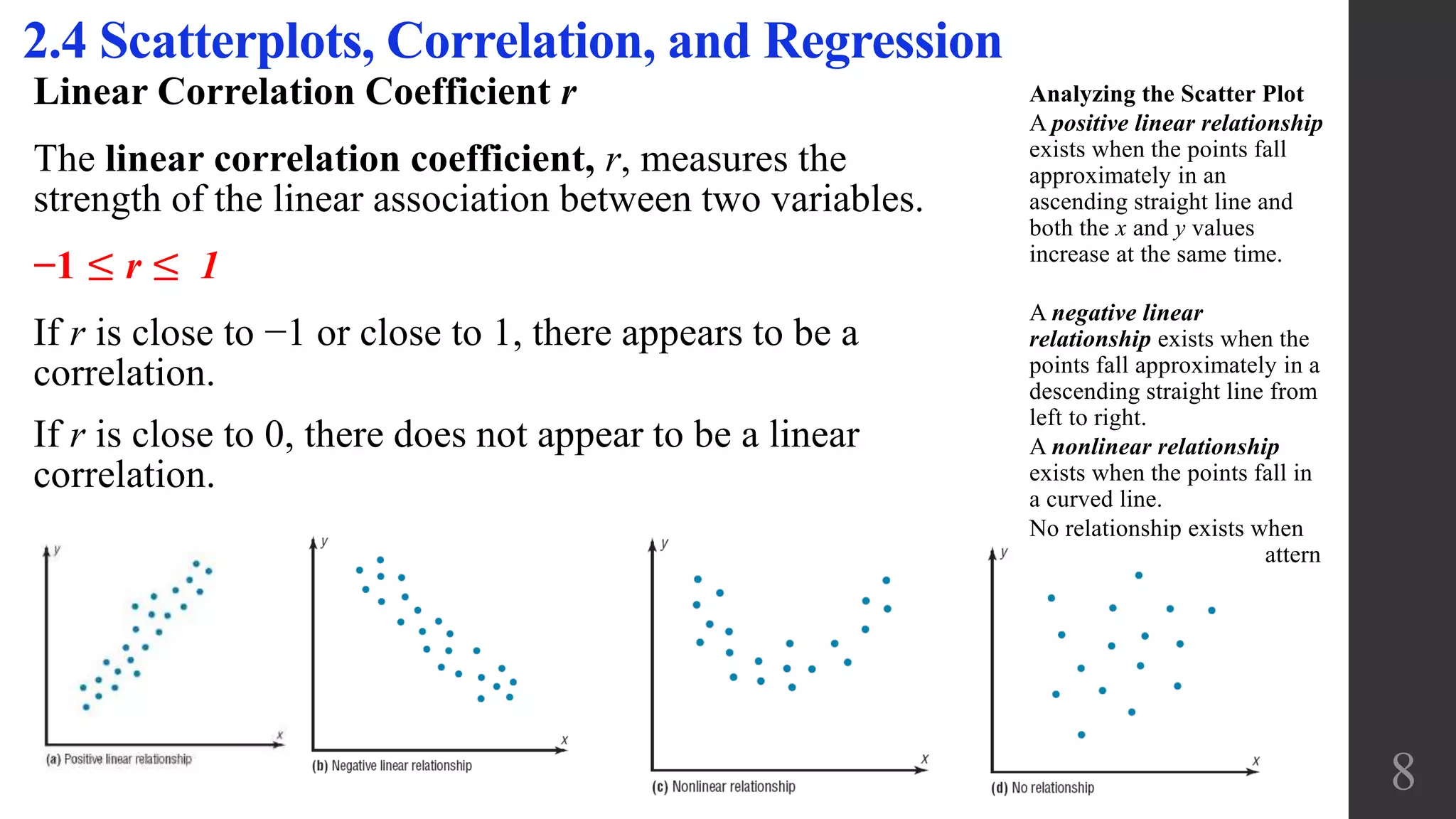
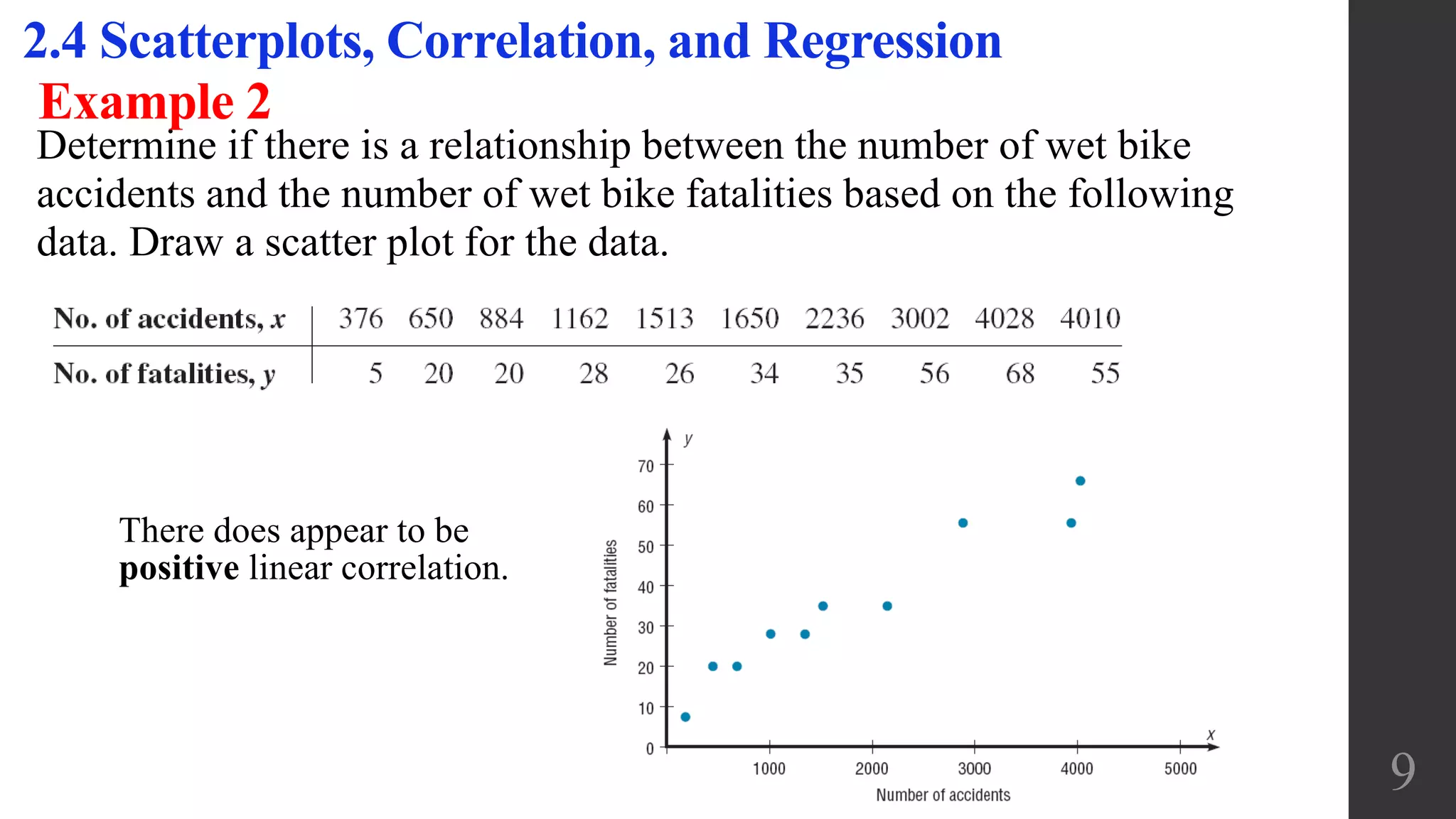
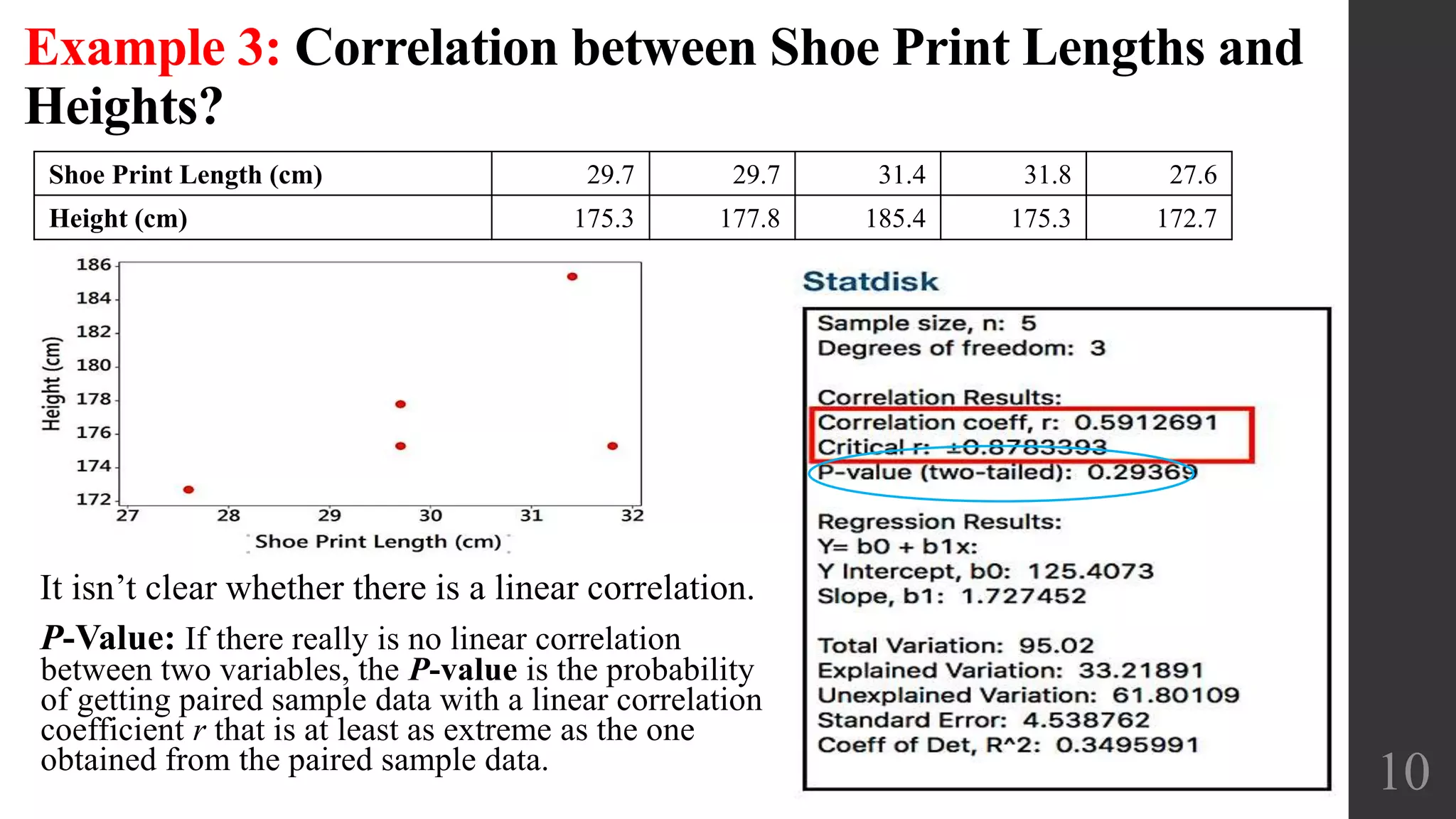


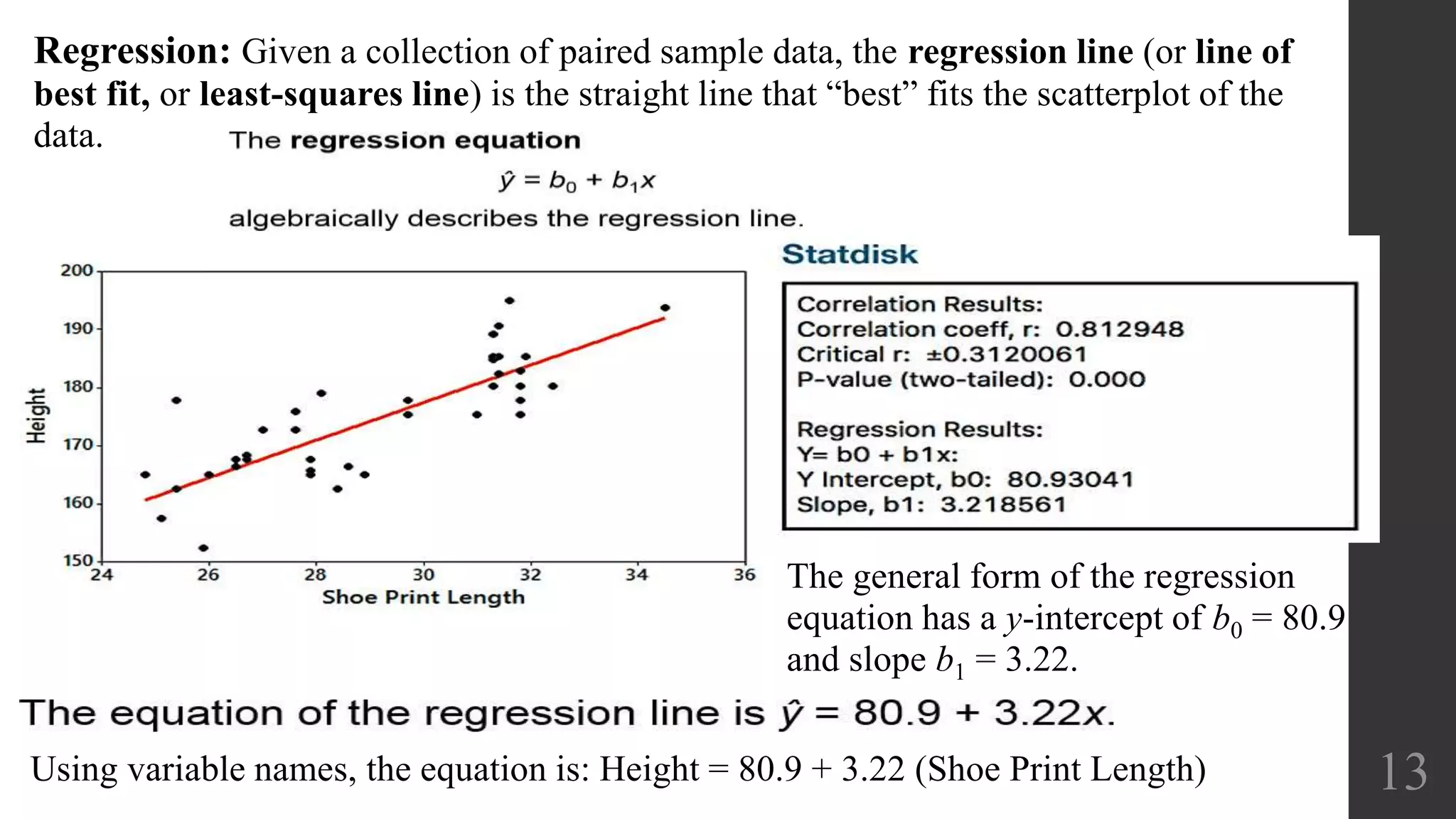

This document discusses scatterplots, correlation, and regression. It defines key terms like scatterplot, correlation, linear correlation, and regression line. Examples are provided to illustrate scatterplots and whether they show correlation between two variables. The linear correlation coefficient r is introduced as a measure of the strength of linear correlation between -1 and 1. Interpreting the p-value is also discussed, with a small p-value providing evidence of a linear correlation. Regression finds the straight line that best fits a set of paired sample data.























































































